谷歌大腦提出簡化稀疏架構,預訓練速度可達T5的7倍
剛剛,Google Brain 高級研究科學家 Barret Zoph 發帖表示,他們設計了一個名叫「Switch Transformer」的簡化稀疏架構,可以將語言模型的參數量擴展至 1.6 萬億(GPT-3 是 1750 億)。在計算資源相同的情況下,Switch Transformer 的訓練速度可以達到 T5 模型的 4-7 倍。
在深度學習領域,模型通常會對所有輸入重用相同的參數。但 Mixture of Experts (MoE,混合專家) 模型是個例外,它們會為每個輸入的例子選擇不同的參數,結果得到一個稀疏激活模型——雖然參數量驚人,但計算成本恒定。
目前,MoE 模型已在機器翻譯領域取得了令人矚目的成就,但由于模型復雜度高、通信成本高、訓練不夠穩定,其廣泛應用受到了一定的阻礙。
為了解決這些問題,Google Brain 的研究者提出了 Switch Transformer。在 Switch Transformer 的設計中,它們簡化了 MoE 的路由算法(routing algorithm),設計了直觀的改進模型,新模型的通信成本和計算成本都大大降低。此外,他們提出的訓練技術還提高了訓練的穩定性,首次表明大型稀疏模型也可以用低精度(bfloat16)進行訓練。

論文鏈接:https://arxiv.org/pdf/2101.03961.pdf
代碼鏈接:
https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/moe.py
研究者還將新模型與 T5-Base 和 T5-Large 進行了對比,結果表明,在相同的計算資源下,新模型實現了最高 7 倍的預訓練速度提升。這一改進還可以擴展至多語言設置中,在所有的 101 種語言中都測到了新模型相對于 mT5-Base 版本的性能提升。
最后,研究者在 Colossal Clean Crawled Corpus 上進行預訓練,將語言模型的參數量提升至上萬億,且相比 T5-XXL 模型實現了 4 倍加速。
研究者還表示,雖然這項工作著眼于規模,但它也表明,Switch Transformer 架構不僅在具備超級計算機的環境下具有優勢,在只有幾個計算核心的計算機上也是有效的。此外,研究者設計的大型稀疏模型可以被蒸餾為一個小而稠密的版本,同時還能保留稀疏模型質量提升的 30%。
