













端到端大一統(tǒng)前夕?GenAD:LLM和軌跡規(guī)劃全搞定
今天汽車(chē)人和大家分享一篇自動(dòng)駕駛領(lǐng)域中第一個(gè)大規(guī)模視頻預(yù)測(cè)模型。為了消除高成本數(shù)據(jù)收集的限制,并增強(qiáng)模型的泛化能力,從網(wǎng)絡(luò)獲取了大量數(shù)據(jù),并將其與多樣化和高質(zhì)量的文本描述配對(duì)。由此產(chǎn)生的數(shù)據(jù)集累積了超過(guò)2000小時(shí)的駕駛視頻,涵蓋了世界各地具有多樣化天氣條件和交通場(chǎng)景的區(qū)域。本文提出了GenAD,它繼承了最近潛在擴(kuò)散模型的優(yōu)點(diǎn),通過(guò)新穎的時(shí)間推理模塊處理駕駛場(chǎng)景中的挑戰(zhàn)性動(dòng)態(tài)情況。它可以以zero-shot的方式泛化到各種未見(jiàn)的駕駛數(shù)據(jù)集,超越了一般或駕駛特定的視頻預(yù)測(cè)模型。此外,GenAD可以被調(diào)整為一個(gè)動(dòng)作條件的預(yù)測(cè)模型或一個(gè)運(yùn)動(dòng)規(guī)劃器,具有在真實(shí)世界駕駛應(yīng)用中的巨大潛力。

寫(xiě)在前面&筆者的個(gè)人理解
自動(dòng)駕駛agents作為高級(jí)人工智能的一個(gè)有前景的應(yīng)用,感知周?chē)h(huán)境,構(gòu)建內(nèi)部世界模型表示,做出決策,并作出響應(yīng)行動(dòng)。然而,盡管學(xué)術(shù)界和工業(yè)界已經(jīng)進(jìn)行了數(shù)十年的努力,但它們的部署仍然受到限制,僅限于某些區(qū)域或場(chǎng)景,并且不能無(wú)縫地應(yīng)用于整個(gè)世界。其中一個(gè)關(guān)鍵原因是學(xué)習(xí)模型在結(jié)構(gòu)化自動(dòng)駕駛系統(tǒng)中的有限泛化能力。通常,感知模型面臨著在地理位置、傳感器配置、天氣條件、開(kāi)放目標(biāo)等多樣化環(huán)境中泛化的挑戰(zhàn);而預(yù)測(cè)和規(guī)劃模型則面臨著無(wú)法泛化到具有不確定未來(lái)的情景和不同駕駛意圖的挑戰(zhàn)。受人類(lèi)學(xué)習(xí)感知和認(rèn)知世界的啟發(fā),本文主張將駕駛視頻作為通用接口,用于泛化到不同的環(huán)境和動(dòng)態(tài)未來(lái)。
基于這一觀(guān)點(diǎn),預(yù)測(cè)駕駛視頻模型被認(rèn)為是完全捕捉駕駛場(chǎng)景世界知識(shí)的理想選擇(如上面圖1所示)。通過(guò)預(yù)測(cè)未來(lái),視頻預(yù)測(cè)器基本上學(xué)習(xí)了自動(dòng)駕駛的兩個(gè)關(guān)鍵方面:世界如何運(yùn)行,以及如何在復(fù)雜環(huán)境中安全操控。
近年來(lái),社區(qū)已經(jīng)開(kāi)始采用視頻作為表示觀(guān)察行為和動(dòng)作的接口,用于各種機(jī)器人任務(wù)。對(duì)于諸如經(jīng)典視頻預(yù)測(cè)和機(jī)器人技術(shù)的領(lǐng)域,視頻背景主要是靜態(tài)的,機(jī)器人的移動(dòng)速度較慢,視頻的分辨率較低。相比之下,對(duì)于駕駛場(chǎng)景,它需要應(yīng)對(duì)室外環(huán)境高度動(dòng)態(tài)化、agents具有更大運(yùn)動(dòng)范圍以及傳感器分辨率覆蓋大范圍視野的挑戰(zhàn)。這些差異導(dǎo)致了自動(dòng)駕駛應(yīng)用面臨著重大挑戰(zhàn)。
幸運(yùn)的是,在駕駛領(lǐng)域已經(jīng)有一些初步嘗試開(kāi)發(fā)視頻預(yù)測(cè)模型。盡管在預(yù)測(cè)質(zhì)量方面取得了令人鼓舞的進(jìn)展,但這些嘗試并沒(méi)有像經(jīng)典機(jī)器人任務(wù)(例如控制)中那樣實(shí)現(xiàn)理想的泛化能力,而是局限于限定的情景,例如交通密度低的高速公路,以及小規(guī)模的數(shù)據(jù)集,或者受限的條件,難以生成多樣化的環(huán)境。如何發(fā)掘視頻預(yù)測(cè)模型在駕駛領(lǐng)域的潛力仍然鮮有探索。
受以上討論的啟發(fā),我們的目標(biāo)是構(gòu)建一個(gè)用于自動(dòng)駕駛的視頻預(yù)測(cè)模型,能夠泛化到新的條件和環(huán)境。為了實(shí)現(xiàn)這一目標(biāo),需要回答以下問(wèn)題:
(1)如何以可行和可擴(kuò)展的方式獲取數(shù)據(jù)?
