機器學習平臺在Kubernetes上的實踐
背景
過去音樂算法的模型訓練任務,是在物理機上進行開發、調試以及定時調度。每個算法團隊使用屬于自己的獨立物理機,這種現狀會造成一些問題。比如物理機的分布零散,缺乏統一的管理,主要依賴于doc文檔的表格記錄機器的使用與歸屬;各業務間機器資源的調配,有時需要機器在不同機房的搬遷,耗時耗力。另外,由于存在多人共用、開發與調度任務共用等情況,會造成環境的相互影響,以及資源的爭奪。針對當前的情況,總結問題如下:
- 資源利用率低:部分機器資源利用率偏低;無法根據各個業務的不同階段,在全局內快速、動態的實現擴縮容,以達到資源的合理配置,提升資源整體利用率;
- 環境相互影響:存在多人共用、測試與調度混用同一開發機,未做任何的隔離,造成可能的環境、共享資源的相互影響與爭奪;
- 監控報警缺失:物理機模式,任務監控報警功能缺失,導致任務無法運維,或者效率低。
資源沒有全局統一的合理調配,會出現負載不均衡,資源不能最大化的利用。
Kubernetes的嘗試
在快速的擴縮容、環境隔離、資源監控等方面,Kubernetes及其相關擴展,可以很好的解決問題。現將物理機集中起來,并構建成一個Kubernetes集群。通過分析算法同事以往的工作方式,機器學習平臺(GoblinLab)決定嘗試基于Kubernetes提供在線的開發調試容器環境以及任務的容器化調度兩種方案,其分別針對任務開發和任務調度兩種場景。
任務開發
為最大化的減少算法同事由物理機遷移到容器化環境的學習成本,GoblinLab系統中基本將Kubernetes的容器當做云主機使用。容器的鏡像以各版本Tensoflow鏡像為基礎(底層是Ubuntu),集成了大數據開發環境(Hadoop、Hive、Spark等Client),安裝了常用的軟件。另外,為了方便使用,容器環境提供了Jupyter Lab、SSH登錄、Code Server(VSCode)三種使用方式。
在GoblinLab中新建容器化開發環境比較簡單,只需選擇鏡像,填寫所需的資源,以及需要掛載的外部存儲即可(任務開發的環境下文簡稱開發實例)。
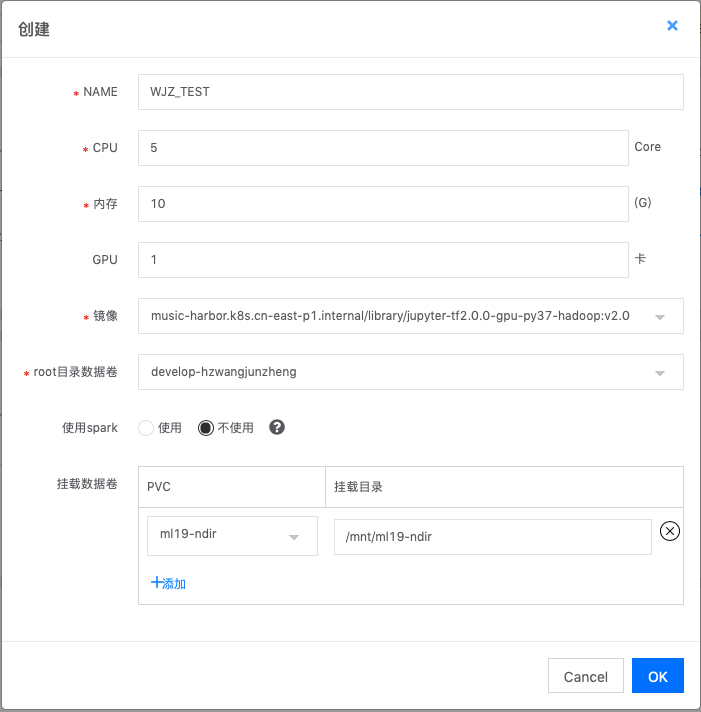
新建環境配置后,點擊啟動實例,容器初始化時,會自動啟動Jupyter lab、SSH以及CodeServer。

Jupyter Lab:
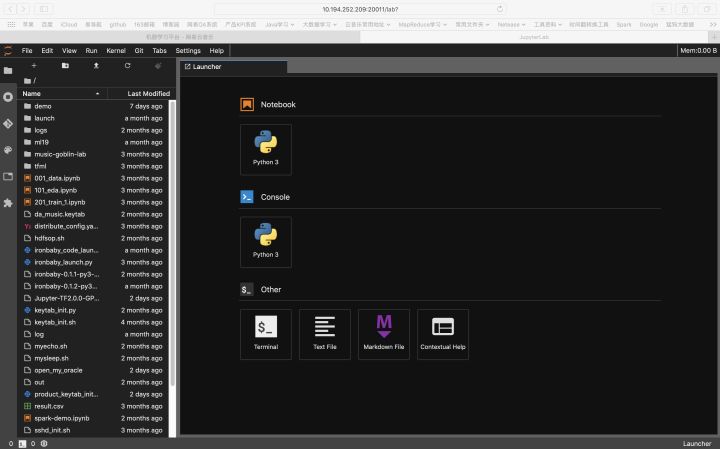
Code Server:
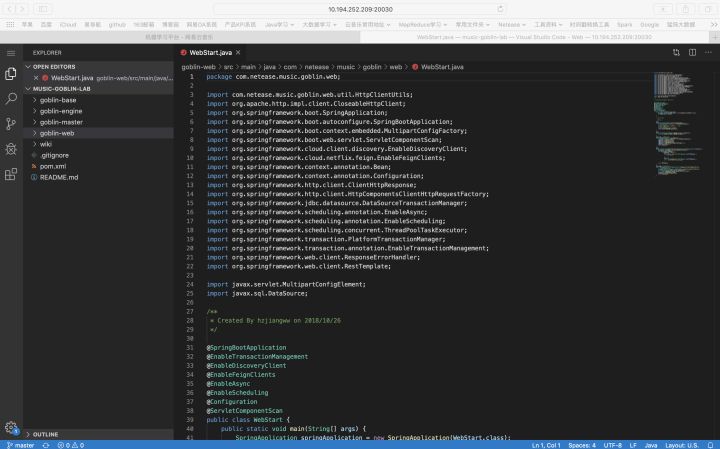
SSH登錄:
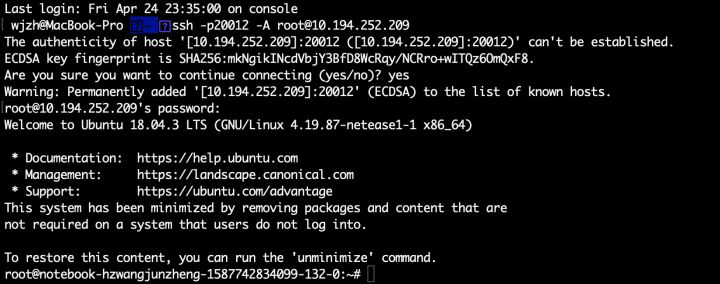
算法可以選擇以上任意一種方式進行任務的開發,或者調試。由于提供了Code Server(VSCode),所以可以獲得更好的體驗。
任務開發所用的容器化環境,在底層Kubernetes上是通過StatefulSet類型實現,對應資源編排文件如下(已精簡細節):
- kind: StatefulSet
- apiVersion: apps/v1
- metadata:
- name: ${name}
- namespace: "${namespace}"
- spec:
- replicas: 1
- selector:
- matchLabels:
- statefulset: ${name}
- system/app: ${name}
- template:
- spec:
- <#if (gpu > 0)>
- tolerations:
- - effect: NoSchedule
