MSSQL · 特性分析 · 列存儲技術(shù)做實(shí)時分析
數(shù)據(jù)分析指導(dǎo)商業(yè)行為的價值越來越高,使得用戶對數(shù)據(jù)實(shí)時分析的要求變得越來越高。使用傳統(tǒng)RDBMS數(shù)據(jù)分析架構(gòu),遇到了***的挑戰(zhàn),高延遲、數(shù)據(jù)處理流程復(fù)雜和成本過高。這篇文章討論如何利用SQL Server 2016列存儲技術(shù)做實(shí)時數(shù)據(jù)分析,解決傳統(tǒng)分析方法的痛點(diǎn)。
傳統(tǒng)RDBMS數(shù)據(jù)分析
在過去很長一段時間,企業(yè)均選擇傳統(tǒng)的關(guān)系型數(shù)據(jù)庫做OLAP和Data Warehouse工作。這一節(jié)討論傳統(tǒng)RDBMS數(shù)據(jù)分析的結(jié)構(gòu)和面臨的挑戰(zhàn)。
傳統(tǒng)RDBMS分析架構(gòu)
傳統(tǒng)關(guān)系型數(shù)據(jù)庫做數(shù)據(jù)分析的架構(gòu),按照功能模塊可以劃分為三個部分:
OLTP模塊:OLTP的全稱是Online Transaction Processing,它是數(shù)據(jù)產(chǎn)生的源頭,對數(shù)據(jù)的完整性和一致性要求很高;對數(shù)據(jù)庫的反應(yīng)時間(RT: Response Time)非常敏感;具有高并發(fā),多事務(wù),高響應(yīng)等特點(diǎn)。
ETL模塊:ETL的全稱是Extract Transform Load。他是做數(shù)據(jù)清洗、轉(zhuǎn)化和加載工作的。可以將ETL理解為數(shù)據(jù)從OLTP到Data Warehouse的“搬運(yùn)工”。ETL***的特定是具有延時性,為了***限度減小對OLTP的影響,一般會設(shè)計成按小時,按天或者按周來周期性運(yùn)作。
OLAP模塊:OLAP的全稱是Online Analytic Processing,它是基于數(shù)據(jù)倉庫(Data Warehouse)做數(shù)據(jù)分析和報表呈現(xiàn)的終端產(chǎn)品。數(shù)據(jù)倉庫的特點(diǎn)是:數(shù)據(jù)形態(tài)固定,幾乎或者很少發(fā)生數(shù)據(jù)變更,統(tǒng)計查詢分析讀取數(shù)據(jù)量大。
傳統(tǒng)的RDBMS分析模型圖,如下圖展示(圖片直接截取自微軟的培訓(xùn)材料):
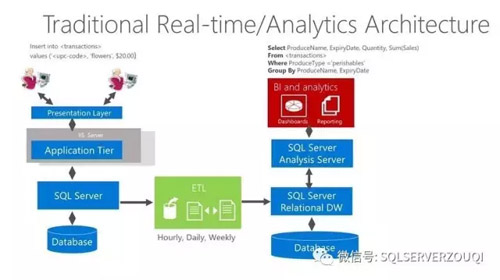
從這個圖,我們可以非常清晰的看到傳統(tǒng)RDBMS分析模型的三個大的部分:在圖的最左邊是OLTP業(yè)務(wù)場景,負(fù)責(zé)采集和產(chǎn)生數(shù)據(jù);圖的中部是ETL任務(wù),負(fù)責(zé)“搬運(yùn)”數(shù)據(jù);圖的右邊是OLAP業(yè)務(wù)場景,負(fù)責(zé)分析數(shù)據(jù),然后將分析結(jié)果交給BI報表展示給最終用戶。企業(yè)使用這個傳統(tǒng)的架構(gòu)長達(dá)數(shù)年,遇到了不少的挑戰(zhàn)和困難。
面臨的挑戰(zhàn)
商場如戰(zhàn)場,戰(zhàn)機(jī)隨息萬變,數(shù)據(jù)分析結(jié)果指導(dǎo)商業(yè)行為的價值越來越高,使得數(shù)據(jù)分析結(jié)果變得越來越重要,用戶對數(shù)據(jù)實(shí)時分析的要求變得越來越高。使用傳統(tǒng)RDBMS分析架構(gòu),遇到了***的挑戰(zhàn),主要的痛點(diǎn)包括:
- 數(shù)據(jù)延遲大
- 數(shù)據(jù)處理流程冗長復(fù)雜
- 成本過高
數(shù)據(jù)延遲大:為了減少對OLTP模塊的影響,ETL任務(wù)往往會選擇在業(yè)務(wù)低峰期周期性運(yùn)作,比如凌晨。這就會導(dǎo)致OLAP分析的數(shù)據(jù)源Data Warehouse相對于OLTP有至少一天的時間差異。這個時間差異對于某些實(shí)時性要求很高的業(yè)務(wù)來說,是無法接受的。比如:銀行卡盜刷的檢查服務(wù),是需要做到秒級別通知持卡人的。試想下,如果你的銀行卡被盜刷,一天以后才收到銀行發(fā)過來的短信提醒,會是多么糟糕的體驗。