(2)我們?nèi)绾螛?gòu)建一個(gè)預(yù)測(cè)模型來(lái)捕捉動(dòng)態(tài)場(chǎng)景的復(fù)雜演變?
(3)如何將(基礎(chǔ))模型應(yīng)用于下游任務(wù)?
規(guī)模化數(shù)據(jù)。 為了獲得強(qiáng)大的泛化能力,需要大量且多樣化的數(shù)據(jù)。受基礎(chǔ)模型從互聯(lián)網(wǎng)規(guī)模數(shù)據(jù)中學(xué)習(xí)成功的啟發(fā),我們從網(wǎng)絡(luò)和公共許可的數(shù)據(jù)集構(gòu)建我們的駕駛數(shù)據(jù)集。與現(xiàn)有的選項(xiàng)相比,由于其受到監(jiān)管的收集流程的限制,現(xiàn)有的選項(xiàng)在規(guī)模和多樣性上受到限制,而在線(xiàn)數(shù)據(jù)在幾個(gè)方面具有很高的多樣性:地理位置、地形、天氣條件、安全關(guān)鍵場(chǎng)景、傳感器設(shè)置、交通元素等。為了確保數(shù)據(jù)具有高質(zhì)量且適合大規(guī)模訓(xùn)練,我們通過(guò)嚴(yán)格的人工驗(yàn)證從YouTube上詳盡地收集駕駛記錄,并刪除意外損壞幀。此外,視頻與各種文本級(jí)別的條件配對(duì),包括利用現(xiàn)有的基礎(chǔ)模型生成和優(yōu)化的描述,以及由視頻分類(lèi)器推斷出的高級(jí)指令。通過(guò)這些步驟,我們構(gòu)建了迄今為止最大的公共駕駛數(shù)據(jù)集OpenDV-2K,其中包含超過(guò)2000小時(shí)的駕駛視頻,比廣泛使用的nuScenes數(shù)據(jù)集大374倍。
通用預(yù)測(cè)模型。 學(xué)習(xí)一個(gè)通用的駕駛視頻預(yù)測(cè)器面臨幾個(gè)關(guān)鍵挑戰(zhàn):生成質(zhì)量、訓(xùn)練效率、因果推理和視角劇烈變化。我們通過(guò)提出一種新穎的兩階段學(xué)習(xí)的時(shí)間生成模型來(lái)解決這些方面的問(wèn)題。為了同時(shí)捕捉環(huán)境細(xì)節(jié)、提高生成質(zhì)量和保持訓(xùn)練效率,我們借鑒了最近潛在擴(kuò)散模型(LDMs)的成功經(jīng)驗(yàn)。在第一階段,我們通過(guò)對(duì)OpenDV-2K圖像進(jìn)行微調(diào),將LDM的生成分布從其預(yù)先訓(xùn)練的通用視覺(jué)領(lǐng)域轉(zhuǎn)移到駕駛領(lǐng)域。在第二階段,我們將所提出的時(shí)間推理模塊插入到原始模型中,并學(xué)習(xí)在給定過(guò)去幀和條件的情況下預(yù)測(cè)未來(lái)。與傳統(tǒng)的時(shí)間模塊不同,我們的解決方案包括因果時(shí)間注意力和分離的空間注意力,以有效地建模高度動(dòng)態(tài)的駕駛場(chǎng)景中的劇烈時(shí)空轉(zhuǎn)移。經(jīng)過(guò)充分訓(xùn)練,我們的自動(dòng)駕駛生成模型(GenAD)能夠以零樣本方式泛化到各種場(chǎng)景。
仿真和規(guī)劃的擴(kuò)展。 在進(jìn)行視頻預(yù)測(cè)的大規(guī)模預(yù)訓(xùn)練之后,GenAD基本上了解了世界的演變方式以及如何駕駛。我們展示了如何將其學(xué)習(xí)到的知識(shí)應(yīng)用于真實(shí)世界的駕駛問(wèn)題,即仿真和規(guī)劃。對(duì)于仿真,我們通過(guò)使用未來(lái)的自車(chē)軌跡作為額外條件,對(duì)預(yù)先訓(xùn)練的模型進(jìn)行微調(diào),將未來(lái)的想象與不同的自車(chē)行為聯(lián)系起來(lái)。我們還賦予了GenAD在具有挑戰(zhàn)性的基準(zhǔn)測(cè)試中執(zhí)行規(guī)劃的能力,通過(guò)使用輕量級(jí)規(guī)劃器將潛在特征轉(zhuǎn)化為自車(chē)未來(lái)軌跡。由于其預(yù)先訓(xùn)練能力能夠準(zhǔn)確預(yù)測(cè)未來(lái)幀,我們的算法在仿真一致性和規(guī)劃可靠性方面展現(xiàn)出了令人期待的結(jié)果。
