??[[266327]]
??
人工智能結(jié)合開源硬件工具能夠提升嚴(yán)重傳染病瘧疾的診斷。
人工智能(AI)和開源工具、技術(shù)和框架是促進(jìn)社會(huì)進(jìn)步的強(qiáng)有力的結(jié)合。“健康就是財(cái)富”可能有點(diǎn)陳詞濫調(diào),但它卻是非常準(zhǔn)確的!在本篇文章,我們將測(cè)試 AI 是如何與低成本、有效、精確的開源深度學(xué)習(xí)方法結(jié)合起來一起用來檢測(cè)致死的傳染病瘧疾。
我既不是一個(gè)醫(yī)生,也不是一個(gè)醫(yī)療保健研究者,我也絕不像他們那樣合格,我只是對(duì)將 AI 應(yīng)用到醫(yī)療保健研究感興趣。在這片文章中我的想法是展示 AI 和開源解決方案如何幫助瘧疾檢測(cè)和減少人工勞動(dòng)的方法。
??
??
Python 和 TensorFlow: 一個(gè)構(gòu)建開源深度學(xué)習(xí)方法的很棒的結(jié)合
感謝 Python 的強(qiáng)大和像 TensorFlow 這樣的深度學(xué)習(xí)框架,我們能夠構(gòu)建健壯的、大規(guī)模的、有效的深度學(xué)習(xí)方法。因?yàn)檫@些工具是自由和開源的,我們能夠構(gòu)建非常經(jīng)濟(jì)且易于被任何人采納和使用的解決方案。讓我們開始吧!
項(xiàng)目動(dòng)機(jī)
瘧疾是由瘧原蟲造成的致死的、有傳染性的、蚊子傳播的疾病,主要通過受感染的雌性按蚊叮咬傳播。共有五種寄生蟲能夠引起瘧疾,但是大多數(shù)病例是這兩種類型造成的:惡性瘧原蟲和間日瘧原蟲。
這個(gè)地圖顯示了瘧疾在全球傳播分布形勢(shì),尤其在熱帶地區(qū),但疾病的性質(zhì)和致命性是該項(xiàng)目的主要?jiǎng)訖C(jī)。
如果一只受感染雌性蚊子叮咬了你,蚊子攜帶的寄生蟲進(jìn)入你的血液,并且開始破壞攜帶氧氣的紅細(xì)胞(RBC)。通常,瘧疾的最初癥狀類似于流感病毒,在蚊子叮咬后,他們通常在幾天或幾周內(nèi)發(fā)作。然而,這些致死的寄生蟲可以在你的身體里生存長達(dá)一年并且不會(huì)造成任何癥狀,延遲治療可能造成并發(fā)癥甚至死亡。因此,早期的檢查能夠挽救生命。
世界健康組織(WHO)的??瘧疾實(shí)情??表明,世界近乎一半的人口面臨瘧疾的風(fēng)險(xiǎn),有超過 2 億的瘧疾病例,每年由于瘧疾造成的死亡將近 40 萬。這是使瘧疾檢測(cè)和診斷快速、簡單和有效的一個(gè)動(dòng)機(jī)。
檢測(cè)瘧疾的方法
有幾種方法能夠用來檢測(cè)和診斷瘧疾。該文中的項(xiàng)目就是基于 Rajaraman, et al. 的論文:“??預(yù)先訓(xùn)練的卷積神經(jīng)網(wǎng)絡(luò)作為特征提取器,用于改善薄血涂片圖像中的瘧疾寄生蟲檢測(cè)??”介紹的一些方法,包含聚合酶鏈反應(yīng)(PCR)和快速診斷測(cè)試(RDT)。這兩種測(cè)試通常用于無法提供高質(zhì)量顯微鏡服務(wù)的地方。
標(biāo)準(zhǔn)的瘧疾診斷通常是基于血液涂片工作流程的,根據(jù) Carlos Ariza 的文章“??Malaria Hero:一個(gè)更快診斷瘧原蟲的網(wǎng)絡(luò)應(yīng)用???”,我從中了解到 Adrian Rosebrock 的“??使用 Keras 的深度學(xué)習(xí)和醫(yī)學(xué)圖像分析??”。我感激這些優(yōu)秀的資源的作者,讓我在瘧原蟲預(yù)防、診斷和治療方面有了更多的想法。
??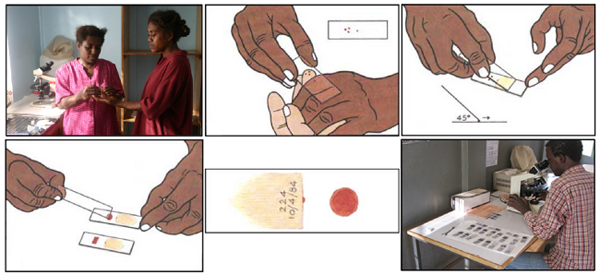
??
