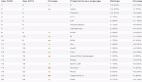
PyPy是不是真的比Python快?
眾所周知, Python 編寫(xiě)的程序運(yùn)行不快,這種慢雖無(wú)大礙,但為了獲得更高的性能,我們需要再切換到另一種編程語(yǔ)言嗎?不一定。我們可以放棄python.py的運(yùn)行方式,轉(zhuǎn)而使用 PyPy 即時(shí)編譯器。
根據(jù)官方網(wǎng)站的說(shuō)法,就連Python 創(chuàng)建者 Guido von Rossum 都建議將 PyPy 用于關(guān)鍵性能的 Python 程序。接下來(lái)我們看看 PyPy 有多快。
基準(zhǔn)測(cè)試的工作原理
為了比較 Python 和 PyPy,我編寫(xiě)了幾個(gè) Python 程序。著名算法、典型用例,甚至是基本的 HTTP 服務(wù)器。然后我用 Python 和 PyPy 執(zhí)行程序——在 macOS 和 Linux 的終端中使用time模塊,可以看到執(zhí)行某事的持續(xù)時(shí)間。使用 time模塊 看起來(lái)像這樣:
- time python.py
執(zhí)行完成后,time模塊會(huì)報(bào)告您花費(fèi)的時(shí)間。
使用的版本:
- PyPy:7.3.5,使用 Python 版本 3.7.10
- Python:版本 3.9.7
這兩個(gè)版本都是目前可用的最新版本。程序本身不記錄任何內(nèi)容。我們只關(guān)心進(jìn)行計(jì)算。
這是準(zhǔn)備好的代碼片段。讓我們對(duì)每個(gè)場(chǎng)景進(jìn)行基準(zhǔn)測(cè)試。
1. 斐波那契
以下函數(shù)生成我們傳遞給它的數(shù)字的斐波那契值。

結(jié)果:
Python 平均需要 2337 毫秒的執(zhí)行時(shí)間。
PyPy 平均只需要 301 毫秒。明顯的贏家是 PyPy。
2. web服務(wù)
為了對(duì) PyPy 和 Python 處理 HTTP 請(qǐng)求的性能進(jìn)行基準(zhǔn)測(cè)試,使用 time 命令測(cè)量時(shí)間是行不通的。有效的是“wrk”——一個(gè)基準(zhǔn)測(cè)試工具,在服務(wù)器上觸發(fā)大量 HTTP 請(qǐng)求。
因此,它為我們提供了有關(guān)服務(wù)器平均響應(yīng)速度以及它可以處理多少 HTTP 請(qǐng)求的數(shù)據(jù)。

上面顯示的 Web 服務(wù)器在端口 4000 上為目錄“app”提供服務(wù)。在這個(gè)目錄中,我創(chuàng)建了一個(gè)小的 hello-world HTML 文件。基準(zhǔn)測(cè)試在終端中執(zhí)行:
- wrk -t12 -c400 -d10s http://localhost:4000/
結(jié)果如下:
Python:Web 服務(wù)器平均每秒可以處理 995 個(gè)請(qǐng)求,平均延遲為 2.03 毫秒。
PyPy:Web 服務(wù)器平均每秒可以處理 1481 個(gè)請(qǐng)求,平均延遲為 1.90 毫秒。如您所見(jiàn),PyPy 要快得多。
3. 快速排序
快速排序可能是最有效的排序算法。這是它在 Python 中的實(shí)現(xiàn):
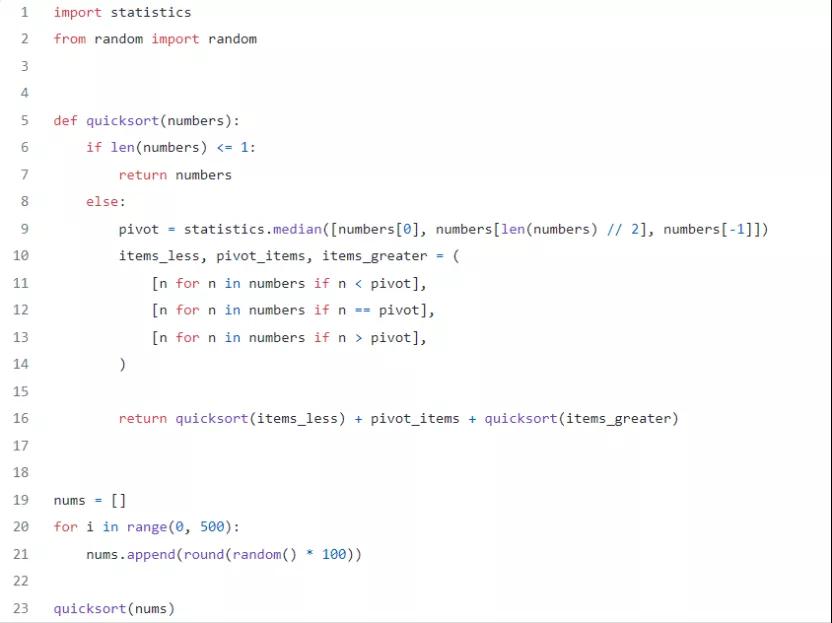
在 Quicksort 實(shí)現(xiàn)下面,我們生成了 500 個(gè)隨機(jī)數(shù)并將它們存儲(chǔ)在一個(gè)數(shù)組中。這個(gè)數(shù)組是 Quicksort 算法將要排序的。
結(jié)果如下:
Python:平均而言,代碼執(zhí)行時(shí)間為 43 毫秒
PyPy:平均執(zhí)行時(shí)間為 132 毫秒。
是的,Python 在這里更快。 這也可以在內(nèi)部測(cè)量時(shí)間時(shí)確認(rèn),使用 start = time.time() 技巧。
4. 堆棧
棧是一種簡(jiǎn)單的數(shù)據(jù)結(jié)構(gòu)。它是一個(gè)數(shù)組的更漂亮的詞,我們?cè)谒厦嫱茤|西并從中彈出它。下面的代碼創(chuàng)建這個(gè)數(shù)組,在堆棧上壓入和彈出 1000 萬(wàn)個(gè)數(shù)字:

讓我們看看兩者的速度有多快。
Python:代碼平均耗時(shí) 2.89 秒
PyPy:平均需要 69 毫秒。是的,我說(shuō)的是毫秒。
在這個(gè)基準(zhǔn)測(cè)試中,PyPy 比普通 Python 快幾個(gè)數(shù)量級(jí)。
5. SQlite3 Database
數(shù)據(jù)庫(kù)是大型項(xiàng)目中常用的東西。我選擇 SQLite 來(lái)做一個(gè)基準(zhǔn)測(cè)試,因?yàn)樗苋菀着c Python 一起使用——不需要通過(guò) pip 安裝任何東西。以下代碼在基于文件的 SQLite 數(shù)據(jù)庫(kù)中創(chuàng)建一個(gè)新表。
在每次基準(zhǔn)測(cè)試之前,我刪除了數(shù)據(jù)庫(kù)文件并創(chuàng)建了一個(gè)普通的新文件。但是數(shù)據(jù)庫(kù)存儲(chǔ)什么?范圍函數(shù)生成一百萬(wàn)個(gè)數(shù)字,然后將每個(gè)數(shù)字加倍——函數(shù) f(n) = n * 2。數(shù)據(jù)庫(kù)存儲(chǔ)每個(gè)函數(shù)對(duì),例如“2、4”或“18、36”。

結(jié)果:
Python 平均需要 6.7 秒來(lái)執(zhí)行代碼。
PyPy 平均需要 9.4 秒的執(zhí)行時(shí)間。
Python 更快。我還嘗試將其與其他操作結(jié)合使用——比如刪除剛剛創(chuàng)建的條目。它沒(méi)有改變結(jié)果。在 SQlite3 數(shù)據(jù)庫(kù)的情況下, Python 比 PyPy 快。
總的來(lái)說(shuō),這讓我很驚訝。當(dāng) Python 勝過(guò) PyPy 時(shí),并不是關(guān)于數(shù)量級(jí)的。由于我不是 Python 或 PyPy 專(zhuān)家,我不確定為什么 Python 在某些情況下更好。可能是因?yàn)?PyPy 是一個(gè) JIT 編譯器,所以在運(yùn)行它時(shí),它首先編譯代碼。
另一方面,默認(rèn)的 Python 解釋器不會(huì)這樣做。因此,對(duì)于 PyPy 的劣勢(shì),JIT 編譯增加了一些所需的時(shí)間。盡管如此,PyPy 在某些情況下提供了更快的執(zhí)行速度。 如您所見(jiàn),它在 5 種情況下的 3 種情況下提供了更快的執(zhí)行。
原文:https://louispetrik.medium.com/pypy-vs-python-49153daca65c