- key: nvidia.com/gpu
- value: "true"
- </#if>
- <#if usePrivateRepository == "true">
- imagePullSecrets:
- - name: registrykey-myhub
- </#if>
- volumes:
- - name: localtime
- hostPath:
- path: /etc/localtime
- <#if MountPVCs?? && (MountPVCs?size > 0)>
- <#list MountPVCs?keys as key>
- - name: "${key}"
- persistentVolumeClaim:
- claimName: "${key}"
- </#list>
- containers:
- - name: notebook
- image: ${image}
- imagePullPolicy: IfNotPresent
- volumeMounts:
- - name: localtime
- mountPath: /etc/localtime
- <#if readMountPVCs?? && (readMountPVCs?size > 0)>
- <#list readMountPVCs?keys as key>
- - name: "${key}"
- mountPath: "${readMountPVCs[key]}"
- readOnly: true
- </#list>
- </#if>
- <#if writeMountPVCs?? && (writeMountPVCs?size > 0)>
- <#list writeMountPVCs?keys as key>
- - name: "${key}"
- mountPath: "${writeMountPVCs[key]}"
- </#list>
- </#if>
- env:
- - name: NOTEBOOK_TAG
- value: "${name}"
- - name: HADOOP_USER
- value: "${hadoopUser}"
- - name: PASSWORD
- value: "${password}"
- resources:
- requests:
- cpu: ${cpu}
- memory: ${memory}Gi
- <#if (gpu > 0)>
- nvidia.com/gpu: ${gpu}
- </#if>
- limits:
- cpu: ${cpu}
- memory: ${memory}Gi
- <#if (gpu > 0)>
- nvidia.com/gpu: ${gpu}
- </#if>
目前GolbinLab已提供基于Tensoflow各版本的CPU與GPU通用鏡像11個,以及多個定制化鏡像。
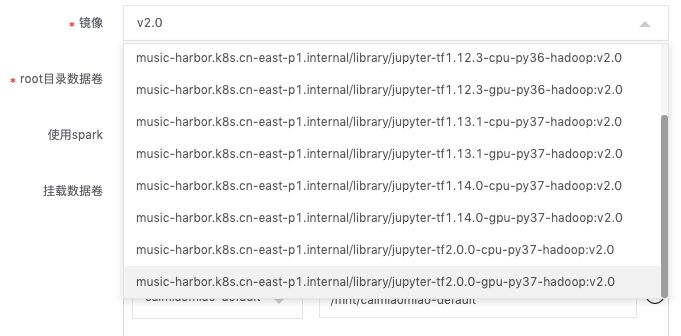
任務調度
算法同事在使用容器化環境之前,任務的開發調度都是在GPU物理機器上完成,調度一般都是通過定時器或crontab命令調度任務,任務無失敗、超時等報警,以及也沒有重試等機制,基本無相關的任務運維工具。
在介紹容器中開發的任務如何上線調度之前,先簡要介紹一下GoblinLab的系統架構。
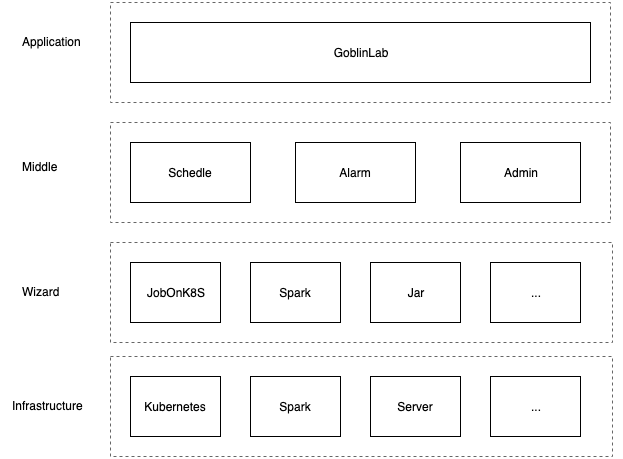
上圖為GoblinLab簡化的系統架構,其中主要分為四層,由上到下分別為:
- Application-應用層:提供直接面向用戶的機器學習開發平臺(GoblinLab)