一個(gè)瘧原蟲檢測(cè)的血涂片工作流程
根據(jù) WHO 方案,診斷通常包括對(duì)放大 100 倍的血涂片的集中檢測(cè)。受過訓(xùn)練的人們手工計(jì)算在 5000 個(gè)細(xì)胞中有多少紅細(xì)胞中包含瘧原蟲。正如上述解釋中引用的 Rajaraman, et al. 的論文:
厚血涂片有助于檢測(cè)寄生蟲的存在,而薄血涂片有助于識(shí)別引起感染的寄生蟲種類(疾病控制和預(yù)防中心, 2012)。診斷準(zhǔn)確性在很大程度上取決于診斷人的專業(yè)知識(shí),并且可能受到觀察者間差異和疾病流行/資源受限區(qū)域大規(guī)模診斷所造成的不利影響(Mitiku, Mengistu 和 Gelaw, 2003)。可替代的技術(shù)是使用聚合酶鏈反應(yīng)(PCR)和快速診斷測(cè)試(RDT);然而,PCR 分析受限于它的性能(Hommelsheim, et al., 2014),RDT 在疾病流行的地區(qū)成本效益低(Hawkes, Katsuva 和 Masumbuko, 2009)。
因此,瘧疾檢測(cè)可能受益于使用機(jī)器學(xué)習(xí)的自動(dòng)化。
瘧疾檢測(cè)的深度學(xué)習(xí)
人工診斷血涂片是一個(gè)繁重的手工過程,需要專業(yè)知識(shí)來分類和計(jì)數(shù)被寄生蟲感染的和未感染的細(xì)胞。這個(gè)過程可能不能很好的規(guī)模化,尤其在那些專業(yè)人士不足的地區(qū)。在利用最先進(jìn)的圖像處理和分析技術(shù)提取人工選取特征和構(gòu)建基于機(jī)器學(xué)習(xí)的分類模型方面取得了一些進(jìn)展。然而,這些模型不能大規(guī)模推廣,因?yàn)闆]有更多的數(shù)據(jù)用來訓(xùn)練,并且人工選取特征需要花費(fèi)很長時(shí)間。
深度學(xué)習(xí)模型,或者更具體地講,卷積神經(jīng)網(wǎng)絡(luò)(CNN),已經(jīng)被證明在各種計(jì)算機(jī)視覺任務(wù)中非常有效。(如果你想更多的了解關(guān)于 CNN 的背景知識(shí),我推薦你閱讀??視覺識(shí)別的 CS2331n 卷積神經(jīng)網(wǎng)絡(luò)??。)簡單地講,CNN 模型的關(guān)鍵層包含卷積和池化層,正如下圖所示。
??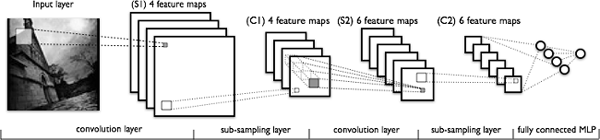
??
一個(gè)典型的 CNN 架構(gòu)
卷積層從數(shù)據(jù)中學(xué)習(xí)空間層級(jí)模式,它是平移不變的,因此它們能夠?qū)W習(xí)圖像的不同方面。例如,第一個(gè)卷積層將學(xué)習(xí)小的和局部圖案,例如邊緣和角落,第二個(gè)卷積層將基于第一層的特征學(xué)習(xí)更大的圖案,等等。這允許 CNN 自動(dòng)化提取特征并且學(xué)習(xí)對(duì)于新數(shù)據(jù)點(diǎn)通用的有效的特征。池化層有助于下采樣和減少尺寸。
因此,CNN 有助于自動(dòng)化和規(guī)模化的特征工程。同樣,在模型末尾加上密集層允許我們執(zhí)行像圖像分類這樣的任務(wù)。使用像 CNN 這樣的深度學(xué)習(xí)模型自動(dòng)的瘧疾檢測(cè)可能非常有效、便宜和具有規(guī)模性,尤其是遷移學(xué)習(xí)和預(yù)訓(xùn)練模型效果非常好,甚至在少量數(shù)據(jù)的約束下。
Rajaraman, et al. 的論文在一個(gè)數(shù)據(jù)集上利用六個(gè)預(yù)訓(xùn)練模型在檢測(cè)瘧疾對(duì)比無感染樣本獲取到令人吃驚的 95.9% 的準(zhǔn)確率。我們的重點(diǎn)是從頭開始嘗試一些簡單的 CNN 模型和用一個(gè)預(yù)訓(xùn)練的訓(xùn)練模型使用遷移學(xué)習(xí)來查看我們能夠從相同的數(shù)據(jù)集中得到什么。我們將使用開源工具和框架,包括 Python 和 TensorFlow,來構(gòu)建我們的模型。
數(shù)據(jù)集
我們分析的數(shù)據(jù)來自 Lister Hill 國家生物醫(yī)學(xué)交流中心(LHNCBC)的研究人員,該中心是國家醫(yī)學(xué)圖書館(NLM)的一部分,他們細(xì)心收集和標(biāo)記了公開可用的健康和受感染的血涂片圖像的??數(shù)據(jù)集???。這些研究者已經(jīng)開發(fā)了一個(gè)運(yùn)行在 Android 智能手機(jī)的??瘧疾檢測(cè)手機(jī)應(yīng)用??,連接到一個(gè)傳統(tǒng)的光學(xué)顯微鏡。它們使用吉姆薩染液將 150 個(gè)受惡性瘧原蟲感染的和 50 個(gè)健康病人的薄血涂片染色,這些薄血涂片是在孟加拉的吉大港醫(yī)學(xué)院附屬醫(yī)院收集和照相的。使用智能手機(jī)的內(nèi)置相機(jī)獲取每個(gè)顯微鏡視窗內(nèi)的圖像。這些圖片由在泰國曼谷的馬希多-牛津熱帶醫(yī)學(xué)研究所的一個(gè)專家使用幻燈片閱讀器標(biāo)記的。
讓我們簡要地查看一下數(shù)據(jù)集的結(jié)構(gòu)。首先,我將安裝一些基礎(chǔ)的依賴(基于使用的操作系統(tǒng))。
??
??
Installing dependencies
我使用的是云上的帶有一個(gè) GPU 的基于 Debian 的操作系統(tǒng),這樣我能更快的運(yùn)行我的模型。為了查看目錄結(jié)構(gòu),我們必須使用 ??sudo apt install tree??? 安裝 ??tree?? 及其依賴(如果我們沒有安裝的話)。
??
??
