8種優(yōu)秀預訓練模型大盤點,NLP應用so easy!
大數(shù)據(jù)文摘出品
編譯:李雷、蔡婕
如今,自然語言處理(NLP)可謂遍地開花,可以說正是我們了解它的好時機。
NLP的快速增長主要得益于通過預訓練模型實現(xiàn)轉(zhuǎn)移學習的概念。在NLP中,轉(zhuǎn)移學習本質(zhì)上是指在一個數(shù)據(jù)集上訓練模型,然后調(diào)整該模型以便在不同數(shù)據(jù)集上實現(xiàn)NLP的功能。
這一突破使NLP應用變得如此簡單,尤其是那些沒有時間或資源從頭開始構建NLP模型的人。或者,對于想要學習或者從其他領域過渡到NLP的新手來說,這簡直就是完美。
一、為什么要使用預訓練模型?
模型的作者已經(jīng)設計出了基準模型,這樣我們就可以在自己的NLP數(shù)據(jù)集上使用該預訓練模型,而無需從頭開始構建模型來解決類似的問題
盡管需要進行一些微調(diào),但這為我們節(jié)省了大量的時間和計算資源
在本文中展示了那些助你開始NLP之旅的頂級預訓練模型,以及該領域的最新研究成果。要查看關于計算機視覺中的頂級預訓練模型的文章,請參閱:
https://www.analyticsvidhya.com/blog/2018/07/top-10-pretrained-models-get-started-deep-learning-part-1-computer-vision/?utm_source=blog&utm_medium=top-pretrained-models-nlp-article
二、本文涵蓋的NLP預訓練模型
我根據(jù)應用場景將預訓練模型分為三類:
多用途NLP模型
- ULMFiT
- Transformer
- 谷歌的BERT
- Transformer-XL
- OpenAI的GPT-2
詞嵌入NLP模型
- ELMo
- Flair
其他預訓練模型
- StanfordNLP
多用途NLP模型
多用途模型在NLP領域里一直為人們所關注。這些模型為提供了許多令人感興趣的NLP應用 - 機器翻譯、問答系統(tǒng)、聊天機器人、情感分析等。這些多用途NLP模型的核心是語言建模的理念。
簡單來說,語言模型的目的是預測語句序列中的下一個單詞或字符,在我們了解各模型時就會明白這一點。
如果你是NLP愛好者,那么一定會喜歡現(xiàn)在這部分,讓我們深入研究5個最先進的多用途NLP模型框架。這里我提供了每種模型的研究論文和預訓練模型的鏈接,來探索一下吧!
1. ULMFiT模型
ULMFiT由fast.ai(深度學習網(wǎng)站)的Jeremy Howard和DeepMind(一家人工智能企業(yè))的Sebastian Ruder提出并設計。可以這么說,ULMFiT開啟了轉(zhuǎn)移學習的熱潮。
正如我們在本文中所述,ULMFiT使用新穎的NLP技術取得了令人矚目的成果。該方法對預訓練語言模型進行微調(diào),將其在WikiText-103數(shù)據(jù)集(維基百科的長期依賴語言建模數(shù)據(jù)集Wikitext之一)上訓練,從而得到新數(shù)據(jù)集,通過這種方式使其不會忘記之前學過的內(nèi)容。
ULMFiT比許多先進的文本分類模型還要好。我喜愛ULMFiT是因為它只需要很少的數(shù)據(jù)就可以來產(chǎn)生令人印象深刻的結果,使我們更容易理解并在機器上實現(xiàn)它!
