數(shù)據(jù)不夠怎么訓(xùn)練深度學(xué)習模型?不妨試試遷移學(xué)習
深度學(xué)習大牛吳恩達曾經(jīng)說過:做AI研究就像造宇宙飛船,除了充足的燃料之外,強勁的引擎也是必不可少的。假如燃料不足,則飛船就無法進入預(yù)定軌道。而引擎不夠強勁,飛船甚至不能升空。類比于AI,深度學(xué)習模型就好像引擎,海量的訓(xùn)練數(shù)據(jù)就好像燃料,這兩者對于AI而言同樣缺一不可。
隨著深度學(xué)習技術(shù)在機器翻譯、策略游戲和自動駕駛等領(lǐng)域的廣泛應(yīng)用和流行,阻礙該技術(shù)進一步推廣的一個普遍性難題也日漸凸顯:訓(xùn)練模型所必須的海量數(shù)據(jù)難以獲取。
以下是一些當前比較流行的機器學(xué)習模型和其所需的數(shù)據(jù)量,可以看到,隨著模型復(fù)雜度的提高,其參數(shù)個數(shù)和所需的數(shù)據(jù)量也是驚人的。
據(jù)不夠怎么訓(xùn)練深度學(xué)習模型?不妨試試遷移學(xué)習")
基于這一現(xiàn)狀,本文將從深度學(xué)習的層狀結(jié)構(gòu)入手,介紹模型訓(xùn)練所需的數(shù)據(jù)量和模型規(guī)模的關(guān)系,然后通過一個具體實例介紹遷移學(xué)習在減少數(shù)據(jù)量方面起到的重要作用,***推薦一個可以簡化遷移學(xué)習實現(xiàn)步驟的云工具:NanoNets。
層狀結(jié)構(gòu)的深度學(xué)習模型
深度學(xué)習是一個大型的神經(jīng)網(wǎng)絡(luò),同時也可以被視為一個流程圖,數(shù)據(jù)從其中的一端輸入,訓(xùn)練結(jié)果從另一端輸出。正因為是層狀的結(jié)構(gòu),所以你也可以打破神經(jīng)網(wǎng)絡(luò),將其按層次分開,并以任意一個層次的輸出作為其他系統(tǒng)的輸入重新展開訓(xùn)練。
據(jù)不夠怎么訓(xùn)練深度學(xué)習模型?不妨試試遷移學(xué)習")
數(shù)據(jù)量、模型規(guī)模和問題復(fù)雜度
模型需要的訓(xùn)練數(shù)據(jù)量和模型規(guī)模之間存在一個有趣的線性正相關(guān)關(guān)系。其中的一個基本原理是,模型的規(guī)模應(yīng)該足夠大,這樣才能充分捕捉數(shù)據(jù)間不同部分的聯(lián)系(例如圖像中的紋理和形狀,文本中的語法和語音中的音素)和待解決問題的細節(jié)信息(例如分類的數(shù)量)。模型前端的層次通常用來捕獲輸入數(shù)據(jù)的高級聯(lián)系(例如圖像邊緣和主體等)。模型后端的層次通常用來捕獲有助于做出最終決定的信息(通常是用來區(qū)分目標輸出的細節(jié)信息)。因此,待解決的問題的復(fù)雜度越高(如圖像分類等),則參數(shù)的個數(shù)和所需的訓(xùn)練數(shù)據(jù)量也越大。
據(jù)不夠怎么訓(xùn)練深度學(xué)習模型?不妨試試遷移學(xué)習")
引入遷移學(xué)習
在大多數(shù)情況下,面對某一領(lǐng)域的某一特定問題,你都不可能找到足夠充分的訓(xùn)練數(shù)據(jù),這是業(yè)內(nèi)一個普遍存在的事實。但是,得益于一種技術(shù)的幫助,從其他數(shù)據(jù)源訓(xùn)練得到的模型,經(jīng)過一定的修改和完善,就可以在類似的領(lǐng)域得到復(fù)用,這一點大大緩解了數(shù)據(jù)源不足引起的問題,而這一關(guān)鍵技術(shù)就是遷移學(xué)習。
根據(jù)Github上公布的“引用次數(shù)最多的深度學(xué)習論文”榜單,深度學(xué)習領(lǐng)域中有超過50%的高質(zhì)量論文都以某種方式使用了遷移學(xué)習技術(shù)或者預(yù)訓(xùn)練(Pretraining)。遷移學(xué)習已經(jīng)逐漸成為了資源不足(數(shù)據(jù)或者運算力的不足)的AI項目的***技術(shù)。但現(xiàn)實情況是,仍然存在大量的適用于遷移學(xué)習技術(shù)的AI項目,并不知道遷移學(xué)習的存在。如下圖所示,遷移學(xué)習的熱度遠不及機器學(xué)習和深度學(xué)習。
據(jù)不夠怎么訓(xùn)練深度學(xué)習模型?不妨試試遷移學(xué)習")
