ServerFrame::HashMap VS stl::unordered_map-性能探究之旅
1. 引言
突然就對項目中的HashMap有了強烈的好奇心,這個HashMap的實現夠高效嗎,和 std::unordered_map 的效率比較性能如何? 他們的插入效率、查找效率、空間使用率對比起來是分別是什么樣的?也沒有找到相關的測評,于是就自己動手,測試了一下,并對一些影響性能的地方修改、驗證自己的猜想,最終得到一個比較好的hashmap的實踐。整個過程還是比較有意思的,現記錄并分享出來。
1.1 好了別的不說了給我結論就好
好吧,大家都很忙,先給一下簡要結論,時間緊迫的同學也可以直接跳到文尾查看結論小節.
- ServerFrame::HashMap 的哈希算法算出來的哈希值散列度不夠,key的長度越長,散列能力越差,性能越差。
- 因為沖突處理的緣故,本文所做的幾個用例中,極端情況下 ServerFrame::HashMap 的表現比 stl::unordered_map 差100倍;
- 哈希算法散列程度足夠的時候,ServerFrame::HashMap 的表現比 stl::unordered_map 好。前者的插入效率是后者的10倍,查找效率3倍;
- 存儲同樣的數據,HashMap 耗內存多于 unordered_map;
1.2 show me the code
本文用到的測試代碼和測試結果全部在 git.oa.com中,有興趣的同學可以下載查看。
- 倉庫路徑:http://git.code.oa.com/lawrencechi/hashmap-benchmark.git
- 成文時倉庫版本 tag:v2.0
- 內存: 12G
- cpu 2核: i7-6700 CPU 3.40GHz
- ServerFrame::HashMap: 編譯時預設的容量是 8000萬
- 測試用例:
- lawrencechi@lawrencechi-VirtualBox /data/hashmap-benchmark/hashmap-benchmark/build ±master:zap: » ./bm_hashmap.O2
- Usage: bm_hashmap.O2 [-n count] -hijklmop
- -h: hashmap-int
- -i: hashmap-string(32 byte)
- -j: unordered-map-int
- -k: unordered-map-string
- -l: hashmap(32 byte)) idx
- -m: hash<string> idx
- -o: hashmapplus(32 byte)) idx
- -p: hashmapplus-string(32 byte))
2.int類型key
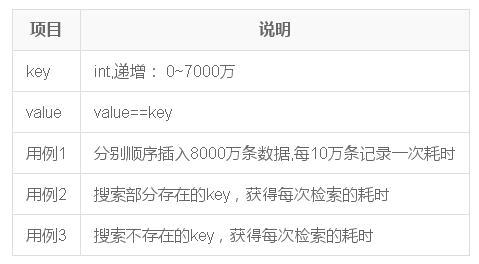
2.1用例結果
執行./bm_hashmap.O2 -n 700 -hj,獲得數據,并繪制圖表如下(畫圖數據經過省略,但關鍵信息還在,下同)
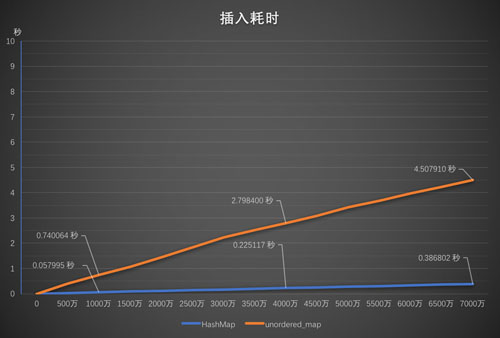
[圖: 2.1插入耗時 ]
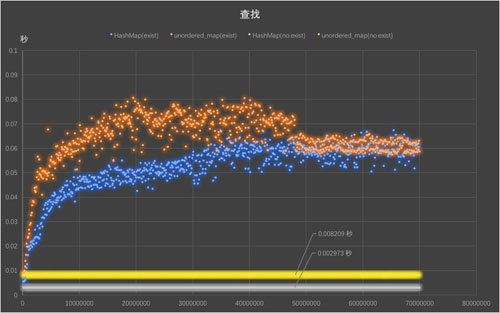
[ 圖:2.1查找耗時 ]