也許你不知道ULMFiT其實是Universal Language Model Fine-Tuning(通用語言模型微調(diào))的簡稱。“通用”一詞在這里非常貼切 - 該框架幾乎可以應用于任何NLP任務。
想知道有關ULMFiT的更多信息,請參閱以下文章和論文:
- 使用ULMFiT模型和Python 的fastai庫進行文本分類(NLP)教程:https://www.analyticsvidhya.com/blog/2018/11/tutorial-text-classification-ulmfit-fastai-library/?utm_source=blog&utm_medium=top-pretrained-models-nlp-article
- ULMFiT的預訓練模型論文:https://www.paperswithcode.com/paper/universal-language-model-fine-tuning-for-text
- 其他研究論文:https://arxiv.org/abs/1801.06146
2. Transformer模型
Transformer架構是NLP近期最核心的發(fā)展,2017年由谷歌提出。當時,用于語言處理任務(如機器翻譯和問答系統(tǒng))的是循環(huán)神經(jīng)網(wǎng)絡(RNN)。
Transformer架構的性能比RNN和CNN(卷積神經(jīng)網(wǎng)絡)要好,訓練模型所需的計算資源也更少,這對于每個使用NLP的人來說都是雙贏。看看下面的比較:
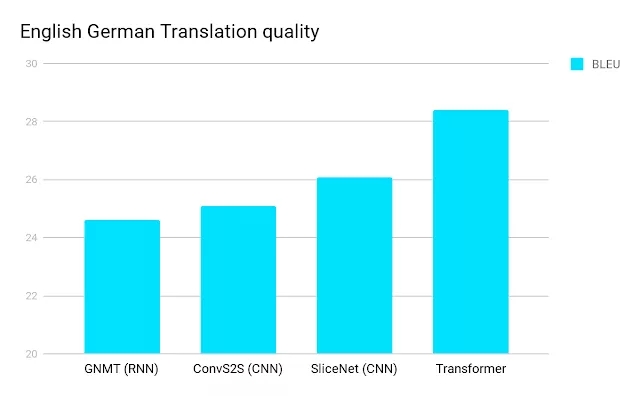
各模型的英德翻譯質(zhì)量
根據(jù)Google的說法,Transformer模型“應用了一種自注意力機制,可直接模擬句子中所有單詞之間的關系,而無需理會其各自的位置如何”。它使用固定長度上下文(也就是前面的單詞)來實現(xiàn)。太復雜了?沒事,我們舉一例子簡單說明。
有句話“She found the shells on the bank of the river.”此時模型需要明白,這里的“bank”是指岸邊,而不是金融機構(銀行)。Transformer模型只需一步就能理解這一點。我希望你能閱讀下面鏈接的完整論文,以了解其工作原理。它肯定會讓你大吃一驚。
下面的動畫很好地說明了Transformer如何處理機器翻譯任務:
谷歌去年發(fā)布了一款名為Universal Transformer的改進版Transformer模型。它還有一個更新,更直觀的名字,叫Transformer-XL,我們將在后面介紹。
想學習和閱讀更多有關Transformer的信息,請訪問:
- 谷歌官方博文:https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
- Transformer預訓練模型論文《Attention Is All You Need》:https://www.paperswithcode.com/paper/attention-is-all-you-need
