













拋棄歸一化,深度學(xué)習(xí)模型準(zhǔn)確率卻達(dá)到了前所未有的水平
我們知道,在傳遞給機(jī)器學(xué)習(xí)模型的數(shù)據(jù)中,我們需要對(duì)數(shù)據(jù)進(jìn)行歸一化(normalization)處理。
在數(shù)據(jù)歸一化之后,數(shù)據(jù)被「拍扁」到統(tǒng)一的區(qū)間內(nèi),輸出范圍被縮小至 0 到 1 之間。人們通常認(rèn)為經(jīng)過(guò)如此的操作,最優(yōu)解的尋找過(guò)程明顯會(huì)變得平緩,模型更容易正確的收斂到最佳水平。
然而這樣的「刻板印象」最近受到了挑戰(zhàn),DeepMind 的研究人員提出了一種不需要?dú)w一化的深度學(xué)習(xí)模型 NFNet,其在大型圖像分類任務(wù)上卻又實(shí)現(xiàn)了業(yè)內(nèi)最佳水平(SOTA)。
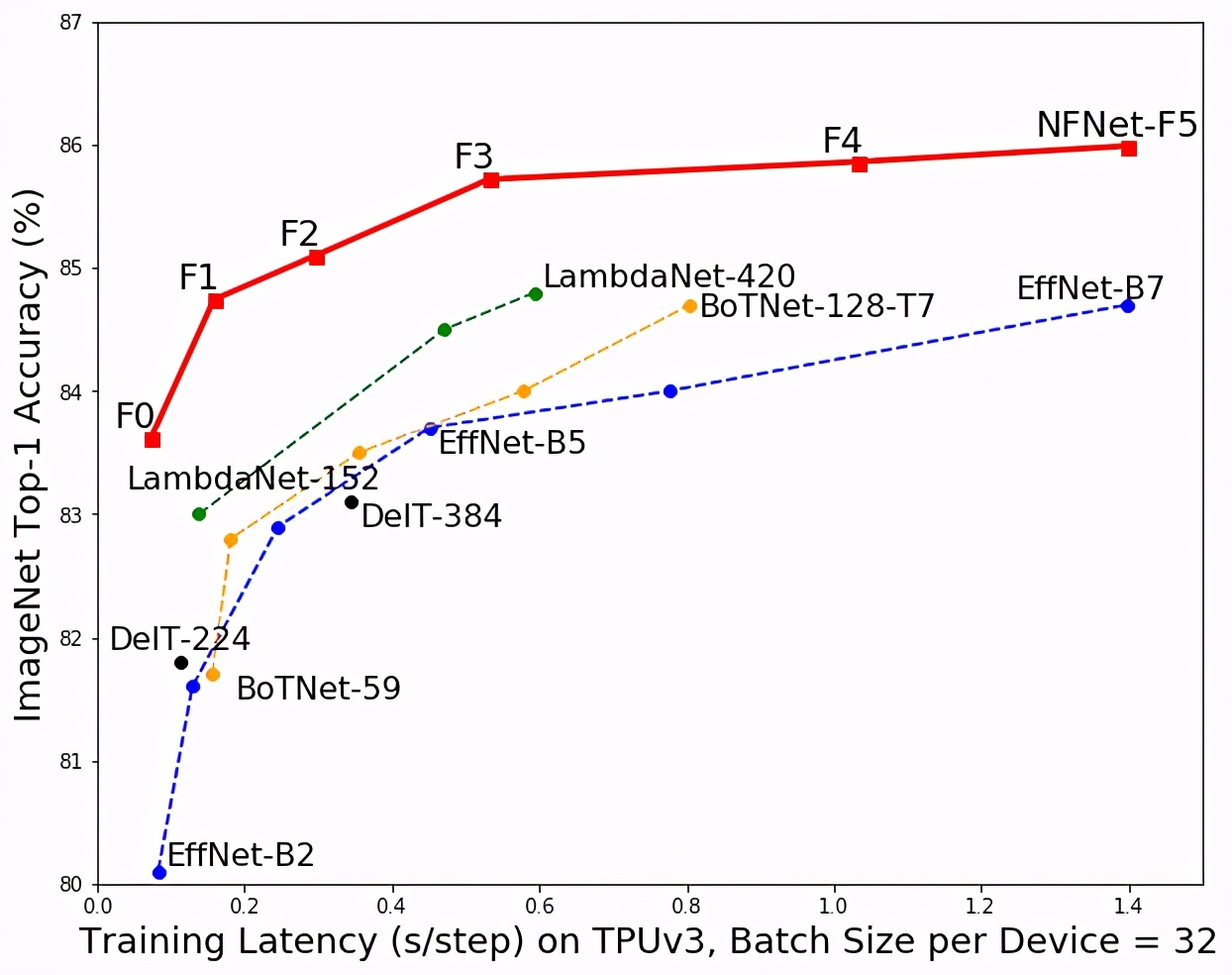 前所未有的水平">
前所未有的水平">該模型(紅色)與其他模型在 ImageNet 分類準(zhǔn)確度和訓(xùn)練時(shí)間上的對(duì)比。
該論文的第一作者,DeepMind 研究科學(xué)家 Andrew Brock 表示:「我們專注于開發(fā)可快速訓(xùn)練的高性能體系架構(gòu),已經(jīng)展示了一種簡(jiǎn)單的技術(shù)(自適應(yīng)梯度裁剪,AGC),讓我們可以訓(xùn)練大批量和大規(guī)模數(shù)據(jù)增強(qiáng)后的訓(xùn)練,同時(shí)達(dá)到 SOTA 水平。」
該研究一經(jīng)提交,便吸引了人們的目光。
 前所未有的水平">
前所未有的水平">- 論文鏈接:https://arxiv.org/abs/2102.06171