Installing the tree dependency
我們有兩個(gè)文件夾包含血細(xì)胞的圖像,包括受感染的和健康的。我們通過輸入可以獲取關(guān)于圖像總數(shù)更多的細(xì)節(jié):
import os
import glob
base_dir = os.path.join('./cell_images')
infected_dir = os.path.join(base_dir,'Parasitized')
healthy_dir = os.path.join(base_dir,'Uninfected')
infected_files = glob.glob(infected_dir+'/*.png')
healthy_files = glob.glob(healthy_dir+'/*.png')
len(infected_files), len(healthy_files)
# Output
(13779, 13779)
看起來我們有一個(gè)平衡的數(shù)據(jù)集,包含 13,779 張瘧疾的和 13,779 張非瘧疾的(健康的)血細(xì)胞圖像。讓我們根據(jù)這些構(gòu)建數(shù)據(jù)幀,我們將用這些數(shù)據(jù)幀來構(gòu)建我們的數(shù)據(jù)集。
import numpy as np
import pandas as pd
np.random.seed(42)
files_df = pd.DataFrame({
'filename': infected_files + healthy_files,
'label': ['malaria'] * len(infected_files) + ['healthy'] * len(healthy_files)
}).sample(frac=1, random_state=42).reset_index(drop=True)
files_df.head()
??
??
Datasets
構(gòu)建和了解圖像數(shù)據(jù)集
為了構(gòu)建深度學(xué)習(xí)模型,我們需要訓(xùn)練數(shù)據(jù),但是我們還需要使用不可見的數(shù)據(jù)測(cè)試模型的性能。相應(yīng)的,我們將使用 60:10:30 的比例來劃分用于訓(xùn)練、驗(yàn)證和測(cè)試的數(shù)據(jù)集。我們將在訓(xùn)練期間應(yīng)用訓(xùn)練和驗(yàn)證數(shù)據(jù)集,并用測(cè)試數(shù)據(jù)集來檢查模型的性能。
from sklearn.model_selection import train_test_split
from collections import Counter
train_files, test_files, train_labels, test_labels = train_test_split(files_df['filename'].values,
files_df['label'].values,
test_size=0.3, random_state=42)
train_files, val_files, train_labels, val_labels = train_test_split(train_files,
train_labels,
test_size=0.1, random_state=42)
print(train_files.shape, val_files.shape, test_files.shape)
print('Train:', Counter(train_labels), '\nVal:', Counter(val_labels), '\nTest:', Counter(test_labels))
# Output
(17361,) (1929,) (8268,)
Train: Counter({'healthy': 8734, 'malaria': 8627})
Val: Counter({'healthy': 970, 'malaria': 959})
Test: Counter({'malaria': 4193, 'healthy': 4075})
這些圖片尺寸并不相同,因?yàn)檠科图?xì)胞圖像是基于人、測(cè)試方法、圖片方向不同而不同的。讓我們總結(jié)我們的訓(xùn)練數(shù)據(jù)集的統(tǒng)計(jì)信息來決定最佳的圖像尺寸(牢記,我們根本不會(huì)碰測(cè)試數(shù)據(jù)集)。
import cv2
from concurrent import futures
import threading
def get_img_shape_parallel(idx, img, total_imgs):
if idx % 5000 == 0 or idx == (total_imgs - 1):
print('{}: working on img num: {}'.format(threading.current_thread().name,
idx))
return cv2.imread(img).shape
ex = futures.ThreadPoolExecutor(max_workers=None)
data_inp = [(idx, img, len(train_files)) for idx, img in enumerate(train_files)]
print('Starting Img shape computation:')
train_img_dims_map = ex.map(get_img_shape_parallel,
[record[0] for record in data_inp],
[record[1] for record in data_inp],
[record[2] for record in data_inp])
train_img_dims = list(train_img_dims_map)
print('Min Dimensions:', np.min(train_img_dims, axis=0))
print('Avg Dimensions:', np.mean(train_img_dims, axis=0))
print('Median Dimensions:', np.median(train_img_dims, axis=0))
print('Max Dimensions:', np.max(train_img_dims, axis=0))
# Output
Starting Img shape computation:
ThreadPoolExecutor-0_0: working on img num: 0
ThreadPoolExecutor-0_17: working on img num: 5000
ThreadPoolExecutor-0_15: working on img num: 10000
ThreadPoolExecutor-0_1: working on img num: 15000
ThreadPoolExecutor-0_7: working on img num: 17360
Min Dimensions: [46 46 3]
Avg Dimensions: [132.77311215 132.45757733 3.]
Median Dimensions: [130. 130. 3.]
Max Dimensions: [385 394 3]
我們應(yīng)用并行處理來加速圖像讀取,并且基于匯總統(tǒng)計(jì)結(jié)果,我們將每幅圖片的尺寸重新調(diào)整到 125x125 像素。讓我們載入我們所有的圖像并重新調(diào)整它們?yōu)檫@些固定尺寸。
IMG_DIMS = (125, 125)
def get_img_data_parallel(idx, img, total_imgs):
if idx % 5000 == 0 or idx == (total_imgs - 1):
print('{}: working on img num: {}'.format(threading.current_thread().name,
idx))
img = cv2.imread(img)
img = cv2.resize(img, dsize=IMG_DIMS,
interpolation=cv2.INTER_CUBIC)
img = np.array(img, dtype=np.float32)
return img
ex = futures.ThreadPoolExecutor(max_workers=None)
train_data_inp = [(idx, img, len(train_files)) for idx, img in enumerate(train_files)]
val_data_inp = [(idx, img, len(val_files)) for idx, img in enumerate(val_files)]
test_data_inp = [(idx, img, len(test_files)) for idx, img in enumerate(test_files)]
print('Loading Train Images:')
train_data_map = ex.map(get_img_data_parallel,
[record[0] for record in train_data_inp],
[record[1] for record in train_data_inp],
