













紐大具身智能新進(jìn)展:靠視覺反饋學(xué)會開罐頭,任務(wù)成功率提高135%,LeCun點(diǎn)贊
注意看,這個機(jī)器人用手中的鉗子輕松剪斷了一根金屬絲。

蓋上的鐵盒子,也三下五除二就打開了。

除此之外,物體抓取等任務(wù)更是能輕松完成。
這個機(jī)器人的背后,是紐約大學(xué)聯(lián)合Meta AI實驗室推出的最新具身智能成果。
研究人員提出了一種名為TAVI的新訓(xùn)練方法,將視覺與觸覺相結(jié)合,把機(jī)器人執(zhí)行任務(wù)的效果提高一倍以上。
目前,研究團(tuán)隊的論文已經(jīng)公開發(fā)表,相關(guān)代碼也已經(jīng)開源。

看到這個機(jī)器人的表現(xiàn),Meta首席科學(xué)家LeCun也不禁感嘆這是一項驚人的進(jìn)展。
那么用這種方法訓(xùn)練出的機(jī)器人,還能做些什么呢?
取物置物易如反掌
它可以把摞在一起的兩只碗分開,然后拿取上面的一個。
仔細(xì)觀察可以發(fā)現(xiàn),在分開的過程當(dāng)中,機(jī)器人的手部做出了攆的動作,讓黃色的碗沿著綠色碗的內(nèi)壁滑動。

這個機(jī)器人不僅能“分”,還能“合”。
將紅色的物塊拿起之后,機(jī)器人將它精準(zhǔn)地放入了紫色的蓋子當(dāng)中。

或者,給橡皮翻個身。
只見它將一大塊橡皮拿起,然后利用下面的盒子調(diào)整角度。
雖然不知道為什么不多用幾根手指,但畢竟也是學(xué)會了借助工具。

總之,用TAVI方式訓(xùn)練出的具身智能機(jī)器人,動作已經(jīng)和人類有了幾分相似。

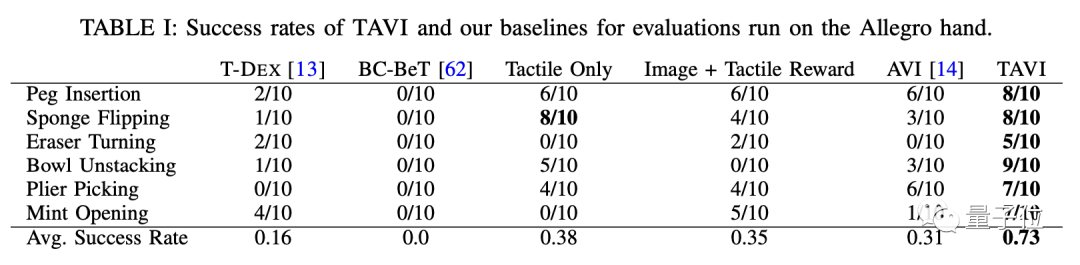
數(shù)據(jù)上,TAVI方式在6項典型任務(wù)中明顯優(yōu)于只用觸覺或視覺反饋的方法。
和不使用觸覺信息的AVI方式相比,TAVI的平均成功率提高了135%,和圖像+觸覺獎勵模型的方式相比也翻了倍。
而同樣采用視覺觸覺混合模式的T-DEX訓(xùn)練方式,成功率還不到TAVI的四分之一。
TAVI訓(xùn)練的機(jī)器人還有很強(qiáng)的泛化能力——對于未曾見過的物體,機(jī)器人也可以完成任務(wù)。
在“拿碗”和“裝盒”兩項任務(wù)中,機(jī)器人面對未知物體的成功率均超過了半數(shù)。
此外,TAVI方法訓(xùn)練出的機(jī)器人不僅能出色完成各項任務(wù),還能按順序依次執(zhí)行多項子任務(wù)。
魯棒性方面,研究團(tuán)隊通過調(diào)整相機(jī)角度進(jìn)行了測試,結(jié)果機(jī)器人依舊保持了高成功率。