Switch Transformer 的設計原理
Switch Transformer 的主要設計原則是,以一種簡單且計算高效的方式最大化 Transformer 模型的參數量。Kaplan 等人(2020)已經對擴展的效益進行了詳盡的研究,揭示了隨模型、數據集大小以及計算預算變化的冪定律縮放。重要的是,該研究提倡在相對較少數據上訓練大型模型,將其作為計算最優方法。
基于這些,研究者在增加參數量的同時保持每個示例的 FLOP 不變。他們假設參數量與執行的總計算量無關,是可以單獨縮放的重要組件。所以,研究者通過設計一個稀疏激活的模型來實現這一目標,該模型能夠高效地利用 GPU 和 TPU 等為稠密矩陣乘法設計的硬件。
在分布式訓練設置中,模型的稀疏激活層在不同設備上分配唯一的權重。所以,模型權重隨設備數量的增加而增加,同時在每個設備上保持可管理的內存和計算空間。
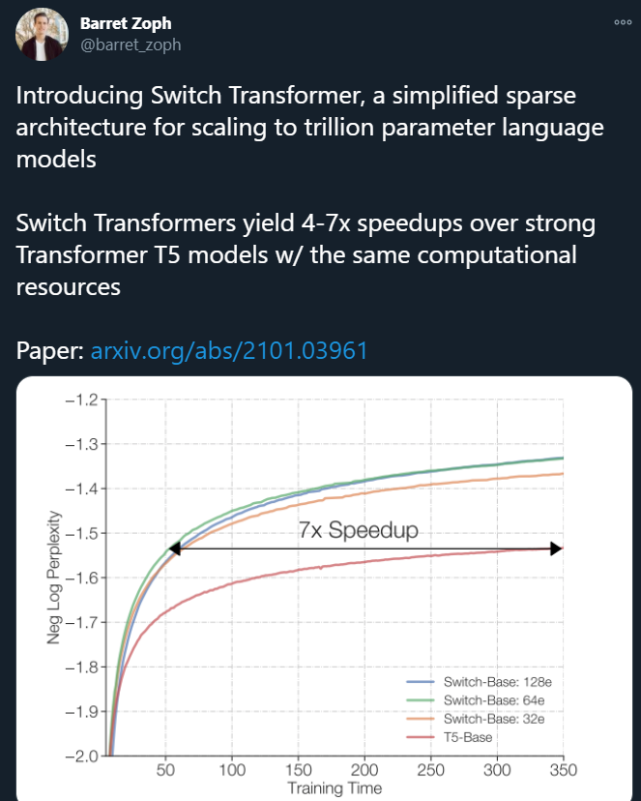
Switch Transformer 的編碼器塊如下圖 2 所示:
簡化稀疏路由
Shazeer 等人(2017)提出了一個自然語言 MoE 層,它以 token 表征 x 為輸入,然后將其發送給最堅定的 top-k 專家(從 N 個專家組成的 ^N_i=1 集合中選出)。他們假設將 token 表征發送給 k>1 個專家是必要的,這樣可以使 routing 函數具備有意義的梯度。他們認為如果沒有對比至少兩個專家的能力,則無法學習路由。
與這些想法不同,谷歌大腦這項研究采用簡化策略,只將 token 表征發送給單個專家。研究表明,這種簡化策略保持了模型質量,降低了路由計算,并且性能更好。研究者將這種 k=1 的策略稱為 Switch 層。
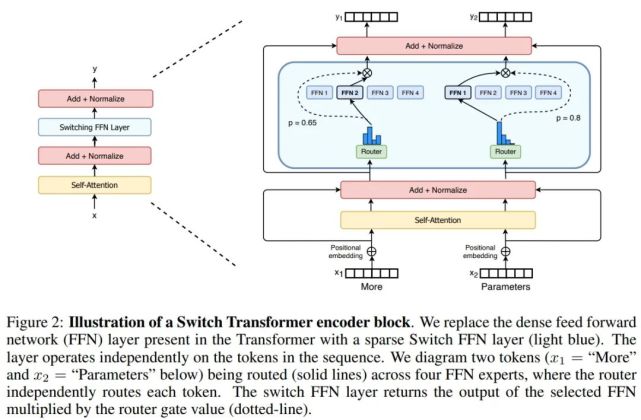
下圖 3 展示了具有不同專家容量因子(expert capacity factor)的路由示例:
高效稀疏路由
研究者使用了 Mesh-Tensorflow 庫 (MTF),它具有類似于 TensorFlow 的語義和 API,可促進高效分布式數據和模型并行架構。研究者在設計模型時考慮到了 TPU,它需要靜態大小。
分布式 Switch Transformer 實現:所有張量形狀在編譯時均得到靜態確定,但由于訓練和推斷過程中的路由決策,計算是動態的。鑒于此,一個重要的技術難題出現了:如何設置專家容量?
