













GPT-4V數(shù)學推理如何?微軟發(fā)布MathVista基準,評測報告長達112頁
微軟最近發(fā)布了名為 “MathVista” 的全新多模態(tài)數(shù)學推理基準數(shù)據(jù)集,同時提供了一份涵蓋 112 頁的詳細評測報告,專注于大型多模態(tài)模型的數(shù)學推理表現(xiàn)。這一基準測試對于目前最先進的模型,如 GPT-4V,來說也是一項挑戰(zhàn),顯示了這些模型在多模態(tài)數(shù)學問題解決方面的局限性。報告還深入分析了 GPT-4V 在自我驗證、自洽性和多輪對話能力的研究潛力。

- 論文地址:https://arxiv.org/abs/2310.02255
- 項目地址:https://mathvista.github.io/
- HF 數(shù)據(jù)集:https://huggingface.co/datasets/AI4Math/MathVista
- 數(shù)據(jù)可視化:https://mathvista.github.io/#visualization
- Leaderboard:https://mathvista.github.io/#leaderboard
數(shù)學推理能力被視為實現(xiàn)通用人工智能的關鍵一步。除了傳統(tǒng)的純文字場景,許多數(shù)學研究和應用還涉及到豐富的圖形內容,這為模型的多模態(tài)處理能力提出了更高的要求。
數(shù)學問題歷史悠久,可以追溯到公元前 2000 年的美索不達米亞。那時的人們就已經(jīng)使用泥板來記錄包含梯形和三角形的數(shù)學問題。研究顯示,早在希臘哲學家畢達哥拉斯生活之前,他們就掌握了畢達哥拉斯定理 —— 也就是著名的勾股定理。

中國古代數(shù)學的杰作《周髀算經(jīng)》中不僅包含了勾股定理的優(yōu)雅證明,也展示了我們祖先在數(shù)學領域的深厚造詣。
從小接受的數(shù)學教育中,我們經(jīng)常看到各種生動有趣的圖形,這些都強調了視覺元素在數(shù)學理解中的重要性。

在現(xiàn)代科學研究中,對大量圖像數(shù)據(jù)進行數(shù)學分析成為了一個不可或缺的環(huán)節(jié)。尤其是隨著大型語言模型(LLMs)和大型多模態(tài)模型(LMMs)的發(fā)展,這些模型在多種任務和領域中展現(xiàn)出令人印象深刻的問題解決能力。
然而,這些模型在視覺場景下的數(shù)學推理能力尚未被系統(tǒng)地研究。為了探索這一領域,微軟聯(lián)合加州大學洛杉磯分校(UCLA)和華盛頓大學(UW)共同開發(fā)了全新的 MathVista 基準數(shù)據(jù)集。這個數(shù)據(jù)集結合了多種數(shù)學和視覺任務的挑戰(zhàn),包含 6141 個問題,來源于 28 個現(xiàn)有的多模態(tài)數(shù)據(jù)集和 3 個新標注的數(shù)據(jù)集,包括 IQTest、FunctionQA 和 PaperQA。MathVista 中豐富的任務類型、推理方式和圖像類型對現(xiàn)有的大型模型構成了巨大挑戰(zhàn)。
微軟的研究報告對 12 個最新的大型模型進行了全面評估。實驗結果顯示,目前性能最強的 GPT-4V 在 MathVista 上達到了 49.9% 的準確率,顯著優(yōu)于排名第二的 Bard 模型,領先了 15.1%。然而,與人類表現(xiàn)相比,GPT-4V 仍有 10.4% 的差距。這種差異主要是由于它在理解復雜圖形和進行嚴密推理方面的不足。