遷移學(xué)習的基本思路是利用預(yù)訓(xùn)練模型,即已經(jīng)通過現(xiàn)成的數(shù)據(jù)集訓(xùn)練好的模型(這里預(yù)訓(xùn)練的數(shù)據(jù)集可以對應(yīng)完全不同的待解問題,例如具有相同的輸入,不同的輸出)。開發(fā)者需要在預(yù)訓(xùn)練模型中找到能夠輸出可復(fù)用特征(feature)的層次(layer),然后利用該層次的輸出作為輸入特征來訓(xùn)練那些需要參數(shù)較少的規(guī)模更小的神經(jīng)網(wǎng)絡(luò)。
由于預(yù)訓(xùn)練模型此前已經(jīng)習得了數(shù)據(jù)的組織模式(patterns),因此這個較小規(guī)模的網(wǎng)絡(luò)只需要學(xué)習數(shù)據(jù)中針對特定問題的特定聯(lián)系就可以了。此前流行的一款名為Prisma的修圖App就是一個很好的例子,它已經(jīng)預(yù)先習得了梵高的作畫風格,并可以將之成功應(yīng)用于任意一張用戶上傳的圖片中。
據(jù)不夠怎么訓(xùn)練深度學(xué)習模型?不妨試試遷移學(xué)習")
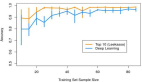
值得一提的是,遷移學(xué)習帶來的優(yōu)點并不局限于減少訓(xùn)練數(shù)據(jù)的規(guī)模,還可以有效避免過度擬合(overfit),即建模數(shù)據(jù)超出了待解問題的基本范疇,一旦用訓(xùn)練數(shù)據(jù)之外的樣例對系統(tǒng)進行測試,就很可能出現(xiàn)無法預(yù)料的錯誤。但由于遷移學(xué)習允許模型針對不同類型的數(shù)據(jù)展開學(xué)習,因此其在捕捉待解問題的內(nèi)在聯(lián)系方面的表現(xiàn)也就更優(yōu)秀。如下圖所示,使用了遷移學(xué)習技術(shù)的模型總體上性能更優(yōu)秀。
據(jù)不夠怎么訓(xùn)練深度學(xué)習模型?不妨試試遷移學(xué)習")
遷移學(xué)習到底能消減多少訓(xùn)練數(shù)據(jù)?
據(jù)不夠怎么訓(xùn)練深度學(xué)習模型?不妨試試遷移學(xué)習")
這里以此前網(wǎng)上流行的一個連衣裙圖片為例。如圖所示,如果你想通過深度學(xué)習判斷這條裙子到底是藍黑條紋還是白金條紋,那就必須收集大量的包含藍黑條紋或者白金條紋的裙子的圖像數(shù)據(jù)。參考上文提到的問題規(guī)模和參數(shù)規(guī)模之間的對應(yīng)關(guān)系,建立這樣一個精準的圖像識別模型至少需要140M個參數(shù),1.2M張相關(guān)的圖像訓(xùn)練數(shù)據(jù),這幾乎是一個不可能完成的任務(wù)。
現(xiàn)在引入遷移學(xué)習,用如下公式可以得到在遷移學(xué)習中這個模型所需的參數(shù)個數(shù):
No. of parameters = [Size(inputs) + 1] * [Size(outputs) + 1] = [2048+1]*[1+1]~ 4098 parameters
可以看到,通過遷移學(xué)習的引入,針對同一個問題的參數(shù)個數(shù)從140M減少到了4098,減少了10的5次方個數(shù)量級!這樣的對參數(shù)和訓(xùn)練數(shù)據(jù)的消減程度是驚人的。
一個遷移學(xué)習的具體實現(xiàn)樣例
在本例中,我們需要用深度學(xué)習技術(shù)對電影短評進行文本傾向性分析,例如“It was great,loved it.”表示積極正面的評論,“It was really stupid.”表示消極負面的評論。
假設(shè)現(xiàn)在可以得到的數(shù)據(jù)規(guī)模只有72條,其中62條沒有經(jīng)過預(yù)先的傾向性標記,用來預(yù)訓(xùn)練。8條經(jīng)過了預(yù)先的傾向性標記,用來訓(xùn)練模型。2條也經(jīng)過了預(yù)先的傾向性標記,用來測試模型。
由于我們只有8條經(jīng)過預(yù)先標記的訓(xùn)練數(shù)據(jù),如果直接以這樣的數(shù)據(jù)量對模型展開訓(xùn)練,無疑最終的測試準確率將非常低。(因為判斷結(jié)果只有正面和負面兩種,因此可以預(yù)見最終的測試準確率可能只有50%)
為了解決這個難題,我們引入遷移學(xué)習。即首先用62條未經(jīng)標記的數(shù)據(jù)對模型展開通用的情感判斷,然后在這一預(yù)訓(xùn)練的基礎(chǔ)上對本例的特定問題展開分析,復(fù)用預(yù)訓(xùn)練模型中的部分層次,就可以將最終的測試準確率提升到100%。下面將從3個步驟展開分析。
步驟1
創(chuàng)建預(yù)訓(xùn)練模型來分析詞與詞之間的關(guān)系。這里我們通過分析未標記語句中的某一詞匯,嘗試預(yù)測出現(xiàn)在同一句子中的其他詞匯。
