Spark 數據傾斜及其解決方案
本文從數據傾斜的危害、現象、原因等方面,由淺入深闡述Spark數據傾斜及其解決方案。
一、什么是數據傾斜
對 Spark/Hadoop 這樣的分布式大數據系統來講,數據量大并不可怕,可怕的是數據傾斜。
對于分布式系統而言,理想情況下,隨著系統規模(節點數量)的增加,應用整體耗時線性下降。如果一臺機器處理一批大量數據需要120分鐘,當機器數量增加到3臺時,理想的耗時為120 / 3 = 40分鐘。但是,想做到分布式情況下每臺機器執行時間是單機時的1 / N,就必須保證每臺機器的任務量相等。不幸的是,很多時候,任務的分配是不均勻的,甚至不均勻到大部分任務被分配到個別機器上,其它大部分機器所分配的任務量只占總得的小部分。比如一臺機器負責處理 80% 的任務,另外兩臺機器各處理 10% 的任務。
『不患多而患不均』,這是分布式環境下最大的問題。意味著計算能力不是線性擴展的,而是存在短板效應: 一個 Stage 所耗費的時間,是由最慢的那個 Task 決定。
由于同一個 Stage 內的所有 task 執行相同的計算,在排除不同計算節點計算能力差異的前提下,不同 task 之間耗時的差異主要由該 task 所處理的數據量決定。所以,要想發揮分布式系統并行計算的優勢,就必須解決數據傾斜問題。
二、數據傾斜的危害
當出現數據傾斜時,小量任務耗時遠高于其它任務,從而使得整體耗時過大,未能充分發揮分布式系統的并行計算優勢。
另外,當發生數據傾斜時,部分任務處理的數據量過大,可能造成內存不足使得任務失敗,并進而引進整個應用失敗。
三、數據傾斜的現象
當發現如下現象時,十有八九是發生數據傾斜了:
- 絕大多數 task 執行得都非常快,但個別 task 執行極慢,整體任務卡在某個階段不能結束。
- 原本能夠正常執行的 Spark 作業,某天突然報出 OOM(內存溢出)異常,觀察異常棧,是我們寫的業務代碼造成的。這種情況比較少見。
TIPS
在 Spark streaming 程序中,數據傾斜更容易出現,特別是在程序中包含一些類似 sql 的 join、group 這種操作的時候。因為 Spark Streaming 程序在運行的時候,我們一般不會分配特別多的內存,因此一旦在這個過程中出現一些數據傾斜,就十分容易造成 OOM。
四、數據傾斜的原因
在進行 shuffle 的時候,必須將各個節點上相同的 key 拉取到某個節點上的一個 task 來進行處理,比如按照 key 進行聚合或 join 等操作。此時如果某個 key 對應的數據量特別大的話,就會發生數據傾斜。比如大部分 key 對應10條數據,但是個別 key 卻對應了100萬條數據,那么大部分 task 可能就只會分配到10條數據,然后1秒鐘就運行完了;但是個別 task 可能分配到了100萬數據,要運行一兩個小時。
因此出現數據傾斜的時候,Spark 作業看起來會運行得非常緩慢,甚至可能因為某個 task 處理的數據量過大導致內存溢出。
五、問題發現與定位
1、通過 Spark Web UI
通過 Spark Web UI 來查看當前運行的 stage 各個 task 分配的數據量(Shuffle Read Size/Records),從而進一步確定是不是 task 分配的數據不均勻導致了數據傾斜。
知道數據傾斜發生在哪一個 stage 之后,接著我們就需要根據 stage 劃分原理,推算出來發生傾斜的那個 stage 對應代碼中的哪一部分,這部分代碼中肯定會有一個 shuffle 類算子。可以通過 countByKey 查看各個 key 的分布。
TIPS
數據傾斜只會發生在 shuffle 過程中。這里給大家羅列一些常用的并且可能會觸發 shuffle 操作的算子: distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition 等。出現數據傾斜時,可能就是你的代碼中使用了這些算子中的某一個所導致的。
2、通過 key 統計
