













圖像識別更準確!尤洋團隊最新研究:全新自適應計算模型AdaTape
自適應計算(adaptive computation)是指ML統根據環境變化調整其行為的能力。
傳統神經網絡具有固定的功能和計算能力,即用相同數量的FLOP來處理不同的輸入。
但具有自適應和動態計算的模型,根據輸入的復雜性調節其專用于處理每個輸入的計算預算。
神經網絡中的自適應計算之所以吸引人,有兩個關鍵原因。
首先,引入自適應的機制提供了一種歸納偏差,可以在解決一些具有挑戰性的任務中發揮關鍵作用。
例如,為不同的輸入啟用不同數量的計算步驟對于解決需要對不同深度的層次結構進行建模的算術問題至關重要。
其次,它使從業者能夠通過動態計算,提供的更大靈活性來調整推理成本。
來自谷歌團隊發表的論文中,介紹了一種全新自適應計算的新模型——AdaTape。

論文地址:https://arxiv.org/pdf/2301.13195.pdf
最新模型是基于Transverter架構,用動態tape token和自適應Tape讀取算法來生成輸入序列,可提高圖像識別任務的性能。
AdaTape使用自適應tape讀取機制,來確定根據輸入的復雜性,添加到每個輸入中的不同數量的tape token。
AdaTape實現起來非常簡單,在需要時提供了一個有效的knob來提高準確性。
與其他自適應基線相比,AdaTape也更高效,因為它直接將適應性注入輸入序列而不是模型深度。
最后,Adatape在標準任務(如圖像分類)以及算法任務上提供了更好的性能,同時保持良好的質量和成本權衡。
彈性輸入序列的自適應計算
AdaTape使用自適應函數類型和動態計算預算。
具體來說,對于分詞后的一批輸入序列,AdaTape使用表示每個輸入的向量來動態選擇可變大小的tape token序列。
AdaTape使用稱為「tape bank」的token庫,來存儲通過自適應tape讀取機制與模型交互的所有候選tape token。
研究人員稱,創建tape庫的2種不同方法:輸入驅動庫和可學習庫。
輸入驅動庫的總體思想,是從輸入中提取一組token庫,同時采用與原始模型分詞器不同的方法,將原始輸入映射到一系列輸入token序列。
這使得動態、按需訪問從使用不同圖像分辨率獲得的輸入信息。

