大數(shù)據(jù)同步工具DataX與Sqoop之比較
DataX是一個在異構的數(shù)據(jù)庫/文件系統(tǒng)之間高速交換數(shù)據(jù)的工具,實現(xiàn)了在任意的數(shù)據(jù)處理系統(tǒng)(RDBMS/Hdfs/Local filesystem)之間的數(shù)據(jù)交換,由淘寶數(shù)據(jù)平臺部門完成。Sqoop是一個用來將Hadoop和關系型數(shù)據(jù)庫中的數(shù)據(jù)相互轉(zhuǎn)移的工具,可以將一個關系型數(shù)據(jù)庫(例如 : MySQL ,Oracle ,Postgres等)中的數(shù)據(jù)導進到Hadoop的HDFS中,也可以將HDFS的數(shù)據(jù)導進到關系型數(shù)據(jù)庫中。同樣是大數(shù)據(jù)異構環(huán)境數(shù)據(jù)同步工具,二者有什么差別呢?本文轉(zhuǎn)自Dean的博客。
從接觸DataX起就有一個疑問,它和Sqoop到底有什么區(qū)別,昨天部署好了DataX和Sqoop,就可以對兩者進行更深入的了解了。
兩者從原理上看有點相似,都是解決異構環(huán)境的數(shù)據(jù)交換問題,都支持oracle,mysql,hdfs,hive的互相交換,對于不同數(shù)據(jù)庫的支持都是插件式的,對于新增的數(shù)據(jù)源類型,只要新開發(fā)一個插件就好了,但是只細看兩者的架構圖,很快就會發(fā)現(xiàn)明顯的不同。
DataX架構圖
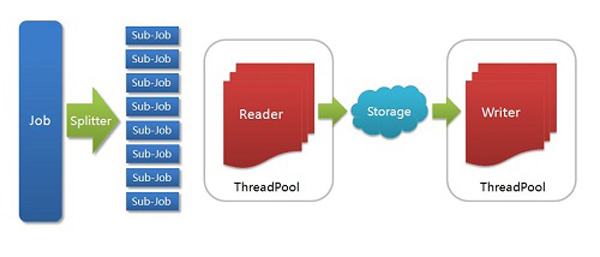
Job: 一道數(shù)據(jù)同步作業(yè)
Splitter: 作業(yè)切分模塊,將一個大任務與分解成多個可以并發(fā)的小任務.
Sub-job: 數(shù)據(jù)同步作業(yè)切分后的小任務
Reader(Loader): 數(shù)據(jù)讀入模塊,負責運行切分后的小任務,將數(shù)據(jù)從源頭裝載入DataX
Storage: Reader和Writer通過Storage交換數(shù)據(jù)
Writer(Dumper): 數(shù)據(jù)寫出模塊,負責將數(shù)據(jù)從DataX導入至目的數(shù)據(jù)地
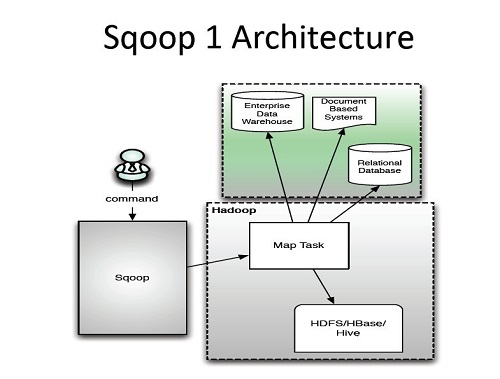
Sqoop架構圖
大數(shù)據(jù)同步工具DataX與Sqoop之比較
DataX 直接在運行DataX的機器上進行數(shù)據(jù)的抽取及加載。
而Sqoop充分里面了map-reduce的計算框架。Sqoop根據(jù)輸入條件,生成一個map-reduce的作業(yè),在Hadoop的框架中運行。
從理論上講,用map-reduce框架同時在多個節(jié)點上進行import應該會比從單節(jié)點上運行多個并行導入效率高。而實際的測試中也是如此,測試一個Oracle to hdfs的作業(yè),DataX上只能看到運行DataX上的機器的數(shù)據(jù)庫連接,而Sqoop運行時,4臺task-tracker全部產(chǎn)生一個數(shù)據(jù)庫連接。調(diào)起的Sqoop作業(yè)的機器也會產(chǎn)生一個數(shù)據(jù)庫連接,應為需要讀取數(shù)據(jù)表的一些元數(shù)據(jù)信息,數(shù)據(jù)量等,做分區(qū)。
Sqoop現(xiàn)在作為Apache的***項目,如果要我從DataX和Sqoop中間選擇的話,我想我還是會選擇Sqoop。而且Sqoop還有很多第三方的插件。早上使用了Quest開發(fā)的OraOop插件,確實像quest說的一樣,速度有著大幅的提升,Quest在數(shù)據(jù)庫方面的經(jīng)驗,確實比旁人深厚。

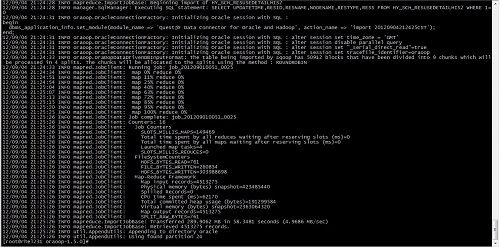
在我的測試環(huán)境上,一臺只有700m內(nèi)存的,IO低下的oracle數(shù)據(jù)庫,百兆的網(wǎng)絡,使用Quest的Sqoop插件在4個并行度的情況下,導出到HDFS速度有5MB/s ,這已經(jīng)讓我很滿意了。相比使用原生Sqoop的2.8MB/s快了將近一倍,sqoop又比DataX的760KB/s快了兩倍。
另外一點Sqoop采用命令行的方式調(diào)用,比如容易與我們的現(xiàn)有的調(diào)度監(jiān)控方案相結合,DataX采用xml 配置文件的方式,在開發(fā)運維上還是有點不方便。
附圖1.Sqoop with Quest oracle connector
大數(shù)據(jù)同步工具DataX與Sqoop之比較