專家容量(每個專家計算的 token 數量)的計算方式為:每個批次的 token 數量除以專家數量,再乘以容量因子。如公式(3)所示:
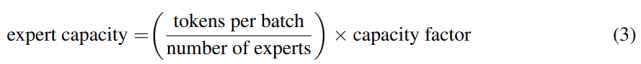
如果將太多 token 發送給一個專家(下文稱為「丟棄的 token」),則會跳過計算,token 表征通過殘差連接直接傳遞到下層。但增加專家容量也不是沒有缺點,數值太高將導致計算和內存浪費。這當著的權衡如上圖 3 所示。
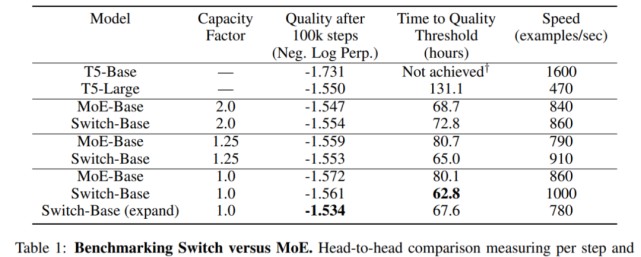
實證研究發現,將丟棄的 token 比例保持在較低水平對于稀疏專家模型的擴展很重要。設計決策對模型質量和速度的影響參見下表 1。
Switch Transformer
研究者首先在 Colossal Clean Crawled Corpus (C4) 數據集上對 Switch Transformer 進行了預訓練測試,使用了掩蔽語言建模任務。在預訓練設置中,他們遵循 Raffel 等人(2019)確定的最優方案,去掉了 15% 的 token,然后使用單個 sentinel token 來替代掩蔽序列。為了比較模型性能,研究者提供了負對數困惑度的結果。
Switch Transformer 與 MoE Transformer 的比較結果如下表 1 所示。結果表明,Switch Transformer 在速度 - 質量(speed-quality)基礎上優于精心調整的稠密模型和 MoE Transformer,并在固定計算量和掛鐘時間情況下取得了最佳結果;Switch Transformer 的計算占用空間比 MoE Transformer 小;Switch Transformer 在低容量因子(1.0, 1.25)下表現更好。
提升訓練和微調的技巧
與原版 Transformer 模型相比,稀疏專家模型在訓練時可能更加困難。所有這些層中的 hard-swithing(路由)決策都可能導致模型的不穩定。此外,像 bfloat16 這樣的低精度格式可能加劇 router 的 softmax 計算問題。研究者采取了以下幾種技巧來克服訓練困難,并實現穩定和可擴展的訓練。
對大型稀疏模型使用可選擇行精度(Selective precision with large sparse models)
為實現穩定性使用更小的參數初始化(Smaller parameter initialization for stability)
正則化大型稀疏模型(Regularizing large sparse models)
預訓練可擴展性
在預訓練期間,研究者對 Switch Transformer 的可擴展性進行了研究。在此過程中,他們考慮了一個算力和數據都不受限制的機制。為了避免數據受限,研究者使用了大型 C4 數據庫,里面包含 180B 的目標 token。在觀察到收益遞減之前,他們一直進行訓練。
專家的數量是擴展模型最有效的維度。增加專家的數量幾乎不會改變計算成本,因為模型只為每個 token 選擇一個專家,這與專家的總體數量無關。router 必須基于更多的專家計算概率分布,但這是一個輕量級的計算成本 O(d_model × num experts)。其中,d_model 是層與層之間所傳遞的 token 的嵌入維度。在這一部分,研究者以固定的計算成本考慮基于步數和時間的可伸縮性。
基于步數的可擴展性
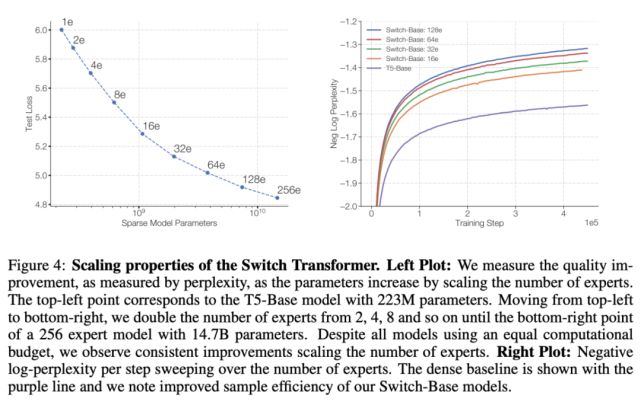
下圖 4 展示了多個模型在訓練步數恒定、專家數量增加時表現出的可擴展性提升情況。從中可以觀察到一個趨勢:在保持每個 token 的 FLOPS 不變時,擁有更多的參數(專家)可以提高訓練速度。
基于時間的可擴展性
如上圖 4 所示,隨著專家數量的增加,模型的性能會不斷提升。雖然模型的每個 token 擁有與基線近乎相同的 FLOPS,但 Switch Transformers 會產生額外的跨設備通信成本,路由機制也會帶來額外的計算開銷。因此,在基于步數的設置中觀察到的樣本效率提升未必能轉化為時間上的模型質量提升。這就引出了一個問題:
在訓練時間和計算成本都固定的前提下,我們應該訓練一個稠密模型還是稀疏模型?