數(shù)據(jù)處理流程冗長復(fù)雜:數(shù)據(jù)是通過ETL任務(wù)來抽取、清洗和加載到Data Warehouse中的。為了保證數(shù)據(jù)分析結(jié)果的正確性,ETL還必須要解決一系列的問題。比如:OLTP變更數(shù)據(jù)的捕獲,并同步到Data Warehouse;周期性的進(jìn)行數(shù)據(jù)全量和增量更新來確保OLTP和Data Warehouse中數(shù)據(jù)的一致性。整個數(shù)據(jù)流冗長,實(shí)現(xiàn)邏輯異常復(fù)雜。
成本過高:為了實(shí)現(xiàn)傳統(tǒng)的RDBMS數(shù)據(jù)分析功能,必須新增Data Warehouse角色來保存所有的OLTP數(shù)據(jù)冗余,專門提供分析服務(wù)功能。這勢必會加大了硬件、軟件和維護(hù)成本投入;隨之還會到來ETL任務(wù)做數(shù)據(jù)抓取、清洗、轉(zhuǎn)換和加載的開發(fā)成本和時間成本投入。
那么,SQL Server有沒有一種技術(shù)既能解決以上所有痛點(diǎn)的方法,又能實(shí)現(xiàn)數(shù)據(jù)實(shí)時分析呢?當(dāng)然有,那就是SQL Server 2016列存儲技術(shù)。
SQL Server 2016列存儲技術(shù)做實(shí)時分析
為了解決OLAP場景的查詢分析,微軟從SQL Server 2012開始引入列存儲技術(shù),大大提高了OLAP查詢的性能;SQL Server 2014解決了列存儲表只讀的問題,使用場景大大拓寬;而SQL Server 2016的列存儲技術(shù)徹底解決了實(shí)時數(shù)據(jù)分析的業(yè)務(wù)場景。用戶只需要做非常小規(guī)模的修改,便可以可以非常平滑的使用SQL Server 2016的列存儲技術(shù)來解決實(shí)時數(shù)據(jù)分析的業(yè)務(wù)場景。這一節(jié)討論以下幾個方面:
SQL Server 2016數(shù)據(jù)分析架構(gòu)
- Disk-based Tables with Nonclustered Columnstore Index
- Memory-based Tables with Columnstore Index
- Minimizing impacts of OLTP
SQL Server 2016數(shù)據(jù)分析架構(gòu)
SQL Server 2016數(shù)據(jù)分析架構(gòu)相對于傳統(tǒng)的RDBMS數(shù)據(jù)分析架構(gòu)有了非常大的改進(jìn),變得更加簡單。具體體現(xiàn)在OLAP直接接入OLTP數(shù)據(jù)源,如此就無需Data Warehouse角色和ETL任務(wù)這個“搬運(yùn)工”了。
OLAP直接接入OLTP數(shù)據(jù)源:讓OLAP報表數(shù)據(jù)源直接接入OLTP的數(shù)據(jù)源頭上。SQL Server會自動選擇合適的列存儲索引來提高數(shù)據(jù)分析查詢的性能,實(shí)現(xiàn)實(shí)時數(shù)據(jù)分析的場景。
不再需要ETL任務(wù):由于OLAP數(shù)據(jù)源直接接入OLTP的數(shù)據(jù),沒有了Data Warehouse角色,所以不再需要ETL任務(wù),從而大大簡化了數(shù)據(jù)處理流程中的各環(huán)節(jié),沒有了相應(yīng)的開發(fā)維護(hù)和時間成本。
SQL Server 2016實(shí)時分析架構(gòu)圖,展示如下(圖片來自微軟培訓(xùn)教程):
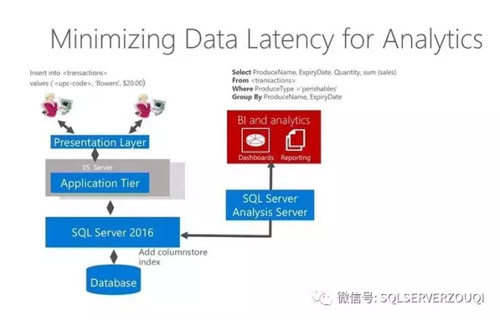
SQL Server 2016之所以能夠?qū)崿F(xiàn)如此簡化的實(shí)時分析,底氣是來源于SQL Server 2016的列存儲技術(shù),我們可以建立基于磁盤存儲或者基于內(nèi)存存儲的列存儲表來進(jìn)行實(shí)時數(shù)據(jù)分析。
Disk-based Tables with Nonclustered Columnstore Index