微軟的報告還進一步探討了 GPT-4V 的自我驗證能力、自洽性,以及其處理多輪對話的潛力。這些分析強調了未來研究的多個方向,尤其是在提高模型在復雜情境下的理解和推理能力方面。
MathVista 基準數(shù)據(jù)集
盡管目前已有多個文本為主的數(shù)學推理數(shù)據(jù)集和多模態(tài)問答數(shù)據(jù)集,但在全面評估大型模型在數(shù)學推理領域的能力方面,特別是在多模態(tài)數(shù)據(jù)集方面,仍存在顯著的空白。
為此,微軟提出了 MathVista 數(shù)據(jù)集,聚焦于視覺場景下的數(shù)學問答任務。MathVista 包含 6141 個數(shù)學問題,來自于 28 個現(xiàn)有數(shù)據(jù)集和 3 個新標注數(shù)據(jù)集 ——IQTest、FunctionQA 和 PaperQA。

這三個新標注的數(shù)據(jù)集各有特色:IQTest 側重于智力測試題,F(xiàn)unctionQA 專注于函數(shù)圖形的推理,而 PaperQA 則關注于對文獻中的圖表進行深入理解,有效地彌補了現(xiàn)有數(shù)據(jù)集的不足。

MathVista 覆蓋了兩種主要的任務類型:多選題(占比 55.2%)和數(shù)值型開放題(占比 44.8%)。它還包括五大任務類別:圖形問答(FQA)、幾何解題(GPS)、數(shù)學應用題(MWP)、教材問答(TQA)和視覺問答(VQA),這些任務類別代表了當前數(shù)學推理領域的前沿挑戰(zhàn)。
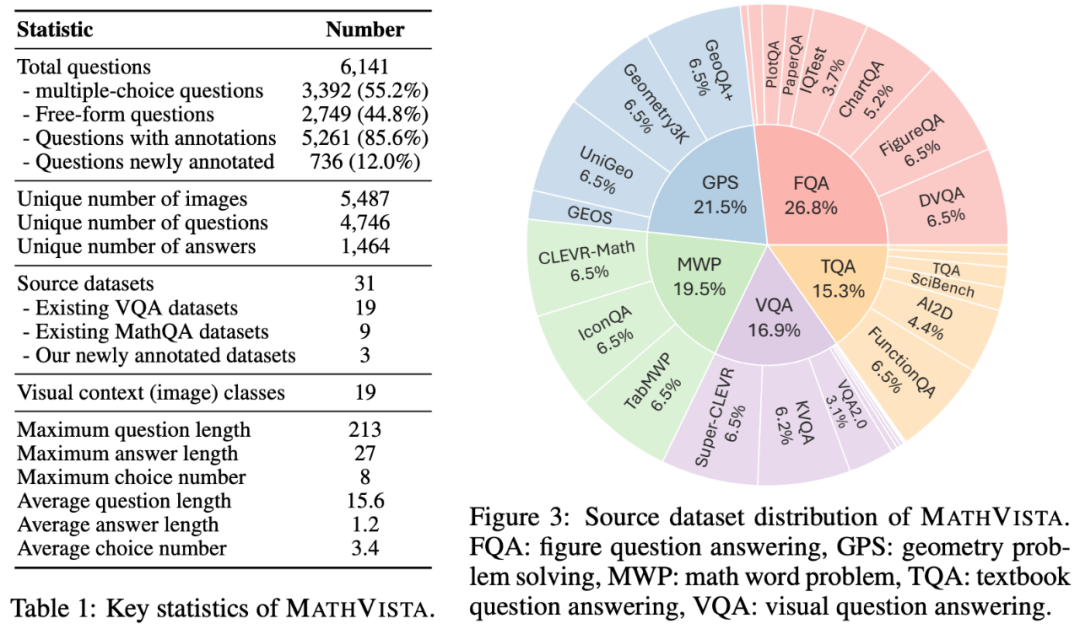
MathVista 中的數(shù)學推理能力與圖像多樣性
MathVista 細分并定義了數(shù)學推理的七大能力領域,包括:算術、統(tǒng)計、代數(shù)、幾何、數(shù)值常識、科學和邏輯。這些領域涵蓋了數(shù)學推理的核心要素,體現(xiàn)了 MathVista 在數(shù)學認知范圍的全面覆蓋。