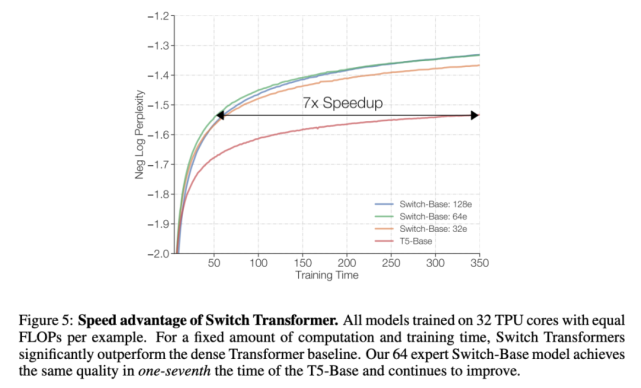
下圖 5 和 6 解決了這個問題。圖 5 展示了預訓練模型質量隨訓練時間增加所產生的變化。在訓練時間和計算成本都固定的情況下,Switch Transformer 的速度優勢非常明顯。在這種設置下,如果要達到相似的困惑度,Switch-Base 64 專家模型的訓練時間僅為 T5-Base 模型的 1/7。
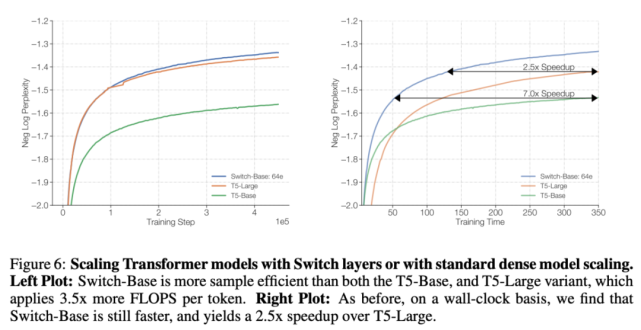
可擴展性 VS. 一個更大的稠密模型
上面的實驗表明,一個計算不受限制的稠密模型已經被 Switch 超越。圖 6 考慮了一種不同的情況:如果把計算資源分給一個更大的稠密模型會怎么樣?
為了驗證這個問題,研究者將 Switch-Base 與更強的基線 T5-Large 進行了對比。實驗結果表明,盡管 T5-Large 每個 token 所用的 FLOPs 是 Switch-Base 的 3.5 倍,但后者的樣本效率依然更高,而且速度是前者的 2.5 倍。此外,如果設計一個與 T5-Large 所需 FLOPs 相同的 Switch 模型(Switch-Large),上述提升還會更加明顯。
下游任務中的結果
微調
這里使用的基線方法是經過高度調參、具備 223M 參數的 T5-Base 和具備 739M 參數的 T5-Large 模型。針對這兩個模型,該研究作者設計了具備更多參數的 FLOP-matched Switch Transformer。
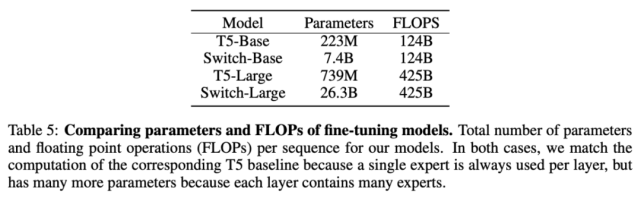
在多項自然語言任務中,Switch Transformer 帶來了顯著性能提升。最明顯的是 SuperGLUE,在該基準上 FLOP-matched Switch Transformer 相比 T5-Base 和 T5-Large 的性能分別提升了 4.4% 和 2%,在 Winogrande、closed book Trivia QA 和 XSum 上也出現了類似情況。唯一沒有觀察到性能提升的基準是 AI2 推理挑戰賽(ARC)數據集:在 ARC challenge 數據集上 T5-Base 的性能超過 Switch-Base;在 ARC easy 數據集上,T5-Large 的性能超過 Switch-Large。
整體而言,Switch Transformer 模型在多項推理和知識任務中帶來了顯著性能提升。這說明該模型架構不只對預訓練有用,還可以通過微調將質量改進遷移至下游任務中。
蒸餾
部署具備十億、萬億參數量的大型神經網絡并非易事。為此,該論文研究了如何將大型稀疏模型蒸餾為小型稠密模型。下表 7 展示了該研究所用的蒸餾技術:
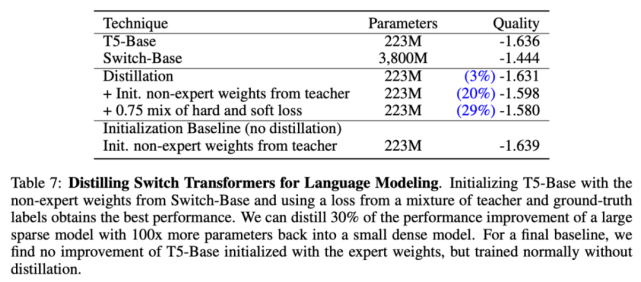
使用表 7 中最優的蒸餾技術后,研究者將多個稀疏模型蒸餾為稠密模型。他們對 Switch-Base 模型進行蒸餾,由于專家數量的不同,其參數量在 11 億至 147 億之間。該研究可以將具備 11 億參數量的模型壓縮 82%,同時保留 37% 的性能提升。最極端的情況下,將模型壓縮了 99%,且維持了 28% 的性能提升。
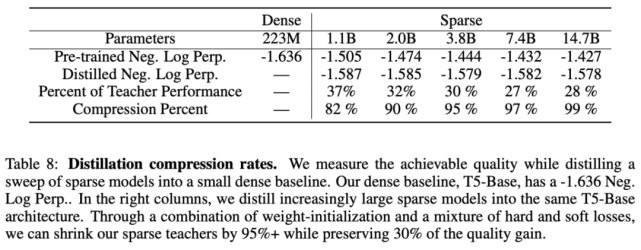
最后,研究者將微調稀疏模型蒸餾為稠密模型。下表 9 展示了對 74 億參數 Switch-Base 模型(該模型針對 SuperGLUE 任務進行了微調)的蒸餾結果——223M T5-Base。與預訓練結果類似,蒸餾后的模型仍保留 30% 的性能提升。這可能有助于確定用于微調任務的特定專家并進行提取,從而獲得更好的模型壓縮。

多語言學習
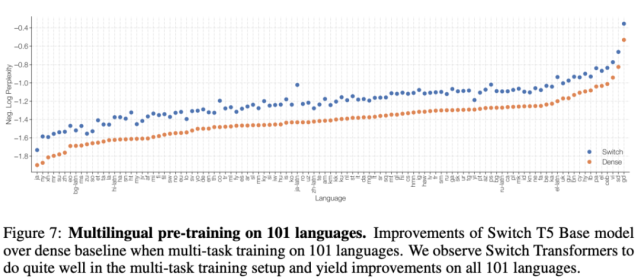
在下游任務實驗中,研究者衡量了模型質量和速度的權衡,模型在 101 種不同語言上進行了預訓練。下圖 7 展示了 Switch T5 Base 模型與 mT5-Base 在所有語言上的質量提升情況(負對數困惑度)。對兩個模型經過 100 萬步預訓練后,Switch Transformer 的最終負對數困惑度相較基線有所提升。
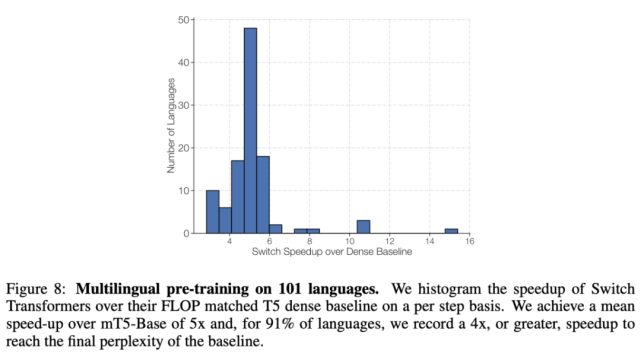
下圖 8 展示了 Switch Transformer 相較 mT5-Base 的每一步加速情況,前者實現了平均 5 倍的加速,其中在 91% 的語言上實現了至少 4 倍加速。這表明 Switch Transformer 是高效的多任務和多語言學習器。
使用數據、模型和專家并行化來設計模型
隨意地增加專家數量會出現收益遞減問題(參見上圖 4),該研究介紹了一些補充性的擴展策略,涉及結合數據、模型與專家并行化的權衡。
結合數據、模型與專家并行化,構建萬億參數模型
Switch Transformer 設計過程中,研究者試圖平衡 FLOPs per token 和參數量。當專家數量增加時,則參數量增加,但不改變 FLOPs per token。要想增加 FLOPs,則需增加 d_ff 維度(這也會帶來參數量的增加,但相對較少)。這就是一種權衡:增加 d_ff 維度會導致每個核心內存的耗盡,因而必須增加 m。但由于核心 N 的數量是固定的 N = n × m,因此必須降低 n,也就是說需要使用更小的批大小。