- 其他研究論文:https://arxiv.org/abs/1706.03762
3. BERT模型(谷歌)
谷歌發(fā)布BERT框架并開放其源代碼在業(yè)界掀起波瀾,甚至有人認為這是否標志著“ NLP新時代”的到來。但至少有一點可以肯定,BERT是一個非常有用的框架,可以很好地推廣到各種NLP任務中。

BERT是Bidirectional Encoder Representations(雙向編碼器表征)的簡稱。這個模型可以同時考慮一個詞的兩側(cè)(左側(cè)和右側(cè))上下文,而以前的所有模型每次都是只考慮詞的單側(cè)(左側(cè)或右側(cè))上下文。這種雙向考慮有助于模型更好地理解單詞的上下文。此外,BERT可以進行多任務學習,也就是說,它可以同時執(zhí)行不同的NLP任務。
BERT是首個無監(jiān)督的、深度雙向預訓練NLP模型,僅使用純文本語料庫進行訓練。
在發(fā)布時,谷歌稱BERT進行了11個自然語言處理(NLP)任務,并產(chǎn)生高水平的結果,這一壯舉意義深遠!你可以在短短幾個小時內(nèi)(在單個GPU上)使用BERT訓練好自己的NLP模型(例如問答系統(tǒng))。
想獲得更多有關BERT的資源,請參閱:
- 谷歌官方博文:https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
- BERT預訓練模型論文:https://www.paperswithcode.com/paper/bert-pre-training-of-deep-bidirectional#code
- 其他研究論文:https://arxiv.org/pdf/1810.04805.pdf
4. Transformer-XL模型(谷歌)
從長期來看,谷歌發(fā)布的版本對NLP而言是非常重要的。如果你是初學者,這個概念可能會有點棘手,所以我鼓勵你多讀幾遍來掌握它。我還在本節(jié)下面提供了多種資源來幫助你開始使用Transformer-XL。
想象一下——你剛讀到一本書的一半,突然出現(xiàn)了這本書開頭提到的一個詞或者一句話時,就能回憶起那是什么了。但可以理解,機器很難建立長期的記憶模型。
如上所述,要達成這個目的的一種方法是使用Transformers,但它們是在固定長度的上下文中實現(xiàn)的。換句話說,如果使用這種方法,就沒有太大的靈活性。
Transformer-XL很好地彌補了這個差距。它由Google AI團隊開發(fā),是一種新穎的NLP架構,能夠幫助機器理解超出固定長度限制的上下文。Transformer-XL的推理速度比傳統(tǒng)的Transformer快1800倍。
通過瀏覽下面谷歌發(fā)布的兩個gif文件,你就會明白這其中的區(qū)別:
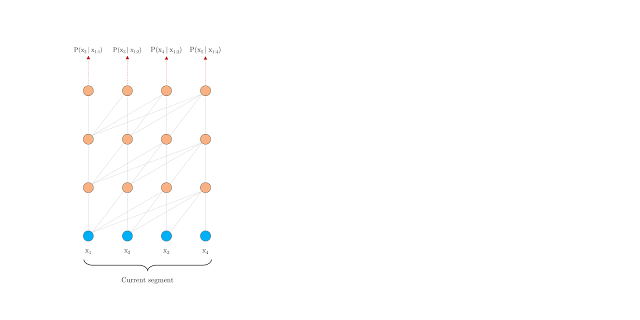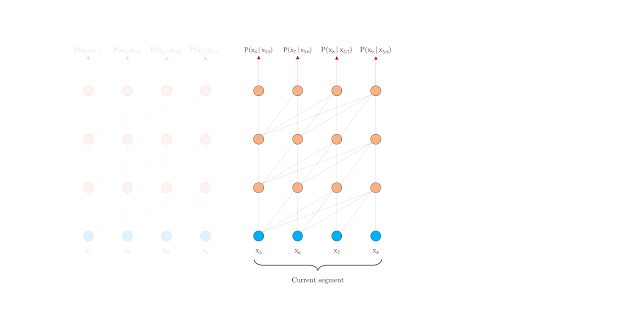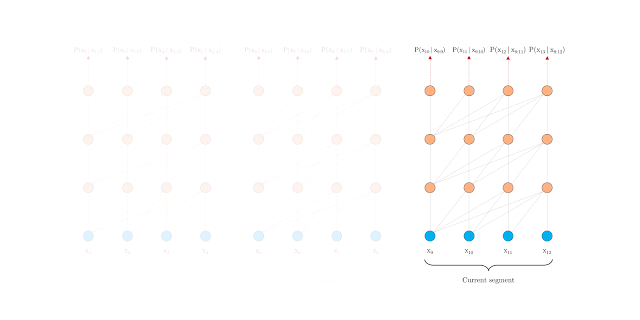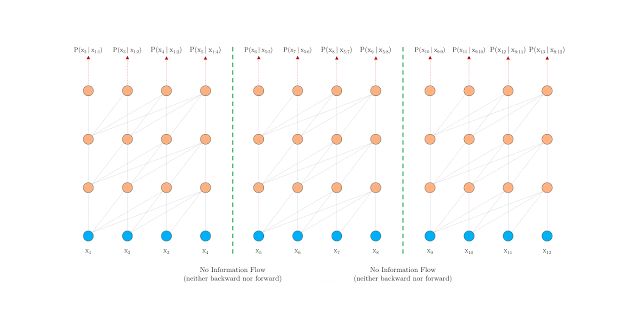
正如你現(xiàn)在可能已經(jīng)預測到的,Transformer-XL在各種語言建模基準/數(shù)據(jù)集上取得了最新的技術成果。以下是他們頁面上的一個小表格,說明了這一點:

之前給過鏈接并將在下面提到的Transformer-XL GitHub存儲庫包含了PyTorch和TensorFlow中的代碼。
學習和閱讀更多Transformer-XL有關信息的資源:
- 谷歌的官方博客文章:https://ai.googleblog.com/2019/01/transformer-xl-unleashing-potential-of.html
- Transformer-XL的預訓練模型:https://www.paperswithcode.com/paper/transformer-xl-attentive-language-models
- 研究論文:https://arxiv.org/abs/1901.02860
5. GPT-2模型(OpenAI)
這是一個十分有爭議的模型,一些人會認為GPT-2的發(fā)布是OpenAI的營銷噱頭。我可以理解他們的想法,但是我認為至少應該要先對OpenAI發(fā)布的代碼進行嘗試。

首先,為那些不知道我在說什么的人提供一些背景信息。OpenAI在2月份發(fā)表了一篇博客文章,他們聲稱已經(jīng)設計了一個名為GPT-2的NLP模型,這個模型非常好,以至于擔心被惡意使用而無法發(fā)布完整的版本,這當然引起了社會的關注。
GPT-2經(jīng)過訓練,可以用來預測40GB的互聯(lián)網(wǎng)文本數(shù)據(jù)中的下一個出現(xiàn)的詞。 該框架也是一個基于transformer的模型,而這個模型是基于800萬個web頁面的數(shù)據(jù)集來進行訓練。他們在網(wǎng)站上發(fā)布的結果簡直令人震驚,因為該模型能夠根據(jù)我們輸入的幾個句子編寫出一個完整的故事。看看這個例子:

難以置信,是吧?
開發(fā)人員已經(jīng)發(fā)布了一個更小版本的GPT-2,供研究人員和工程師測試。原始模型有15億個參數(shù)——開放源碼示例模型有1.17億個參數(shù)。
學習和閱讀更多GPT-2有關信息的資源:
- OpenAI的官方博客文章:https://openai.com/blog/better-language-models/
- GPT-2的預訓練模型:https://github.com/openai/gpt-2
- 研究論文:https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
詞嵌入(word embedding)模型
我們使用的大多數(shù)機器學習和深度學習算法都無法直接處理字符串和純文本。這些技術要求我們將文本數(shù)據(jù)轉(zhuǎn)換為數(shù)字,然后才能執(zhí)行任務(例如回歸或分類)。