也可以通過抽樣統計 key 的出現次數驗證。
由于數據量巨大,可以采用抽樣的方式,對數據進行抽樣,統計出現的次數,根據出現次數大小排序取出前幾個:
df.select("key").sample(false, 0.1) // 數據采樣
.(k => (k, 1)).reduceBykey(_ + _) // 統計 key 出現的次數
.map(k => (k._2, k._1)).sortByKey(false) // 根據 key 出現次數進行排序
.take(10) // 取前 10 個。
如果發現多數數據分布都較為平均,而個別數據比其他數據大上若干個數量級,則說明發生了數據傾斜。
六、如何緩解數據傾斜
基本思路
業務邏輯: 我們從業務邏輯的層面上來優化數據傾斜,比如要統計不同城市的訂單情況,那么我們單獨對這一線城市來做 count,最后和其它城市做整合。
程序實現: 比如說在 Hive 中,經常遇到 count(distinct)操作,這樣會導致最終只有一個 reduce,我們可以先 group 再在外面包一層 count,就可以了;在 Spark 中使用 reduceByKey 替代 groupByKey 等。
參數調優: Hadoop 和 Spark 都自帶了很多的參數和機制來調節數據傾斜,合理利用它們就能解決大部分問題。
思路1. 過濾異常數據
如果導致數據傾斜的 key 是異常數據,那么簡單的過濾掉就可以了。
首先要對 key 進行分析,判斷是哪些 key 造成數據傾斜。具體方法上面已經介紹過了,這里不贅述。
然后對這些 key 對應的記錄進行分析:
- 空值或者異常值之類的,大多是這個原因引起
- 無效數據,大量重復的測試數據或是對結果影響不大的有效數據
- 有效數據,業務導致的正常數據分布
解決方案
對于第 1,2 種情況,直接對數據進行過濾即可。
第3種情況則需要特殊的處理,具體我們下面詳細介紹。
思路2. 提高 shuffle 并行度
Spark 在做 Shuffle 時,默認使用 HashPartitioner(非 Hash Shuffle)對數據進行分區。如果并行度設置的不合適,可能造成大量不相同的 Key 對應的數據被分配到了同一個 Task 上,造成該 Task 所處理的數據遠大于其它 Task,從而造成數據傾斜。
如果調整 Shuffle 時的并行度,使得原本被分配到同一 Task 的不同 Key 發配到不同 Task 上處理,則可降低原 Task 所需處理的數據量,從而緩解數據傾斜問題造成的短板效應。
(1)操作流程
- RDD 操作 可在需要 Shuffle 的操作算子上直接設置并行度或者使用 spark.default.parallelism 設置。如果是 Spark SQL,還可通過 SET
- spark.sql.shuffle.partitions=[num_tasks] 設置并行度。默認參數由不同的 Cluster Manager 控制。
- dataFrame 和 sparkSql 可以設置
- spark.sql.shuffle.partitions=[num_tasks] 參數控制 shuffle 的并發度,默認為200。
(2)適用場景
大量不同的 Key 被分配到了相同的 Task 造成該 Task 數據量過大。
(3)解決方案
調整并行度。一般是增大并行度,但有時如減小并行度也可達到效果。
(4)優勢
實現簡單,只需要參數調優。可用最小的代價解決問題。一般如果出現數據傾斜,都可以通過這種方法先試驗幾次,如果問題未解決,再嘗試其它方法。
(5)劣勢
適用場景少,只是讓每個 task 執行更少的不同的key。無法解決個別key特別大的情況造成的傾斜,如果某些 key 的大小非常大,即使一個 task 單獨執行它,也會受到數據傾斜的困擾。并且該方法一般只能緩解數據傾斜,沒有徹底消除問題。從實踐經驗來看,其效果一般。
TIPS 可以把數據傾斜類比為 hash 沖突。提高并行度就類似于 提高 hash 表的大小。