在圖像類型的多樣性方面,MathVista 也展現(xiàn)了其獨特的廣度和深度。該數(shù)據(jù)集包含了十余種不同的圖像類型,從自然圖像到幾何圖表,從抽象場景到合成場景,以及各種圖形、圖表和繪圖。這種豐富的圖像類型不僅增加了數(shù)據(jù)集的復雜性,也為大型多模態(tài)模型在處理不同類型的視覺信息時提供了全面的挑戰(zhàn)。




全面的量化評估
微軟的研究報告首次對當前大模型在視覺場景下的數(shù)學推理能力進行了全面的量化評估。報告中使用的 MathVista 數(shù)據(jù)集分為兩個子集:minitest 和 test。minitest 子集含有 1000 個問題,主要用于快速評估模型性能。而 test 子集則包含剩余的 5141 個問題,旨在進行模型的標準化評估,因此為了避免測試數(shù)據(jù)污染,該子集的答案標簽數(shù)據(jù)不對外公開。
模型評估過程分為三個關鍵階段:生成回答、抽取答案和計算分數(shù)。在生成回答階段,根據(jù)測試問題的類型,研究團隊使用了特定的模板來引導模型輸出答案。

考慮到當前大型模型通常以對話形式輸出長文本回答,報告中的實驗設計了一個基于 GPT-4 的答案抽取器。這個抽取器通過幾個實例提示 GPT-4,從模型的長文本回答中抽取出符合題目類型的短答案。這種方法有效地克服了傳統(tǒng)人工評估的高成本問題和基于規(guī)則的答案抽取可能導致的不準確性。隨后,這些抽取出來的短文本答案被用于計算模型的總體準確率以及在不同子分類別下的準確率。

MathVista 上的大型模型評估實驗
實驗在 testmini 子集上評估了 12 種大模型:包括 ChatGPT、GPT-4 和 Claude-2 等三個大型語言模型,以及 LLaVA、LLaMA-Adapter、miniGPT-4、Bard 和 GPT-4V 等 9 種大型多模態(tài)模型。對于大型語言模型,實驗設計了兩種形式,第一種只利用問題的文字信息,第二種是使用圖片的 Captioning 描述和 OCR 文本作為外部增強信息。此外,實驗還完成了兩種隨機基準和人類表現(xiàn)基準。

實驗結果顯示,當前的大模型在 MathVista 上的整體表現(xiàn)仍有待提升。表現(xiàn)最佳的 GPT-4V 模型達到了 49.9% 的準確率,但這與人類的 60.3% 表現(xiàn)相比還有顯著差距。其次是 Bard 模型,準確率為 34.8%,而目前最好的開源模型 LLaVA 的準確率則為 26.1%。這些數(shù)據(jù)表明,大型模型在視覺背景下的數(shù)學推理能力還有很大的提升空間。
有趣的是,當結合圖像 OCR 和 Captioning 信息時,大型語言模型 GPT-4 的表現(xiàn)(33.9%)接近于多模態(tài)模型 Bard(34.8%)。這一發(fā)現(xiàn)顯示,通過適當?shù)墓ぞ咴鰪姡笮驼Z言模型在多模態(tài)領域具有巨大的潛力。
實驗還對主要模型在不同數(shù)學推理能力和圖像類型子類上的表現(xiàn)進行了量化評估。結果顯示,GPT-4V 在諸如代數(shù)、幾何和科學領域的推理能力上,以及在處理表格、函數(shù)圖、幾何圖像、散點圖和科學圖形等圖像類型時,其表現(xiàn)接近甚至超過了人類。

在 test 子集的評估中,實驗比較了最佳的兩個大型語言模型(CoT/PoT GPT-4)和最好的開源大型多模態(tài)模型(LLaVA),提供了一個全面的模型性能概覽。

Bard 在 MathVista 中的表現(xiàn)
在 MathVista 上的評估顯示,Bard 模型的總體表現(xiàn)緊隨 GPT-4 之后。通過具體案例分析,報告發(fā)現(xiàn) Bard 模型經(jīng)常產(chǎn)生所謂的 “幻覺現(xiàn)象”,即在生成的答案中引入了問題文本和圖片中不存在的信息。此外,Bard 在進行數(shù)學運算時也容易出現(xiàn)錯誤。

