













如何在Python中使用ChatGPT?API處理實時數據
譯文譯者 | 李睿
審校 | 重樓
OpenAI公司推出的GPT如今已經成為全球最重要的人工智能工具,并精通基于其訓練數據處理查詢。但是,它不能回答未知話題的問題,例如:
- 2021年9月之后的近期事件
- 非公開文件
- 來自過去談話的信息
當用戶處理頻繁變化的實時數據時,這項任務變得更加復雜。此外,用戶不能向GPT提供大量內容,它也不能長時間保留他們的數據。在這種情況下,需要有效地構建一個自定義的大型語言模型(LLM)應用程序來為回答過程提供場景。
本文將引導人們完成使用Python中的開源LLM App庫開發此類應用程序的步驟。源代碼在GitHub上(鏈接在下面的“為銷售構建ChatGPT Python API”一節中)。
學習目標
通過本文了解以下內容:
- 需要添加自定義數據到ChatGPT的原因。
- 如何使用嵌入、提示工程和ChatGPT來更好地回答問題。
- 用戶使用LLM應用程序與自定義數據構建自己的ChatGPT。
- 創建一個ChatGPT Python API查找實時折扣或銷售價格。
為什么為ChatGPT提供自定義知識庫?
在討論增強ChatGPT功能的方法之前,首先探索人工方法并確定它們面臨的挑戰。通常情況下,ChatGPT通過提示工程進行擴展。假設用戶想在各種在線市場上找到實時折扣/交易/優惠券。
例如,當詢問ChatGPT,“你能幫我找到阿迪達斯男鞋在本周的折扣嗎?”,在沒有自定義知識的情況下,可能從ChatGPT UI界面得到的標準回答是:
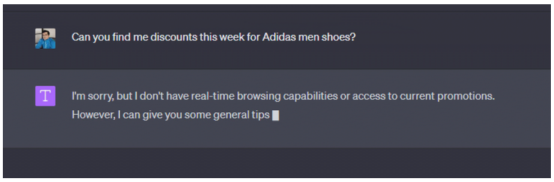
顯然,ChatGPT提供了關于尋找折扣的通常建議,但缺乏關于在哪里或什么類型的折扣以及其他細節的具體信息。現在為了幫助這個模型,使用來自可靠數據源的折扣信息對其進行補充。在發布實際問題之前,必須通過添加初始文檔內容來參與ChatGPT。將從Amazon產品交易數據集中收集這一示例數據,并在提示中僅插入一個JSON項:
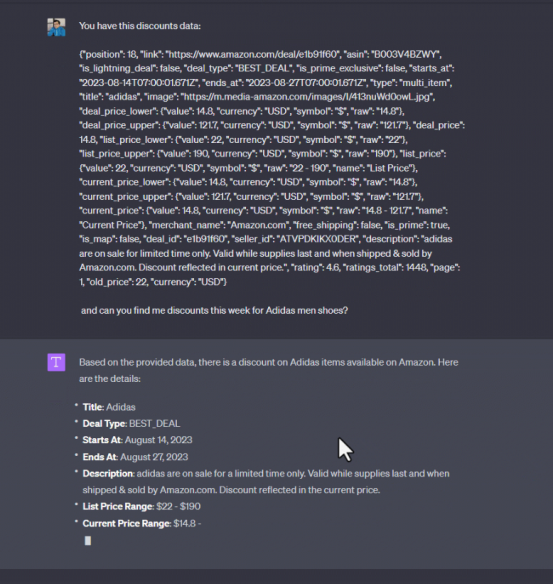
如上圖所示,用戶得到了預期的輸出,這很容易實現,因為ChatGPT現在是場景感知的。然而,這種方法的問題是模型的場景受到限制(GPT-4的最大文本長度為8,192個令牌)。當輸入數據規模非常大時,這種策略很快就會出現問題,用戶可能希望在銷售中發現數千種商品,而無法將如此大量的數據作為輸入消息提供。此外,一旦收集了數據,可能需要對數據進行清理、格式化和預處理,以確保數據質量和相關性。
如果用戶使用OpenAI聊天完成度端點或為ChatGPT構建自定義插件,它會引入以下其他問題:
- 成本—通過提供更詳細的信息和示例,大型語言模型的性能可能會得到改善,盡管成本更高(對于輸入10000個令牌和輸出200個令牌的GPT-4,每次預測的成本為0.624美元)。重復發送相同的請求會增加成本,除非使用本地緩存系統。
- 延遲—在生產中使用ChatGPT API的一個挑戰是它們的不可預測性,不能保證提供一致的服務。
- 安全性—當集成自定義插件時,每個API端點必須在OpenAPI規范中指定功能。這意味著用戶正在向ChatGPT泄露其內部API設置,這是令許多企業擔心的風險。
- 離線評估—對代碼和數據輸出進行離線測試或在本地復制數據流對開發人員來說是具有挑戰性的。這是因為對系統的每個請求可能產生不同的響應。
使用嵌入、提示工程和ChatGPT進行問答
人們在互聯網上發現的一種很有前途的方法是利用大型語言模型(LLM)創建嵌入,然后使用這些嵌入構建應用程序,例如用于搜索和詢問系統。換句話說,不是使用聊天完成端點查詢ChatGPT,而是執行以下查詢:
給定以下折扣數據:{input_data},回答這個查詢:{user_query}。