思路3. 自定義 Partitioner
(1)原理
使用自定義的 Partitioner(默認為 HashPartitioner),將原本被分配到同一個 Task 的不同 Key 分配到不同 Task。
例如,我們在 groupByKey 算子上,使用自定義的 Partitioner:
.groupByKey(new Partitioner() {
@Override
public int numPartitions() {
return 12;
}
@Override
public int getPartition(Object key) {
int id = Integer.parseInt(key.toString());
if(id >= 9500000 && id <= 9500084 && ((id - 9500000) % 12) == 0) {
return (id - 9500000) / 12;
} else {
return id % 12;
}
}
})
TIPS 這個做法相當于自定義 hash 表的 哈希函數。
(2)適用場景
大量不同的 Key 被分配到了相同的 Task 造成該 Task 數據量過大。
(3)解決方案
使用自定義的 Partitioner 實現類代替默認的 HashPartitioner,盡量將所有不同的 Key 均勻分配到不同的 Task 中。
(4)優勢
不影響原有的并行度設計。如果改變并行度,后續 Stage 的并行度也會默認改變,可能會影響后續 Stage。
(5)劣勢
適用場景有限,只能將不同 Key 分散開,對于同一 Key 對應數據集非常大的場景不適用。效果與調整并行度類似,只能緩解數據傾斜而不能完全消除數據傾斜。而且需要根據數據特點自定義專用的 Partitioner,不夠靈活。
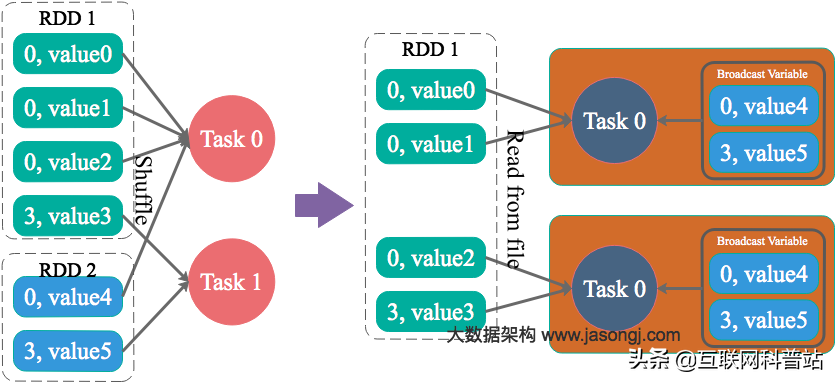
思路4. Reduce 端 Join 轉化為 Map 端 Join
通過 Spark 的 Broadcast 機制,將 Reduce 端 Join 轉化為 Map 端 Join,這意味著 Spark 現在不需要跨節點做 shuffle 而是直接通過本地文件進行 join,從而完全消除 Shuffle 帶來的數據傾斜。
from pyspark.sql.functions import broadcast
result = broadcast(A).join(B, ["join_col"], "left")
其中 A 是比較小的 dataframe 并且能夠整個存放在 executor 內存中。
(1)適用場景
參與Join的一邊數據集足夠小,可被加載進 Driver 并通過 Broadcast 方法廣播到各個 Executor 中。
(2)解決方案
在 Java/Scala 代碼中將小數據集數據拉取到 Driver,然后通過 Broadcast 方案將小數據集的數據廣播到各 Executor。或者在使用 SQL 前,將 Broadcast 的閾值調整得足夠大,從而使 Broadcast 生效。進而將 Reduce Join 替換為 Map Join。
(3)優勢
避免了 Shuffle,徹底消除了數據傾斜產生的條件,可極大提升性能。
(4)劣勢
因為是先將小數據通過 Broadcase 發送到每個 executor 上,所以需要參與 Join 的一方數據集足夠小,并且主要適用于 Join 的場景,不適合聚合的場景,適用條件有限。
NOTES
- 使用Spark SQL時需要通過 SET
- spark.sql.autoBroadcastJoinThreshold=104857600 將 Broadcast 的閾值設置得足夠大,才會生效。
思路5. 拆分 join 再 union
思路很簡單,就是將一個 join 拆分成 傾斜數據集 Join 和 非傾斜數據集 Join,最后進行 union:
- 對包含少數幾個數據量過大的 key 的那個 RDD (假設是 leftRDD),通過 sample 算子采樣出一份樣本來,然后統計一下每個 key 的數量,計算出來數據量最大的是哪幾個 key。具體方法上面已經介紹過了,這里不贅述。
- 然后將這 k 個 key 對應的數據從 leftRDD 中單獨過濾出來,并給每個 key 都打上 1~n 以內的隨機數作為前綴,形成一個單獨的 leftSkewRDD;而不會導致傾斜的大部分 key 形成另外一個 leftUnSkewRDD。
- 接著將需要 join 的另一個 rightRDD,也過濾出來那幾個傾斜 key 并通過 flatMap 操作將該數據集中每條數據均轉換為 n 條數據(這 n 條數據都按順序附加一個 0~n 的前綴),形成單獨的 rightSkewRDD;不會導致傾斜的大部分 key 也形成另外一個 rightUnSkewRDD。
- 現在將 leftSkewRDD 與 膨脹 n 倍的 rightSkewRDD 進行 join,且在 Join 過程中將隨機前綴去掉,得到傾斜數據集的 Join 結果 skewedJoinRDD。注意到此時我們已經成功將原先相同的 key 打散成 n 份,分散到多個 task 中去進行 join 了。
- 對 leftUnSkewRDD 與 rightUnRDD 進行Join,得到 Join 結果 unskewedJoinRDD。
- 通過 union 算子將 skewedJoinRDD 與 unskewedJoinRDD 進行合并,從而得到完整的 Join 結果集。
TIPS
- rightRDD 與傾斜 Key 對應的部分數據,需要與隨機前綴集 (1~n) 作笛卡爾乘積 (即將數據量擴大 n 倍),從而保證無論數據傾斜側傾斜 Key 如何加前綴,都能與之正常 Join。skewRDD 的 join 并行度可以設置為 n * k (k 為 topSkewkey 的個數)。由于傾斜Key與非傾斜Key的操作完全獨立,可并行進行。
(1)適用場景
兩張表都比較大,無法使用 Map 端 Join。其中一個 RDD 有少數幾個 Key 的數據量過大,另外一個 RDD 的 Key 分布較為均勻。
(2)解決方案
將有數據傾斜的 RDD 中傾斜 Key 對應的數據集單獨抽取出來加上隨機前綴,另外一個 RDD 每條數據分別與隨機前綴結合形成新的RDD(相當于將其數據增到到原來的N倍,N即為隨機前綴的總個數),然后將二者Join并去掉前綴。然后將不包含傾斜Key的剩余數據進行Join。最后將兩次Join的結果集通過union合并,即可得到全部Join結果。
(3)優勢
相對于 Map 則 Join,更能適應大數據集的 Join。如果資源充足,傾斜部分數據集與非傾斜部分數據集可并行進行,效率提升明顯。且只針對傾斜部分的數據做數據擴展,增加的資源消耗有限。
(4)劣勢
如果傾斜 Key 非常多,則另一側數據膨脹非常大,此方案不適用。而且此時對傾斜 Key 與非傾斜 Key 分開處理,需要掃描數據集兩遍,增加了開銷。
思路6. 大表 key 加鹽,小表擴大 N 倍 jion
如果出現數據傾斜的 Key 比較多,上一種方法將這些大量的傾斜 Key 分拆出來,意義不大。此時更適合直接對存在數據傾斜的數據集全部加上隨機前綴,然后對另外一個不存在嚴重數據傾斜的數據集整體與隨機前綴集作笛卡爾乘積(即將數據量擴大N倍)。
其實就是上一個方法的特例或者簡化。少了拆分,也就沒有 union。
(1)適用場景
一個數據集存在的傾斜 Key 比較多,另外一個數據集數據分布比較均勻。
(2)優勢
對大部分場景都適用,效果不錯。
(3)劣勢
需要將一個數據集整體擴大 N 倍,會增加資源消耗。
思路7. map 端先局部聚合
在 map 端加個 combiner 函數進行局部聚合。加上 combiner 相當于提前進行 reduce ,就會把一個 mapper 中的相同 key 進行聚合,減少 shuffle 過程中數據量 以及 reduce 端的計算量。這種方法可以有效的緩解數據傾斜問題,但是如果導致數據傾斜的 key 大量分布在不同的 mapper 的時候,這種方法就不是很有效了。