使用SQL Server 2016列存儲索引實(shí)現(xiàn)實(shí)時分析的***種方法是為表建立非聚集列存儲索引。在SQL Server 2012版本中,僅支持非聚集列存儲索引,并且表會成為只讀,而無法更新;在SQL Server 2014版本中,支持聚集列存儲索引表,且數(shù)據(jù)可更新;但是非聚集列存儲索引表還是只讀;而在SQL Server 2016中,完全支持非聚集列存儲索引和聚集列存儲索引,并且表可更新。所以,在SQL Server 2016版本中,我們完全可以建立非聚集列存儲索引來實(shí)現(xiàn)OLAP的查詢場景。創(chuàng)建方法示例如下:
- DROP TABLE IF EXISTS dbo.SalesOrder;
- GO
- CREATE TABLE dbo.SalesOrder
- (
- OrderID BIGINT IDENTITY(1,1) NOT NULL
- ,AutoID INT NOT NULL
- ,UserID INT NOT NULL
- ,OrderQty INT NOT NULL
- ,Price DECIMAL(8,2) NOT NULL
- ,OrderDate DATETIME NOT NULL
- ,OrderStatus SMALLINT NOT NULL
- CONSTRAINT PK_SalesOrder PRIMARY KEY NONCLUSTERED (OrderID)
- ) ;
- GO
- --Create the columnstore index with a filtered condition
- CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_SalesOrder
- ON dbo.SalesOrder (OrderID, AutoID, UserID, OrderQty, Price, OrderDate, OrderStatus)
- ;
- GO
在這個實(shí)例中,我們創(chuàng)建了SalesOrder表,并且為該表創(chuàng)建了非聚集列存儲索引,當(dāng)進(jìn)行OLAP查詢分析的時候,SQL Server會直接從該列存儲索引中讀取數(shù)據(jù)。
Memory-based Tables with Columnstore Index
SQL Server 2014版本引入了In-Memory OLTP,又或者叫著Hekaton,中文稱之為內(nèi)存優(yōu)化表,內(nèi)存優(yōu)化表完全是Lock Free、Latch Free的,可以***限度的增加并發(fā)和提高響應(yīng)時間。而在SQL Server 2016中,如果你的服務(wù)器內(nèi)存足夠大的話,我們完全可以建立基于內(nèi)存優(yōu)化表的列存儲索引,這樣的表數(shù)據(jù)會按列存儲在內(nèi)存中,充分利用兩者的優(yōu)勢,***程度的提高查詢查詢效率,降低數(shù)據(jù)庫響應(yīng)時間。創(chuàng)建方法實(shí)例如下:
- DROP TABLE IF EXISTS dbo.SalesOrder;
- GO
- CREATE TABLE dbo.SalesOrder
- (
- OrderID BIGINT IDENTITY(1,1) NOT NULL
- ,AutoID INT NOT NULL
- ,UserID INT NOT NULL
- ,OrderQty INT NOT NULL
- ,Price DECIMAL(8,2) NOT NULL
- ,OrderDate DATETIME NOT NULL
- ,OrderStatus SMALLINT NOT NULL
- CONSTRAINT PK_SalesOrder PRIMARY KEY NONCLUSTERED HASH (OrderID) WITH (BUCKET_COUNT = 10000000)
- ) WITH(MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA) ;
- GO
- ALTER TABLE dbo.SalesOrder
- ADD INDEX CCSI_SalesOrder CLUSTERED COLUMNSTORE
- ;
- GO
在這個實(shí)例中,我們創(chuàng)建了基于內(nèi)存的優(yōu)化表SalesOrder,持久化方案為表結(jié)構(gòu)和數(shù)據(jù);然后在這個內(nèi)存表上建立聚集列存儲索引。當(dāng)OLAP查詢分析執(zhí)行的時候,SQL Server可以直接從基于內(nèi)存的列存儲索引中獲取數(shù)據(jù),大大提高查詢分析的能力。
