為什么會有這么多中間表?
中間表的由來
中間表是數據庫中專門存放中間計算結果的數據表。報表系統中的中間表是普遍存在的。那么,這些中間表是如何出現的?為什么中間表會越來越多?中間表會給項目組帶來什么樣的困擾,如何解決這些困擾?這里我們就嘗試探討一下這個問題。
中間表出現的典型場景主要有三個:
- 一步算不出來。數據庫中的原始數據表要經過復雜計算,才能在報表上展現出來。一個SQL很難實現這樣的復雜計算。要連續多個SQL實現,前面的生成中間表給后邊的SQL使用。
- 實時計算等待時間過長。因為數據量大或者計算復雜,報表用戶等待時間太長。所以要每天晚上跑批量任務,把數據計算好之后存入中間表。報表用戶基于中間表查詢就會快很多。
- 多樣性數據源參加計算。來自于文件、NOSQL、Web service等的外部數據,需要與數據庫內數據進行混合計算時,傳統辦法只能導入數據庫形成中間表。
中間表帶來的問題
在一個運營商的報表系統中,我們發現了一個讓人吃驚的現象。在DB2數據倉庫中,有兩萬多個數據庫表!經過深入了解發現,真正的原始數據表只有幾百張,剩下的大量的數據庫表都是為查詢和報表服務的中間表。
經過幾年乃至十幾年的運行,數據庫中的中間表越來越多,甚至出現這個項目中上萬個的情況。大量中間表帶來的直接困擾是數據庫存儲空間不夠用,面臨頻繁的擴容需求。中間表對應的存儲過程、觸發器等等需要占用數據庫的計算資源,也會造成數據庫的擴容壓力。
那么,是不是可以清理掉一些不用的中間表?一般的結論都是:搞不動。數據庫中的中間表是不同程序員制作的,有的是綜合查詢系統使用,有的是報表系統使用。中間表之間還存在交叉引用,有些程序員看到有別人生成的中間表就直接使用了。有時候一些查詢報表已經廢棄不用了,但是對應的中間表沒人敢刪,因為不知道刪掉之后會影響其他什么查詢或者報表。
很多情況下,項目組只好為了越來越多的中間表去擴容數據庫。但是數據庫的擴容成本太昂貴了:不管是換更強的服務器(縱向擴容),還是增加數據庫服務器的節點(橫向擴容),都不便宜。過于頻繁的擴容讓項目組非常頭疼。
那么,能不能把中間表導出到文件中,從而減輕數據庫的壓力呢?這個辦法初看挺好,但是有個問題始終無法解決。例如:每天晚上把經營分析表數據生成好之后放到文件中,第二天上班的時候發現,業務人員還要對經營分析表按照各種條件過濾,或者按照各種維度分組。因為文件本身是沒有計算能力的,一旦把中間表從數據庫中導出成文件就很難進一步計算了。不得已,只能把中間表繼續留在數據庫中。
解決問題的辦法
采用潤乾集算器實現文件計算,就可以把中間表從庫中遷移到文件系統中了。采用集算器的前后對比圖如下:
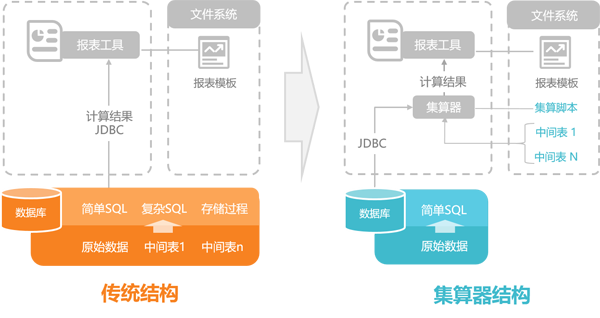
在集算器結構中,數據庫的大量中間表都移到了庫外,數據庫僅僅存儲少量原始數據表,壓力就小了很多。針對這些中間表實現的多個ETL存儲過程、觸發器、復雜SQL也都由集算器來實現,數據庫的計算壓力也變小了很多。雖然計算和存儲壓力由應用服務器來承擔,但是成本還是要比數據庫服務器低很多。項目組不用再每隔一段時間就申請數據庫服務器擴容了。
同時,集算器可以讀取多樣性數據源,直接參與混合計算。無需再導入數據庫,成為中間表。
集算器編程很容易
移到庫外的數據文件不能再使用SQL計算了,換成集算器會不會增加編寫的難度呢?實際上,集算器編寫簡單計算腳本的時候和SQL差不多,復雜多步驟計算還要比SQL容易。例如:
- 讀取文件
| A | ||
| 1 | =file(“D:/report/HR/employee.b”) | |
| 2 | =A1.import@b() |
- 實現過濾
| A | B | |
| 1 | =file(“Order_Books.b”).import@b() | =A1.select(Amount>=20000 && month(Date)==3) |
- 分組匯總
| A | B | |
| 1 | =file(“Order_Books.b”).import@b() | =A1.select(Amount>20000) |
| 2 | =A1.groups(SalesID, month(Date); sum(Amount), count(~)) | |
從上述例子來看,采用集算器實現數據文件庫外計算,學習成本很低,很容易掌握。
新方案的價值
新方案的價值還不僅僅是降低數據庫的壓力。
對于報表應用而言,中間數據的存在是有價值的:有些中間表是報表業務決定的,有些是為了彌補現有技術的不足。也就是說,中間數據和報表模板一樣,都是報表系統的一部分。所以,集算器的方案并沒有讓中間數據消失,只是移到了庫外,保存在報表應用的文件目錄中,使得中間表在物理上也成為了報表應用系統的一部分。這樣既能發揮中間數據的價值,還可以讓中間數據和報表系統的其他部分一起管理。顯然,文件系統的樹形目錄結構比數據庫混在一起的幾萬個表要更容易維護。
在實際項目中,可以給中間數據文件建立多層文件夾存儲。例如:***層目錄是財務管理、人力資源、ERP等等。人力資源又有子目錄:工資管理,基本信息,黨員信息等等。目錄可以細化到某個報表,如果該報表發生了變化,只需要調整這個目錄中的報表模板或者數據文件即可。如果該報表廢棄不用,那么刪掉或者移走報表所在目錄,就可以快速的釋放硬盤空間。
從計算速度來說,由于文件更底層,更接近于磁盤,IO性能要好于數據庫。所以集算器的方案可以為報表系統帶來更快的性能。
報表數據來自于多樣性數據源時,還可以有更好的實時性,不像傳統手段時只能定期入庫。