













9個技巧讓你的PyTorch模型訓練變得飛快!
不要讓你的神經網絡變成這樣
讓我們面對現實吧,你的模型可能還停留在石器時代。我敢打賭你仍然使用32位精度或GASP甚至只在一個GPU上訓練。
我明白,網上都是各種神經網絡加速指南,但是一個checklist都沒有(現在有了),使用這個清單,一步一步確保你能榨干你模型的所有性能。
本指南從最簡單的結構到最復雜的改動都有,可以使你的網絡得到最大的好處。我會給你展示示例Pytorch代碼以及可以在Pytorch- lightning Trainer中使用的相關flags,這樣你可以不用自己編寫這些代碼!
**這本指南是為誰準備的?**任何使用Pytorch進行深度學習模型研究的人,如研究人員、博士生、學者等,我們在這里談論的模型可能需要你花費幾天的訓練,甚至是幾周或幾個月。
我們會講到:
- 使用DataLoaders
- DataLoader中的workers數量
- Batch size
- 梯度累計
- 保留的計算圖
- 移動到單個
- 16-bit 混合精度訓練
- 移動到多個GPUs中(模型復制)
- 移動到多個GPU-nodes中 (8+GPUs)
- 思考模型加速的技巧
Pytorch-Lightning
你可以在Pytorch的庫Pytorch- lightning中找到我在這里討論的每一個優化。Lightning是在Pytorch之上的一個封裝,它可以自動訓練,同時讓研究人員完全控制關鍵的模型組件。Lightning 使用最新的最佳實踐,并將你可能出錯的地方最小化。
我們為MNIST定義LightningModel并使用Trainer來訓練模型。
- from pytorch_lightning import Trainer
- model = LightningModule(…)
- trainer = Trainer()
- trainer.fit(model)
1. DataLoaders

這可能是最容易獲得速度增益的地方。保存h5py或numpy文件以加速數據加載的時代已經一去不復返了,使用Pytorch dataloader加載圖像數據很簡單(對于NLP數據,請查看TorchText)。
在lightning中,你不需要指定訓練循環,只需要定義dataLoaders和Trainer就會在需要的時候調用它們。
- dataset = MNIST(root=self.hparams.data_root, traintrain=train, download=True)
- loader = DataLoader(dataset, batch_size=32, shuffle=True)
- for batch in loader:
- x, y = batch
- model.training_step(x, y)
- ...
2. DataLoaders 中的 workers 的數量

另一個加速的神奇之處是允許批量并行加載。因此,您可以一次裝載nb_workers個batch,而不是一次裝載一個batch。
- # slow
- loader = DataLoader(dataset, batch_size=32, shuffle=True)
- # fast (use 10 workers)
- loader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=10)
3. Batch size
在開始下一個優化步驟之前,將batch size增大到CPU-RAM或GPU-RAM所允許的最大范圍。
下一節將重點介紹如何幫助減少內存占用,以便你可以繼續增加batch size。
記住,你可能需要再次更新你的學習率。一個好的經驗法則是,如果batch size加倍,那么學習率就加倍。
4. 梯度累加

在你已經達到計算資源上限的情況下,你的batch size仍然太小(比如8),然后我們需要模擬一個更大的batch size來進行梯度下降,以提供一個良好的估計。
假設我們想要達到128的batch size大小。我們需要以batch size為8執行16個前向傳播和向后傳播,然后再執行一次優化步驟。
- # clear last step
- optimizer.zero_grad()
- # 16 accumulated gradient steps
- scaled_loss = 0
- for accumulated_step_i in range(16):
- out = model.forward()
- loss = some_loss(out,y)
- loss.backward()
- scaled_loss += loss.item()
- # update weights after 8 steps. effective batch = 8*16
- optimizer.step()
- # loss is now scaled up by the number of accumulated batches
- actual_loss = scaled_loss / 16
在lightning中,全部都給你做好了,只需要設置accumulate_grad_batches=16:
- trainer = Trainer(accumulate_grad_batches=16)
- trainer.fit(model)
5. 保留的計算圖
一個最簡單撐爆你的內存的方法是為了記錄日志存儲你的loss。
- losses = []
- ...