那么,TAVI方法是如何實現(xiàn)這樣的效果的呢?
用視覺信息評價機(jī)器人表現(xiàn)
TAVI的核心是使用視覺上的反饋來訓(xùn)練機(jī)器人,工作主要分為三個步驟。
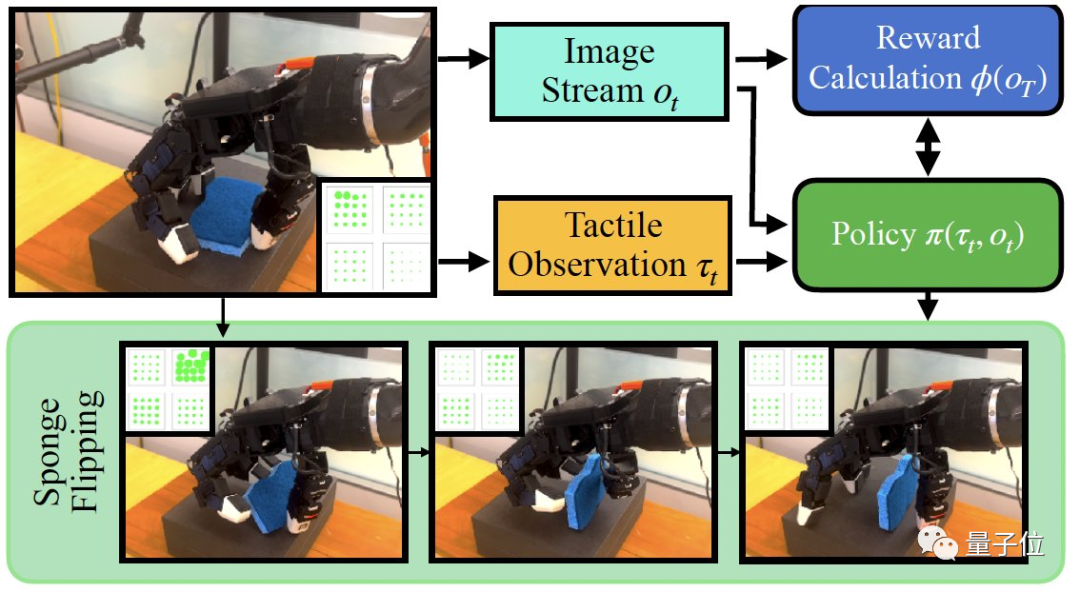
首先是從視覺和觸覺兩個維度收集人類給出的演示信息。
收集到的視覺信息會被用于建立獎勵函數(shù),以供后續(xù)學(xué)習(xí)過程中使用。
這一過程中,系統(tǒng)通過對比學(xué)習(xí)的方式來獲取對完成任務(wù)有用的視覺特征,對機(jī)器人動作完成度進(jìn)行評價。
然后結(jié)合觸覺信息和視覺反饋,通過強(qiáng)化學(xué)習(xí)方式進(jìn)行訓(xùn)練,讓機(jī)器人反復(fù)嘗試,直到獲得較高的完成度評分。
而TAVI的學(xué)習(xí)是一個循序漸進(jìn)的過程,隨著學(xué)習(xí)步驟的增加,獎勵函數(shù)越來越完善,機(jī)器人的動作也越來越精準(zhǔn)。

而為了提高TAVI的靈活性,研究團(tuán)隊還引入了一種殘差策略。
遇到與基礎(chǔ)策略出現(xiàn)差別時,只需要對有差別的部分進(jìn)行學(xué)習(xí),而不必從頭開始。
消融實驗結(jié)果表明,如果沒有殘差策略,而是每次都從頭學(xué)起,機(jī)器人完成任務(wù)的成功率將有所降低。
如果對具身智能有興趣,可以閱讀研究團(tuán)隊的論文了解更多詳情。
論文地址:https://arxiv.org/abs/2309.12300GitHub。
項目頁:https://github.com/irmakguzey/see-to-touch。




















