具有前景的深度學習工具一覽
解決問題往往需要大量工具的支持,深度學習也不例外。要說真有什么區(qū)別的話,那就是在不遠的將來,用好這一領域的工具將愈發(fā)重要。
深度學習雖是一顆冉冉升起的“超新星”,但目前仍處于發(fā)展初期,許多該領域的工程師與有志之士正為深度學習的高效化進程而拼搏奮斗。除了人才輩出,我們還見證著越來越多深度學習工具的誕生,它們有助于推進深度學習曲折的發(fā)展進程,增加其便利性與高效性。
深度學習正逐漸從學者專家的理論研究邁向一個更為廣闊的世界,在那里,深度學習愛好者想要投身該領域(便利性),越來越多的工程小組想要簡化運作流程,化繁為簡(高效性)。隨著這一進程的發(fā)展,我們也整理出了一份***深度學習工具圖表。
研究深度學習生命周期
要想對高效便捷的深度學習工具做出更好的評估,我們應先了解下深度學習周期的大致情況。(有監(jiān)督)深度學習應用的生命周期包括多個不同步驟,始于原始數(shù)據(jù),終于實況預測。
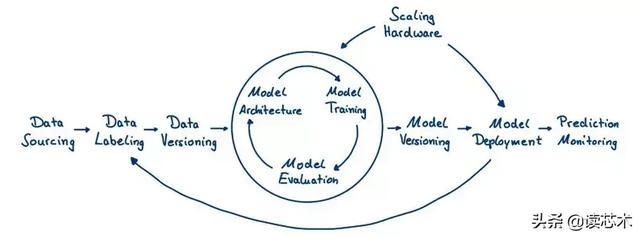
典型的深度學習生命周期© 2018 Luminovo
數(shù)據(jù)來源
任何深度學習技術應用的***步都是確定正確信息的來源。如果幸運的話,你會輕而易舉地找到可用的歷史數(shù)據(jù)。否則,你要搜索開源數(shù)據(jù)集,在網(wǎng)頁中提取信息,購買原始數(shù)據(jù)或使用模擬數(shù)據(jù)集。鑒于該步驟要視手頭所擁有的具體技術應用而定,我們便未將其列入文末的工具圖表中。不過請注意,谷歌數(shù)據(jù)集搜索或Fast.ai數(shù)據(jù)等網(wǎng)站會幫助我們省去不少麻煩。
數(shù)據(jù)標注
許多監(jiān)督深度學習技術應用涉及對圖片、視頻、文本與音像的處理。在進行模式訓練前,要用真值(真實的有效值)來標注原始數(shù)據(jù)(未處理數(shù)據(jù))。數(shù)據(jù)標注高成本,高耗時。
在一個理想的安裝程序中,數(shù)據(jù)標注往往與模型訓練與模型部署緊密相連,并盡可能(雖然目前效果不盡如人意)地對深度學習訓練模型做出調節(jié)。
數(shù)據(jù)版本
(假設你有個智能標注處理流程,隨著數(shù)據(jù)集的增長,模型也得到不斷地重訓)數(shù)據(jù)會隨時間推移而演變,而時間過得越久,對數(shù)據(jù)集的版本更新就愈發(fā)重要(這和經(jīng)常更新代碼和訓練模型是一個道理)。
硬件規(guī)模
對模型訓練與模型部署來說,有一點很重要——采用適當?shù)挠布?guī)模。在模型訓練從本地服務器發(fā)展到大規(guī)模實驗這一過程中,硬件的規(guī)模也需要做出適當調整。這就和部署模型時要根據(jù)用戶需求來調整硬件規(guī)模是一個道理。
模型結構
想要開始模型訓練,需要選擇一個神經(jīng)網(wǎng)絡模型結構。
提醒:如果你有一個標準問題(例如找出網(wǎng)絡上與貓有關的表情包),這就意味著只需要在GitHub開源代碼庫中找出一個***進的模型直接照搬即可,不過有的時候為了改善性能,要親自動手調整自己的模型結構。隨著諸如神經(jīng)網(wǎng)絡架構搜索(Neural Architecture Search)等新途徑的出現(xiàn),選擇合適的模型架構逐漸并入模型訓練這一步驟,不過對于2018年大部分技術應用來說,使用NAS的性價比并不夠高。