TIPS 使用 reduceByKey 而不是 groupByKey。
思路8. 加鹽局部聚合 + 去鹽全局聚合
這個方案的核心實現思路就是進行兩階段聚合。第一次是局部聚合,先給每個 key 都打上一個 1~n 的隨機數,比如 3 以內的隨機數,此時原先一樣的 key 就變成不一樣的了,比如 (hello, 1) (hello, 1) (hello, 1) (hello, 1) (hello, 1),就會變成 (1_hello, 1) (3_hello, 1) (2_hello, 1) (1_hello, 1) (2_hello, 1)。接著對打上隨機數后的數據,執行 reduceByKey 等聚合操作,進行局部聚合,那么局部聚合結果,就會變成了 (1_hello, 2) (2_hello, 2) (3_hello, 1)。然后將各個 key 的前綴給去掉,就會變成 (hello, 2) (hello, 2) (hello, 1),再次進行全局聚合操作,就可以得到最終結果了,比如 (hello, 5)。
def antiSkew(): RDD[(String, Int)] = {
val SPLIT = "-"
val prefix = new Random().nextInt(10)
pairs.map(t => ( prefix + SPLIT + t._1, 1))
.reduceByKey((v1, v2) => v1 + v2)
.map(t => (t._1.split(SPLIT)(1), t2._2))
.reduceByKey((v1, v2) => v1 + v2)
}
不過進行兩次 mapreduce,性能稍微比一次的差些。
七、Hadoop 中的數據傾斜
Hadoop 中直接貼近用戶使用的是 Mapreduce 程序和 Hive 程序,雖說 Hive 最后也是用 MR 來執行(至少目前 Hive 內存計算并不普及),但是畢竟寫的內容邏輯區別很大,一個是程序,一個是Sql,因此這里稍作區分。
Hadoop 中的數據傾斜主要表現在 ruduce 階段卡在99.99%,一直99.99%不能結束。
這里如果詳細的看日志或者和監控界面的話會發現:
- 有一個多幾個 reduce 卡住
- 各種 container報錯 OOM
- 讀寫的數據量極大,至少遠遠超過其它正常的 reduce
- 伴隨著數據傾斜,會出現任務被 kill 等各種詭異的表現。
經驗: Hive的數據傾斜,一般都發生在 Sql 中 Group 和 On 上,而且和數據邏輯綁定比較深。
優化方法
- 這里列出來一些方法和思路,具體的參數和用法在官網看就行了。
- map join 方式
- count distinct 的操作,先轉成 group,再 count
- 參數調優
- set hive.map.aggr=true
- set hive.groupby.skewindata=true
- left semi jion 的使用
- 設置 map 端輸出、中間結果壓縮。(不完全是解決數據傾斜的問題,但是減少了 IO 讀寫和網絡傳輸,能提高很多效率)
說明
hive.map.aggr=true: 在map中會做部分聚集操作,效率更高但需要更多的內存。
hive.groupby.skewindata=true: 數據傾斜時負載均衡,當選項設定為true,生成的查詢計劃會有兩個MRJob。第一個MRJob 中,Map的輸出結果集合會隨機分布到Reduce中,每個Reduce做部分聚合操作,并輸出結果,這樣處理的結果是相同的GroupBy Key有可能被分發到不同的Reduce中,從而達到負載均衡的目的;第二個MRJob再根據預處理的數據結果按照GroupBy Key分布到Reduce中(這個過程可以保證相同的GroupBy Key被分布到同一個Reduce中),最后完成最終的聚合操作。