從人工智能 (AI)發(fā)展應(yīng)用看算法測(cè)試的測(cè)試策略
隨著人工智能的發(fā)展與應(yīng)用,AI測(cè)試逐漸進(jìn)入到我們的視野,傳統(tǒng)的功能測(cè)試策略對(duì)于算法測(cè)試而言,心有余而力不足,難以滿足對(duì)人工智能 (AI) 的質(zhì)量保障。
結(jié)合在人臉檢測(cè)、檢索算法上的測(cè)試探索、實(shí)踐的過(guò)程,本文將從以下幾個(gè)方面介紹人工智能 (AI) 算法測(cè)試策略。
- 算法測(cè)試集數(shù)據(jù)準(zhǔn)備
- 算法功能測(cè)試
- 算法性能測(cè)試
- 算法效果測(cè)試(模型評(píng)估指標(biāo))
- 算法指標(biāo)結(jié)果分析
- 算法測(cè)試報(bào)告
我們將算法測(cè)試測(cè)試流程中的幾個(gè)核心環(huán)節(jié)提煉如上幾點(diǎn),也就組成了我們算法測(cè)試的測(cè)試策略,在此,拋磚引玉的分享一下。
算法測(cè)試集數(shù)據(jù)準(zhǔn)備
測(cè)試集的準(zhǔn)備對(duì)于整體算法測(cè)試而言非常重要,一般測(cè)試集準(zhǔn)備過(guò)程中需考慮以下幾點(diǎn):
- 測(cè)試集的覆蓋度
- 測(cè)試集的獨(dú)立性
- 測(cè)試集的準(zhǔn)確性
測(cè)試集的覆蓋度
如果,測(cè)試集準(zhǔn)備只是隨機(jī)的選取測(cè)試數(shù)據(jù),容易造成測(cè)試結(jié)果的失真,降低算法模型評(píng)估結(jié)果的可靠性。
好比我們的功能測(cè)試,根據(jù)功能測(cè)試設(shè)計(jì),構(gòu)造對(duì)應(yīng)的數(shù)據(jù)進(jìn)行測(cè)試覆蓋。算法測(cè)試亦然,以人臉檢測(cè)算法而言,除了考慮選取正樣本、負(fù)樣本外,還需要考慮正樣本中人臉特征的覆蓋,如人臉占比、模糊度、光照、姿態(tài)(角度)、完整性(遮擋)等特征。
選擇好對(duì)應(yīng)的測(cè)試數(shù)據(jù)后,后來(lái)后期的指標(biāo)計(jì)算、結(jié)果分析,還需對(duì)數(shù)據(jù)進(jìn)行標(biāo)注,標(biāo)注對(duì)應(yīng)的特征,以人臉檢測(cè)為例,使用工具對(duì)人臉圖標(biāo)進(jìn)行人臉坐標(biāo)框圖,并將對(duì)應(yīng)特征進(jìn)行標(biāo)注記錄及存儲(chǔ),如下圖。
另外,除了數(shù)據(jù)特征的覆蓋,也需要考慮數(shù)據(jù)來(lái)源的覆蓋,結(jié)合實(shí)際應(yīng)用環(huán)境、場(chǎng)景的數(shù)據(jù)進(jìn)行數(shù)據(jù)模擬、準(zhǔn)備。比如公共場(chǎng)所攝像頭下的人臉檢索,圖片一般比較模糊、圖片光照強(qiáng)度不一,因此準(zhǔn)備數(shù)據(jù)時(shí),也需要根據(jù)此場(chǎng)景,模擬數(shù)據(jù)。一般來(lái)講,最好將真實(shí)生產(chǎn)環(huán)境數(shù)據(jù)作為測(cè)試數(shù)據(jù),并從其中按照數(shù)據(jù)特征分布選取測(cè)試數(shù)據(jù)。
