













每秒100W次的計數,架構原來可以這樣設計!
今天和大家聊聊計數系統。
畫外音:文章較長,可提前收藏。
計數系統解決什么業務問題?
很多業務都有“計數”需求,以微博為例:
微博首頁的個人中心部分,有三個重要的計數:
- 關注了多少人的計數;
- 粉絲的計數;
- 發布博文的計數;
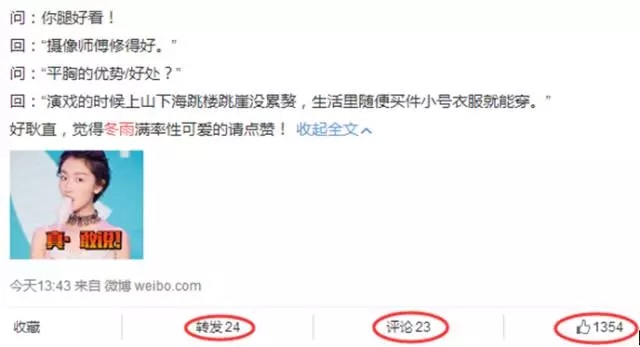
微博首頁的博文消息主體部分,也有有很多計數,分別是一條博文的:
- 轉發計數;
- 評論計數;
- 點贊計數;
- 甚至是瀏覽計數;
畫外音:瀏覽計數有點難,每秒100W次PV,就有100W次計數。
在業務復雜,計數擴展頻繁,數據量大,并發量大的情況下,計數系統的架構演進與實踐,是本文將要分享的問題。
如何最快速的實現業務計數呢?
count計數法。
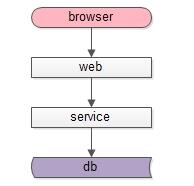
典型的互聯網架構,常常分為這么幾層:
- 調用層:處于端上的browser或者APP;
- 站點層:拼裝html或者json返回的web-server層;
- 服務層:提供RPC調用接口的service層;
- 數據層:提供固化數據存儲的db,以及加速存儲的cache;
針對上文微博計數的例子,主要涉及“關注”業務,“粉絲”業務,“微博消息”業務,一般來說,會有相應的db存儲相關數據,相應的service提供相關業務的RPC接口:
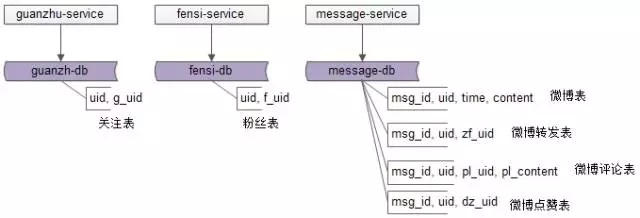
- 關注服務:提供關注數據的增刪查改RPC接口;
- 粉絲服務:提供粉絲數據的增刪查改RPC接口;
- 消息服務:提供微博消息數據的增刪查改RPC接口,消息業務相對比較復雜,涉及微博消息、轉發、評論、點贊等數據的存儲;
對關注、粉絲、微博業務進行了初步解析,那首頁的計數需求應該如何滿足呢?
很容易想到,關注服務+粉絲服務+消息服務均提供相應接口,就能拿到相關計數數據。
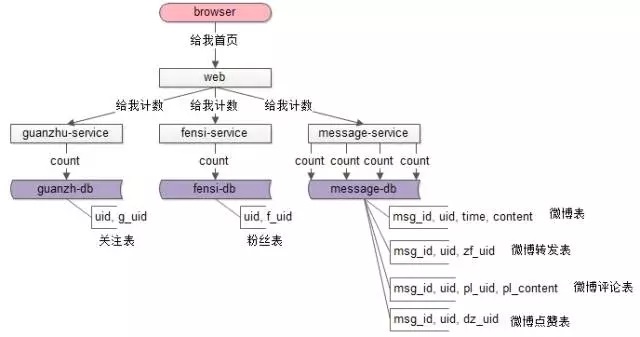
例如,個人中心首頁,需要展現博文數量這個計數,web層訪問message-service的count接口,這個接口執行:
- select count(*) from t_msg where uid = XXX
同理,也很容易拿到關注,粉絲的這些計數。
這個方案叫做“count”計數法,在數據量并發量不大的情況下,最容易想到且最經常使用的就是這種方法。
count計數法存在什么問題呢?
隨著數據量的上升,并發量的上升,這個方法的弊端將逐步展現。
例如,微博首頁有很多條微博消息,每條消息有若干計數,此時計數的拉取就成了一個龐大的工程:
整個拉取計數的偽代碼如下:
- list<msg_id> = getHomePageMsg(uid);// 獲取首頁所有消息
- for( msg_id in list<msg_id>){ // 對每一條消息
- getReadCount(msg_id); // 閱讀計數
- getForwordCount(msg_id); // 轉發計數
- getCommentCount(msg_id); // 評論計數
- getPraiseCount(msg_id); // 贊計數
- }
其中:
- 每一個微博消息的若干個計數,都對應4個后端服務訪問;
- 每一個訪問,對應一條count的數據庫訪問(count要了老命了);
其效率之低,資源消耗之大,處理時間之長,可想而知。
“count”計數法方案,可以總結為:
- 多條消息多次查詢,for循環進行;
- 一條消息多次查詢,多個計數的查詢;
- 一次查詢一個count,每個計數都是一個count語句;
那如何進行優化呢?