在結合模型并行化和專家并行化之后,發送 token 到正確的專家以及模型并行化導致的內部 all-reduce 通信會帶來 all-to-all 通信成本。在結合這三種方法時,如何平衡 FLOPs、通信成本和每個核心的內存變得非常復雜。
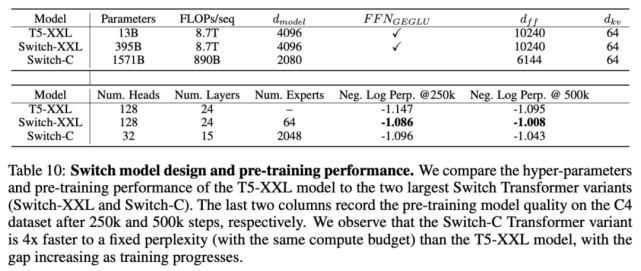
該研究結合數據、模型與專家并行化,設計了兩個大型 Switch Transformer 模型,分別具備3950 億參數和1.6 萬億參數,并研究了這些模型在上游預訓練語言模型和下游微調任務中的性能。參數量、FLOPs 和不同模型的超參數參見下表 10:
關于 Switch Transformer 還有很多問題
在論文最后部分,谷歌大腦研究者探討了一些關于 Switch Transformer 和稀疏專家模型的問題(這里稀疏指的是權重,而不是注意力模式)。
問題 1:Switch Transformer 的性能更好嗎?原因是否在于巨量參數?
性能的確更好,但原因不在參數量,而在于設計。參數有助于擴展神經語言模型,大模型的性能確實會好一些。但是該研究提出的模型在使用相同計算資源的情況下具備更高的樣本效率。
問題 2:沒有超級計算機的情況下,我能使用該方法嗎?
盡管這篇論文聚焦非常大型的模型,但研究者仍找到了具備兩個專家的模型,既能提升性能又可以輕松適應常用 GPU 或 TPU 的內存限制。因此,研究者認為該技術可用于小規模設置中。
問題 3:在速度 - 準確率帕累托曲線上,稀疏模型的表現優于稠密模型嗎?
是的。在多種不同模型規模情況下,稀疏模型在每一步和墻上時鐘時間方面都優于稠密模型。受控實驗表明,對于固定的計算量和時間而言,稀疏模型的表現超過稠密模型。
問題 4:我無法部署萬億參數模型,可以將模型縮小嗎?
雖然無法完整維持萬億參數模型的質量,但通過將稀疏模型蒸餾為稠密模型,可實現 10-100 倍的壓縮率,同時獲得專家模型約 30% 的質量改進。
問題 5:為什么要使用 Switch Transformer 代替模型并行稠密模型?
以時間為基準,Switch Transformer 要比使用分片參數(sharded parameter)的稠密模型高效得多。同時,這一選擇并非互斥,Switch Transformer 中也可以使用模型并行化,這可以提高 FLOPs per token,但也會導致傳統模型并行化的減速。
問題 6:為什么稀疏模型未得到廣泛使用?
嘗試稀疏模型的想法被稠密模型的巨大成功所阻撓。并且,稀疏模型面臨著多個問題,包括模型復雜度、訓練難度、通信成本等。而 Switch Transformer 緩解了這些問題。