此外,關(guān)于測(cè)試數(shù)據(jù)的數(shù)量,一般來(lái)講測(cè)試數(shù)據(jù)量越多越能客觀的反映算法的真實(shí)效果,但出于測(cè)試成本的考慮,不能窮其盡,一般以真實(shí)生產(chǎn)環(huán)境為參考,選取20%,如果生產(chǎn)環(huán)境數(shù)據(jù)量巨大,則選取1%~2%,或者更小。由于我們的生產(chǎn)環(huán)境數(shù)據(jù)量巨大,考慮到測(cè)試成本,我們選取了2W左右的圖片進(jìn)行測(cè)試。
測(cè)試集的獨(dú)立性
測(cè)試集的獨(dú)立性主要考慮測(cè)試數(shù)據(jù)集相互干擾導(dǎo)致測(cè)試結(jié)果的失真風(fēng)險(xiǎn)。
我們以人臉檢索為例,我們準(zhǔn)備200組人臉測(cè)試數(shù)據(jù),每組為同一個(gè)人不同時(shí)期或角度的10張人臉照片,對(duì)人臉檢索算法模型指標(biāo)進(jìn)行計(jì)算時(shí),如計(jì)算TOP10的精確率,此時(shí)若在數(shù)據(jù)庫(kù)中,存在以上200組人的其他照片時(shí),便會(huì)對(duì)指標(biāo)計(jì)算結(jié)果造成影響,比如我們200組人臉中包含Jack,但數(shù)據(jù)庫(kù)中除了Jack的10張,還存在其他的8張Jack的照片。若算法微服務(wù)接口返回的TOP10圖片中有我們測(cè)試集中的Jack圖片6張,非測(cè)試集但在數(shù)據(jù)庫(kù)中的其他Jack照片2張,還有2張非Jack的照片,測(cè)試的精確率該如何計(jì)算,按照我們的測(cè)試集(已標(biāo)注)來(lái)看,精確率為60%,但實(shí)際精確率為80%,造成了精確率指標(biāo)計(jì)算結(jié)果的失真。
因此,我們?cè)跍y(cè)試集數(shù)據(jù)準(zhǔn)備時(shí),需考慮數(shù)據(jù)干擾,測(cè)試準(zhǔn)備階段對(duì)數(shù)據(jù)庫(kù)的其他測(cè)試數(shù)據(jù)進(jìn)行評(píng)估,比如從200組人臉測(cè)試數(shù)據(jù)組,進(jìn)行預(yù)測(cè)試,對(duì)相似度非常高的數(shù)據(jù)進(jìn)行研判,判斷是否為同一人,若是則刪除該照片或者不將該人從200組測(cè)試集中剔除。
測(cè)試集的準(zhǔn)確性
數(shù)據(jù)集的準(zhǔn)確性比較好理解,一般指的是數(shù)據(jù)標(biāo)注的準(zhǔn)確性,比如Jack的照片不應(yīng)標(biāo)注為Tom,照片模糊的特征不應(yīng)標(biāo)注為清晰。如果數(shù)據(jù)標(biāo)注錯(cuò)誤,那么直接影響了算法模型指標(biāo)計(jì)算的結(jié)果。
對(duì)于測(cè)試集的準(zhǔn)備,為了提高測(cè)試集準(zhǔn)備效率及復(fù)用性,我們嘗試搭建了算法數(shù)倉(cāng)平臺(tái),實(shí)現(xiàn)數(shù)據(jù)(圖片)的在線標(biāo)注、存儲(chǔ)等功能,作為算法測(cè)試數(shù)據(jù)的同一獲取入口。