[record[2] for record in train_data_inp])
train_data = np.array(list(train_data_map))
print('\nLoading Validation Images:')
val_data_map = ex.map(get_img_data_parallel,
[record[0] for record in val_data_inp],
[record[1] for record in val_data_inp],
[record[2] for record in val_data_inp])
val_data = np.array(list(val_data_map))
print('\nLoading Test Images:')
test_data_map = ex.map(get_img_data_parallel,
[record[0] for record in test_data_inp],
[record[1] for record in test_data_inp],
[record[2] for record in test_data_inp])
test_data = np.array(list(test_data_map))
train_data.shape, val_data.shape, test_data.shape
# Output
Loading Train Images:
ThreadPoolExecutor-1_0: working on img num: 0
ThreadPoolExecutor-1_12: working on img num: 5000
ThreadPoolExecutor-1_6: working on img num: 10000
ThreadPoolExecutor-1_10: working on img num: 15000
ThreadPoolExecutor-1_3: working on img num: 17360
Loading Validation Images:
ThreadPoolExecutor-1_13: working on img num: 0
ThreadPoolExecutor-1_18: working on img num: 1928
Loading Test Images:
ThreadPoolExecutor-1_5: working on img num: 0
ThreadPoolExecutor-1_19: working on img num: 5000
ThreadPoolExecutor-1_8: working on img num: 8267
((17361, 125, 125, 3), (1929, 125, 125, 3), (8268, 125, 125, 3))
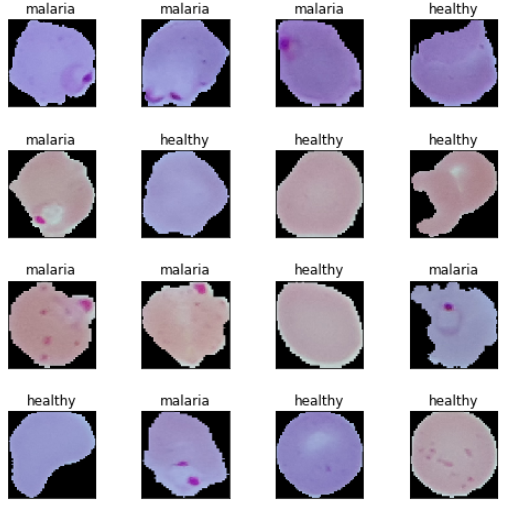
我們?cè)俅螒?yīng)用并行處理來加速有關(guān)圖像載入和重新調(diào)整大小的計(jì)算。最終,我們獲得了所需尺寸的圖片張量,正如前面的輸出所示。我們現(xiàn)在查看一些血細(xì)胞圖像樣本,以對(duì)我們的數(shù)據(jù)有個(gè)印象。
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(1 , figsize = (8 , 8))
n = 0
for i in range(16):
n += 1
r = np.random.randint(0 , train_data.shape[0] , 1)
plt.subplot(4 , 4 , n)
plt.subplots_adjust(hspace = 0.5 , wspace = 0.5)
plt.imshow(train_data[r[0]]/255.)
plt.title('{}'.format(train_labels[r[0]]))
plt.xticks([]) , plt.yticks([])
??
??
Malaria cell samples
基于這些樣本圖像,我們看到一些瘧疾和健康細(xì)胞圖像的細(xì)微不同。我們將使我們的深度學(xué)習(xí)模型試圖在模型訓(xùn)練中學(xué)習(xí)這些模式。
開始我們的模型訓(xùn)練前,我們必須建立一些基礎(chǔ)的配置設(shè)置。
BATCH_SIZE = 64
NUM_CLASSES = 2
EPOCHS = 25
INPUT_SHAPE = (125, 125, 3)
train_imgs_scaled = train_data / 255.
val_imgs_scaled = val_data / 255.
# encode text category labels
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(train_labels)
train_labels_enc = le.transform(train_labels)
val_labels_enc = le.transform(val_labels)
print(train_labels[:6], train_labels_enc[:6])
# Output
['malaria' 'malaria' 'malaria' 'healthy' 'healthy' 'malaria'] [1 1 1 0 0 1]
我們修復(fù)我們的圖像尺寸、批量大小,和紀(jì)元,并編碼我們的分類的類標(biāo)簽。TensorFlow 2.0 于 2019 年三月發(fā)布,這個(gè)練習(xí)是嘗試它的完美理由。
import tensorflow as tf
# Load the TensorBoard notebook extension (optional)
%load_ext tensorboard.notebook
tf.random.set_seed(42)
tf.__version__
# Output
'2.0.0-alpha0'
深度學(xué)習(xí)訓(xùn)練
在模型訓(xùn)練階段,我們將構(gòu)建三個(gè)深度訓(xùn)練模型,使用我們的訓(xùn)練集訓(xùn)練,使用驗(yàn)證數(shù)據(jù)比較它們的性能。然后,我們保存這些模型并在之后的模型評(píng)估階段使用它們。
模型 1:從頭開始的 CNN
我們的第一個(gè)瘧疾檢測(cè)模型將從頭開始構(gòu)建和訓(xùn)練一個(gè)基礎(chǔ)的 CNN。首先,讓我們定義我們的模型架構(gòu),
inp = tf.keras.layers.Input(shape=INPUT_SHAPE)
conv1 = tf.keras.layers.Conv2D(32, kernel_size=(3, 3),
activation='relu', padding='same')(inp)
pool1 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv1)
conv2 = tf.keras.layers.Conv2D(64, kernel_size=(3, 3),
activation='relu', padding='same')(pool1)
pool2 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv2)
conv3 = tf.keras.layers.Conv2D(128, kernel_size=(3, 3),
activation='relu', padding='same')(pool2)
pool3 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv3)
flat = tf.keras.layers.Flatten()(pool3)
hidden1 = tf.keras.layers.Dense(512, activation='relu')(flat)
drop1 = tf.keras.layers.Dropout(rate=0.3)(hidden1)
hidden2 = tf.keras.layers.Dense(512, activation='relu')(drop1)
drop2 = tf.keras.layers.Dropout(rate=0.3)(hidden2)
out = tf.keras.layers.Dense(1, activation='sigmoid')(drop2)
model = tf.keras.Model(inputs=inp, outputs=out)
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
# Output
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 125, 125, 3)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 125, 125, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 62, 62, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 62, 62, 64) 18496
_________________________________________________________________
...
...
