













3D特效師可以下班了丨Science
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
是否還記得前陣子爆火的SM娛樂公司電子屏海浪?

人工制作那樣的特效,可能需要花費……嗯,畢竟被稱為「每滴水都是粉絲貢獻的錢」。
但現在,DeepMind和斯坦福等一眾科學家研究出了一款圖網絡模擬器——GNS框架,AI只需要“看著”場景中的流體,就能將它模擬出來。
無論是流體、剛性固體還是可變形材料,GNS都能模擬的惟妙惟肖。研究人員還稱:
GNS框架是迄今為止最精確的通用學習物理模擬器。
并且,這項研究最近還被頂刊 Science 收錄。

這也不禁讓人聯想起,清華姚班畢業生胡淵鳴開發的太極 (Taichi),不僅大幅降低了CG特效門檻,效果還是十分逼真。
而在 DeepMind 和斯坦福大學的這項工作中,胡淵鳴的太極,依然發揮了作用。
他們正是利用胡同學的太極,來生成2D和3D的挑戰場景,作為基線效果之一。
效果好到什么程度?Science在社交網絡評價說:

「好萊塢或許會投資這款模擬器吧」。
是你印象中的畫面了
我們人類通過「經驗」,說到一個場景時,能很快腦補出那種動態畫面。
那么AI「腦補」出來的畫面效果,是否和你想象的一樣呢?
首先,是水落入玻璃容器中的3D效果。

和我們想象中的物理效果一模一樣,有木有!
左側的基線方法叫做SPH (smoothed particle hydrodynamics),這是1992年提出的一種基于顆粒的模擬流體的方法。
而右側,AI通過「看」而預測得到的結果,就是研究人員提出來的GNS方法。
來看下二者在慢動作下的細節差異。

不難看出,GNS方法在細節處理上,例如濺起的水花,更加細粒度,也更逼近我們印象中的樣子。
當然,GNS不僅能夠處理液體,還能夠模擬其他狀態的物體。
例如,顆粒狀的沙子。

還有粘性的物體。

上面兩個效果中的基線方法是MPM (material point method),1995年提出,適用于相互作用的可變形材料。
同樣,在顆粒散落在玻璃容器壁上的細節上,GNS的預測結果更加符合現實物理世界的效果。
那么,如此逼真的效果是如何做到的呢?
圖網絡模擬器模擬流體
傳統特效計算方法
此前,對于真實物體的模擬,需要通過大量計算來實現,上文中提到的MPM就是其中的一種。
這種方法被稱為物質點法(Material Point Method),將一塊材料離散成非常多的顆粒,并計算空間導數和求解動量方程。
經過胡淵鳴等人改進的MLS-MPM,模擬物體的速度有了很大的提升,相比于原來的MPM快了兩倍左右。

除此之外,一種名為PBD的方法,可以計算模擬出一個方塊漂浮在水上的動態效果;

而這兩種方法之外,還有一種被叫做SPH的~~古老~~經典方法,用于計算生成水的3D特效。

相比于這些采用大量計算模擬出來的真實場景,如果用神經網絡對它們進行訓練,是不是能模擬出物體在真實場景中受到撞擊的效果,而且和用這些方法生成的效果非常相似?
網友對這樣的想法感到驚奇,畢竟,人腦對于流體或是物體撞擊效果的模擬,并非通過大量力學計算得出,而是通過神經網絡模擬的。
DeepMind在這樣的想法上,采用了GNS對生成的這些模型進行訓練,用于模擬物體在真實場景下的特效。
圖網絡預測物體特效
GNS模擬物體最根本的原理,是將一塊體積不變的物體模型X,分散成許多顆粒,并通過一個模擬器sθ,轉變成它受到撞擊后的形態。
從下圖可見,模擬器sθ的用處,是將這塊流體輸入到一個動力學模型dθ中,并將產生的一幀幀結果用于更新物體變形的過程。