- losses.append(loss)
- print(f'current loss: {torch.mean(losses)'})
上面的問題是,loss仍然包含有整個圖的副本。在這種情況下,調用.item()來釋放它。
- # bad
- losses.append(loss)
- # good
- losses.append(loss.item())
Lightning會非常小心,確保不會保留計算圖的副本。
6. 單個GPU訓練
一旦你已經完成了前面的步驟,是時候進入GPU訓練了。在GPU上的訓練將使多個GPU cores之間的數學計算并行化。你得到的加速取決于你所使用的GPU類型。我推薦個人用2080Ti,公司用V100。
乍一看,這可能會讓你不知所措,但你真的只需要做兩件事:1)移動你的模型到GPU, 2)每當你運行數據通過它,把數據放到GPU上。
- # put model on GPU
- model.cuda(0)
- # put data on gpu (cuda on a variable returns a cuda copy)
- xx = x.cuda(0)
- # runs on GPU now
- model(x)
如果你使用Lightning,你什么都不用做,只需要設置Trainer(gpus=1)。
- # ask lightning to use gpu 0 for training
- trainer = Trainer(gpus=[0])
- trainer.fit(model)
在GPU上進行訓練時,要注意的主要事情是限制CPU和GPU之間的傳輸次數。
- # expensive
- xx = x.cuda(0)# very expensive
- xx = x.cpu()
- xx = x.cuda(0)
如果內存耗盡,不要將數據移回CPU以節省內存。在求助于GPU之前,嘗試以其他方式優化你的代碼或GPU之間的內存分布。
另一件需要注意的事情是調用強制GPU同步的操作。清除內存緩存就是一個例子。
- # really bad idea. Stops all the GPUs until they all catch up
- torch.cuda.empty_cache()
但是,如果使用Lightning,惟一可能出現問題的地方是在定義Lightning Module時。Lightning會特別注意不去犯這類錯誤。
7. 16-bit 精度
16bit精度是將內存占用減半的驚人技術。大多數模型使用32bit精度數字進行訓練。然而,最近的研究發現,16bit模型也可以工作得很好。混合精度意味著對某些內容使用16bit,但將權重等內容保持在32bit。
要在Pytorch中使用16bit精度,請安裝NVIDIA的apex庫,并對你的模型進行這些更改。
- # enable 16-bit on the model and the optimizer
- model, optimizers = amp.initialize(model, optimizers, opt_level='O2')
- # when doing .backward, let amp do it so it can scale the loss
- with amp.scale_loss(loss, optimizer) as scaled_loss:
- scaled_loss.backward()
amp包會處理好大部分事情。如果梯度爆炸或趨向于0,它甚至會縮放loss。
在lightning中,啟用16bit并不需要修改模型中的任何內容,也不需要執行我上面所寫的操作。設置Trainer(precision=16)就可以了。
- trainer = Trainer(amp_level='O2', use_amp=False)
- trainer.fit(model)
8. 移動到多個GPUs中
現在,事情變得非常有趣了。有3種(也許更多?)方法來進行多GPU訓練。
分batch訓練
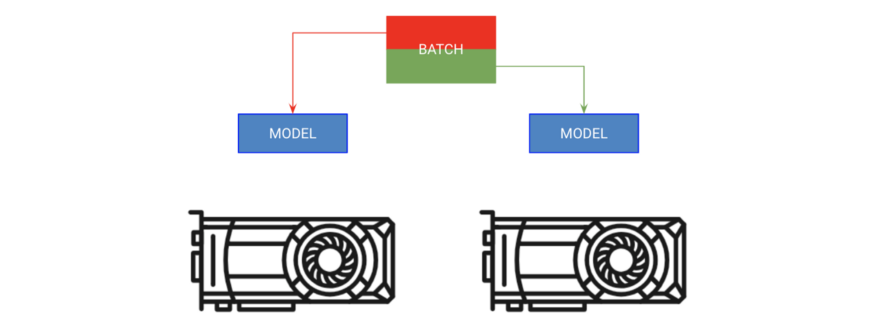