- DeepMind 還放出了模型的實(shí)現(xiàn):https://github.com/deepmind/deepmind-research/tree/master/nfnets
NFNet 是不做歸一化的 ResNet 網(wǎng)絡(luò)。具體而言,該研究貢獻(xiàn)有以下幾點(diǎn):
- 提出了自適應(yīng)梯度修剪(Adaptive Gradient Clipping,AGC)方法,基于梯度范數(shù)與參數(shù)范數(shù)的單位比例來(lái)剪切梯度,研究人員證明了 AGC 可以訓(xùn)練更大批次和大規(guī)模數(shù)據(jù)增強(qiáng)的非歸一化網(wǎng)絡(luò)。
- 設(shè)計(jì)出了被稱為 Normalizer-Free ResNets 的新網(wǎng)絡(luò),該方法在 ImageNet 驗(yàn)證集上大范圍訓(xùn)練等待時(shí)間上都獲得了最高水平。NFNet-F1 模型達(dá)到了與 EfficientNet-B7 相似的準(zhǔn)確率,同時(shí)訓(xùn)練速度提高了 8.7 倍,而 NFNet 模型的最大版本則樹立了全新的 SOTA 水平,無(wú)需額外數(shù)據(jù)即達(dá)到了 86.5%的 top-1 準(zhǔn)確率。
- 如果在對(duì) 3 億張帶有標(biāo)簽的大型私人數(shù)據(jù)集進(jìn)行預(yù)訓(xùn)練,隨后針對(duì) ImageNet 進(jìn)行微調(diào),NFNet 可以比批歸一化的模型獲得更高的 Top-1 準(zhǔn)確率:高達(dá) 89.2%。
研究方法