只要模擬器更新的時間夠快,我們看見的就是這塊物體在玻璃盒中受到撞擊、不斷變形的樣子。

△ 圖右為模擬器生成的效果
關鍵來了,動力學模型dθ要怎么實現?
團隊采用了“三步走”的方法,將模型分為編碼器、處理器和解碼器三部分。

一塊物體經過編碼器后,編碼器會將物體中原本分散的各顆粒架構起來,組成一個“看不見的”圖。
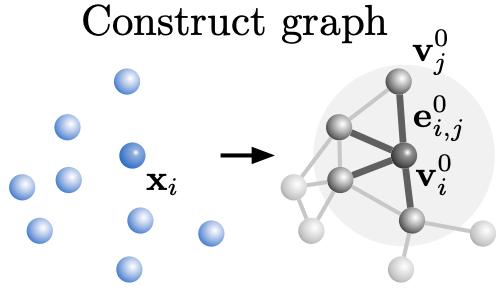
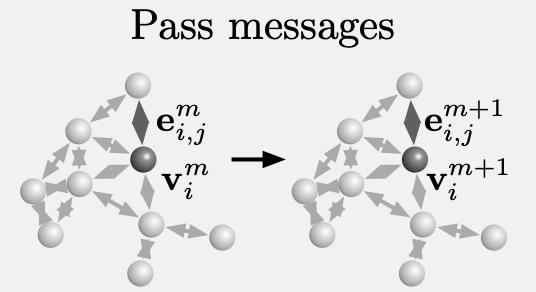
而在處理器中,圖中各顆粒的關系會不斷發生變化,圖網絡學習得到的傳遞信息將會在圖上迭代M次。
最后,解碼器會將迭代好的動力學信息Y,從最后一次迭代出的圖中提取出來。
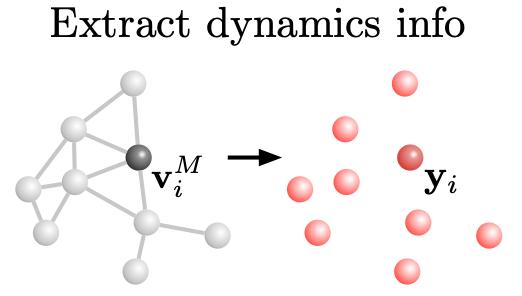
反饋回物體X上后,物體中的顆粒便能一進行一幀幀改變,連續起來就是模擬出的液體形態。
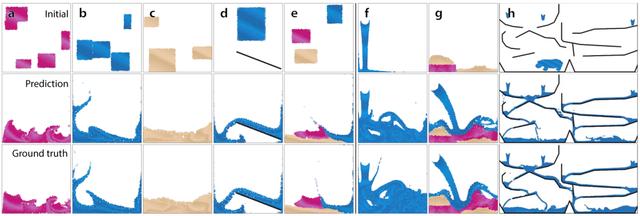
可以看見,無論是哪種物體形態,GNS預測的效果都與真值非常相近。
創新點
與之前一些模擬液體的神經網絡相比,GNS最大的改進在于,它將不同的物體類型,轉變成了輸入向量的一個特征。
只需要將不同的物體類型(例如沙子、水、膠質物等)用不同特征區分,就能表現出它們的狀態。
相比之下,此前一個名為DLP的、基于神經網絡的液體模擬器,與GNS相比就過于復雜。
同樣是模擬各種流體模型,DLP則需要不斷地保存顆粒之間的相對位移,甚至需要修改模型來滿足不同的流體類型——所需要的運算量過于龐大。
不僅如此,GNS的模擬效果竟然還比基于DLP的模擬器更好。
細節更出眾
下面是GNS與一款基于DLP原理的增強版CConv模擬器的效果對比。
與CConv相比,GNS在不同物體類型的模擬表現上依舊非常優秀,下圖是二者共同模擬一個漂浮在水上的方塊時,所生成的效果。