這個概念很簡單。這種方法不是直接發布問題,而是首先通過OpenAI API為每個輸入文檔(文本、圖像、CSV、PDF或其他類型的數據)創建向量嵌入,然后對生成的嵌入進行索引以便快速檢索,并將其存儲到向量數據庫中,并利用用戶的問題從向量數據庫中搜索并獲得相關文檔。然后將這些文檔與問題一起作為提示呈現給ChatGPT。有了這個添加的場景,ChatGPT就可以像在內部數據集上訓練一樣進行響應。
另一方面,如果使用Pathway的LLM App,甚至不需要任何矢量數據庫。它實現了實時內存數據索引,直接從任何兼容的存儲中讀取數據,而無需查詢矢量文檔數據庫,而這會增加準備工作、基礎設施和復雜性等成本。保持源和矢量同步是很痛苦的。此外,如果帶下劃線的輸入數據隨時間變化而需要重新索引,則會更加困難。
ChatGPT自定義數據使用LLM App
下面這些簡單的步驟解釋了使用LLM App為數據構建ChatGPT應用程序的數據管道方法。
- 收集:用戶的應用程序從各種數據源(CSV、 JSON Lines、SQL數據庫、Kafka、Redpanda、Debezium等)實時讀取數據,當流模式與路徑啟用時或者也可以在靜態模式下測試數據攝取。它還將每個數據行映射到結構化文檔模式中,以便更好地管理大型數據集。
- 預處理:可以選擇通過刪除可能影響回答質量的重復、不相關信息和嘈雜數據,并提取需要進一步處理的數據字段,從而輕松地進行數據清理。此外,在這個階段,可以屏蔽或隱藏隱私數據,以避免將它們發送到ChatGPT。
- 嵌入:每個文檔都嵌入了OpenAI API,并檢索嵌入的結果。
- 索引:在實時生成的嵌入上構建索引。
- 搜索:給定來自API友好界面的用戶問題,從OpenAI API生成查詢的嵌入。使用嵌入,根據與查詢的相關性動態檢索向量索引。
- 提問:將問題和最相關的部分插入到GPT的信息中。返回GPT的答案(聊天完成端點)。
為銷售構建ChatGPT Python API
在對LLM App的工作過程有了清晰的了解之后,可以按照下面的步驟來了解如何構建折扣查找器應用程序。其項目源代碼可以在GitHub上找到。如果想快速開始使用這個應用程序,可以跳過這一部分直接克隆存儲庫,并按照README.md文件中的說明運行代碼示例。
項目目標示例
受到一篇關于企業搜索的文章的啟發,這一示例應用程序應該在Python中公開一個HTTP REST API端點,通過從各種來源(CSV、Jsonlines、API、消息代理或數據庫)檢索最新交易來回答用戶對當前銷售的查詢,并利用OpenAI API嵌入和聊天完成端點生成式人工智能助理響應。
步驟1:數據收集(自定義數據攝取)
為了簡單起見,可以使用任何JSON行作為數據源。這個應用程序采用discounts.jsonl等JSON Lines文件,并在處理用戶查詢時使用這些數據。數據源希望每行都有一個文檔對象。確保首先將輸入數據轉換為Jsonline。下面是一個帶有單個raw的Jsonline文件的示例:
{"doc": "{'position': 1, 'link': 'https://www.amazon.com/deal/6123cc9f', 'asin': 'B00QVKOT0U', 'is_lightning_deal': False, 'deal_type': 'DEAL_OF_THE_DAY', 'is_prime_exclusive': False, 'starts_at': '2023-08-15T00:00:01.665Z', 'ends_at': '2023-08-17T14:55:01.665Z', 'type': 'multi_item', 'title': 'Deal on Crocs, DUNLOP REFINED(\u30c0\u30f3\u30ed\u30c3\u30d7\u30ea\u30d5\u30a1\u30a4\u30f3\u30c9)', 'image': 'https://m.media-amazon.com/images/I/41yFkNSlMcL.jpg', 'deal_price_lower': {'value': 35.48, 