總體來看,兩個實現的效率都很高,穩定(斜率不變,意味著單位時間內插入條數沒有變化),插入8000萬條數據最多只需要4.5s, 在使用 ServerFrame::HashMap插入數據的時候,HashMap甚至能夠達到 stl::unordered_map的10倍;當key不存在的時候,HashMap 查找速度也比 unordered_map 快4倍, key 存在的時候,容量少于5000萬條時,HashMap 比 unordered_map 快,只有大于5000萬時,兩者查找的速度才相差不大。
這次測試看起來 HashMap 實現得非常完美,很好地解決了預設需求,插入效率高、查找效率高。雖然耗費的內存多,僅存8000萬個int的 HashMap 需要 3.5G 的內存,但現代服務器內存充足,這個缺點似乎是可以忍受的。
除了內存之外,ServerFrame::HashMap 的實現就沒有其他的缺點了嗎? 很快,我就想到了他的 Hash 函數和沖突處理,決定從這里入手繼續分析。
2.2 隱憂:hash算法
ServerFrame::HashMap 的 hash 算法實現是將 key 的 buffer(sizeof(key)),按照 int 字節累加,并將其結果和哈希表容量進行取余,簡單粗暴,而且似乎也符合大道至簡的理論。但是仔細想想,這個地方的實現違背了哈希算法的原則:均衡性。一個不夠均衡性的算法會導致大量沖突,最終使得HashMap在反復的沖突處理中疲于奔命。
很簡單,按照這個算法下面的這些數據算得到的哈希值都是一樣的,而且這樣的數據可以輕易地構造:
- 0xFFFFFFFF,
- 0xFFFFFFFF 00000000
- 0xFFFFFFFF 00000000 00000000
- 0xFFFFFFFF 00000000 00000000 00000000
最為對比,我們都知道構造兩個擁有同樣MD5值的數據是何等的困難。
而且仔細分析一下可以知道 2.1 用例剛好繞過了這個算法的缺陷,取到的key都不會相互沖突! 這時候的測試結果恰恰是最優結果!
如果沖突了會怎么樣,測試結果變成怎么樣? 在好奇心驅使下,我馬上進行 3.1 用例的測試。
3. buffer(32byte)類型

3.1用例結果
執行./bm_hashmap.O2 -n 700 -ik,獲得數據,并繪制圖表如下
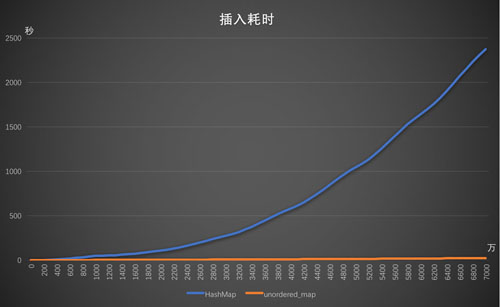
[圖: 3.1插入耗時 ]
從上圖可以看到,對于buffer類型的key,性能表現差異很大.
從HashMap的圖來看,越到后面斜率越大,說明到后面的時候,插入單位條數的耗時已經急劇增長。這是符合我們的設想的,此時程序在拼命進行沖突處理!
從圖中還可以得到一個信息,插入7000萬條數據,HashMap的耗時是接近2500秒,也就是41分鐘!
至于unordered_map,上圖已經分析不出什么東西來,和HashMap比起來,它的變化太緩慢了。我只能抽出來單獨分析,圖如下:
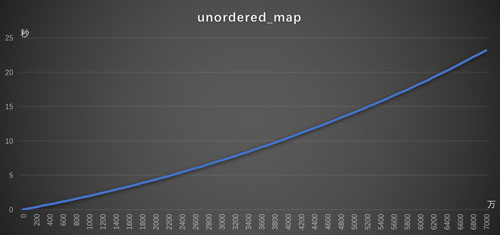
[ [圖:3.1插入耗時-unordered_map ]
unordered_map 斜率幾乎不變,可以知道每次插入的耗時是相同的,穩定,插入7000萬條數據,耗時25s,HashMap差不多是他的100倍。
從上面的測試結果可知 HashMap 的效率的確是急劇下降,但是這個急劇下降是 Hash 算法引起的嗎? 還是需要定量分析!