例如,在下面的例子中,Bard 在簡化分式 8/10 的過程中犯了計算錯誤。這種問題突顯了模型在處理數(shù)學問題時的局限性。

GPT-4 在 MathVista 上的表現(xiàn)
雖然 GPT-4 本質上是一種語言模型,但通過工具增強(例如 OCR 文字和 captioning 描述的結合),它在 MathVista 上的性能可以達到與多模態(tài)模型 Bard 相當?shù)乃健>唧w來說,當引入這些圖片的 OCR 文字和 Captioning 描述作為輔助輸入信息時,GPT-4 能夠成功解決許多多模態(tài)數(shù)學問題。這一發(fā)現(xiàn)顯示了 GPT-4 在多模態(tài)問題處理方面的潛力。
然而,GPT-4 對這些增強信息的準確性有著極高的依賴性。如果這些 OCR 文字或 Captioning 描述存在錯誤或不準確性,GPT-4 在推理過程中就很容易走向錯誤的方向,從而導致不正確的結果。這一點凸顯了在使用工具增強大型語言模型時,輸入信息質量的重要性。

GPT-4V 在 MathVista 上的全方位分析
GPT-4V 作為目前最先進的大型多模態(tài)模型,對其能力的深入分析對未來的研究具有重要意義。報告通過大量實例詳盡分析了 GPT-4V 在不同維度的能力,特別是在自我驗證、自洽性和多輪對話方面的巨大潛力。
代數(shù)推理能力:在 MathVista 的代數(shù)問題中,GPT-4V 展現(xiàn)了理解圖像中函數(shù)并推斷其性質的出色能力,甚至超過了其他大型模型和人類。但在處理低分辨率圖像和多函數(shù)圖像時,GPT-4V 仍面臨挑戰(zhàn)。


數(shù)值計算能力:MathVista 中的算術問題不僅需要準確的基礎運算,還需理解多樣化視覺場景。如下圖所示,GPT-4V 在此方面相比現(xiàn)有模型表現(xiàn)出顯著的提升。

幾何推理能力:在幾何推理方面,GPT-4V 在 MathVista 上的表現(xiàn)與人類相當。在以下兩個例子中,無論是小學難度還是高年級難度的問題,GPT-4V 均能給出正確答案,并附有詳細解釋。



邏輯推理能力:在 MathVista 的邏輯推理問題中,模型需從抽象圖形中推導出數(shù)字或形狀的隱含規(guī)律。GPT-4V 在這方面遇到了挑戰(zhàn),其準確率僅為 21.6%,僅略高于隨機猜測的 8.1%。


數(shù)值常識推理能力:MathVista 中的數(shù)值常識推理涉及日常物品和名人知識。這類問題對大型模型是一大挑戰(zhàn)。例如,下圖所示的問題中,只有 GPT-4V 能正確理解圖像中的光學錯覺現(xiàn)象。

然而,某些情況下,例如識別燒杯的最大容量,GPT-4V 與 Bard 模型均表現(xiàn)不佳。

科學推理能力:在 MathVista 的科學推理問題上,GPT-4V 顯著優(yōu)于其他大型模型。它經(jīng)常能準確解析涉及特定科學領域的圖中信息,并進行后續(xù)推理。


然而,某些基本概念的應用,如相對運動,仍是 GPT-4V 的弱點。


統(tǒng)計推理能力:GPT-4V 在理解 MathVista 中的各種圖表、繪圖和圖形方面展現(xiàn)出強大的統(tǒng)計推理能力。它能準確解答涉及圖表分析的數(shù)學問題,超過了其他大型模型。