- Middle-中間層: 中間層,主要是接入了統一的調度、報警、以及配置等服務
- Wizard-執行服務: 其提供統一的執行服務,提供包含Kubernetes、Spark、Jar等各類任務的提交執行。插件式,支持快速擴展
- Infrastructure-基礎設施: 底層的基礎設施,主要包含Kubernetes集群、Spark集群以及普通服務器等
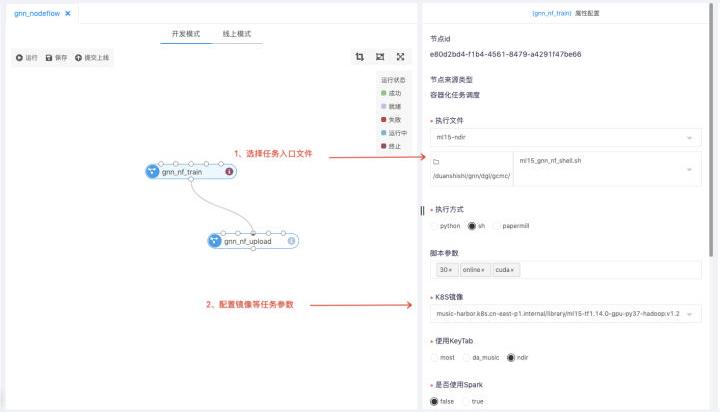
GolbinLab為了保障調度任務的穩定性,將任務的開發與調度拆分,改變之前算法直接在物理機上開發完任務后,通過定時器或者crontab調度任務的方式。如上圖所示,在開發完成后,任務的調度是通過任務流中的容器化任務調度組件實現,用戶需填組件的相關參數(代碼所在PVC及路徑,配置鏡像等),再通過任務流的調度功能實現任務調度。與任務開發不同,每個調度任務執行在獨立的容器中,保證任務間相互隔離,同時通過后續介紹的資源隔離方案,可以優先保障線上調度任務所需資源。

任務調度執行的一般流程如下:

任務調度執行時在Kubernetes上資源編排文件(已精簡細節):
- apiVersion: batch/v1
- kind: Job
- metadata:
- name: ${name}
- namespace: ${namespace}
- spec:
- template:
- spec:
- containers:
- - name: jupyter-job
- image: ${image}
- env:
- - name: ENV_TEST
- value: ${envTest}
- command: ["/bin/bash", "-ic", "cd ${workDir} && \
- ${execCommand} /root/${entryPath} ${runArgs}"]
- volumeMounts:
- - mountPath: "/root"
- name: "root-dir"
- resources:
- requests:
- cpu: ${cpu}
- memory: ${memory}Gi
- <#if (gpu > 0)>
- nvidia.com/gpu: ${gpu}
- </#if>
- limits:
- cpu: ${cpu}
- memory: ${memory}Gi
- <#if (gpu > 0)>
- nvidia.com/gpu: ${gpu}
- </#if>
- volumes:
- - name: "root-dir"
- persistentVolumeClaim:
- claimName: "${pvc}"
- backoffLimit: 0
權限控制
容器化開發環境配置啟動后,用戶可以通過SSH登錄、CodeServer或JupyterLab等其中一種方式使用。為了避免容器化開發環境被其他人使用,GoblinLab給每種方式都設置了統一的密鑰,而密鑰在每次啟動時隨機生成。
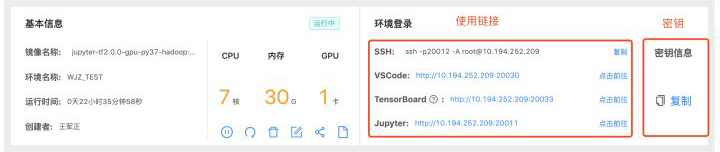
1、隨機生成密碼
2、設置賬號密碼(SSH登錄密碼)
- echo "root:${password}" | chpasswd
3、設置Code Server密碼 (VSCode)
- #設置環境變量PASSWORD即可
- env:
- - name: PASSWORD
- value: "${password}"
4、設置Jupyter Lab密碼
- jupyter notebook --generate-config,~/.jupyter 目錄下生成jupyter_notebook_config.py,并添加代碼