A) 拷貝模型到每個GPU中,B) 給每個GPU一部分batch
第一種方法被稱為“分batch訓練”。該策略將模型復制到每個GPU上,每個GPU獲得batch的一部分。
- # copy model on each GPU and give a fourth of the batch to each
- model = DataParallel(model, devices=[0, 1, 2 ,3])
- # out has 4 outputs (one for each gpu)
- out = model(x.cuda(0))
在lightning中,你只需要增加GPUs的數量,然后告訴trainer,其他什么都不用做。
- # ask lightning to use 4 GPUs for training
- trainer = Trainer(gpus=[0, 1, 2, 3])
- trainer.fit(model)
模型分布訓練
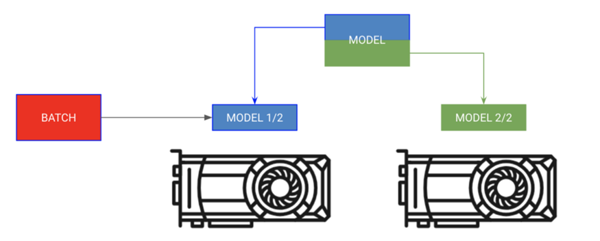
將模型的不同部分放在不同的GPU上,batch按順序移動
有時你的模型可能太大不能完全放到內存中。例如,帶有編碼器和解碼器的序列到序列模型在生成輸出時可能會占用20GB RAM。在本例中,我們希望將編碼器和解碼器放在獨立的GPU上。
- # each model is sooo big we can't fit both in memory
- encoder_rnn.cuda(0)
- decoder_rnn.cuda(1)
- # run input through encoder on GPU 0
- encoder_out = encoder_rnn(x.cuda(0))
- # run output through decoder on the next GPU
- out = decoder_rnn(encoder_out.cuda(1))
- # normally we want to bring all outputs back to GPU 0
- outout = out.cuda(0)
對于這種類型的訓練,在Lightning中不需要指定任何GPU,你應該把LightningModule中的模塊放到正確的GPU上。
- class MyModule(LightningModule):
- def __init__():
- self.encoder = RNN(...)
- self.decoder = RNN(...)
- def forward(x):
- # models won't be moved after the first forward because
- # they are already on the correct GPUs
- self.encoder.cuda(0)
- self.decoder.cuda(1)
- out = self.encoder(x)
- out = self.decoder(out.cuda(1))
- # don't pass GPUs to trainer
- model = MyModule()
- trainer = Trainer()
- trainer.fit(model)
兩者混合
在上面的情況下,編碼器和解碼器仍然可以從并行化操作中獲益。
- # change these lines
- self.encoder = RNN(...)
- self.decoder = RNN(...)
- # to these
- # now each RNN is based on a different gpu set
- self.encoder = DataParallel(self.encoder, devices=[0, 1, 2, 3])
- self.decoder = DataParallel(self.encoder, devices=[4, 5, 6, 7])
- # in forward...