OpenDV-2K Dataset
OpenDV-2K數(shù)據(jù)集 這是一個(gè)用于自動(dòng)駕駛的大規(guī)模多模態(tài)數(shù)據(jù)集,以支持通用視頻預(yù)測(cè)模型的訓(xùn)練。其主要組成部分是大量高質(zhì)量的YouTube駕駛視頻,這些視頻來(lái)自世界各地,并經(jīng)過(guò)精心篩選后被收入我們的數(shù)據(jù)集中。利用視覺(jué)-語(yǔ)言模型自動(dòng)生成了這些視頻的語(yǔ)言標(biāo)注。為了進(jìn)一步提高數(shù)據(jù)集中的傳感器配置和語(yǔ)言表達(dá)的多樣性,將7個(gè)公開(kāi)授權(quán)的數(shù)據(jù)集合并到我們的OpenDV-2K中,如表1所示。
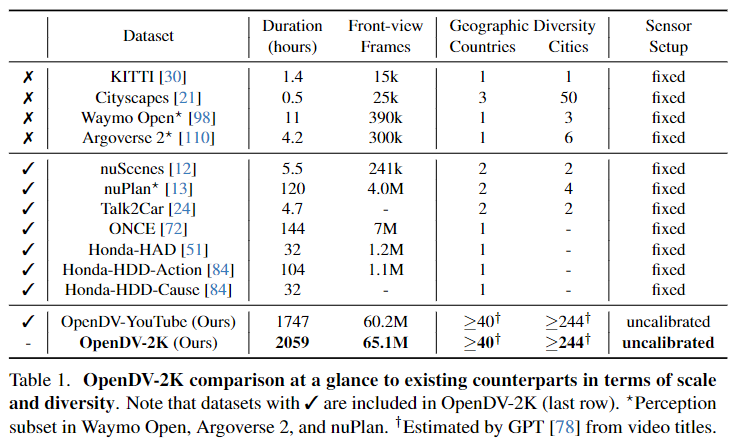
因此,OpenDV-2K總共包含了2059小時(shí)的視頻與文本配對(duì),其中1747小時(shí)來(lái)自YouTube,312小時(shí)來(lái)自公開(kāi)數(shù)據(jù)集。使用OpenDV-YouTube和OpenDV-2K來(lái)指定YouTube拆分和整體數(shù)據(jù)集,分別表示YouTube拆分和整體數(shù)據(jù)集。
與先前數(shù)據(jù)集的多樣性比較
表1提供了與其他公開(kāi)數(shù)據(jù)集的簡(jiǎn)要比較。除了其顯著的規(guī)模外,提出的OpenDV-2K在以下各個(gè)方面都具有多樣性。
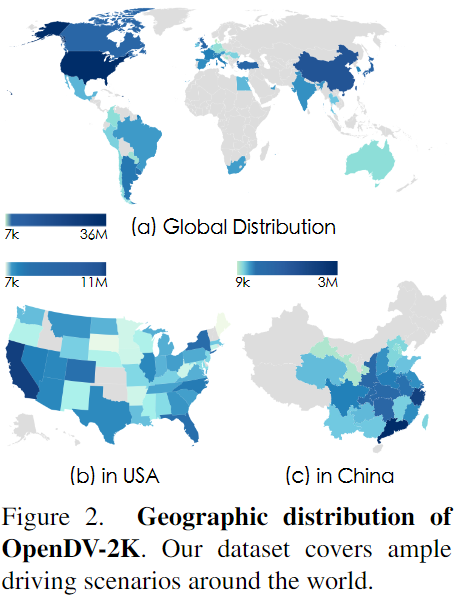
全球地理分布。 由于在線(xiàn)視頻的全球性質(zhì),OpenDV-2K覆蓋了全球40多個(gè)國(guó)家和244個(gè)城市。這相比于先前的公開(kāi)數(shù)據(jù)集是一個(gè)巨大的改進(jìn),先前的數(shù)據(jù)集通常只收集在少數(shù)受限制的地區(qū)。在圖2中繪制了OpenDV-YouTube的具體分布。
開(kāi)放式駕駛場(chǎng)景。 本數(shù)據(jù)集提供了大量的現(xiàn)實(shí)世界中的駕駛經(jīng)驗(yàn),涵蓋了像森林、大雪等極端天氣條件以及對(duì)交互式交通情況做出的適當(dāng)駕駛行為等稀有環(huán)境。這些數(shù)據(jù)對(duì)于多樣性和泛化至關(guān)重要,但是在現(xiàn)有的公開(kāi)數(shù)據(jù)集中很少被收集。
無(wú)限制的傳感器配置。 當(dāng)前的駕駛數(shù)據(jù)集局限于特定的傳感器配置,包括內(nèi)在和外在的相機(jī)參數(shù)、圖像、傳感器類(lèi)型、光學(xué)等,這給使用不同傳感器部署學(xué)習(xí)模型帶來(lái)了巨大挑戰(zhàn)。相比之下,YouTube駕駛視頻是在各種類(lèi)型的車(chē)輛上錄制的,具有靈活的相機(jī)設(shè)置,這有助于在使用新的相機(jī)設(shè)置部署訓(xùn)練模型時(shí)的穩(wěn)健性。
邁向高質(zhì)量多模態(tài)數(shù)據(jù)集
駕駛視頻收集與篩選。 從廣闊的網(wǎng)絡(luò)中找到干凈的駕駛視頻是一項(xiàng)繁瑣且成本高昂的任務(wù)。為了簡(jiǎn)化這個(gè)過(guò)程,首先選擇了某些視頻上傳者,即YouTubers。從平均長(zhǎng)度和整體質(zhì)量來(lái)看,收集了43位YouTuber的2139個(gè)高質(zhì)量前視駕駛視頻。為了確保訓(xùn)練集和驗(yàn)證集之間沒(méi)有重疊,從中選擇了3位YouTuber的所有視頻作為驗(yàn)證集,其余視頻作為訓(xùn)練集。為了排除非駕駛幀,如視頻介紹和訂閱提醒,丟棄了每個(gè)視頻開(kāi)頭和結(jié)尾一定長(zhǎng)度的片段。然后,使用VLM模型BLIP-2 對(duì)每個(gè)幀進(jìn)行語(yǔ)言上下文描述。進(jìn)一步通過(guò)手動(dòng)檢查這些上下文中是否包含特定關(guān)鍵字,來(lái)移除不利于訓(xùn)練的黑色幀和過(guò)渡幀。數(shù)據(jù)集構(gòu)建流程的示意圖見(jiàn)圖3,下面介紹如何生成這些上下文。