計數外置法。
計數是一個通用的需求,有沒有可能,這個計數的需求實現在一個通用的系統里,而不是由關注服務、粉絲服務、微博服務來分別來提供相應的功能呢?
畫外音:各個業務系統具備的通用痛點,應該下沉統一解決。
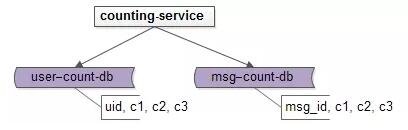
可以抽象一個通用的計數服務。
通過分析,上述微博的業務可以抽象成兩類:
- 用戶(uid)維度的計數:用戶的關注計數,粉絲計數,發布的微博計數;
- 微博消息(msg_id)維度的計數:消息轉發計數,評論計數,點贊計數;
于是可以抽象出兩個表,針對這兩個維度來進行計數的存儲:
- t_user_count (uid, gz_count, fs_count, wb_count);
- t_msg_count (msg_id, forword_count, comment_count, praise_count);
甚至可以更為抽象,一個表搞定所有計數:
- t_count(id, type, c1, c2, c3, …)
通過type來判斷,id究竟是uid還是msg_id,但并不建議這么做。
存儲抽象完,再抽象出一個計數服務對這些數據進行管理,提供友善的RPC接口:
這樣,在查詢一條微博消息的若干個計數的時候,不用進行多次數據庫count操作,而會轉變為一條數據的多個屬性的查詢:
- for(msg_id in list<msg_id>) {
- select forword_count, comment_count, praise_count
- from t_msg_count
- where msg_id=$msg_id;
- }
甚至,可以將微博首頁所有消息的計數,轉變為一條IN語句(不用多次查詢了)的批量查詢:
- select * from t_msg_count
- where msg_id IN
- ($msg_id1, $msg_id2, $msg_id3, …);
IN查詢可以命中msg_id聚集索引,效率很高。
那么,當有微博被轉發、評論、點贊的時候,計數服務如何同步的進行計數的變更呢?
如果讓業務服務來調用計數服務,勢必會導致業務系統與計數系統耦合。可以通過MQ來解耦,在業務發生變化的時候,向MQ發送一條異步消息,通知計數系統計數發生了變化即可:
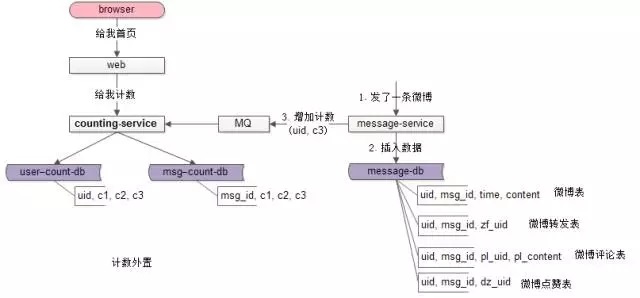
如上圖:
- 用戶新發布了一條微博;
- msg-service向MQ發送一條消息;
- counting-service從MQ接收消息;
- counting-service變更這個uid發布微博消息計數;
畫外音:其實發送一條微博本來就會發MQ消息,計數系統只是新增一個訂閱方。
這個方案稱為“計數外置”,可以總結為:
- 通過counting-service單獨保存計數;
- MQ同步計數的變更;
- 多條消息的多個計數,一個批量IN查詢完成;
計數外置可能存在什么新的問題呢?
計數外置,本質是數據的冗余,架構設計上,數據冗余必將引發數據的一致性問題,需要有機制來保證計數系統里的數據與業務系統里的數據一致,常見的方法有:
- 對于一致性要求比較高的業務,要有定期check并fix的機制,例如關注計數,粉絲計數,微博消息計數等;
- 對于一致性要求比較低的業務,即使有數據不一致,業務可以接受,例如微博瀏覽數,微博轉發數等;
計數外置很大程度上解決了計數存取的性能問題,但是否還有優化空間呢?
像關注計數,粉絲計數,微博消息計數,變化的頻率很低,查詢的頻率很高,這類讀多些少的業務場景,非常適合使用緩存來進行查詢優化,減少數據庫的查詢次數,降低數據庫的壓力。
但是,緩存是kv結構的,無法像數據庫一樣,設置成
- t_uid_count(uid, c1, c2, c3)
這樣的schema,如何來對kv進行設計呢?