AdaTape整體架構
在某些情況下,由于不同抽象級別的分詞化是不可能的,因此輸入驅動的tape庫是不可行的。
例如當很難進一步拆分圖Transformer中的每個節點時。
為了解決這個問題,AdaTape提供了一種更通用的方法,通過使用一組可訓練向量作為tape token來生成tape庫。
這種方法被稱為「可學習庫」,可以被視為嵌入層,其中模型可以根據輸入示例的復雜性動態檢索token。
可學習庫使AdaTape能夠生成更靈活的tape庫,使其能夠根據每個輸入示例的復雜性動態調整其計算預算。
例如,更復雜的示例從庫中檢索更多token,這使得模型不僅使用存儲在庫中的知識,而且花費更多的FLOP來處理它,因為輸入現在更大了。
最后,選定的tape token被附加到原始輸入,并饋送到以下Transformer層。
對于每個Transformer層,在所有輸入和tape token上使用相同的多頭注意力。
但是,使用了兩種不同的前饋網絡(FFN):一種用于來自原始輸入的所有token,另一種用于所有tape token。
研究人員觀察到,通過對輸入和tape token使用單獨前饋網絡,質量略好一些。
歸納偏差
我們在奇偶校驗上評估AdaTape,這對標準Transformer來說是一項非常具有挑戰性的任務,以研究AdaTape中歸納偏差的影響。
對于奇偶校驗任務,給定序列1、0和-1,模型必須預測序列中1的數量的均勻性或奇異性。
奇偶校驗是周期性正則語言,但也許令人驚訝的是,這項任務是標準Transformer無法解決的。
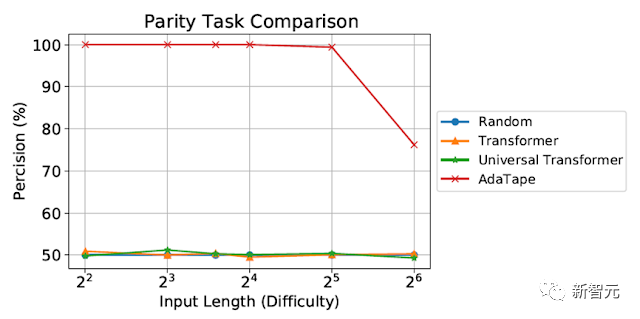
對奇偶校驗任務的評估
盡管在短而簡單的序列上進行了評估,但標準Transformer和通用Transformer都無法執行奇偶校驗任務,因為它們無法在模型中維護計數器。
然而,AdaTape的性能優于所有基線,因為它在其輸入選擇機制中結合了輕量級遞歸,提供了歸納偏差,可以隱式維護計數器,這在標準Transformer中是不可能的。
圖像分類評估
就圖像分類任務,研究人員在ImageNet-1K上從頭開始訓練AdaTape。
下圖顯示了AdaTape和基線方法的準確性,包括A-ViT和通用Transformer ViT(UViT和U2T)與其速度(以每秒每個代碼處理的圖像數量衡量)。
在質量和成本權衡方面,AdaTape的表現,比替代的自適應Transformer基線要好得多。
在效率方面,較大的AdaTape模型(就參數計數而言)比較小的基線更快。
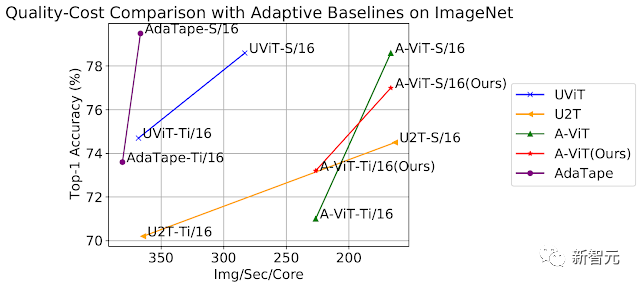
通過在ImageNet上從頭開始訓練來評估AdaTape
這樣的結果與之前的研究發現一致,即自適應模型深度架構不太適合許多加速器,如TPU。
對AdaTape行為研究
除了測試在奇偶校驗任務和ImageNet-1K上的性能,研究人員還評估了AdaTape在JFT-300M驗證集上,使用輸入驅動庫的token選擇行為。
為了更好地理解模型的行為,將輸入驅動庫上的token選擇結果可視化為熱圖,其中較淺的顏色意味著位置被更頻繁地選擇。
熱圖顯示AdaTape更頻繁地選擇中心patch。
這同樣符合先驗知識,因為中心patch通常信息更豐富。
尤其是在自然圖像數據集的上下文中,其中主要對象位于圖像中間。
這一結果凸顯了AdaTape的智能性,因為它可以有效地識別和優先考慮更多信息patch,以提高其性能。
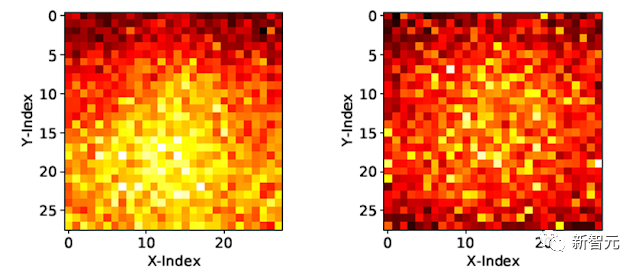
可視化AdaTape-B/32(左)和AdaTape-B/16(右)的tape token選擇熱圖
AdaTape的特點是,自適應tape讀取機制產生的彈性序列長度。
這也引入了一種新的感應偏置,使AdaTape有潛力解決,對標準Transformer和現有自適應Transformer都具有挑戰性的任務。
通過對圖像識別基準進行綜合實驗,研究證明,當計算保持不變時,AdaTape優于標準和自適應Transformer。
作者介紹
尤洋目前是新加坡國立大學校長青年教授。
2021年4月,入選亞洲福布斯30歲以下精英榜。他曾獲得了清華大學計算機系獲得碩士學位,還獲得了美國加利福尼亞大學伯克利分校計算機系獲得博士學位。