在沒有歸一化的情況下,許多研究者試圖通過(guò)恢復(fù)批歸一化的好處來(lái)訓(xùn)練深度 ResNet 以提升其準(zhǔn)確率。這些研究大多數(shù)通過(guò)引入小常數(shù)或可學(xué)習(xí)的標(biāo)量來(lái)抑制初始化時(shí)殘差分支上的激活尺度。
DeepMind 的這項(xiàng)研究采用并建立在「Normalizer-Free ResNet(NF-ResNet)」上,這是一類可以在沒有歸一化層的情況下,被訓(xùn)練成具有訓(xùn)練和測(cè)試準(zhǔn)確率的預(yù)激活 ResNet。
NF-ResNet 使用如下形式的殘差塊:
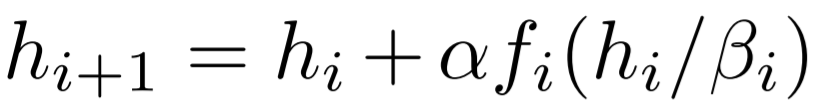 前所未有的水平">
前所未有的水平">其中,h_i 代表第 i 個(gè)殘差塊的輸入,f_i 代表由第 i 個(gè)殘差分支計(jì)算的函數(shù)。
用于高效大批量訓(xùn)練的自適應(yīng)梯度裁剪
為了將 NF-ResNet 擴(kuò)展到更大的批規(guī)模,研究者探索了一系列梯度裁剪策略。梯度裁剪通常被用于語(yǔ)言建模中以穩(wěn)定訓(xùn)練。近來(lái)一些研究表明:與梯度下降相比,梯度裁剪允許以更高的學(xué)習(xí)率進(jìn)行訓(xùn)練,從而加快收斂速度。這對(duì)于條件較差的 loss landscape 或大批量訓(xùn)練尤為重要。因?yàn)樵谶@些情況下,最佳學(xué)習(xí)率受到最大穩(wěn)定學(xué)習(xí)率的限制。因此該研究假設(shè)梯度裁剪應(yīng)該有助于將 NF-ResNet 有效地?cái)U(kuò)展到大批量設(shè)置。
借助一種稱為 AGC 的梯度裁剪方法,該研究探索設(shè)計(jì)了 Normalizer-Free 架構(gòu),該架構(gòu)實(shí)現(xiàn)了 SOTA 的準(zhǔn)確率和訓(xùn)練速度。