'currency': 'USD', 'symbol': '$', 'raw': '35.48'}, 'deal_price_upper': {'value': 52.14, 'currency': 'USD', 'symbol': '$', 'raw': '52.14'}, 'deal_price': 35.48, 'list_price_lower': {'value': 49.99, 'currency': 'USD', 'symbol': '$', 'raw': '49.99'}, 'list_price_upper': {'value': 59.99, 'currency': 'USD', 'symbol': '$', 'raw': '59.99'}, 'list_price': {'value': 49.99, 'currency': 'USD', 'symbol': '$', 'raw': '49.99 - 59.99', 'name': 'List Price'}, 'current_price_lower': {'value': 35.48, 'currency': 'USD', 'symbol': '$', 'raw': '35.48'}, 'current_price_upper': {'value': 52.14, 'currency': 'USD', 'symbol': '$', 'raw': '52.14'}, 'current_price': {'value': 35.48, 'currency': 'USD', 'symbol': '$', 'raw': '35.48 - 52.14', 'name': 'Current Price'}, 'merchant_name': 'Amazon Japan', 'free_shipping': False, 'is_prime': False, 'is_map': False, 'deal_id': '6123cc9f', 'seller_id': 'A3GZEOQINOCL0Y', 'description': 'Deal on Crocs, DUNLOP REFINED(\u30c0\u30f3\u30ed\u30c3\u30d7\u30ea\u30d5\u30a1\u30a4\u30f3\u30c9)', 'rating': 4.72, 'ratings_total': 6766, 'page': 1, 'old_price': 49.99, 'currency': 'USD'}"}最酷的是,這個應用程序總是能意識到數據文件夾中的更改。如果添加另一個JSON Lines文件,LLM App就會發揮神奇的作用,自動更新人工智能模型的響應。
步驟2:數據加載和映射
使用Pathway的JSON Lines輸入連接器,將讀取本地JSONlines文件,將數據條目映射到模式中,并創建一個路徑表。可以參閱app.py中的完整源代碼:
...
sales_data = pw.io.jsonlines.read(
"./examples/data",
schema=DataInputSchema,
mode="streaming"
)將每個數據行映射到結構化文檔模式。可以參閱App.py中的完整源代碼:
class DataInputSchema(pw.Schema):
doc: str步驟3:數據嵌入
每個文檔都嵌入了OpenAI API,并檢索嵌入的結果。可以參閱app.py中的完整源代碼:
...
embedded_data = embeddings(cnotallow=sales_data, data_to_embed=sales_data.doc)步驟4:數據索引
然后在生成的嵌入上構建一個即時索引:
index = index_embeddings(embedded_data)步驟5:用戶查詢處理和索引
創建一個REST端點,從API請求負載中獲取用戶查詢,并將用戶查詢嵌入OpenAI API。
...