_________________________________________________________________
dense_1 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_1 (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 1) 513
=================================================================
Total params: 15,102,529
Trainable params: 15,102,529
Non-trainable params: 0
_________________________________________________________________
基于這些代碼的架構(gòu),我們的 CNN 模型有三個(gè)卷積和一個(gè)池化層,其后是兩個(gè)致密層,以及用于正則化的失活。讓我們訓(xùn)練我們的模型。
import datetime
logdir = os.path.join('/home/dipanzan_sarkar/projects/tensorboard_logs',
datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.5,
patience=2, min_lr=0.000001)
callbacks = [reduce_lr, tensorboard_callback]
history = model.fit(x=train_imgs_scaled, y=train_labels_enc,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
validation_data=(val_imgs_scaled, val_labels_enc),
callbacks=callbacks,
verbose=1)
# Output
Train on 17361 samples, validate on 1929 samples
Epoch 1/25
17361/17361 [====] - 32s 2ms/sample - loss: 0.4373 - accuracy: 0.7814 - val_loss: 0.1834 - val_accuracy: 0.9393
Epoch 2/25
17361/17361 [====] - 30s 2ms/sample - loss: 0.1725 - accuracy: 0.9434 - val_loss: 0.1567 - val_accuracy: 0.9513
...
...
Epoch 24/25
17361/17361 [====] - 30s 2ms/sample - loss: 0.0036 - accuracy: 0.9993 - val_loss: 0.3693 - val_accuracy: 0.9565
Epoch 25/25
17361/17361 [====] - 30s 2ms/sample - loss: 0.0034 - accuracy: 0.9994 - val_loss: 0.3699 - val_accuracy: 0.9559
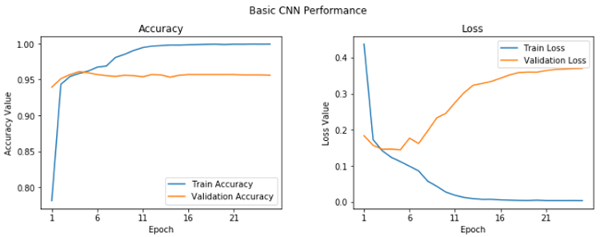
我們獲得了 95.6% 的驗(yàn)證精確率,這很好,盡管我們的模型看起來有些過擬合(通過查看我們的訓(xùn)練精確度,是 99.9%)。通過繪制訓(xùn)練和驗(yàn)證的精度和損失曲線,我們可以清楚地看到這一點(diǎn)。
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
t = f.suptitle('Basic CNN Performance', fontsize=12)
f.subplots_adjust(top=0.85, wspace=0.3)
max_epoch = len(history.history['accuracy'])+1
epoch_list = list(range(1,max_epoch))
ax1.plot(epoch_list, history.history['accuracy'], label='Train Accuracy')
ax1.plot(epoch_list, history.history['val_accuracy'], label='Validation Accuracy')
ax1.set_xticks(np.arange(1, max_epoch, 5))
ax1.set_ylabel('Accuracy Value')
ax1.set_xlabel('Epoch')
ax1.set_title('Accuracy')
l1 = ax1.legend(loc="best")
ax2.plot(epoch_list, history.history['loss'], label='Train Loss')
ax2.plot(epoch_list, history.history['val_loss'], label='Validation Loss')
ax2.set_xticks(np.arange(1, max_epoch, 5))
ax2.set_ylabel('Loss Value')
ax2.set_xlabel('Epoch')
ax2.set_title('Loss')
l2 = ax2.legend(loc="best")
??
??
基礎(chǔ) CNN 學(xué)習(xí)曲線
我們可以看在在第五個(gè)紀(jì)元,情況并沒有改善很多。讓我們保存這個(gè)模型用于將來的評(píng)估。
model.save('basic_cnn.h5')深度遷移學(xué)習(xí)
就像人類有與生俱來在不同任務(wù)間傳輸知識(shí)的能力一樣,遷移學(xué)習(xí)允許我們利用從以前任務(wù)學(xué)到的知識(shí)用到新的相關(guān)的任務(wù),即使在機(jī)器學(xué)習(xí)或深度學(xué)習(xí)的情況下也是如此。如果想深入探究遷移學(xué)習(xí),你應(yīng)該看我的文章“??一個(gè)易于理解與現(xiàn)實(shí)應(yīng)用一起學(xué)習(xí)深度學(xué)習(xí)中的遷移學(xué)習(xí)的指導(dǎo)實(shí)踐???”和我的書《??Python 遷移學(xué)習(xí)實(shí)踐??》。
??
??
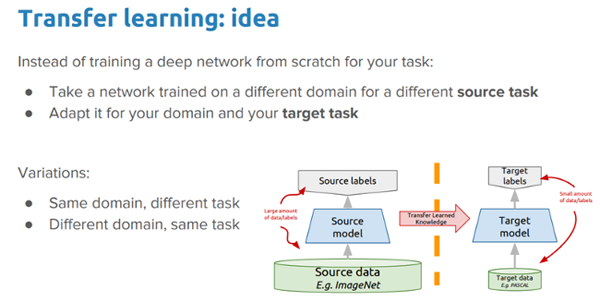
深度遷移學(xué)習(xí)的想法
在這篇實(shí)踐中我們想要探索的想法是:
在我們的問題背景下,我們能夠利用一個(gè)預(yù)訓(xùn)練深度學(xué)習(xí)模型(在大數(shù)據(jù)集上訓(xùn)練的,像 ImageNet)通過應(yīng)用和遷移知識(shí)來解決瘧疾檢測(cè)的問題嗎?