YouTube視頻的語(yǔ)言標(biāo)注。 為了創(chuàng)建一個(gè)可以通過(guò)自然語(yǔ)言控制以相應(yīng)地模擬不同未來(lái)的預(yù)測(cè)模型,為了使預(yù)測(cè)模型可控并提高樣本質(zhì)量,將駕駛視頻與有意義且多樣化的語(yǔ)言標(biāo)注配對(duì)至關(guān)重要。為OpenDV-YouTube構(gòu)建了兩種類(lèi)型的文本,即自車(chē)指令和幀描述,即“指令”和“上下文”,以幫助模型理解自車(chē)動(dòng)作和開(kāi)放世界的概念。對(duì)于指令,在Honda-HDD-Action上訓(xùn)練了一個(gè)視頻分類(lèi)器,用于標(biāo)注4秒序列中的自車(chē)行為的14種類(lèi)型的動(dòng)作。這些分類(lèi)指令將進(jìn)一步映射到預(yù)定義字典中的多個(gè)自由形式表達(dá)。對(duì)于上下文,利用一個(gè)成熟的視覺(jué)語(yǔ)言模型BLIP-2,描述每個(gè)幀的主要目標(biāo)和場(chǎng)景。有關(guān)標(biāo)注的更多細(xì)節(jié),請(qǐng)參閱附錄。
用公共數(shù)據(jù)集擴(kuò)大語(yǔ)言范圍。 考慮到BLIP-2標(biāo)注是為靜態(tài)幀生成的,沒(méi)有理解動(dòng)態(tài)駕駛場(chǎng)景,例如交通燈的過(guò)渡,我們利用幾個(gè)提供駕駛場(chǎng)景的語(yǔ)言描述的公共數(shù)據(jù)集。然而,它們的元數(shù)據(jù)相對(duì)稀疏,只有一些諸如“晴天的道路”之類(lèi)的詞語(yǔ)。使用GPT進(jìn)一步提升它們的文本質(zhì)量,形成描述性的“上下文”,并通過(guò)對(duì)每個(gè)視頻剪輯的記錄軌跡進(jìn)行分類(lèi),生成“指令”。最終,我們將這些數(shù)據(jù)集與OpenDV-YouTube集成,建立OpenDV-2K數(shù)據(jù)集,如表1的最后一行所示。
GenAD框架
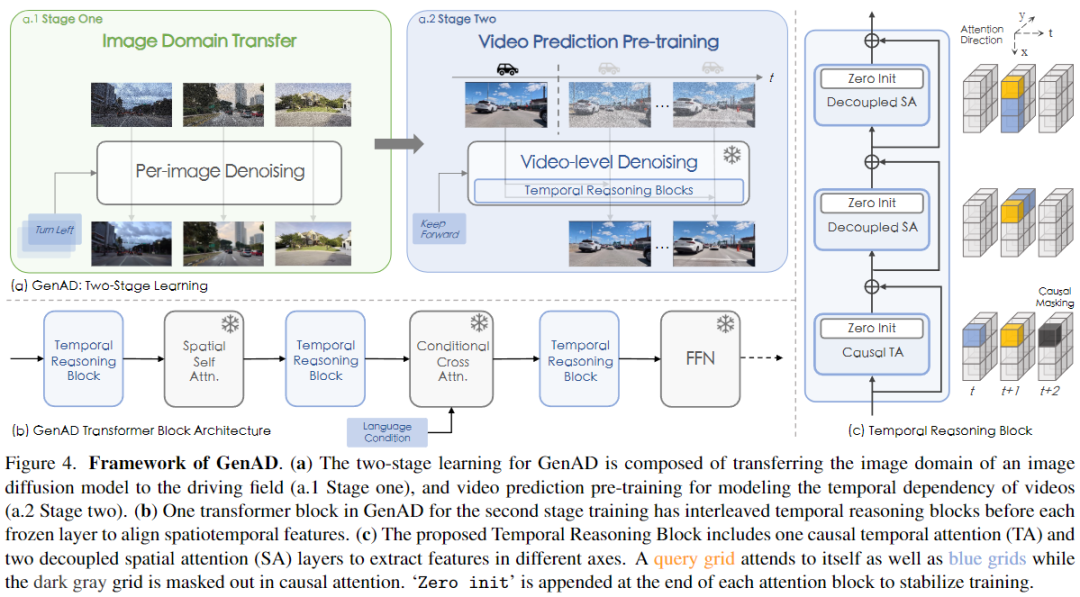
本節(jié)介紹了GenAD模型的訓(xùn)練和設(shè)計(jì)。如圖4所示,GenAD分為兩個(gè)階段進(jìn)行訓(xùn)練,即圖像域轉(zhuǎn)移和視頻預(yù)測(cè)預(yù)訓(xùn)練。第一階段將通用的文本到圖像模型調(diào)整到駕駛領(lǐng)域。第二階段通過(guò)提出的時(shí)間推理塊和修改的訓(xùn)練方案,將文本到圖像模型擴(kuò)展為視頻預(yù)測(cè)模型。最后,探討了如何將預(yù)測(cè)模型擴(kuò)展到動(dòng)作條件預(yù)測(cè)和規(guī)劃。
圖像域遷移
車(chē)載相機(jī)捕捉了豐富的視野,包括道路、背景建筑、周?chē)?chē)輛等豐富的視覺(jué)內(nèi)容,需要強(qiáng)大而魯棒的生成能力來(lái)產(chǎn)生連續(xù)和逼真的駕駛場(chǎng)景。為了促進(jìn)學(xué)習(xí)過(guò)程,首先在第一階段進(jìn)行獨(dú)立的圖像生成。具體地,使用SDXL初始化我們的模型,SDXL是一個(gè)用于文本到圖像生成的大規(guī)模潛在擴(kuò)散模型(LDM),利用其合成高質(zhì)量圖像的能力。它被實(shí)現(xiàn)為一個(gè)具有多個(gè)堆疊的卷積和注意力塊的去噪θ,通過(guò)去噪的方式學(xué)習(xí)合成圖像。具體來(lái)說(shuō),給定由前向擴(kuò)散過(guò)程損壞的噪聲輸入潛在 ,通過(guò)以下目標(biāo)函數(shù)被訓(xùn)練來(lái)預(yù)測(cè) 的添加噪聲ε:
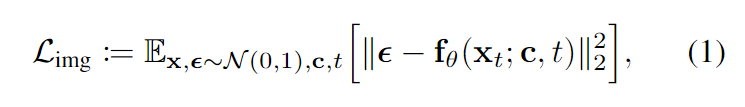
其中 x 和分別是干凈和嘈雜的潛在空間,t 表示不同噪聲尺度的時(shí)間步長(zhǎng),c 是指導(dǎo)去噪過(guò)程的文本條件,它是上下文和指令的串聯(lián)。為了訓(xùn)練效率,學(xué)習(xí)過(guò)程發(fā)生在壓縮的潛在空間中,而不是像素空間。在采樣過(guò)程中,模型通過(guò)迭代地去噪最后一步的預(yù)測(cè),從標(biāo)準(zhǔn)高斯噪聲中生成圖像。然而,原始的SDXL是在通用域的數(shù)據(jù)上進(jìn)行訓(xùn)練的,例如肖像和藝術(shù)畫(huà)作,這些數(shù)據(jù)與自主系統(tǒng)無(wú)關(guān)。為了使模型適應(yīng)于為駕駛場(chǎng)景合成圖像,在OpenDV-2K中使用圖像文本對(duì)進(jìn)行文本到圖像生成的微調(diào),目標(biāo)與方程(1)相同。在SDXL的原始訓(xùn)練之后,所有UNet的參數(shù)θ都在此階段進(jìn)行微調(diào),而CLIP文本編碼器和自編碼器保持凍結(jié)狀態(tài)。
視頻預(yù)測(cè)預(yù)訓(xùn)練
在第二階段,利用連續(xù)視頻的幾幀作為過(guò)去的觀(guān)察,GenAD被訓(xùn)練來(lái)推理所有視覺(jué)觀(guān)察,并以可信的方式預(yù)測(cè)未來(lái)的幾幀。與第一階段類(lèi)似,預(yù)測(cè)過(guò)程也可以由文本條件指導(dǎo)。然而,由于兩個(gè)基本障礙,預(yù)測(cè)高度動(dòng)態(tài)的駕駛世界在時(shí)間上是具有挑戰(zhàn)性的。
- 因果推理: 為了預(yù)測(cè)遵循駕駛世界時(shí)間因果關(guān)系的合理未來(lái),模型需要理解所有其他agents和自車(chē)的意圖,并了解潛在的交通規(guī)則,例如,交通信號(hào)燈轉(zhuǎn)換時(shí)交通將如何變化。
- 視圖變化劇烈: 與Typical視頻生成基準(zhǔn)相反,后者主要具有靜態(tài)背景,中心目標(biāo)的移動(dòng)速度較慢,駕駛的視圖隨時(shí)間變化劇烈。每個(gè)幀中的每個(gè)像素可能會(huì)在下一個(gè)幀中移動(dòng)到一個(gè)遙遠(yuǎn)的位置。
本文提出了時(shí)間推理block來(lái)解決這些問(wèn)題。如圖4(c)所示,每個(gè)block由三個(gè)連續(xù)的注意力層組成,即因果時(shí)間注意力層和兩個(gè)解耦的空間注意力層,分別用于因果推理和模擬駕駛場(chǎng)景中的大的移位。
因果時(shí)間注意力。 由于第一階段訓(xùn)練后的模型只能獨(dú)立處理每個(gè)幀,本文利用時(shí)間注意力在不同的視頻幀之間交換信息。注意力發(fā)生在時(shí)間軸上,并模擬每個(gè)網(wǎng)格特征的時(shí)間依賴(lài)性。然而,直接采用雙向時(shí)間注意力在這里幾乎無(wú)法獲得因果推理的能力,因?yàn)轭A(yù)測(cè)將不可避免地依賴(lài)于隨后的幀而不是過(guò)去的條件。因此,通過(guò)添加因果注意mask,限制注意力方向,鼓勵(lì)模型充分利用過(guò)去的觀(guān)察知識(shí),并如實(shí)推理未來(lái),就像在真實(shí)的駕駛中一樣。在經(jīng)驗(yàn)上發(fā)現(xiàn),因果約束極大地使預(yù)測(cè)的幀與過(guò)去的幀保持一致。遵循通用做法,還在時(shí)間軸上添加了實(shí)現(xiàn)為相對(duì)位置嵌入的時(shí)間偏差,以區(qū)分序列的不同幀,用于時(shí)間注意力。