因此簡單來說, 詞嵌入(word embedding)是文本塊,這些文本塊被轉(zhuǎn)換成數(shù)字以用于執(zhí)行NLP任務。詞嵌入(word embedding)格式通常嘗試使用字典將單詞映射到向量。
你可以在下面的文章中更深入地了解word embedding、它的不同類型以及如何在數(shù)據(jù)集中使用它們。如果你不熟悉這個概念,我認為本指南必讀:
對詞嵌入的直觀理解:從計算向量到Word2Vec:
https://www.analyticsvidhya.com/blog/2019/03/pretrained-models-get-started-nlp/
在本節(jié)中,我們將介紹NLP的兩個最先進的詞嵌入(word embedding)。我還提供了教程鏈接,以便你可以對每個主題有實際的了解。
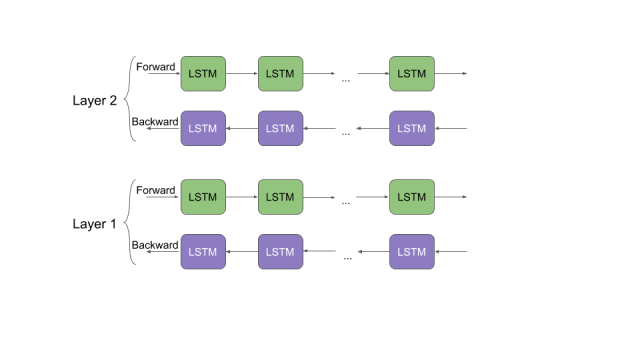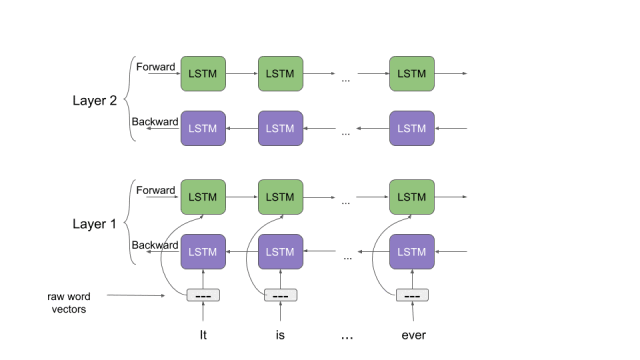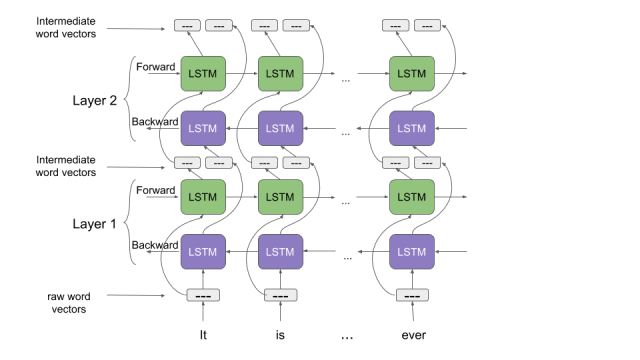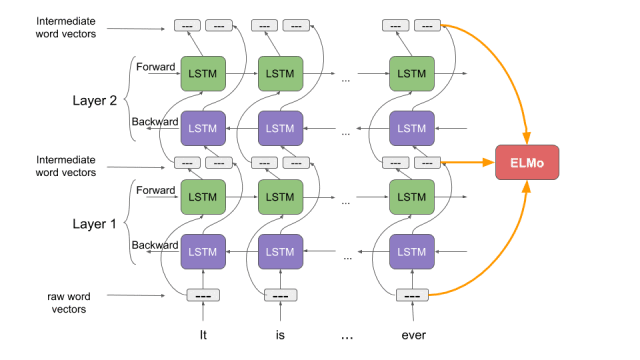
6. ELMo模型
這個ELMo并不是《芝麻街》里的那個角色,但是這個ELMo(Embeddings from Language Models(語言模型嵌入)的縮寫)在構建NLP模型的上下文中非常有用。
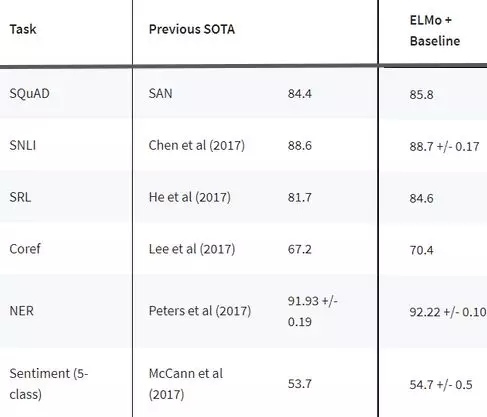
ELMo是一種用向量和嵌入表示單詞的新方法。這些ELMo 詞嵌入(word embedding)幫助我們在多個NLP任務上實現(xiàn)最先進的結果,如下圖所示:
讓我們花點時間來了解一下ELMo是如何工作的。回想一下我們之前討論過的雙向語言模型。從這篇文章中我們能夠得到提示,“ELMo單詞向量是在雙層雙向語言模型(biLM)的基礎上進行計算的。這個biLM模型有兩層疊加在一起,每一層都有2個通道——前向通道和后向通道:
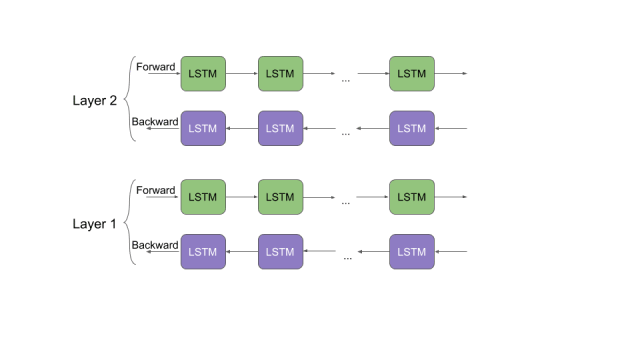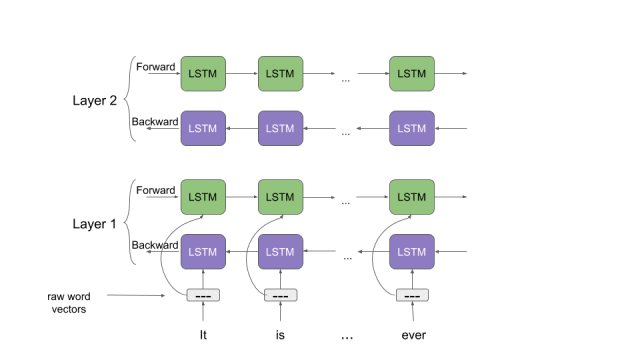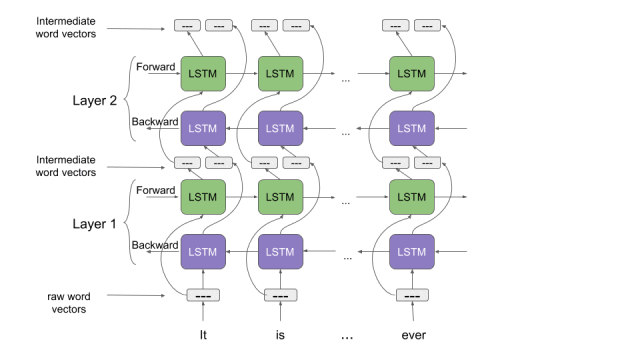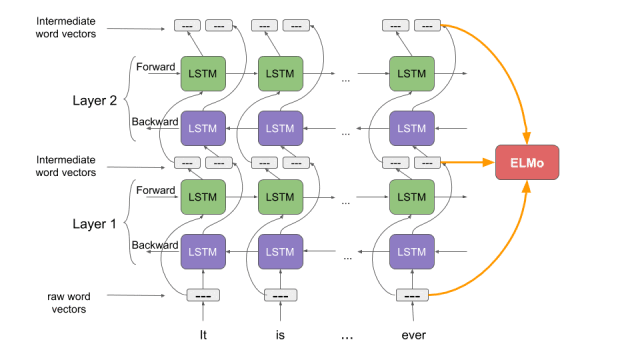
ELMo單詞表示考慮計算詞嵌入(word embedding)的完整輸入語句。因此,“read”這單詞在不同的上下文中具有不同的ELMo向量。這與舊版的詞嵌入(word embedding)大不相同,舊版中無論在什么樣的上下文中使用單詞“read”,分配給該單詞的向量是相同的。
學習和閱讀更多ELMo有關信息的資源:
- 循序漸進的NLP指南,了解ELMo從文本中提取特征:https://www.analyticsvidhya.com/blog/2019/03/learn-to-use-elmo-to-extract-features-from-text/?utm_source=blog&utm_medium=top-pretrained-models-nlp-article
- 預訓練模型的GitHub存儲庫:https://github.com/allenai/allennlp/blob/master/tutorials/how_to/elmo.md
- 研究論文:https://arxiv.org/pdf/1802.05365.pdf
7. Flair模型
Flair不是一個詞嵌入(word embedding),而是它的組合。我們可以將Flair稱為結合了GloVe、BERT與ELMo等嵌入方式的NLP庫。Zalando Research的優(yōu)秀員工已經(jīng)開發(fā)了開源的Flair。

該團隊已經(jīng)為以下NLP任務發(fā)布了幾個預訓練模型:
- 名稱 - 實體識別(NER)
- 詞性標注(PoS)
- 文本分類
- 培訓定制模型
不相信嗎?那么,這個對照表會幫你找到答案:
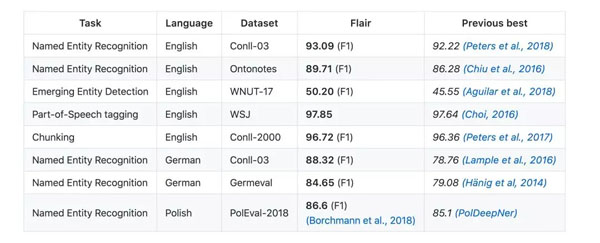
“Flair Embedding”是Flair庫中打包的簽名嵌入,它由上下文字符串嵌入提供支持。了解支持Flair的核心組件可以閱讀這篇文章:
https://www.analyticsvidhya.com/blog/2019/02/flair-nlp-library-python/?utm_source=blog&utm_medium=top-pretrained-models-nlp-article
我特別喜歡Flair的地方是它支持多種語言,而這么多的NLP發(fā)行版大多都只有英文版本。如果NLP要在全球獲得吸引力,我們需要在此基礎上進行擴展。
學習和閱讀更多有關Flair的資源:
- Flair for NLP簡介:一個簡單但功能強大的最先進的NLP庫:https://www.analyticsvidhya.com/blog/2019/02/flair-nlp-library-python/?utm_source=blog&utm_medium=top-pretrained-models-nlp-article
- Flair的預訓練模型:https://github.com/zalandoresearch/flair
8. 其他預訓練模型:StanfordNLP (斯坦福)

提到擴展NLP使其不局限于英語,這里有一個已經(jīng)實現(xiàn)該目的的庫——StanfordNLP。其作者聲稱StanfordNLP支持超過53種語言,這當然引起了我們的注意。
我們的團隊是第一批使用該庫并在真實數(shù)據(jù)集上發(fā)布結果的團隊之一。我們通過嘗試,發(fā)現(xiàn)StanfordNLP確實為在非英語語言上應用NLP技術提供了很多可能性,比如印地語、漢語和日語。