可以看見,GNS生成的方塊和真值一樣,在水中漂浮自如;相比之下,CConv生成的方塊直接在水的沖擊下變了形(被生活擊垮)。
如果采用與真實值相比的均方誤差(MSE)進行對比的話,在各種物體形態下,GNS都要比CConv效果更佳。
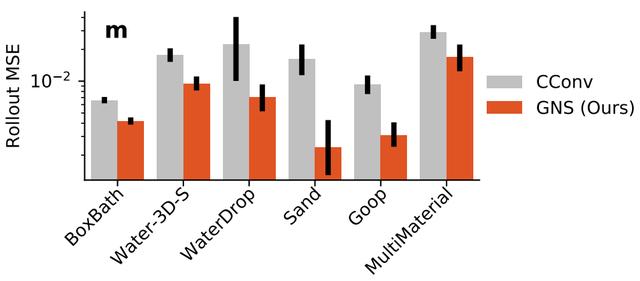
除此之外,下圖展示了GNS分別采用強化學習中Rollout和One-step兩種算法策略的均方誤差效果。(以及迭代次數、是否共享GN參數、連接半徑、訓練噪聲量、關聯/獨立編碼器等)
可見,采取Rollout的效果(下半部分)在各方面都要比采取One-step的效果好得多。
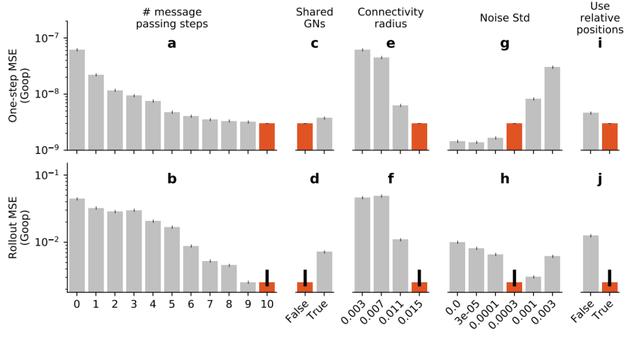
不僅如此,紅色部分是GNS模型最終采用的策略,可見,所有策略都將均方誤差降到了最低。
四位共同一作
這項研究主要由DeepMind和斯坦福大學合作。
論文的共同一作共四位。
△ Alvaro Sanchez-Gonzalez
Alvaro Sanchez-Gonzalez 本科和碩士攻讀的專業分別是物理和計算機,基于這樣的背景,在博士期間,他主要專注于使用計算機方法來解決物理研究中的一些挑戰。
2017年加入谷歌DeepMind團隊,研究主要集中在結構化方法、強化學習等。
△ Jonathan Godwin
Jonathan Godwin在2018年3月加入DeepMind,并于2019年11月晉升為高級研究工程師。
此前,他也有過自己創業的經歷,分別是信息科技服務公司Bit by Bit Computer Consulting和金融公司Community Capital的CEO。
在創業后和加入DeepMind之前,他還在計算機軟件公司Bloomsbury AI做了一年多的機器學習工程師。
△Tobias Pfaff
Tobias Pfaff 是DeepMind的一名研究科學家,從事物理模擬和機器學習的交叉研究。
分別在蘇黎世聯邦理工學院和加州伯克利分校,完成博士和博士后的學習任務。
△Rex Ying
第四位共同一作是Rex Ying,目前在斯坦福大學攻讀博士學位,研究主要集中在開發應用于圖形結構數據的機器學習算法。
2016年以最高榮譽畢業于杜克大學,主修計算機科學和數學兩個專業。
……
最后,對于AI通過「看」來模擬如此復雜的流體運動,網友認為:
腦能模擬各種復雜運動,靠的就是神經網絡,而不是復雜的力學公式。

不僅如此,這項技術或許還大幅降低影視、游戲行業特效成本。
那么,這樣的技術,你看好嗎?