Minimizing impacts of OLTP
考慮到OLTP數(shù)據(jù)源的高并發(fā),低延遲要求的特性,在某些非常高并發(fā)事務(wù)場景中,我們可以采用以下方法***限度減少對OLTP的影響:
- Filtered NCCI + Clustered B-Tree Index
- Compress Delay
- Offloading OLAP to AlwaysOn Readable Secondary
- Filtered NCCI + Clustered B-Tree Index
帶過濾條件的索引在SQL Server產(chǎn)品中并不是什么全新的概念,在SQL Server 2008及以后的產(chǎn)品版本中,均支持創(chuàng)建過濾索引,這項技術(shù)允許用戶創(chuàng)建存在過濾條件的索引,以加速特定條件的查詢語句使用過濾索引。而在SQL Server 2016中支持存在過濾條件的列存儲索引,我們可以使用這項技術(shù)來區(qū)分?jǐn)?shù)據(jù)的冷熱程度(數(shù)據(jù)冷熱程度是指數(shù)據(jù)的修改頻率;冷數(shù)據(jù)是指幾乎或者很少被修改的數(shù)據(jù);熱數(shù)據(jù)是指經(jīng)常會被修改的數(shù)據(jù)。比如在訂單場景中,訂單從生成狀態(tài)到客戶收到貨物之間的狀態(tài),會被經(jīng)常更新,屬于熱數(shù)據(jù);而客人一旦收到貨物,訂單信息幾乎不會被修改了,就屬于冷數(shù)據(jù))。利用過濾列存儲索引來區(qū)分冷熱數(shù)據(jù)的技術(shù),是使用聚集B-Tree索引來存放熱數(shù)據(jù),使用過濾非聚集列存儲索引來存放冷數(shù)據(jù),這樣SQL Server 2016的優(yōu)化器可以非常智能的從非聚集列存儲索引中獲取冷數(shù)據(jù),從聚集B-Tree索引中獲取熱數(shù)據(jù),這樣使得OLAP操作與OLTP事務(wù)操作邏輯隔離開來,最終OLAP***限度的減少對OLTP的影響。
下圖直觀的表示了Filtered NCCI + Clustered B-Tree Index的結(jié)構(gòu)圖(圖片來自微軟培訓(xùn)教程):
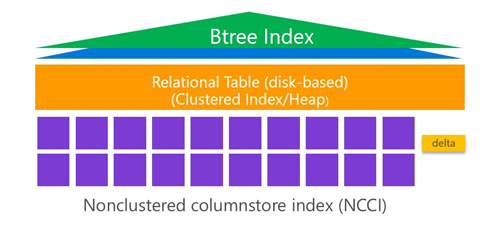
實(shí)現(xiàn)方法參見以下代碼:
- -- create demo table SalesOrder
- DROP TABLE IF EXISTS dbo.SalesOrder;
- GO
- CREATE TABLE dbo.SalesOrder
- (
- OrderID BIGINT IDENTITY(1,1) NOT NULL
- ,AutoID INT NOT NULL
- ,UserID INT NOT NULL
- ,OrderQty INT NOT NULL
- ,Price DECIMAL(8,2) NOT NULL
- ,OrderDate DATETIME NOT NULL
- ,OrderStatus SMALLINT NOT NULL
- CONSTRAINT PK_SalesOrder PRIMARY KEY NONCLUSTERED (OrderID)
- ) ;
- GO
- /*
- — OrderStatus Description
- — 0 => ‘Placed’
- — 1 => ‘Closed’
- — 2 => ‘Paid’
- — 3 => ‘Pending’
- — 4 => ‘Shipped’
- — 5 => ‘Received’
- */
- CREATE CLUSTERED INDEX CI_SalesOrder
- ON dbo.SalesOrder(OrderStatus)
- ;
- GO
- --Create the columnstore index with a filtered condition
- CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_SalesOrder
- ON dbo.SalesOrder (AutoID, Price, OrderQty, orderstatus)