我們將應(yīng)用兩個(gè)最流行的深度遷移學(xué)習(xí)策略。
- 預(yù)訓(xùn)練模型作為特征提取器
- 微調(diào)的預(yù)訓(xùn)練模型
我們將使用預(yù)訓(xùn)練的 VGG-19 深度訓(xùn)練模型(由劍橋大學(xué)的視覺幾何組(VGG)開發(fā))進(jìn)行我們的實(shí)驗(yàn)。像 VGG-19 這樣的預(yù)訓(xùn)練模型是在一個(gè)大的數(shù)據(jù)集(??Imagenet??)上使用了很多不同的圖像分類訓(xùn)練的。因此,這個(gè)模型應(yīng)該已經(jīng)學(xué)習(xí)到了健壯的特征層級(jí)結(jié)構(gòu),相對(duì)于你的 CNN 模型學(xué)到的特征,是空間不變的、轉(zhuǎn)動(dòng)不變的、平移不變的。因此,這個(gè)模型,已經(jīng)從百萬幅圖片中學(xué)習(xí)到了一個(gè)好的特征顯示,對(duì)于像瘧疾檢測(cè)這樣的計(jì)算機(jī)視覺問題,可以作為一個(gè)好的合適新圖像的特征提取器。在我們的問題中發(fā)揮遷移學(xué)習(xí)的能力之前,讓我們先討論 VGG-19 模型。
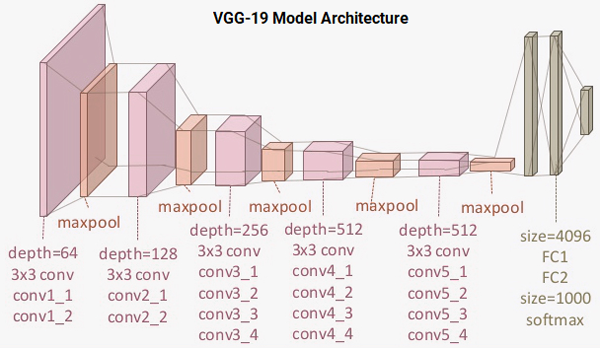
理解 VGG-19 模型
VGG-19 模型是一個(gè)構(gòu)建在 ImageNet 數(shù)據(jù)庫之上的 19 層(卷積和全連接的)的深度學(xué)習(xí)網(wǎng)絡(luò),ImageNet 數(shù)據(jù)庫為了圖像識(shí)別和分類的目的而開發(fā)。該模型是由 Karen Simonyan 和 Andrew Zisserman 構(gòu)建的,在他們的論文“??大規(guī)模圖像識(shí)別的非常深的卷積網(wǎng)絡(luò)??”中進(jìn)行了描述。VGG-19 的架構(gòu)模型是:
??
??
VGG-19 模型架構(gòu)
你可以看到我們總共有 16 個(gè)使用 3x3 卷積過濾器的卷積層,與最大的池化層來下采樣,和由 4096 個(gè)單元組成的兩個(gè)全連接的隱藏層,每個(gè)隱藏層之后跟隨一個(gè)由 1000 個(gè)單元組成的致密層,每個(gè)單元代表 ImageNet 數(shù)據(jù)庫中的一個(gè)分類。我們不需要最后三層,因?yàn)槲覀儗⑹褂梦覀冏约旱娜B接致密層來預(yù)測(cè)瘧疾。我們更關(guān)心前五個(gè)塊,因此我們可以利用 VGG 模型作為一個(gè)有效的特征提取器。
我們將使用模型之一作為一個(gè)簡單的特征提取器,通過凍結(jié)五個(gè)卷積塊的方式來確保它們的位權(quán)在每個(gè)紀(jì)元后不會(huì)更新。對(duì)于最后一個(gè)模型,我們會(huì)對(duì) VGG 模型進(jìn)行微調(diào),我們會(huì)解凍最后兩個(gè)塊(第 4 和第 5)因此當(dāng)我們訓(xùn)練我們的模型時(shí),它們的位權(quán)在每個(gè)時(shí)期(每批數(shù)據(jù))被更新。
模型 2:預(yù)訓(xùn)練的模型作為一個(gè)特征提取器
為了構(gòu)建這個(gè)模型,我們將利用 TensorFlow 載入 VGG-19 模型并凍結(jié)卷積塊,因此我們能夠?qū)⑺鼈冇米魈卣魈崛∑鳌N覀冊(cè)谀┪膊迦胛覀冏约旱闹旅軐觼韴?zhí)行分類任務(wù)。
vgg = tf.keras.applications.vgg19.VGG19(include_top=False, weights='imagenet',
input_shape=INPUT_SHAPE)
vgg.trainable = False
# Freeze the layers
for layer in vgg.layers:
layer.trainable = False
base_vgg = vgg
base_out = base_vgg.output
pool_out = tf.keras.layers.Flatten()(base_out)
hidden1 = tf.keras.layers.Dense(512, activation='relu')(pool_out)
drop1 = tf.keras.layers.Dropout(rate=0.3)(hidden1)
hidden2 = tf.keras.layers.Dense(512, activation='relu')(drop1)
drop2 = tf.keras.layers.Dropout(rate=0.3)(hidden2)
out = tf.keras.layers.Dense(1, activation='sigmoid')(drop2)
model = tf.keras.Model(inputs=base_vgg.input, outputs=out)
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=1e-4),
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
# Output
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 125, 125, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 125, 125, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 125, 125, 64) 36928
_________________________________________________________________
...
...
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 3, 3, 512) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 4608) 0
_________________________________________________________________
dense_3 (Dense) (None, 512) 2359808
_________________________________________________________________
dropout_2 (Dropout) (None, 512) 0
_________________________________________________________________
dense_4 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_3 (Dropout) (None, 512) 0
_________________________________________________________________
dense_5 (Dense) (None, 1) 513
=================================================================
Total params: 22,647,361
Trainable params: 2,622,977
Non-trainable params: 20,024,384
_________________________________________________________________
從整個(gè)輸出可以明顯看出,在我們的模型中我們有了很多層,我們將只利用 VGG-19 模型的凍結(jié)層作為特征提取器。你可以使用下列代碼來驗(yàn)證我們的模型有多少層是實(shí)際可訓(xùn)練的,以及我們的網(wǎng)絡(luò)中總共存在多少層。
print("Total Layers:", len(model.layers))
print("Total trainable layers:",
sum([1 for l in model.layers if l.trainable]))
# Output
Total Layers: 28
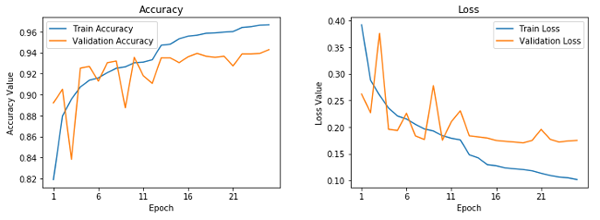
Total trainable layers: 6我們將使用和我們之前的模型相似的配置和回調(diào)來訓(xùn)練我們的模型。參考??我的 GitHub 倉庫??以獲取訓(xùn)練模型的完整代碼。我們觀察下列圖表,以顯示模型精確度和損失曲線。
??