解耦的空間注意力。 由于駕駛視頻具有快速的視角變化,在不同的時(shí)間步長(zhǎng)中,特定網(wǎng)格中的特征可能會(huì)有很大的變化,并且很難通過(guò)時(shí)間注意力進(jìn)行相關(guān)性和學(xué)習(xí),因?yàn)闀r(shí)間注意力具有有限的感受野。考慮到這一點(diǎn),引入了空間注意力來(lái)在空間軸中傳播每個(gè)網(wǎng)格特征,以幫助收集用于時(shí)間注意力的信息。采用了一種解耦的自注意力變體,由于其具有線(xiàn)性計(jì)算復(fù)雜度,相對(duì)于二次完全自注意力,它更加高效。如圖4(c)所示,這兩個(gè)解耦注意層分別在水平和垂直軸上傳播特征。
深度交互。 直覺(jué)上,第一階段中調(diào)整的空間block獨(dú)立地使每個(gè)幀的特征朝向照片逼真性,而第二階段引入的時(shí)間block使所有視頻幀的特征朝向一致性和一致性對(duì)齊。為了進(jìn)一步增強(qiáng)時(shí)空特征交互,本文將提出的時(shí)間推理block與SDXL中的原始Transformer block交叉,即空間注意力,交叉注意力和前饋網(wǎng)絡(luò),如圖4(b)所示。
零初始化。 與先前的做法類(lèi)似,對(duì)于在第二階段新引入的每個(gè)block,將其最終層的所有參數(shù)初始化為零。這樣可以避免在開(kāi)始時(shí)破壞經(jīng)過(guò)良好訓(xùn)練的圖像生成模型的先驗(yàn)知識(shí),并穩(wěn)定訓(xùn)練過(guò)程。
訓(xùn)練。 GenAD通過(guò)在噪聲潛變量的共同去噪過(guò)程中利用過(guò)去幀和文本條件的指導(dǎo)來(lái)預(yù)測(cè)未來(lái)。首先將視頻剪輯的T個(gè)連續(xù)幀投影到一批潛變量中,其中前m幀潛變量是干凈的,代表歷史觀(guān)察,而其他n=T?m幀潛變量表示要預(yù)測(cè)的未來(lái)。然后,被轉(zhuǎn)換為通過(guò)前向擴(kuò)散過(guò)程產(chǎn)生的,其中t索引隨機(jī)抽取的噪聲尺度。模型被訓(xùn)練以預(yù)測(cè)受觀(guān)察和文本c條件下的噪聲。視頻預(yù)測(cè)模型的學(xué)習(xí)目標(biāo)如下所示:
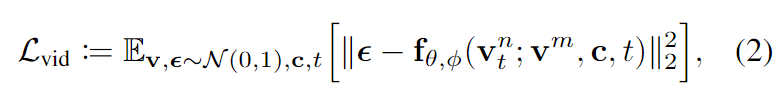
其中,θ表示繼承自第一階段模型的參數(shù),φ表示新插入的時(shí)間推理塊。遵循[8]凍結(jié)θ,并僅訓(xùn)練時(shí)間推理塊,以避免干擾圖像生成模型的生成能力,并集中學(xué)習(xí)視頻中的時(shí)間依賴(lài)性。請(qǐng)注意,只有來(lái)自受損幀的輸出會(huì)對(duì)訓(xùn)練損失做出貢獻(xiàn),而來(lái)自條件幀的輸出會(huì)被忽略。訓(xùn)練方法也可以很容易地應(yīng)用于視頻插值,只需進(jìn)行輕微的修改,即交換條件幀的索引。
擴(kuò)展。 依靠在駕駛場(chǎng)景中訓(xùn)練良好的視頻預(yù)測(cè)能力,進(jìn)一步挖掘了預(yù)訓(xùn)練模型在動(dòng)作控制預(yù)測(cè)和規(guī)劃方面的潛力,這對(duì)于真實(shí)世界的駕駛系統(tǒng)非常重要。在這里,探索了nuScenes上的下游任務(wù),該任務(wù)提供了記錄的姿態(tài)。
動(dòng)作條件預(yù)測(cè)。 為了使我們的預(yù)測(cè)模型能夠受到精確的自我行為控制并充當(dāng)模擬器,使用成對(duì)的未來(lái)軌跡作為額外條件對(duì)模型進(jìn)行微調(diào)。具體來(lái)說(shuō),使用Fourier embedding將原始軌跡映射到高維特征。經(jīng)過(guò)線(xiàn)性層的進(jìn)一步投影后,將其添加到原始條件中。因此,自我行為通過(guò)圖4(b)中的條件交叉注意力層注入到網(wǎng)絡(luò)中。