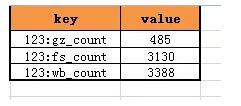
緩存kv結構的value是計數,看來只能在key上做設計,很容易想到,可以使用uid:type來做key,存儲對應type的計數。
對于uid=123的用戶,其關注計數,粉絲計數,微博消息計數的緩存就可以設計為:
此時對應的counting-service架構變為:
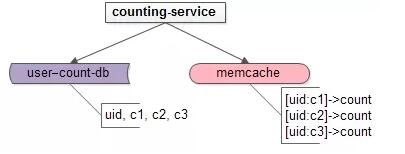
如此這般,多個uid的多個計數,又可能會變為多次緩存的訪問:
- for(uid in list<uid>) {
- memcache::get($uid:c1, $uid:c2, $uid:c3);
- }
這個“計數外置緩存優化”方案,可以總結為:
- 使用緩存來保存讀多寫少的計數;
畫外音:其實寫多讀少,一致性要求不高的計數,也可以先用緩存保存,然后定期刷到數據庫中,以降低數據庫的讀寫壓力。
- 使用id:type的方式作為緩存的key,使用count來作為緩存的value;
- 多次讀取緩存來查詢多個uid的計數;
緩存的使用能夠極大降低數據庫的壓力,但多次緩存交互依舊存在優化空間,有沒有辦法進一步優化呢?
不要陷入思維定式,誰說value一定只能是一個計數,難道不能多個計數存儲在一個value中么?
緩存kv結構的key是uid,value可以是多個計數同時存儲。
對于uid=123的用戶,其關注計數,粉絲計數,微博消息計數的緩存就可以設計為:
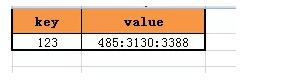
這樣多個用戶,多個計數的查詢就可以一次搞定:
- memcache::get($uid1, $uid2, $uid3, …);
然后對獲取的value進行分析,得到關注計數,粉絲計數,微博計數。
如果計數value能夠事先預估一個范圍,甚至可以用一個整數的不同bit來存儲多個計數,用整數的與或非計算提高效率。
這個“計數外置緩存批量優化”方案,可以總結為:
- 使用id作為key,使用同一個id的多個計數的拼接作為value;
- 多個id的多個計數查詢,一次搞定;
考慮完效率,架構設計上還需要考慮擴展性,如果uid除了關注計數,粉絲計數,微博計數,還要增加一個計數,這時系統需要做什么變更呢?
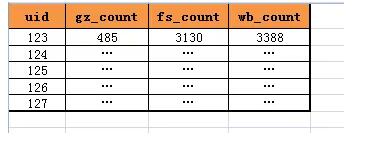
之前的數據庫結構是:
- t_user_count(uid, gz_count, fs_count, wb_count)
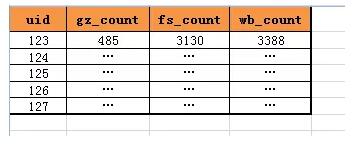
這種設計,通過列來進行計數的存儲,如果增加一個XX計數,數據庫的表結構要變更為:
- t_user_count(uid, gz_count, fs_count, wb_count, XX_count)
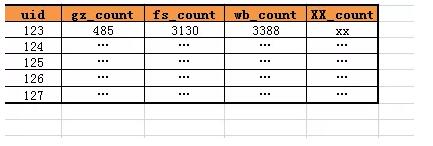
在數據量很大的情況下,頻繁的變更數據庫schema的結構顯然是不可取的,有沒有擴展性更好的方式呢?
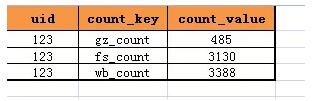
不要陷入思維定式,誰說只能通過擴展列來擴展屬性,能不能通過擴展行來擴展屬性呢?
答案是肯定的,完全可以這樣設計表結構:
- t_user_count(uid, count_key, count_value)
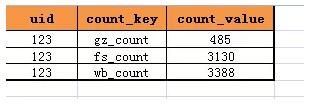
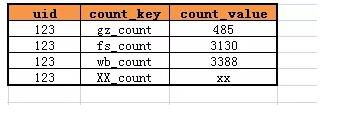
如果需要新增一個計數XX_count,只需要增加一行即可,而不需要變更表結構:
總結
小小的計數,在數據量大,并發量大的時候,其架構實踐思路為:
(1)計數外置:由“count計數法”升級為“計數外置法”;
(2)讀多寫少,甚至寫多但一致性要求不高的計數,需要進行緩存優化,降低數據庫壓力;
(3)緩存kv設計優化,可以由[key:type]->[count],優化為[key]->[c1:c2:c3]即:
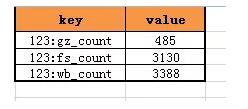
優化為:
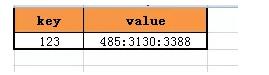
(4)數據庫擴展性優化,可以由列擴展優化為行擴展即:
優化為:
【本文為51CTO專欄作者“58沈劍”原創稿件,轉載請聯系原作者】

