??
凍結(jié)的預(yù)訓(xùn)練的 CNN 的學(xué)習(xí)曲線
這表明我們的模型沒有像我們的基礎(chǔ) CNN 模型那樣過擬合,但是性能有點(diǎn)不如我們的基礎(chǔ)的 CNN 模型。讓我們保存這個(gè)模型,以備將來的評(píng)估。
model.save('vgg_frozen.h5')模型 3:使用圖像增強(qiáng)來微調(diào)預(yù)訓(xùn)練的模型
在我們的最后一個(gè)模型中,我們將在預(yù)定義好的 VGG-19 模型的最后兩個(gè)塊中微調(diào)層的位權(quán)。我們同樣引入了圖像增強(qiáng)的概念。圖像增強(qiáng)背后的想法和其名字一樣。我們從訓(xùn)練數(shù)據(jù)集中載入現(xiàn)有圖像,并且應(yīng)用轉(zhuǎn)換操作,例如旋轉(zhuǎn)、裁剪、轉(zhuǎn)換、放大縮小等等,來產(chǎn)生新的、改變過的版本。由于這些隨機(jī)轉(zhuǎn)換,我們每次獲取到的圖像不一樣。我們將應(yīng)用 tf.keras 中的一個(gè)名為 ImageDataGenerator 的優(yōu)秀工具來幫助構(gòu)建圖像增強(qiáng)器。
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255,
zoom_range=0.05,
rotation_range=25,
width_shift_range=0.05,
height_shift_range=0.05,
shear_range=0.05, horizontal_flip=True,
fill_mode='nearest')
val_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
# build image augmentation generators
train_generator = train_datagen.flow(train_data, train_labels_enc, batch_size=BATCH_SIZE, shuffle=True)
val_generator = val_datagen.flow(val_data, val_labels_enc, batch_size=BATCH_SIZE, shuffle=False)
我們不會(huì)對(duì)我們的驗(yàn)證數(shù)據(jù)集應(yīng)用任何轉(zhuǎn)換(除非是調(diào)整大小,因?yàn)檫@是必須的),因?yàn)槲覀儗⑹褂盟u(píng)估每個(gè)紀(jì)元的模型性能。對(duì)于在傳輸學(xué)習(xí)環(huán)境中的圖像增強(qiáng)的詳細(xì)解釋,請(qǐng)隨時(shí)查看我上面引用的??文章??。讓我們從一批圖像增強(qiáng)轉(zhuǎn)換中查看一些樣本結(jié)果。
img_id = 0
sample_generator = train_datagen.flow(train_data[img_id:img_id+1], train_labels[img_id:img_id+1],
batch_size=1)
sample = [next(sample_generator) for i in range(0,5)]
fig, ax = plt.subplots(1,5, figsize=(16, 6))
print('Labels:', [item[1][0] for item in sample])
l = [ax[i].imshow(sample[i][0][0]) for i in range(0,5)]
??
??
Sample augmented images
你可以清晰的看到與之前的輸出的我們圖像的輕微變化。我們現(xiàn)在構(gòu)建我們的學(xué)習(xí)模型,確保 VGG-19 模型的最后兩塊是可以訓(xùn)練的。
vgg = tf.keras.applications.vgg19.VGG19(include_top=False, weights='imagenet',
input_shape=INPUT_SHAPE)
# Freeze the layers
vgg.trainable = True
set_trainable = False
for layer in vgg.layers:
if layer.name in ['block5_conv1', 'block4_conv1']:
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
base_vgg = vgg
base_out = base_vgg.output
pool_out = tf.keras.layers.Flatten()(base_out)
hidden1 = tf.keras.layers.Dense(512, activation='relu')(pool_out)
drop1 = tf.keras.layers.Dropout(rate=0.3)(hidden1)
hidden2 = tf.keras.layers.Dense(512, activation='relu')(drop1)
drop2 = tf.keras.layers.Dropout(rate=0.3)(hidden2)
out = tf.keras.layers.Dense(1, activation='sigmoid')(drop2)
model = tf.keras.Model(inputs=base_vgg.input, outputs=out)
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=1e-5),
loss='binary_crossentropy',
metrics=['accuracy'])
print("Total Layers:", len(model.layers))
print("Total trainable layers:", sum([1 for l in model.layers if l.trainable]))
# Output
Total Layers: 28
Total trainable layers: 16
在我們的模型中我們降低了學(xué)習(xí)率,因?yàn)槲覀儾幌朐谖⒄{(diào)的時(shí)候?qū)︻A(yù)訓(xùn)練的層做大的位權(quán)更新。模型的訓(xùn)練過程可能有輕微的不同,因?yàn)槲覀兪褂昧藬?shù)據(jù)生成器,因此我們將應(yīng)用 ??fit_generator(...)?? 函數(shù)。
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.5,
patience=2, min_lr=0.000001)
callbacks = [reduce_lr, tensorboard_callback]
train_steps_per_epoch = train_generator.n // train_generator.batch_size
val_steps_per_epoch = val_generator.n // val_generator.batch_size
history = model.fit_generator(train_generator, steps_per_epoch=train_steps_per_epoch, epochs=EPOCHS,
validation_data=val_generator, validation_steps=val_steps_per_epoch,
verbose=1)
# Output
Epoch 1/25
271/271 [====] - 133s 489ms/step - loss: 0.2267 - accuracy: 0.9117 - val_loss: 0.1414 - val_accuracy: 0.9531
Epoch 2/25
271/271 [====] - 129s 475ms/step - loss: 0.1399 - accuracy: 0.9552 - val_loss: 0.1292 - val_accuracy: 0.9589
...