據(jù)不夠怎么訓(xùn)練深度學(xué)習模型?不妨試試遷移學(xué)習")
步驟2
對模型展開訓(xùn)練,使得出現(xiàn)在類似上下文中的詞匯獲得類似的向量表示。在這一步驟中,62條待處理語句首先會被刪除停用詞,并被標記解釋。之后,針對每個詞匯,系統(tǒng)會嘗試減小其向量表示與相關(guān)詞匯的差別,并增加其與不相關(guān)詞匯的差別。
據(jù)不夠怎么訓(xùn)練深度學(xué)習模型?不妨試試遷移學(xué)習")
步驟3
預(yù)測一個句子的文本傾向性。由于在此前的預(yù)訓(xùn)練模型中我們已經(jīng)得到了針對所有詞匯的向量表示,并且這些向量具有用數(shù)字表征的每個詞匯的上下文屬性,這將使得文本的傾向性分析變得更易于實現(xiàn)。
據(jù)不夠怎么訓(xùn)練深度學(xué)習模型?不妨試試遷移學(xué)習")
需要注意的是,這里并非直接使用10個已經(jīng)被預(yù)先標記的句子,而是先將句子的向量設(shè)置為其所有詞匯的平均值(在實際任務(wù)中,我們將使用類似時間遞歸神經(jīng)網(wǎng)絡(luò)LSTM的相關(guān)原理)。這樣,經(jīng)過平均化處理的句子向量將作為輸入數(shù)據(jù)導(dǎo)入模型,而句子的正面或負面判定將作為結(jié)果輸出。需要特別強調(diào)的是,這里我們在預(yù)訓(xùn)練模型和10個被預(yù)先標記的句子之間加入了一個隱藏層(hidden layer),用來適配文本傾向性分析這一特定場景。正如你所看到的,這里只用10個標記量就實現(xiàn)了100%的預(yù)測準確率。
當然,必須指出的是,這里展示的只是一個非常簡單的模型示意,而且測試用例只有2條。但不可否認的一點是,由于遷移學(xué)習的引入,確實使得本例中的文本傾向性預(yù)測準確率從50%提升到了100%。
遷移學(xué)習的實現(xiàn)難點
雖然遷移學(xué)習的引入可以顯著減少模型對訓(xùn)練數(shù)據(jù)量的要求,但同時也意味著更多的專業(yè)調(diào)教。從上面的例子就能看出,只是考慮這些海量的必須硬編碼實現(xiàn)的參數(shù)數(shù)量,以及圍繞這些參數(shù)進行的繁雜的調(diào)試過程,就足夠讓人望而生畏了。而這也是遷移學(xué)習在實際應(yīng)用中難以進一步推廣的重要阻礙之一。這里我們總結(jié)了8條常見的遷移學(xué)習的實現(xiàn)難點。
- 獲取一個相對大規(guī)模的預(yù)訓(xùn)練數(shù)據(jù)
- 選擇一個合適的預(yù)訓(xùn)練模型
- 難以排查哪個模型沒有發(fā)揮作用
- 不知道需要多少額外數(shù)據(jù)來訓(xùn)練模型
- 難以判斷應(yīng)該在什么情況下停止預(yù)訓(xùn)練
- 決定預(yù)訓(xùn)練模型的層次和參數(shù)個數(shù)
- 代理和服務(wù)于組合模型
- 當獲得更多數(shù)據(jù)或者更好的算法時,預(yù)訓(xùn)練模型難以更新
NanoNets工具
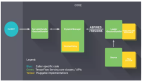
NanoNets是一個簡單方便的基于云端實現(xiàn)的遷移學(xué)習工具,其內(nèi)部包含了一組已經(jīng)實現(xiàn)好的預(yù)訓(xùn)練模型,每個模型有數(shù)百萬個訓(xùn)練好的參數(shù)。用戶可以自己上傳或通過網(wǎng)絡(luò)搜索得到數(shù)據(jù),NanoNets將自動根據(jù)待解問題選擇***的預(yù)訓(xùn)練模型,并根據(jù)該模型建立一個NanoNets(納米網(wǎng)絡(luò)),并將之適配到用戶的數(shù)據(jù)。NanoNets和預(yù)訓(xùn)練模型之間的關(guān)系結(jié)構(gòu)如下所示。
據(jù)不夠怎么訓(xùn)練深度學(xué)習模型?不妨試試遷移學(xué)習")
以上文提到的藍黑條紋還是白金條紋的連衣裙為例,用戶只需要選擇待分類的名稱,然后自己上傳或者網(wǎng)絡(luò)搜索訓(xùn)練數(shù)據(jù),之后NanoNets就會自動適配預(yù)訓(xùn)練模型,并生成用于測試的web頁面和用于進一步開發(fā)的API接口。如下所示,圖中為系統(tǒng)根據(jù)一張連衣裙圖片給出的分析結(jié)果。
據(jù)不夠怎么訓(xùn)練深度學(xué)習模型?不妨試試遷移學(xué)習")
具體使用方法詳見NanoNets官網(wǎng)。