規(guī)劃。 通過(guò)學(xué)習(xí)預(yù)測(cè)未來(lái),GenAD獲得了復(fù)雜駕駛場(chǎng)景的強(qiáng)大表示,這可以進(jìn)一步用于規(guī)劃。具體來(lái)說(shuō),通過(guò)凍結(jié)的GenAD的UNet編碼器提取兩個(gè)歷史幀的時(shí)空特征,該編碼器幾乎是整個(gè)模型大小的一半,并將它們饋送到多層感知器(MLP)以預(yù)測(cè)未來(lái)的路標(biāo)。通過(guò)凍結(jié)的GenAD編碼器和可學(xué)習(xí)的MLP層,規(guī)劃器的訓(xùn)練過(guò)程可以比端到端規(guī)劃模型UniAD 加快3400倍,驗(yàn)證了GenAD學(xué)習(xí)的時(shí)空特征的有效性。
實(shí)驗(yàn)
設(shè)置與實(shí)驗(yàn)方案
GenAD在OpenDV-2K上分兩個(gè)階段學(xué)習(xí),但具有不同的學(xué)習(xí)目標(biāo)和輸入格式。在第一階段,模型接受(圖像,文本)對(duì)作為輸入,并在文本到圖像生成上進(jìn)行訓(xùn)練。將命令標(biāo)注廣播到包含的所有幀中,每4秒視頻序列標(biāo)注一個(gè)。該模型在32個(gè)NVIDIA Tesla A100 GPU上進(jìn)行了300K次迭代訓(xùn)練,總批量大小為256。在第二階段,GenAD被訓(xùn)練以在過(guò)去的潛變量和文本的條件下聯(lián)合去噪未來(lái)的潛變量。其輸入為(視頻剪輯,文本)對(duì),其中每個(gè)視頻剪輯為2Hz的4秒。當(dāng)前版本的GenAD在64個(gè)GPU上進(jìn)行了112.5K次迭代訓(xùn)練,總batch大小為64。輸入幀在兩個(gè)階段的訓(xùn)練中被調(diào)整為256×448的大小,并且以概率p = 0.1丟棄文本條件c,以啟用無(wú)分類(lèi)器的引導(dǎo)在采樣中,這在擴(kuò)散模型中通常用于改善樣本質(zhì)量。
視頻預(yù)訓(xùn)練結(jié)果
與最近的視頻生成方法的比較
將GenAD與最近的先進(jìn)方法進(jìn)行比較,使用OpenDV-YouTube、Waymo 、KITTI和Cityscapes上的未見(jiàn)過(guò)的地理圍欄集合進(jìn)行zero-shot生成方式。圖5顯示了定性結(jié)果。圖像到視頻模型I2VGen-XL和VideoCrafter1不能?chē)?yán)格按照給定的幀進(jìn)行預(yù)測(cè),導(dǎo)致預(yù)測(cè)幀與過(guò)去幀之間的一致性較差。在Cityscapes上訓(xùn)練的視頻預(yù)測(cè)模型DMVFN在其預(yù)測(cè)中遭遇了不利的形狀扭曲,尤其是在三個(gè)未見(jiàn)過(guò)的數(shù)據(jù)集上。相比之下,盡管這些集合都沒(méi)有包含在訓(xùn)練中,但GenAD表現(xiàn)出了顯著的zero-shot泛化能力和視覺(jué)質(zhì)量。

與nuScenes專(zhuān)家的比較
還將GenAD與最近可用的專(zhuān)門(mén)針對(duì)nuScenes訓(xùn)練的駕駛視頻生成模型進(jìn)行比較。表2顯示,GenAD在圖像保真度(FID)和視頻連貫性(FVD)方面超過(guò)了所有先前的方法。
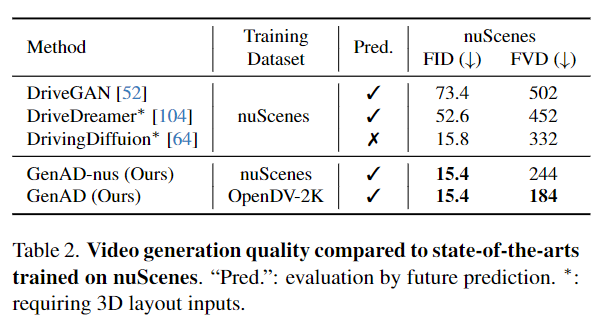
具體來(lái)說(shuō),與DrivingDiffusion相比,GenAD將FVD顯著降低了44.5%,而沒(méi)有將3D未來(lái)布局作為額外輸入。為了公平比較,訓(xùn)練了一個(gè)模型變體(GenAD-nus)只在nuScenes數(shù)據(jù)集上進(jìn)行訓(xùn)練。我們發(fā)現(xiàn),盡管GenAD-nus在nuScenes上表現(xiàn)與GenAD相當(dāng),但它很難推廣到未見(jiàn)過(guò)的數(shù)據(jù)集,例如Waymo,其中生成物會(huì)退化到nuScenes的視覺(jué)模式。相比之下,訓(xùn)練在OpenDV-2K上的GenAD在各個(gè)數(shù)據(jù)集上都表現(xiàn)出很強(qiáng)的泛化能力,如前圖5所示。