- WHERE orderstatus = 5
- ;
- GO
在這個實(shí)例中,我們創(chuàng)建了SalesOrder表,并在OrderStatus字段上建立了Clustered B-Tree結(jié)構(gòu)的索引CI_SalesOrder,然后再建立了帶過濾條件的非聚集列存儲索引NCCI_SalesOrder。當(dāng)客人還未收到貨物的訂單,會處于前面五中狀態(tài),屬于需要經(jīng)常更新的熱數(shù)據(jù),SQL Server查詢會根據(jù)Clustered B-Tree索引CI_SalesOrder來查詢數(shù)據(jù);客人已經(jīng)收貨的訂單,處于第六種狀態(tài),屬于冷數(shù)據(jù),SQL Server查詢冷數(shù)據(jù)會直接從非聚集列存儲索引中獲取數(shù)據(jù)。從而***限度減少對OLTP影響的同時,提高查詢效率。
Compress Delay
如果按照業(yè)務(wù)邏輯層面很難明確劃分出數(shù)據(jù)的冷熱程度,也就是說很難從過濾條件來邏輯區(qū)分?jǐn)?shù)據(jù)的冷熱。這種情況下,我們可以使用延遲壓縮(Compress Delay)技術(shù)從時間層面來區(qū)分冷熱數(shù)據(jù)。比如:我們定義超過60分鐘的數(shù)據(jù)為冷數(shù)據(jù),60分鐘以內(nèi)的數(shù)據(jù)為熱數(shù)據(jù),那么我們可以在創(chuàng)建列存儲索引的時候添加WITH選項COMPRESSION_DELAY = 60 Minutes。當(dāng)數(shù)據(jù)產(chǎn)生超過60分鐘以后,數(shù)據(jù)會被壓縮存放到列存儲索引中(冷數(shù)據(jù)),60分鐘以內(nèi)的數(shù)據(jù)會駐留在Delta Store的B-Tree結(jié)構(gòu)中,這種延遲壓縮的技術(shù)不但能夠達(dá)到隔離OLAP對OLTP作用,還能***限度的減少列存儲索引碎片的產(chǎn)生。
實(shí)現(xiàn)方法參見以下例子:
- -- create demo table SalesOrder
- DROP TABLE IF EXISTS dbo.SalesOrder;
- GO
- CREATE TABLE dbo.SalesOrder
- (
- OrderID BIGINT IDENTITY(1,1) NOT NULL
- ,AutoID INT NOT NULL
- ,UserID INT NOT NULL
- ,OrderQty INT NOT NULL
- ,Price DECIMAL(8,2) NOT NULL
- ,OrderDate DATETIME NOT NULL
- ,OrderStatus SMALLINT NOT NULL
- CONSTRAINT PK_SalesOrder PRIMARY KEY NONCLUSTERED (OrderID)
- ) ;
- GO
- --Create the columnstore index with a filtered condition
- CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_SalesOrder
- ON dbo.SalesOrder (AutoID, Price, OrderQty, orderstatus)
- WITH(COMPRESSION_DELAY = 60 MINUTES)
- ;
- GO
- SELECT name
- ,type_desc
- ,compression_delay
- FROM sys.indexes
- WHERE object_id = object_id('SalesOrder')
- AND name = 'NCCI_SalesOrder'
- ;
檢查索引信息截圖如下:
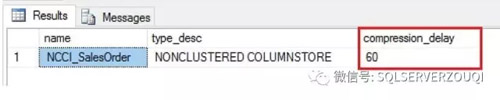
Offloading OLAP to AlwaysOn Readable Secondary
另外一種減少OLAP對OLTP影響的方法是利用AlwaysOn只讀副本,這種情況,可以將OLAP數(shù)據(jù)源從OLTP剝離出來,接入到AlwaysOn的只讀副本上。AlwaysOn的主副本負(fù)責(zé)事務(wù)處理,只讀副本可以作為OLAP的數(shù)據(jù)分析源,這樣實(shí)現(xiàn)了OLAP與OLTP的物理隔離,將影響減到***。架構(gòu)圖如下所示(圖片來自微軟培訓(xùn)教程):