GPT-4V 的自我驗證能力探究
自我驗證(self-verification)是一種社會心理學概念,其核心觀點是個體希望他人按照他們自我感知的方式來理解他們。這導致個體主動采取行動,確保他人能看到他們的穩(wěn)定狀態(tài)(Talaifar & Swann, 2020)。
在微軟的實驗中,GPT-4V 顯示出了一種類似的自我驗證能力。這種能力體現(xiàn)在 GPT-4V 能夠在推理過程中自主檢查自身的行為,并主動糾正可能的錯誤。值得注意的是,這種自我驗證能力不同于僅依賴外部反饋或多輪對話來改進模型輸出。例如,在某些情況下,GPT-4V 能夠在單次輸出中自行審核一組候選答案,從而識別出符合所有給定條件的有效答案。

在以下多步推理問題中,GPT-4V 顯示出了顯著的能力。它不僅能夠進行連貫的推理,還能驗證關鍵步驟的有效性。特別是在遇到無效的中間結果時,如發(fā)現(xiàn)得出的長度為負數(shù),GPT-4V 能夠主動檢測并識別這些錯誤。這種能力使得 GPT-4V 在識別問題后,能夠嘗試采用不同的方法來解決問題,從而優(yōu)化其推理過程。


GPT-4V 的自洽性應用及其局限性
自洽性(self-consistency)是在大型語言模型中廣泛使用的一種技術,目的是提升模型在處理復雜推理任務時的準確性。這種方法通常包括采樣多種推理路徑,并選擇出現(xiàn)頻次最高的答案作為最終解。
微軟的實驗驗證了自洽性技術在提高 GPT-4V 在 MathVista 上的性能方面的有效性。實驗表明,自洽性對于糾正 GPT-4V 在視覺感知和計算中的錯誤,以及減少幻覺現(xiàn)象方面起到了顯著作用。



然而,實驗也揭示了自洽性的局限性。特別是在 GPT-4V 難以正確理解復雜的視覺場景的情況下,自洽性的改善效果并不顯著。這表明,盡管自洽性是一種有效的提升方法,但它的成功在很大程度上還是依賴于模型對視覺信息的基本理解能力。

GPT-4V 在 MathVista 上的多輪對話能力
微軟的報告最后探討了 GPT-4V 在 MathVista 上進行多輪人機互動對話的能力。實驗結果表明,GPT-4V 擅長在多輪對話中有效地利用用戶提供的提示來優(yōu)化其推理過程。這包括根據(jù)用戶的引導來糾正視覺感知上的誤解,修正推理邏輯中的不一致,更正相關領域的知識,甚至在人類的協(xié)助下理解和處理極其復雜的圖表問題。





主要華人作者
Pan Lu

Pan Lu 是加州大學洛杉磯分校(UCLA)的博士生,是 UCLA 自然語言處理實驗室(NLP Group)和視覺、認知、學習和自主中心(VCLA)的成員。
在此之前,他在清華大學獲得計算機科學碩士學位。他曾在微軟和艾倫人工智能研究院進行過實習。
他是 ScienceQA 和 Chameleon 等工作的作者。他曾榮獲亞馬遜博士獎學金、彭博社博士獎學金和高通創(chuàng)新獎學金。
Tony Xia

Tony Xia 是斯坦福大學計算機系的碩士生。此前,他在加州大學洛杉磯分校獲得計算機本科學位。
Jiacheng Liu

Jiacheng Liu 是華盛頓大學的博士生,從事常識推理、數(shù)學推理和文本生成的研究。
此前,他在伊利諾伊香檳分校取得本科學位。他曾獲高通創(chuàng)新獎學金。
Chunyuan Li

Chunyuan Li 是微軟雷德蒙德研究院的首席研究員。
此前,他在杜克大學獲得了機器學習博士學位,師從 Lawrence Carin 教授。他曾擔任過 NeurIPS、ICML、ICLR、EMNLP 和 AAAI 的領域主席,以及 IJCV 的客座編輯。
他是 LLaVA、Visual Instruction Tuning 和 Instruction Tuning 等工作的作者。
Hao Cheng

Hao Cheng 是微軟雷德蒙德研究院的高級研究員,同時也是華盛頓大學的兼職教授。
此前,他在華盛頓大學獲得了博士學位。他是 2017 年 Alexa Prize 冠軍團隊的主要成員。



