在nuScenes上提供了語(yǔ)言條件預(yù)測(cè)樣本,如圖6所示,GenAD根據(jù)不同的文本指令模擬了相同起始點(diǎn)的各種未來(lái)。復(fù)雜的環(huán)境細(xì)節(jié)和自運(yùn)動(dòng)的自然過(guò)渡展示了令人印象深刻的生成質(zhì)量。

消融研究
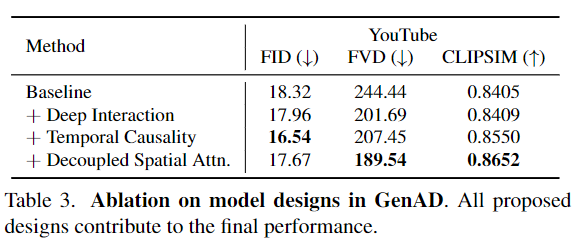
通過(guò)在OpenDV-2K的子集上進(jìn)行75K步的訓(xùn)練,執(zhí)行消融實(shí)驗(yàn)。從具有普通時(shí)間注意力的基線(xiàn)開(kāi)始,逐漸引入我們提出的組件。值得注意的是,通過(guò)將時(shí)間塊與空間塊交錯(cuò),F(xiàn)VD顯著提高了(-17%),這是由于更充分的時(shí)空交互。時(shí)間因果關(guān)系和解耦的空間注意力都有助于更好的CLIP-SIM,改善了未來(lái)預(yù)測(cè)與條件幀之間的時(shí)間一致性。需要明確的是,表3中第四行和第三行顯示的FID和FVD的輕微增加,并不真實(shí)反映了生成質(zhì)量的下降,如[8, 10, 79]中所討論的。每種設(shè)計(jì)的有效性如圖7所示。

擴(kuò)展結(jié)果
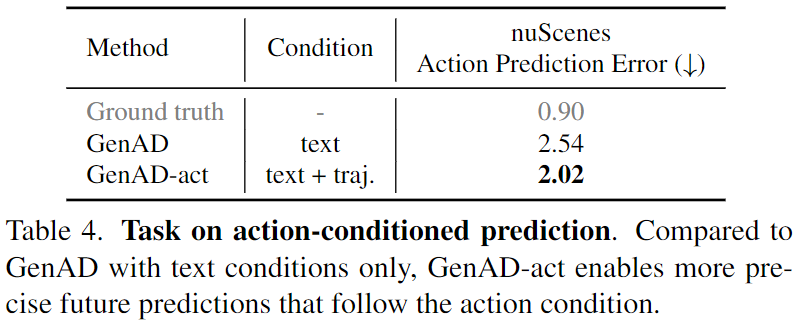
動(dòng)作條件預(yù)測(cè)。 進(jìn)一步展示了在nuScenes上微調(diào)的動(dòng)作條件模型GenAD-act的性能,如圖8和表4所示。給定兩個(gè)起始幀和一個(gè)包含6個(gè)未來(lái)路徑點(diǎn)的軌跡w,GenAD-act模擬了6個(gè)按照軌跡順序的未來(lái)幀。為了評(píng)估輸入軌跡w和預(yù)測(cè)幀之間的一致性,在nuScenes上建立了一個(gè)反向動(dòng)力學(xué)模型(IDM)作為評(píng)估器,該模型將視頻序列映射到相應(yīng)的自車(chē)軌跡上。我們利用IDM將預(yù)測(cè)幀轉(zhuǎn)換為軌跡?w,并計(jì)算w和?w之間的L2距離作為動(dòng)作預(yù)測(cè)誤差。具體來(lái)說(shuō),與具有文本條件的GenAD相比,GenAD-act將動(dòng)作預(yù)測(cè)誤差顯著降低了20.4%,從而實(shí)現(xiàn)更準(zhǔn)確的未來(lái)模擬。

規(guī)劃結(jié)果。 表5描述了在nuScenes上的規(guī)劃結(jié)果,其中可以獲得自車(chē)的姿態(tài)真值。通過(guò)凍結(jié)GenAD編碼器,并僅優(yōu)化其頂部的附加MLP,模型可以有效地學(xué)習(xí)規(guī)劃。值得注意的是,通過(guò)通過(guò)GenAD的UNet編碼器預(yù)提取圖像特征,規(guī)劃適應(yīng)的整個(gè)學(xué)習(xí)過(guò)程僅需在單個(gè)NVIDIA Tesla V100設(shè)備上花費(fèi)10分鐘,比UniAD規(guī)劃器的訓(xùn)練高效3400倍。
結(jié)論
對(duì)GenAD進(jìn)行了系統(tǒng)級(jí)開(kāi)發(fā)研究,這是一個(gè)用于自動(dòng)駕駛的大規(guī)模通用視頻預(yù)測(cè)模型。還驗(yàn)證了GenAD學(xué)習(xí)表示適應(yīng)駕駛?cè)蝿?wù)的能力,即學(xué)習(xí)“世界模型”和運(yùn)動(dòng)規(guī)劃。盡管在開(kāi)放領(lǐng)域獲得了改進(jìn)的泛化能力,但增加的模型容量在訓(xùn)練效率和實(shí)時(shí)部署方面帶來(lái)了挑戰(zhàn)。設(shè)想統(tǒng)一的視頻預(yù)測(cè)任務(wù)將成為未來(lái)關(guān)于表示學(xué)習(xí)和策略學(xué)習(xí)的研究的可擴(kuò)展目標(biāo)。另一個(gè)有趣的方向是將編碼的知識(shí)提煉出來(lái),用于更廣泛的下游任務(wù)。
