...
Epoch 24/25
271/271 [====] - 128s 473ms/step - loss: 0.0815 - accuracy: 0.9727 - val_loss: 0.1466 - val_accuracy: 0.9682
Epoch 25/25
271/271 [====] - 128s 473ms/step - loss: 0.0792 - accuracy: 0.9729 - val_loss: 0.1127 - val_accuracy: 0.9641
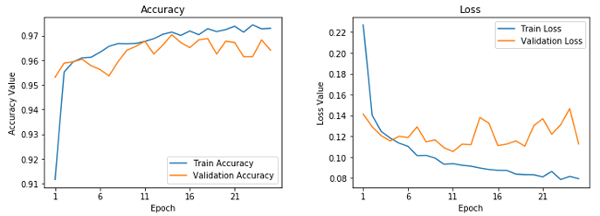
這看起來是我們的最好的模型。它給了我們近乎 96.5% 的驗(yàn)證精確率,基于訓(xùn)練精度,它看起來不像我們的第一個(gè)模型那樣過擬合。這可以通過下列的學(xué)習(xí)曲線驗(yàn)證。
??
??
微調(diào)過的預(yù)訓(xùn)練 CNN 的學(xué)習(xí)曲線
讓我們保存這個(gè)模型,因此我們能夠在測(cè)試集上使用。
model.save('vgg_finetuned.h5')這就完成了我們的模型訓(xùn)練階段。現(xiàn)在我們準(zhǔn)備好了在測(cè)試集上測(cè)試我們模型的性能。
深度學(xué)習(xí)模型性能評(píng)估
我們將通過在我們的測(cè)試集上做預(yù)測(cè)來評(píng)估我們?cè)谟?xùn)練階段構(gòu)建的三個(gè)模型,因?yàn)閮H僅驗(yàn)證是不夠的!我們同樣構(gòu)建了一個(gè)檢測(cè)工具模塊叫做 ??model_evaluation_utils??,我們可以使用相關(guān)分類指標(biāo)用來評(píng)估使用我們深度學(xué)習(xí)模型的性能。第一步是擴(kuò)展我們的數(shù)據(jù)集。
test_imgs_scaled = test_data / 255.
test_imgs_scaled.shape, test_labels.shape
# Output
((8268, 125, 125, 3), (8268,))
下一步包括載入我們保存的深度學(xué)習(xí)模型,在測(cè)試集上預(yù)測(cè)。
# Load Saved Deep Learning Models
basic_cnn = tf.keras.models.load_model('./basic_cnn.h5')
vgg_frz = tf.keras.models.load_model('./vgg_frozen.h5')
vgg_ft = tf.keras.models.load_model('./vgg_finetuned.h5')
# Make Predictions on Test Data
basic_cnn_preds = basic_cnn.predict(test_imgs_scaled, batch_size=512)
vgg_frz_preds = vgg_frz.predict(test_imgs_scaled, batch_size=512)
vgg_ft_preds = vgg_ft.predict(test_imgs_scaled, batch_size=512)
basic_cnn_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
for pred in basic_cnn_preds.ravel()])
vgg_frz_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
for pred in vgg_frz_preds.ravel()])
vgg_ft_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
for pred in vgg_ft_preds.ravel()])
下一步是應(yīng)用我們的 ??model_evaluation_utils?? 模塊根據(jù)相應(yīng)分類指標(biāo)來檢查每個(gè)模塊的性能。
import model_evaluation_utils as meu
import pandas as pd
basic_cnn_metrics = meu.get_metrics(true_labels=test_labels, predicted_labels=basic_cnn_pred_labels)
vgg_frz_metrics = meu.get_metrics(true_labels=test_labels, predicted_labels=vgg_frz_pred_labels)
vgg_ft_metrics = meu.get_metrics(true_labels=test_labels, predicted_labels=vgg_ft_pred_labels)
pd.DataFrame([basic_cnn_metrics, vgg_frz_metrics, vgg_ft_metrics],
index=['Basic CNN', 'VGG-19 Frozen', 'VGG-19 Fine-tuned'])
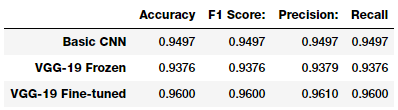
??
??
Model accuracy
看起來我們的第三個(gè)模型在我們的測(cè)試集上執(zhí)行的最好,給出了一個(gè)模型精確性為 96% 的 F1 得分,這非常好,與我們之前提到的研究論文和文章中的更復(fù)雜的模型相當(dāng)。
總結(jié)
瘧疾檢測(cè)不是一個(gè)簡單的過程,全球的合格人員的不足在病例診斷和治療當(dāng)中是一個(gè)嚴(yán)重的問題。我們研究了一個(gè)關(guān)于瘧疾的有趣的真實(shí)世界的醫(yī)學(xué)影像案例。利用 AI 的、易于構(gòu)建的、開源的技術(shù)在檢測(cè)瘧疾方面可以為我們提供最先進(jìn)的精確性,因此使 AI 具有社會(huì)效益。
我鼓勵(lì)你查看這篇文章中提到的文章和研究論文,沒有它們,我就不能形成概念并寫出來。如果你對(duì)運(yùn)行和采納這些技術(shù)感興趣,本篇文章所有的代碼都可以在??我的 GitHub 倉庫???獲得。記得從??官方網(wǎng)站??下載數(shù)據(jù)。
讓我們希望在健康醫(yī)療方面更多的采納開源的 AI 能力,使它在世界范圍內(nèi)變得更便宜、更易用。