- out = self.encoder(x.cuda(0))
- # notice inputs on first gpu in device
- sout = self.decoder(out.cuda(4)) # <--- the 4 here
使用多個GPU時要考慮的注意事項:
- 如果模型已經在GPU上了,model.cuda()不會做任何事情。
- 總是把輸入放在設備列表中的第一個設備上。
- 在設備之間傳輸數據是昂貴的,把它作為最后的手段。
- 優化器和梯度會被保存在GPU 0上,因此,GPU 0上使用的內存可能會比其他GPU大得多
9. 多節點GPU訓練

每臺機器上的每個GPU都有一個模型的副本。每臺機器獲得數據的一部分,并且只在那部分上訓練。每臺機器都能同步梯度。
如果你已經做到了這一步,那么你現在可以在幾分鐘內訓練Imagenet了!這并沒有你想象的那么難,但是它可能需要你對計算集群的更多知識。這些說明假設你正在集群上使用SLURM。
Pytorch允許多節點訓練,通過在每個節點上復制每個GPU上的模型并同步梯度。所以,每個模型都是在每個GPU上獨立初始化的,本質上獨立地在數據的一個分區上訓練,除了它們都從所有模型接收梯度更新。
在高層次上:
- 在每個GPU上初始化一個模型的副本(確保設置種子,讓每個模型初始化到相同的權重,否則它會失敗)。
- 將數據集分割成子集(使用DistributedSampler)。每個GPU只在它自己的小子集上訓練。
- 在.backward()上,所有副本都接收到所有模型的梯度副本。這是模型之間唯一一次的通信。
Pytorch有一個很好的抽象,叫做DistributedDataParallel,它可以幫你實現這個功能。要使用DDP,你需要做4的事情:
- def tng_dataloader():
- d = MNIST()
- # 4: Add distributed sampler
- # sampler sends a portion of tng data to each machine
- dist_sampler = DistributedSampler(dataset)
- dataloader = DataLoader(d, shuffle=False, sampler=dist_sampler)
- def main_process_entrypoint(gpu_nb):
- # 2: set up connections between all gpus across all machines
- # all gpus connect to a single GPU "root"
- # the default uses env://
- world = nb_gpus * nb_nodes
- dist.init_process_group("nccl", rank=gpu_nb, worldworld_size=world)
- # 3: wrap model in DPP
- torch.cuda.set_device(gpu_nb)
- model.cuda(gpu_nb)
- model = DistributedDataParallel(model, device_ids=[gpu_nb])
- # train your model now...
- if __name__ == '__main__':
- # 1: spawn number of processes
- # your cluster will call main for each machine
- mp.spawn(main_process_entrypoint, nprocs=8)
然而,在Lightning中,只需設置節點數量,它就會為你處理其余的事情。
- # train on 1024 gpus across 128 nodes
- trainer = Trainer(nb_gpu_nodes=128, gpus=[0, 1, 2, 3, 4, 5, 6, 7])
Lightning還附帶了一個SlurmCluster管理器,可以方便地幫助你提交SLURM作業的正確詳細信息。
10. 福利!在單個節點上多GPU更快的訓練
事實證明,distributedDataParallel比DataParallel快得多,因為它只執行梯度同步的通信。所以,一個好的hack是使用distributedDataParallel替換DataParallel,即使是在單機上進行訓練。
在Lightning中,這很容易通過將distributed_backend設置為ddp和設置GPUs的數量來實現。
- # train on 4 gpus on the same machine MUCH faster than DataParallel
- trainer = Trainer(distributed_backend='ddp', gpus=[0, 1, 2, 3])
對模型加速的思考
盡管本指南將為你提供了一系列提高網絡速度的技巧,但我還是要給你解釋一下如何通過查找瓶頸來思考問題。
我將模型分成幾個部分:
首先,我要確保在數據加載中沒有瓶頸。為此,我使用了我所描述的現有數據加載解決方案,但是如果沒有一種解決方案滿足你的需要,請考慮離線處理和緩存到高性能數據存儲中,比如h5py。
接下來看看你在訓練步驟中要做什么。確保你的前向傳播速度快,避免過多的計算以及最小化CPU和GPU之間的數據傳輸。最后,避免做一些會降低GPU速度的事情(本指南中有介紹)。
接下來,我試圖最大化我的batch size,這通常是受GPU內存大小的限制。現在,需要關注在使用大的batch size的時候如何在多個GPUs上分布并最小化延遲(比如,我可能會嘗試著在多個gpu上使用8000 +的有效batch size)。
然而,你需要小心大的batch size。針對你的具體問題,請查閱相關文獻,看看人們都忽略了什么!



