算法功能測(cè)試
以我現(xiàn)在接觸的人工智能系統(tǒng)而言,將算法以微服務(wù)接口的形式對(duì)外提供服務(wù),類似于百度AI開(kāi)放平臺(tái)。
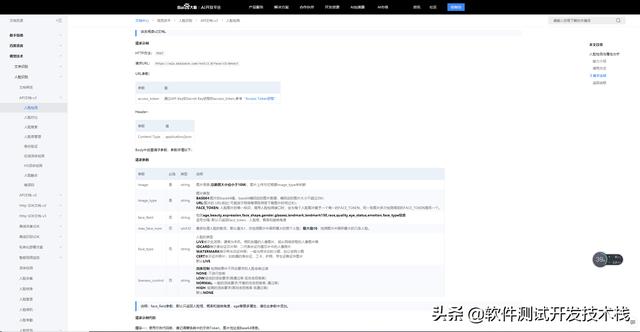
因此需要對(duì)算法微服務(wù)接口進(jìn)行功能性驗(yàn)證,比如結(jié)合應(yīng)用場(chǎng)景從功能性、可靠性、可維護(hù)性角度對(duì)必填、非必填、參數(shù)組合驗(yàn)證等進(jìn)行正向、異向的測(cè)試覆蓋。此處不多做介紹,同普通的API接口測(cè)試策略一致。
算法性能測(cè)試
微服務(wù)接口的性能測(cè)試大家也比較了解,對(duì)于算法微服務(wù)同樣需要進(jìn)行性能測(cè)試,如基準(zhǔn)測(cè)試、性能測(cè)試(驗(yàn)證是否符合性能指標(biāo))、長(zhǎng)短穩(wěn)定性能測(cè)試,都是算法微服務(wù)每個(gè)版本中需要測(cè)試的內(nèi)容,同時(shí)產(chǎn)出版本間的性能橫向?qū)Ρ龋兄阅茏兓3jP(guān)注的指標(biāo)有平均響應(yīng)時(shí)間、95%響應(yīng)時(shí)間、TPS,同時(shí)關(guān)注GPU、內(nèi)存等系統(tǒng)資源的使用情況。
一般使用Jmeter進(jìn)行接口性能測(cè)試。不過(guò),我們?cè)趯?shí)際應(yīng)用中為了將算法微服務(wù)接口的功能測(cè)試、性能測(cè)試融合到一起,以降低自動(dòng)化測(cè)試開(kāi)發(fā)、使用、學(xué)習(xí)成本,提高可持續(xù)性,我們基于關(guān)鍵字驅(qū)動(dòng)、數(shù)據(jù)驅(qū)動(dòng)的測(cè)試思想,利用Python Request、Locust模塊分別實(shí)現(xiàn)了功能、性能自定義關(guān)鍵字開(kāi)發(fā)。每輪測(cè)試執(zhí)行完算法微服務(wù)功能自動(dòng)化測(cè)試,若功能執(zhí)行通過(guò),則自動(dòng)拉起對(duì)應(yīng)不同執(zhí)行策略的性能測(cè)試用例,每次測(cè)試執(zhí)行結(jié)果都進(jìn)行存儲(chǔ)至數(shù)據(jù)庫(kù)中,以便輸出該算法微服務(wù)接口的不同版本性能各項(xiàng)指標(biāo)的比較結(jié)果。
算法模型評(píng)估指標(biāo)

首先,不同類型算法的其關(guān)注的算法模型評(píng)估指標(biāo)不同。
比如人臉檢測(cè)算法常以精確率、召回率、準(zhǔn)確率、錯(cuò)報(bào)率等評(píng)估指標(biāo);人臉檢索算法常以TOPN的精確率、召回率、前N張連續(xù)準(zhǔn)確率。
其次,相同類型算法在不同應(yīng)用場(chǎng)景其關(guān)注的算法模型評(píng)估指標(biāo)也存在差異。
比如人臉檢索在應(yīng)用在高鐵站的人臉比對(duì)(重點(diǎn)人員檢索)的場(chǎng)景中,不太關(guān)注召回率,但對(duì)精確率要求很多,避免抓錯(cuò)人,造成公共場(chǎng)所的秩序混亂。但在海量人臉檢索的應(yīng)用場(chǎng)景中,愿意犧牲部分精確率來(lái)提高召回率,因此在該場(chǎng)景中不能盲目的追求精準(zhǔn)率。