4. hash 算法比較
4.1 unordered_map
stl::unordered_map 是C++11引進的,老版本也有,只是沒有提供接口出來供外部使用。
恰好手頭上有 gcc 4.9.3 的代碼,于是一探究竟
- //代碼片段 ==================
- //file:/data/study/gcc/gcc.4.9.3/gcc-4.9.3/libstdc++-v3/libsupc++/hash_bytes.cc +73
- size_t _Hash_bytes(const void* ptr, size_t len, size_t seed)
- {
- const size_t m = 0x5bd1e995;
- size_t hash = seed ^ len;
- const char* buf = static_cast<const char*>(ptr);
- // Mix 4 bytes at a time into the hash.
- while(len >= 4)
- {
- size_t k = unaligned_load(buf);
- k *= m;
- k ^= k >> 24;
- k *= m;
- hash *= m;
- hash ^= k;
- buf += 4;
- len -= 4;
- }
- // Handle the last few bytes of the input array.
- switch(len)
- {
- case 3:
- hash ^= static_cast<unsigned char>(buf[2]) << 16;
- case 2:
- hash ^= static_cast<unsigned char>(buf[1]) << 8;
- case 1:
- hash ^= static_cast<unsigned char>(buf[0]);
- hash *= m;
- };
- // Do a few final mixes of the hash.
- hash ^= hash >> 13;
- hash *= m;
- hash ^= hash >> 15;
- return hash;
- }
對于可以轉換成 size_t 類型的key,hash提供了幾個特化哈希函數,直接返回((size_t)key),上面的哈希函數是buffer類型的哈希函數,傳入起始地址,得到哈希值。這個hash算法用了幾個魔數,各種位運算得到一個 int32 的值,好吧,此時我已經不知道怎么才能構造兩個碰撞數據了。
最為對比,HashMap的hash函數如下:
- template <typename KEY_TYPE, typename DATA_TYPE, int NODE_SIZE, typename CMP_FUNC, int HASH_SIZE>
- int CHashMap<KEY_TYPE, DATA_TYPE, NODE_SIZE, CMP_FUNC, HASH_SIZE>::HashKeyToIndex(const KEY_TYPE& rstKey, int& riIndex) const
- {
- size_t uiKeyLength = sizeof(rstKey);
- unsigned int uiHashSum = 0;
- //目前Hash算法實現比較簡單只是將Key值的每個字節的值加起來并對SIZE取模
- unsigned int i;
- for( i = 0; i < uiKeyLength / sizeof(unsigned int); ++i)
- {
- unsigned int uiTmp = 0;
- memcpy(&uiTmp, ((char*)(&rstKey))+sizeof(uiTmp)*i, sizeof(uiTmp));
- uiHashSum += uiTmp;
- }
- if(uiKeyLength % sizeof(unsigned int) > 0)
- {
- unsigned char* pByte = (unsigned char*)&rstKey;
- pByte += (uiKeyLength - (uiKeyLength % sizeof(unsigned int)));
- unsigned int uiTemp = 0;
- memcpy((void *)&uiTemp, (const void *)pByte, uiKeyLength%sizeof(unsigned int));
- uiHashSum += uiTemp;
- }
- uiHashSum = (uiHashSum & ((unsigned int)0x7fffffff));
- riIndex = (int)(uiHashSum % HASH_SIZE);
- return 0;
- }
4.2 用例設計
4.3 用例結果
執行./bm_hashmap.O2 -n 700 -lm,獲得數據,并繪制圖表如下
碰撞太頻繁了,為了可讀性,這里對原始數據做了二次統計。統計每一個沖突鏈表的長度,以及key數量和占比。key數量之和是 7000萬,占比之和是100%。
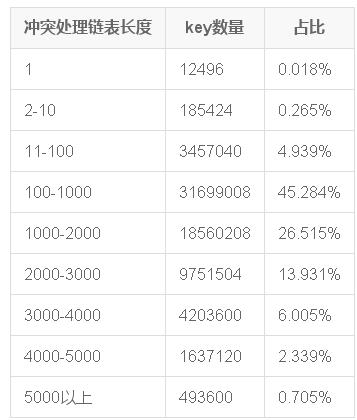
這個表格就一目了然了:
- 我們最期望的結果是沒有沖突,也就是鏈表長度為1,僅占比0.265%!