- import os
- from IPython.lib import passwd
- c = c # pylint:disable=undefined-variable
- c.NotebookApp.ip = '0.0.0.0' # https://github.com/jupyter/notebook/issues/3946 c.NotebookApp.port = int(os.getenv('PORT', 8888)) c.NotebookApp.open_browser = False
- sets a password if PASSWORD is set in the environment
- if 'PASSWORD' in os.environ:
- password = os.environ['PASSWORD']
- if password:
- c.NotebookApp.password = passwd(password)
- else:
- c.NotebookApp.password = ''
- c.NotebookApp.token = ''
- del os.environ['PASSWORD']
數據持久化
在Kubernetes容器中,如無特殊配置,容器中的數據是沒有進行持久化,這意味著隨著容器的刪除或者重啟,數據就會丟失。對應的解決方法比較簡單,只需給需要持久化的目錄,掛載外部存儲即可。在GoblinLab中,會給每個用戶自動創建一個默認的外部存儲PVC,并掛載到容器的/root目錄。另外,用戶也可以自定義外部存儲的掛載。
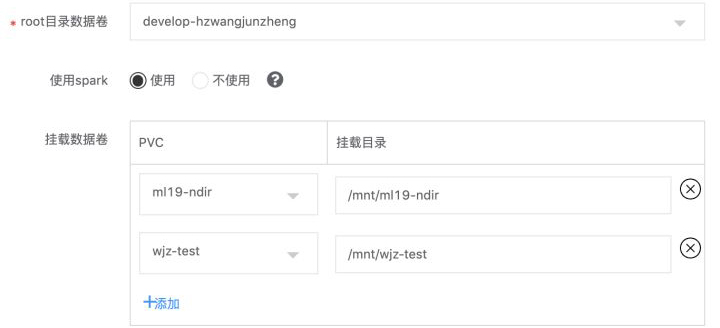
除了自動創建的PVC外,用戶也可以自己創建PVC,并支持將創建的PVC只讀或者讀寫分享給其他人。
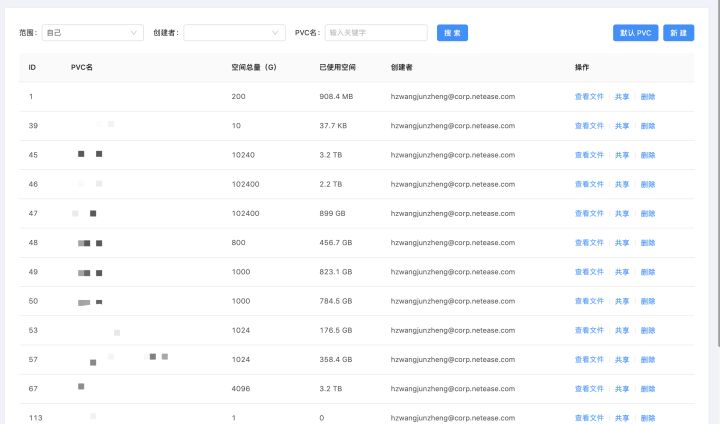
另外,在Goblinlab上也可以對PVC里的數據進行管理。

服務暴露
Kubernetes集群中創建的服務,在集群外無法直接訪問,GoblinLab使用Nginx Ingress + Gateway訪問,將集群內的服務暴露到外部。
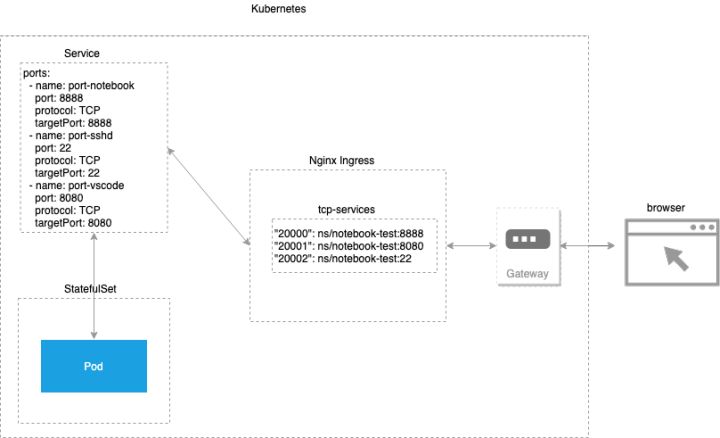
容器化開發環境的Service資源編排文件如下(已精簡細節):
- apiVersion: v1
- kind: Service
- metadata:
- name: ${name}
- namespace: ${namespace}
- spec:
- clusterIP: None
- ports:
- - name: port-notebook
- port: 8888
- protocol: TCP
- targetPort: 8888
- - name: port-sshd
- port: 22
- protocol: TCP
- targetPort: 22
- - name: port-vscode
- port: 8080
- protocol: TCP
- targetPort: 8080
- - name: port-tensofboard
- port: 6006
- protocol: TCP
- targetPort: 6006
- <#if ports?? && (ports?size > 0)>
- <#list ports as port>
- - name: port-${port}
- port: ${port}
- targetPort: ${port}