除了上述算法模型評(píng)估指標(biāo),我們還常用ROC、PR曲線來(lái)衡量算法模型效果的好壞。

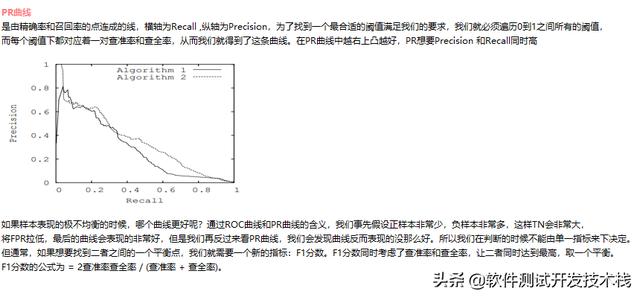
我們?cè)谒惴ㄎ⒎?wù)功能、性能測(cè)試中介紹到,使用了基于關(guān)鍵字驅(qū)動(dòng)、數(shù)據(jù)驅(qū)動(dòng)的測(cè)試思想,利用Python Request、Locust模塊分別實(shí)現(xiàn)功能、性能自定義關(guān)鍵字開(kāi)發(fā)。考慮到測(cè)試技術(shù)棧的統(tǒng)一以及可復(fù)用性,我們基于上述設(shè)計(jì),實(shí)現(xiàn)了算法模型評(píng)估指標(biāo)的自定義關(guān)鍵字開(kāi)發(fā),每次運(yùn)行輸出相同測(cè)試集下的不同版本模型評(píng)估指標(biāo)的橫向比較。
當(dāng)然除了不同版本的比較模型評(píng)估指標(biāo)的比較,如果條件允許,我們還需要進(jìn)行一定的競(jìng)品比較,比較與市場(chǎng)上相同類似的算法效果的差異,取長(zhǎng)補(bǔ)短。
算法指標(biāo)結(jié)果分析
我們對(duì)算法模型指標(biāo)評(píng)估之后,除了感知算法模型評(píng)估指標(biāo)在不同版本的差異,還希望進(jìn)一步的進(jìn)行分析,已得到具體算法模型的優(yōu)化的優(yōu)化方向,這時(shí)候就需要結(jié)合數(shù)據(jù)的標(biāo)注信息進(jìn)行深度的分析,挖掘算法優(yōu)劣是否哪些數(shù)據(jù)特征的影響,影響程度如何。比如通過(guò)數(shù)據(jù)特征組合或者控制部分特征一致等方式,看其他特征對(duì)算法效果的影響程度等等。
這時(shí)候我們一般通過(guò)開(kāi)發(fā)一些腳本實(shí)現(xiàn)我們的分析過(guò)程,根據(jù)算法微服務(wù)接口的響應(yīng)體以及數(shù)據(jù)準(zhǔn)備階段所標(biāo)注的數(shù)據(jù)特征,進(jìn)行分析腳本的開(kāi)發(fā)。
另外指標(biāo)結(jié)果的進(jìn)一步分析,也要結(jié)合算法設(shè)計(jì),比如人臉檢索算法,每張圖片的檢索流程為“輸入圖片的人臉檢測(cè)“ -> “輸入圖片的人臉特征提取“ -> “相似特征檢索“,通過(guò)此查詢流程不難看出人臉檢索的整體精確率受上述三個(gè)環(huán)節(jié)的影響,因此基于指標(biāo)結(jié)果的深度分析也需要從這三個(gè)層次入手。
算法測(cè)試報(bào)告
一般算法測(cè)試報(bào)告由以下幾個(gè)要素組成:
- 算法功能測(cè)試結(jié)果
- 算法性能測(cè)試結(jié)果
- 算法模型評(píng)估指標(biāo)結(jié)果
- 算法指標(biāo)結(jié)果分析
由于算法微服務(wù)測(cè)試的復(fù)雜度相對(duì)普通服務(wù)接口較高,在報(bào)告注意簡(jiǎn)明扼要。