當(dāng)前圖像分類任務(wù)的 SOTA 大多是 EfficientNet 系列模型 (Tan & Le, 2019)取得的,該系列的模型經(jīng)過(guò)優(yōu)化以最大化測(cè)試準(zhǔn)確率,同時(shí)最小化參數(shù)量和 FLOP 計(jì)數(shù),但它們的低理論計(jì)算復(fù)雜度并沒有轉(zhuǎn)化為訓(xùn)練速度的提高。
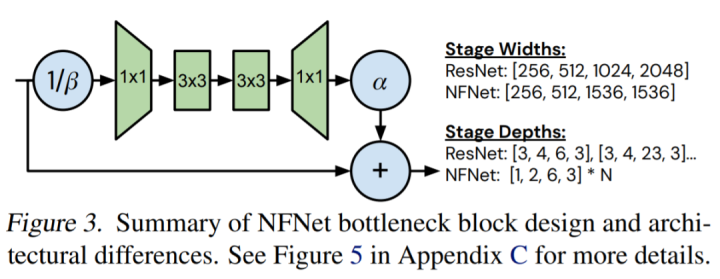 前所未有的水平">
前所未有的水平">該研究通過(guò)手動(dòng)搜索設(shè)計(jì)導(dǎo)向來(lái)探索模型設(shè)計(jì)的空間,這些導(dǎo)向?qū)Ρ仍O(shè)備上的實(shí)際訓(xùn)練延遲,可帶來(lái) ImageNet 上 holdout top-1 的帕累托前沿面的改進(jìn)。它們對(duì) holdout 準(zhǔn)確率的影響如下表 2 所示:
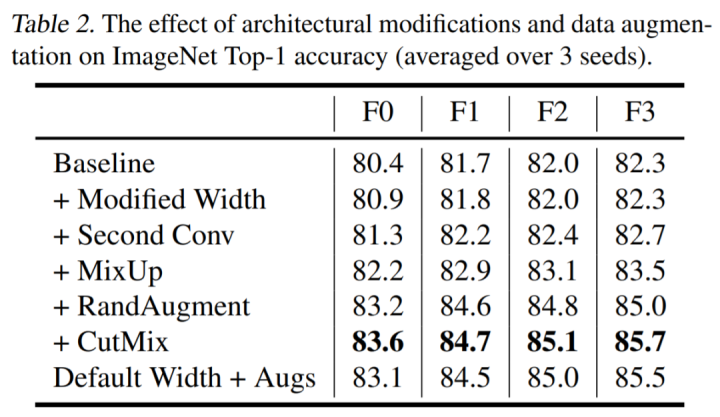 前所未有的水平">
前所未有的水平">實(shí)驗(yàn)
表 3 展示了六個(gè)不同的 NFNets(F0-F5)與其他模型在模型大小、訓(xùn)練延遲和 ImageNet 驗(yàn)證準(zhǔn)確率方面的對(duì)比情況。NFNets-F5 達(dá)到了 86.0%的 SOTA top-1 準(zhǔn)確率,相比 EfficientNet-B8 有了一定提升;NFNet-F1 的測(cè)試準(zhǔn)確率與 EfficientNet-B7 相媲美,同時(shí)訓(xùn)練速度提升了 8.7 倍;NFNet-F6+SAM 達(dá)到了 86.5%的 top-1 準(zhǔn)確率。