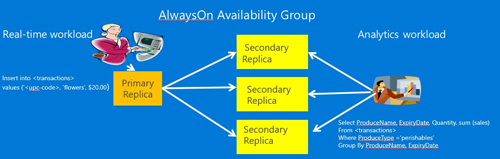
一個實(shí)際例子
在訂單系統(tǒng)場景中,用戶收到貨物過程,每個訂單會經(jīng)歷6中狀態(tài),假設(shè)為Placed、Canceled、Paid、Pending、Shipped和Received。在前面5中狀態(tài)的訂單,會被經(jīng)常修改,比如:打包訂單,出庫,更新快遞信息等,這部分經(jīng)常被修改的數(shù)據(jù)稱為熱數(shù)據(jù);而訂單一旦被客人接受以后,訂單數(shù)據(jù)就幾乎不會被修改,這部分?jǐn)?shù)據(jù)稱為冷數(shù)據(jù)。這個例子就是使用SQL Server 2016 Filtered NCCI + Clustered B-Tree索引的方式來邏輯劃分出數(shù)據(jù)的冷熱程度,SQL Server在查詢過程中,會從非聚集列存儲索引中取冷數(shù)據(jù),從B-Tree索引中取熱數(shù)據(jù),***限度提高OLAP查詢效率,減少對OLTP的影響。
具體建表代碼實(shí)現(xiàn)如下:
- -- create demo table SalesOrder
- DROP TABLE IF EXISTS dbo.SalesOrder;
- GO
- CREATE TABLE dbo.SalesOrder
- (
- OrderID BIGINT IDENTITY(1,1) NOT NULL
- ,AutoID INT NOT NULL
- ,UserID INT NOT NULL
- ,OrderQty INT NOT NULL
- ,Price DECIMAL(8,2) NOT NULL
- ,OrderDate DATETIME NOT NULL
- ,OrderStatus SMALLINT NOT NULL
- CONSTRAINT PK_SalesOrder PRIMARY KEY NONCLUSTERED (OrderID)
- ) ;
- GO
- /*
- — OrderStatus Description
- — 0 => ‘Placed’
- — 1 => ‘Closed’
- — 2 => ‘Paid’
- — 3 => ‘Pending’
- — 4 => ‘Shipped’
- — 5 => ‘Received’
- */
- CREATE CLUSTERED INDEX CI_SalesOrder
- ON dbo.SalesOrder(OrderStatus)
- ;
- GO
- --Create the columnstore index with a filtered condition
- CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_SalesOrder
- ON dbo.SalesOrder (AutoID, Price, OrderQty, orderstatus)
- WHERE orderstatus = 5
- ;
- GO
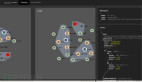
為了能夠直觀的看到利用SQL Server 2016列存儲索引實(shí)現(xiàn)實(shí)時分析的效果,我虛擬了一個網(wǎng)絡(luò)汽車銷售訂單系統(tǒng),使用NodeJs + SQL Server 2016 Columnstore Index + Socket.IO來實(shí)現(xiàn)實(shí)時訂單銷量和銷售收入的分析頁面。
總結(jié)
這篇文章講解利用SQL Server 2016列存儲索引技術(shù)實(shí)現(xiàn)數(shù)據(jù)實(shí)時分析的兩種方法,以解決傳統(tǒng)RDBMS數(shù)據(jù)分析的高延遲、高成本的痛點(diǎn)。***種方法是Hekaton + Clustered Columnstore Index;第二種方法是Filtered Nonclustered Columnstore Index + Clustered B-Tree。本文并以此理論為基礎(chǔ),展示了一個網(wǎng)絡(luò)汽車在線銷售系統(tǒng)的實(shí)時訂單分析頁面。