query, response_writer = pw.io.http.rest_connector(
host=host,
port=port,
schema=QueryInputSchema,
autocommit_duration_ms=50,
)
embedded_query = embeddings(cnotallow=query, data_to_embed=pw.this.query)步驟6:相似性搜索和提示工程
通過使用索引來識別查詢嵌入的最相關匹配來執行相似性搜索。然后構建一個提示,將用戶的查詢與獲取的相關數據結果合并,并將消息發送到ChatGPT完成端點,以生成正確且詳細的響應。
responses = prompt(index, embedded_query, pw.this.query)當制作提示符并在prompt.py中向ChatGPT添加內部知識時,遵循了相同的場景學習方法。
prompt = f"Given the following discounts data: \\n {docs_str} \\nanswer this query: {query}"步驟7:返回響應
最后一步就是將API響應返回給用戶。
# Build prompt using indexed data
responses = prompt(index, embedded_query, pw.this.query)步驟8:將把所有步驟放在一起
現在,如果將上述所有步驟放在一起,就擁有了用于自定義折扣數據的支持LLM的Python API,可以在app.py Python腳本中看到實現。
import pathway as pw
from common.embedder import embeddings, index_embeddings
from common.prompt import prompt
def run(host, port):
# Given a user question as a query from your API
query, response_writer = pw.io.http.rest_connector(
host=host,
port=port,
schema=QueryInputSchema,
autocommit_duration_ms=50,
)
# Real-time data coming from external data sources such as jsonlines file
sales_data = pw.io.jsonlines.read(
"./examples/data",
schema=DataInputSchema,
mode="streaming"
)
# Compute embeddings for each document using the OpenAI Embeddings API
embedded_data = embeddings(cnotallow=sales_data, data_to_embed=sales_data.doc)
# Construct an index on the generated embeddings in real-time
index = index_embeddings(embedded_data)
# Generate embeddings for the query from the OpenAI Embeddings API
embedded_query = embeddings(cnotallow=query, data_to_embed=pw.this.query)
# Build prompt using indexed data
responses = prompt(index, embedded_query, pw.this.query)
# Feed the prompt to ChatGPT and obtain the generated answer.
response_writer(responses)
# Run the pipeline
pw.run()
class DataInputSchema(pw.Schema):
doc: str
class QueryInputSchema(pw.Schema):
query: str步驟9 (可選):添加交互式UI
為了讓應用程序更具互動性和用戶友好性,可以使用Streamlit來構建一個前端應用。
運行應用程序
按照README. Md文件中“如何運行項目”一節中的說明,可以開始詢問有關折扣的問題,API將根據添加的折扣數據源做出響應。
在使用UI(應用數據源)將這些知識提供給GPT之后,看看它是如何回復的:
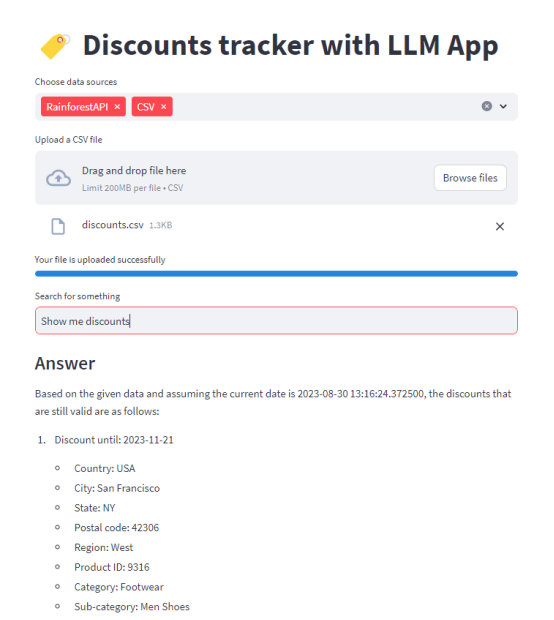
這個應用程序考慮了Rainforest API和discount .csv文件文檔(立即合并來自這些來源的數據),實時對其進行索引,并在處理查詢時使用這些數據。
進一步的改進
通過向ChatGPT添加折扣等領域特定知識,發現了LLM應用程序的一些功能。還可以做更多的事情:
- 整合來自外部API的額外數據,以及各種文件(例如Jsonlines、PDF、Doc、HTML或Text格式),PostgreSQL或MySQL等數據庫,以及來自Kafka、Redpanda或Debedizum等平臺的流數據。
- 維護數據快照以觀察銷售價格隨時間的變化,因為Pathway提供了一個內置功能來計算兩次更改之間的差異。
- 除了通過API訪問數據之外,LLM App還允許用戶將處理過的數據中繼到其他下游連接器,例如商業智能(BI)和分析工具。例如,設置它在檢測到價格變化時接收警報。
原文標題:How To Use ChatGPT API in Python for Your Real-Time Data,作者:Bobur Umurzokov




