StanfordNLP是一系列經(jīng)過預先訓練的最先進的NLP模型的集合。這些模型不僅是在實驗室里進行測試——作者在2017年和2018年的CoNLL競賽中都使用了這些模型。在StanfordNLP中打包的所有預訓練NLP模型都是基于PyTorch構建的,可以在你自己的注釋數(shù)據(jù)上進行訓練和評估。
我們認為你應該考慮使用StanfordNLP的兩個主要原因是:
用于執(zhí)行文本分析的完整神經(jīng)網(wǎng)絡管道,包括。
- 標記化
- 多字令牌(MWT)拓展
- 詞形還原
- 詞性(POS)和詞形特征標記
- 依存語法分析
穩(wěn)定的Stanford CoreNLP軟件的官方Python接口。
學習和閱讀更多StanfordNLP有關信息的資源:
- StanfordNLP簡介:一個不可思議的支持53種語言的最先進NLP庫 (使用Python代碼):https://www.analyticsvidhya.com/blog/2019/02/stanfordnlp-nlp-library-python/?utm_source=blog&utm_medium=top-pretrained-models-nlp-article
- StanfordNLP的預訓練模型:https://github.com/stanfordnlp/stanfordnlp
尾注
這絕不是一個預訓練NLP模型的詳盡列表,有更多能用的可以在這個網(wǎng)站上找到:https://paperswithcode.com
以下是學習NLP的一些有用資源:
- 使用Python課程進行自然語言處理https://courses.analyticsvidhya.com/courses/natural-language-processing-nlp?utm_source=blog&utm_medium=top-pretrained-models-nlp-article
- 認證項目:NLP初學者https://courses.analyticsvidhya.com/bundles/nlp-combo?utm_source=blog&utm_medium=top-pretrained-models-nlp-article
- 自然語言處理(NLP)系列文章https://www.analyticsvidhya.com/blog/category/nlp/?utm_source=blog&utm_medium=top-pretrained-models-nlp-article
我很想聽聽你對這份清單的看法。你以前用過這些預訓練過的模型嗎?或者你已經(jīng)探索過其他的模型?請在下面的評論區(qū)告訴我——我很樂意搜索它們并添加到這個列表中。
相關報道:
https://www.analyticsvidhya.com/blog/2019/03/pretrained-models-get-started-nlp/
【本文是51CTO專欄機構大數(shù)據(jù)文摘的原創(chuàng)譯文,微信公眾號“大數(shù)據(jù)文摘( id: BigDataDigest)”】