- </#list>
- </#if>
- selector:
- statefulset: ${name}
- type: ClusterIP
每當用戶啟動一個容器化開發環境,GoblinLab將通過接口自動修改Nginx Ingress配置,將服務暴露出來,以供用戶使用,Ingress轉發配置如下:
- apiVersion: v1
- kind: ConfigMap
- metadata:
- name: tcp-services
- namespace: kube-system
- data:
- "20000": ns/notebook-test:8888
- "20001": ns/notebook-test:8080
- "20002": ns/notebook-test:22
資源管控
為提高資源的利用率,GoblinLab底層Kubernetes中的資源,基本都是以共享的方式使用,并進行一定比例的超售。但是當多個團隊共享一個資源總量固定的集群時,為了確保每個團隊公平的共享資源,此時需要對資源進行管理和控制。在Kubernetes中,資源配額就是解決此問題的工具。目前GoblinLab需要管控的資源主要為CPU、內存、GPU以及存儲等。平臺在考慮各個團隊的實際需求后,將資源劃分為多個隊列(Kubernetes中的概念為namespace),提供給各個團隊使用。
- apiVersion: v1
- kind: ResourceQuota
- metadata:
- name: skiff-quota
- namespace: test
- spec:
- hard:
- limits.cpu: "2"
- limits.memory: 5Gi
- requests.cpu: "2"
- requests.memory: 5Gi
- requests.nvidia.com/gpu: "1"
- requests.storage: 10Gi
在集群中,最常見的資源為CPU與內存,由于可以超售(overcommit),所以存在limits與requests兩個配額限制。除此以外,其他資源為擴展類型,由于不允許overcommit,所以只有requests配額限制。參數說明:
- limits.cpu:Across all pods in a non-terminal state, the sum of CPU limits cannot exceed this value.
- limits.memory: Across all pods in a non-terminal state, the sum of memory limits cannot exceed this value.
- requests.cpu:Across all pods in a non-terminal state, the sum of CPU requests cannot exceed this value.
- requests.memory:Across all pods in a non-terminal state, the sum of memory requests cannot exceed this value.
- http://requests.nvidia.com/gpu:Across all pods in a non-terminal state, the sum of gpu requests cannot exceed this value.