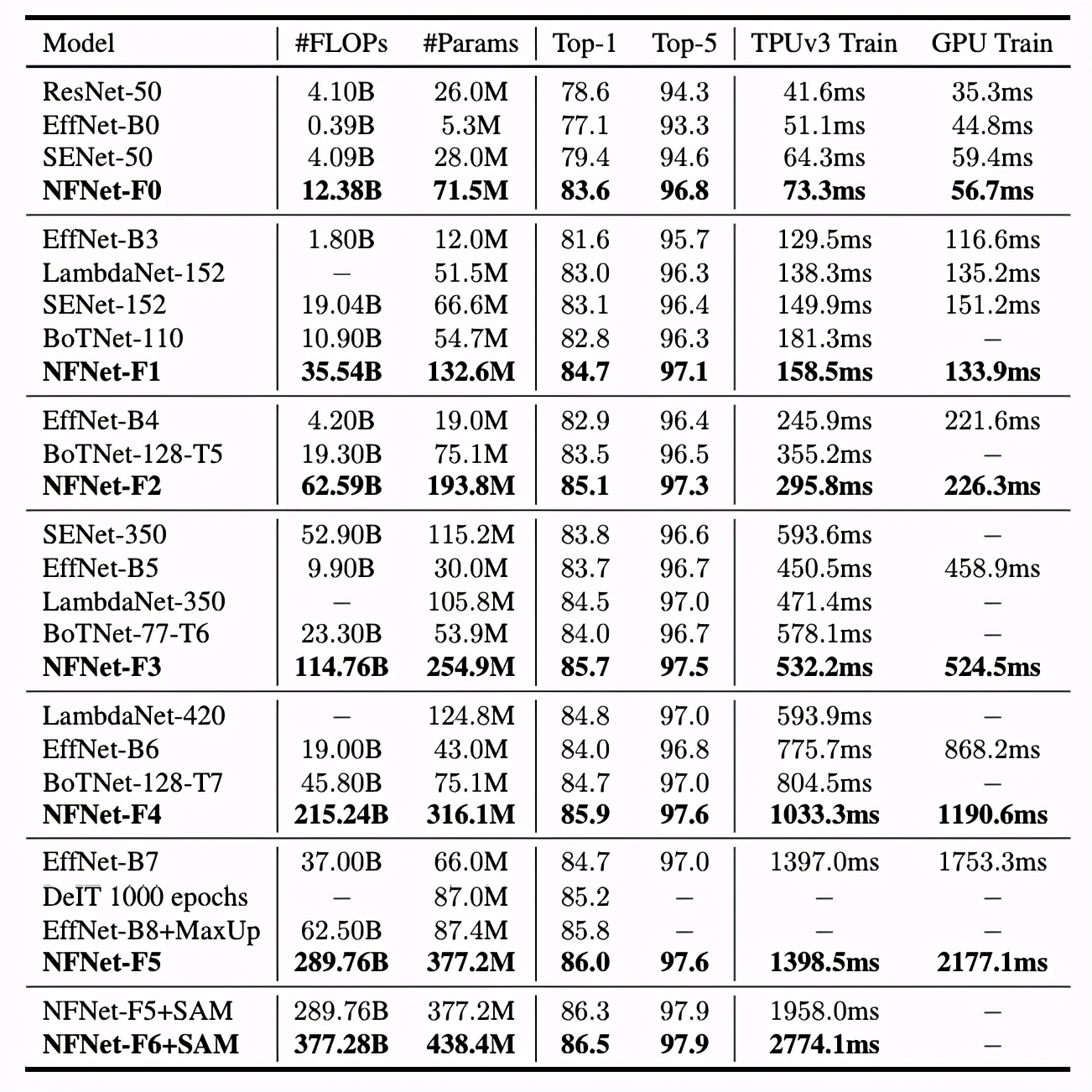 前所未有的水平">
前所未有的水平">NFNets 和其他模型在 ImageNet 數(shù)據(jù)集上的準(zhǔn)確率對(duì)比。延遲是指在 TPU 或 GPU(V100)上運(yùn)行單個(gè)完整訓(xùn)練步驟所需要的毫秒時(shí)間。
此外,研究者使用了一個(gè) 3 億標(biāo)注圖像的數(shù)據(jù)集對(duì) NFNet 的變體進(jìn)行了預(yù)訓(xùn)練,并針對(duì) ImageNet 進(jìn)行微調(diào)。最終,NFNet-F4 + 在 ImageNet 上獲得了 89.2% 的 top-1 準(zhǔn)確率。這是迄今為止通過(guò)額外訓(xùn)練數(shù)據(jù)達(dá)到的第二高的驗(yàn)證準(zhǔn)確率,僅次于目前最強(qiáng)大的半監(jiān)督學(xué)習(xí)基線 (Pham et al., 2020) 和通過(guò)遷移學(xué)習(xí)達(dá)到的最高準(zhǔn)確率。
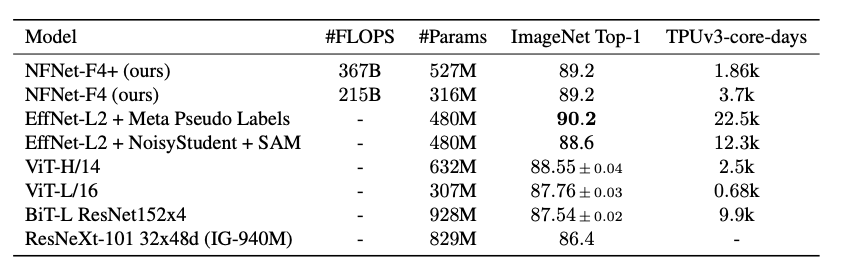 前所未有的水平">
前所未有的水平">表 5:使用額外數(shù)據(jù)進(jìn)行大規(guī)模預(yù)訓(xùn)練后,ImageNet 模型遷移性能對(duì)比。
Andrew Brock 表示,雖然我們對(duì)于神經(jīng)網(wǎng)絡(luò)信號(hào)傳遞、訓(xùn)練規(guī)律的理解還有很多需要探索的方向,但無(wú)歸一化的方法已經(jīng)為人們提供了一個(gè)強(qiáng)有力的參考,并證明了發(fā)展這種深度理解能力可以有效地在生產(chǎn)環(huán)境中提升效率。


