一想到深度學習技術應用的編碼,人們首先想到的往往就是模型結構這一步驟,但是這只是深度學習運行周期中區(qū)區(qū)一環(huán)而已,并且通常而言,這還不是最重要的一環(huán)。
模型訓練
在模型訓練中,所標注數(shù)據(jù)需錄入神經(jīng)網(wǎng)絡,并通過迭代來更新權值(即參數(shù)),以此實現(xiàn)損失(函數(shù))的最小化。一旦確定了一個指標,便可用很多組不同的超參數(shù)(如學習率、模型架構與可選預處理步驟)來訓練模型,這個過程便叫做超參數(shù)調優(yōu)。
模型評價
如果你不能甄別模型的好壞,那訓練神經(jīng)網(wǎng)絡無從談起。在模型評價中,你通常會選擇一個指標對其優(yōu)化(同時你也可以觀測許多不同的指標)。對于這個指標,你通常會找出一個***建模,它可以從訓練數(shù)據(jù)推廣到驗證數(shù)據(jù)。而這需要跟蹤記錄不同的實驗數(shù)據(jù)(不同的超參數(shù)、模型結構與數(shù)據(jù)集)與性能指標,實現(xiàn)訓練模型的輸出可視化并將各個實驗進行比對。
如果沒有合適的工具予以輔助,尤其是在許多工程師采用同樣的深度學習數(shù)據(jù)管道進行作業(yè)時,這個過程很快便會變得盤根錯節(jié),撲朔迷離。
模型版本管理
這是在模型評價和模型部署之間的一個小環(huán)節(jié)(但仍值得一提):給不同版本下的模型添上標識符。在***版本沒有達到你的預期時,你可以通過這個標識符輕松返回到上一個運行正常的版本。
模型部署
如果你愿意將模型版本投入生產,那需要對該模型做出部署,使其與用戶(人或另一個應用)實現(xiàn)交互:用戶能對其發(fā)送數(shù)據(jù)請求并收到模型做出的預測。理論上來說,模型部署工具支持不同版本的漸進性變化,因此你可以預測出新投入生產模型的運行效果。
監(jiān)控預測
一旦模型部署完成,你肯定會想密切關注模型的實地預測數(shù)據(jù),時刻留意其數(shù)據(jù)發(fā)布與運行性能,以防用戶在發(fā)現(xiàn)模型出問題后上門投訴。
提醒:上面提到的流程圖已反映出深度學習這一工作流程的循環(huán)特性。實際上,深度學習應用要想成功,要點之一就是將所部署模型與新添加的標記之間構成的反饋回路(即人機回圈)視為深度學習工作流程中的重中之重。
與流程圖上描述的相比,現(xiàn)實中深度學習的運行要復雜得多。你會發(fā)現(xiàn)深度學習的運行出現(xiàn)很多問題:“一躍千里”(比如處理預處理數(shù)據(jù)集時跳步驟),“重蹈覆轍”(模型性能數(shù)據(jù)不夠準確,因此你需要搜集更多的數(shù)據(jù)),“鬼打墻”(陷入一個死循環(huán),如建模——訓練——評價——訓練——評價——建模)。
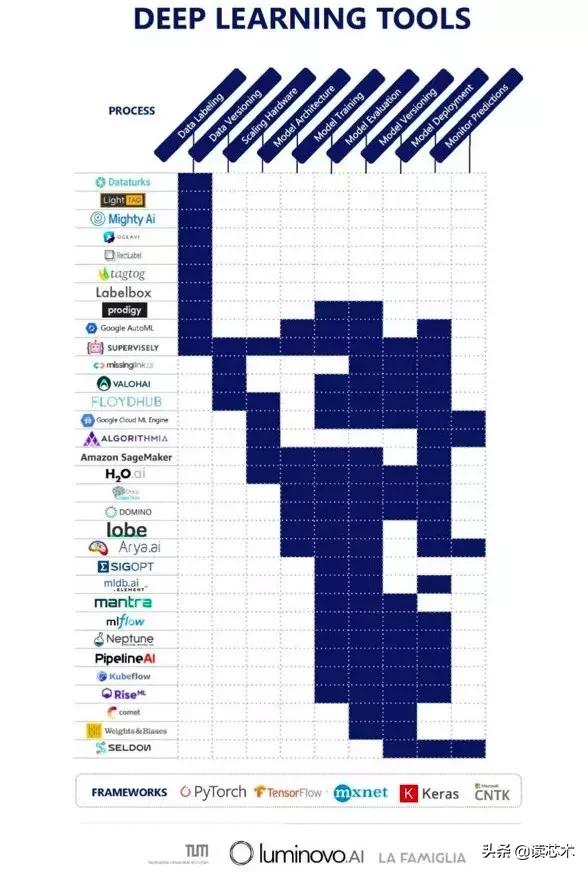
強推——深度學習工具一覽
知識貴在分享,下面的圖表簡要地列舉了當今市場***前景的深度學習工具。這些工具由深度學習工程師所研制,惠及所有樂于為深度學習這一超贊技術添磚加瓦的同道中人。