- requests.storage:Across all persistent volume claims, the sum of storage requests cannot exceed this value.
可以進行配額控制的資源不僅有CPU、內存、存儲、GPU,其他類型參見官方文檔:https://kubernetes.io/docs/con ... otas/
資源隔離
GoblinLab的資源隔離,指的是在同一Kubernetes集群中,資源在調度層面的相對隔離,其中包含GPU機器資源的隔離、線上與測試任務的隔離。
GPU機器資源的隔離
在Kubernetes集群中,相對于CPU機器,GPU機器資源較為珍貴,因此為了提供GPU的利用率,禁止CPU任務調度在GPU機器上。
GPU節點設置污點(Taint):禁止一般任務調度在GPU節點
- key: nvidia.com/gpu
- value: true
- effect: NoSchedule
Taint的effect可選配置:
- NoSchedule:Pod不會被調度到標記為taints節點。
- PreferNoSchedule:NoSchedule的軟策略版本。盡量避免將Pod調度到存在其不能容忍taint的節點上。
- NoExecute:該選項意味著一旦Taint生效,如該節點內正在運行的Pod沒有對應Tolerate設置,會直接被逐出。
GPU任務設置容忍(Toleration):讓GPU任務可以調度在GPU節點
- <#if (gpu > 0)>
- tolerations:
- - effect: NoSchedule
- key: nvidia.com/gpu
- value: "true"
- </#if>
線上與測試任務隔離
線上與測試任務(GolbinLab中線上任務與測試任務為業務層面的定義,指的是周期調度任務和開發測試任務)使用同一Kubernetes集群,但為了保障線上任務的資源,會特殊設置一些機器節點為線上任務的專有資源池。線上任務執行時優先調度在線上節點上,線上資源池無資源時,也可調度于非線上節點。
線上資源池節點設置污點(Taint):禁止一般任務調度在線上資源池
- key: node.netease.com/node-pool
- value: online
- effect: NoSchedule
線上任務添加容忍(Toleration):允許線上任務調度于線上資源池,但不是必須調度于線上資源池中
- tolerations:
- - effect: NoSchedule
- key: node.netease.com/node-pool
- value: "online"
- operator: Equal
線上資源池中機器節點設置標簽 + 線上任務設置節點親和性(nodeAffinity):優先將線上任務調度在線上資源池中,但如果線上資源池中無已資源,此時也可以調度在其他節點上
線上資源池中節點設置標簽:為了方便,標簽與污點同名:
- node.netease.com/node-pool: online
線上任務設置節點親和性(nodeAffinity):線上任務優先調度在線上資源池中
- affinity:
- nodeAffinity:
- preferredDuringSchedulingIgnoredDuringExecution:
- nodeSelectorTerms:
- - matchExpressions:
- - key: node.netease.com/node-pool
- operator: In
- values:
- - online
目前Node affinity有以下幾種策略,官方文檔affinity-and-anti-affinity:
- requiredDuringSchedulingIgnoredDuringExecution表示Pod必須部署到滿足條件的節點上,如果沒有滿足條件的節點,就不停重試。其中IgnoreDuringExecution表示Pod部署之后運行的時候,如果節點標簽發生了變化,不再滿足Pod指定的條件,Pod也會繼續運行。
- requiredDuringSchedulingRequiredDuringExecution表示Pod必須部署到滿足條件的節點上,如果沒有滿足條件的節點,就不停重試。其中RequiredDuringExecution表示Pod部署之后運行的時候,如果節點標簽發生了變化,不再滿足Pod指定的條件,則重新選擇符合要求的節點。
- preferredDuringSchedulingIgnoredDuringExecution表示優先部署到滿足條件的節點上,如果沒有滿足條件的節點,就忽略這些條件,按照正常邏輯部署。
- preferredDuringSchedulingRequiredDuringExecution表示優先部署到滿足條件的節點上,如果沒有滿足條件的節點,就忽略這些條件,按照正常邏輯部署。其中RequiredDuringExecution表示如果后面節點標簽發生了變化,滿足了條件,則重新調度到滿足條件的節點。
策略生效后效果如下圖所示, 線上任務優先執行與線上資源池節點中,但當線上資源池沒有空閑資源后,線上任務Job5也可以去使用普通節點的資源。

階段性結果
截止今日,音樂機器學習平臺(GoblinLab)在容器化方面的嘗試,已開展了一段時間,并且已經有了階段性的成果。
集群建設
經過近一段時間的嘗試,目前音樂數據平臺的Kubernetes,隨著承載的業務越來越多,以及基于Kubernetes的大數據計算平臺(Flink等)的落地,后續將有大量的CPU資源加入, 其穩定性將會成為比較大的挑戰。
用戶使用
- 任務遷移:目前協助算法同事已完成80%任務遷移
任務開發
- 用戶情況 : 已有60%算法同學使用開發實例的容器化環境;其中用戶來源包含音樂推薦算法、社交視頻推薦算法、搜索算法、音視頻、數據應用、實時計算算法等團隊
- 開發實例:平臺鼓勵組內共用開發實例,限制了每人最多創建3個開發實例
- 任務調度: 覆蓋云音樂音樂推薦、社交視頻推薦算法、搜索算法、音視頻、數據應用、實時計算算法等多個團隊
容器化的好處
對于算法同事,由物理機遷移到機器學習平臺提供容器化的環境,能夠帶來的好處是:
- 更多資源:由于整理資源利用率的提高,將有機會獲取到比之前單獨使用物理機更多的資源;另外資源擴縮容的周期由之前的以天為單位減少到秒級別即可完成
- 更好體驗:通過打通大數據、Git環境,提供多樣化的使用方式(SSH和在線IDE),由機器學習平臺統一維護環境鏡像,避免了每個團隊需自己搭建、運維環境的苦惱
- 更完善的任務調度:GoblinLab的調度,提供了更完善的報警、重試、依賴檢查等功能,并且能夠與之前已有PS、Ironbaby任務的整合,實現在一個任務流的統一調度
- 更好的隔離:環境隔離是容器化的天然優勢。另外資源在調度層面的隔離,可以更好的保障線上任務
- 統一的入口:統一了開發的入口后,可以有更大的操作空間。例如將通用的服務抽象后由平臺直接提供(依賴檢查、調度、報警監控等等)、數據的共享、鏡像的更新以及后面持續的支持服務等
后續規劃
目前音樂機器學習平臺已能提供完整的容器化開發基礎能力,為進一步提高集群的資源利用率、提升運維效率,后續計劃從資源調度策略優化(搶占等)、更豐富的資源監控等方面入手,進一步優化。
作者:網易云音樂數據智能部數據平臺組王軍正