- 絕大部分的沖突鏈表長度在100以上, 占了總量的 95%.
- 最長的鏈表達到了 5000以上,而且占比 有 0.705%,比我們期望的不沖突的占比還多了3倍。也就是說最差情況的比最好情況多了3倍。
作為對比,stl::unordered_map 的結果就好看很多了,甚至都不需要進行二次統計、處理:
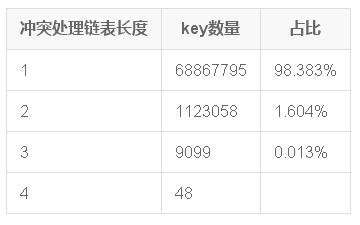
那么,猜想一下,如果替換掉 ServerFrame::HashMap 的哈希算法,是不是測試的效果就會好很多呢?
5. 升級HashMap hash算法之后測試
開搞,把gcc4.9.3的哈希算法移植到 ServerFrame::HashMap,并放到一個新命名空間中,另存為文件 HashMapPlush.hpp。 重做3.1的測試用例 ./bm_hashmap.O2 -n 700 -lm,獲得數據,并繪制圖表如下
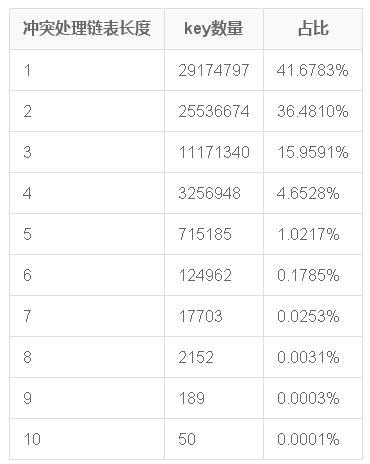
可見升級哈希算法之后,沖突還是存在,但是沖突鏈表過長的現象已經不存在了,最長的沖突鏈表長度也只有10。此時可以想象耗時數據肯定好了很多。
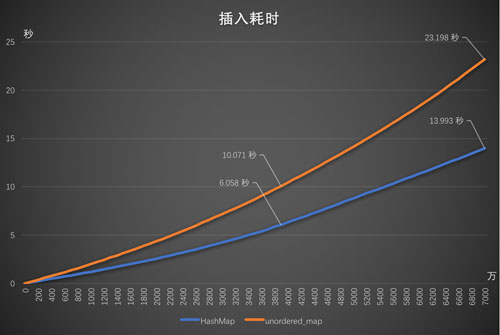
[ 圖:5.1插入耗時 ]
可見,調整較小,但是效果比較明顯
ServerFrame::HashMap 的插入耗時是 unordered_map 的 1/2;
ServerFrame::HashMap 斜率很穩,可見插入耗時比較穩定
6. 結論
從上面的實驗可以看出,影響 HashMap 效率的主要是 哈希算法 和 內存分配算法,在哈希算法足夠散列的情況下,預分配方式的效率更高。
空間換時間的策略是對的,兩個影響因素,另個不夠好的時候,靠空間得到的優勢反而會損失;
原文鏈接:https://www.qcloud.com/community/article/625434
【本文是51CTO專欄作者“騰訊云技術社區”的原創稿件,轉載請通過51CTO聯系原作者獲取授權】