五分鐘上手Python爬蟲:從干飯開始,輕松掌握技巧
在這個過程中,技術(shù)方面實際上沒有太多復雜的內(nèi)容,實際上就是一項耐心細致的工作。因此才會有那么多人選擇從事爬蟲兼職工作,因為雖然耗時較長,但技術(shù)要求并不是很高。今天學完之后,你就不會像我一樣認為爬蟲很困難了。或許在未來你會需要考慮如何保持會話(session)或者繞過驗證等問題,因為網(wǎng)站越難爬取,說明對方并不希望被爬取。實際上,這部分內(nèi)容是最具挑戰(zhàn)性的,有機會的話我們可以在以后的學習中深入討論。
今天我們以選擇菜譜為案例,來解決我們在吃飯時所面臨的“吃什么”的生活難題。
爬蟲解析
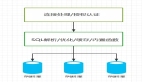
爬蟲的工作原理類似于模擬用戶在瀏覽網(wǎng)站時的操作:首先訪問官方網(wǎng)站,檢查是否有需要點擊的鏈接,若有,則繼續(xù)點擊查看。當直接發(fā)現(xiàn)所需的圖片或文字時,即可進行下載或復制。這種爬蟲的基本架構(gòu)如圖所示,希望這樣的描述能幫助你更好地理解。
 image
image
爬網(wǎng)頁HTML
在進行爬蟲工作時,我們通常從第一步開始,即發(fā)送一個HTTP請求以獲取返回的數(shù)據(jù)。在我們的工作中,通常會請求一個鏈接以獲取JSON格式的信息,以便進行業(yè)務(wù)處理。然而,爬蟲的工作方式略有不同,因為我們需要首先獲取網(wǎng)頁內(nèi)容,因此這一步通常返回的是HTML頁面。在Python中,有許多請求庫可供選擇,我只舉一個例子作為參考,但你可以根據(jù)實際需求選擇其他第三方庫,只要能夠完成任務(wù)即可。
在開始爬蟲工作之前,首先需要安裝所需的第三方庫依賴。這部分很簡單,只需根據(jù)需要安裝相應(yīng)的庫即可,沒有太多復雜的步驟。
讓我們不多廢話,直接看下面的代碼示例:
from urllib.request import urlopen,Request
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'}
req = Request("https://www.meishij.net/?from=space_block",headers=headers)
# 發(fā)出請求,獲取html
# 獲取的html內(nèi)容是字節(jié),將其轉(zhuǎn)化為字符串
html = urlopen(req)
html_text = bytes.decode(html.read())
print(html_text)通常情況下,我們可以獲取這個菜譜網(wǎng)頁的完整內(nèi)容,就像我們在瀏覽器中按下F12查看的網(wǎng)頁源代碼一樣。
解析元素
最笨的方法是使用字符串解析,但由于Python有許多第三方庫可以解決這個問題,因此我們可以使用BeautifulSoup來解析HTML。其他更多的解析方法就不一一介紹了,我們需要用到什么就去搜索即可,不需要經(jīng)常使用的也沒必要死記硬背。
熱搜菜譜
在這里,讓我們對熱門搜索中的菜譜進行解析和分析。
from urllib.request import urlopen,Request
from bs4 import BeautifulSoup as bf
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'}
req = Request("https://www.meishij.net/?from=space_block",headers=headers)
# 發(fā)出請求,獲取html
# 獲取的html內(nèi)容是字節(jié),將其轉(zhuǎn)化為字符串
html = urlopen(req)
html_text = bytes.decode(html.read())
# print(html_text)
# 用BeautifulSoup解析html
obj = bf(html_text,'html.parser')
# print(html_text)
# 使用find_all函數(shù)獲取所有圖片的信息
index_hotlist = obj.find_all('a',class_='sancan_item')
# 分別打印每個圖片的信息
for ul in index_hotlist:
for li in ul.find_all('strong',class_='title'):
print(li.get_text())主要步驟是,首先在上一步中打印出HTML頁面,然后通過肉眼觀察確定所需內(nèi)容位于哪個元素下,接著利用BeautifulSoup定位該元素并提取出所需信息。在我的情況下,我提取的是文字內(nèi)容,因此成功提取了所有l(wèi)i列表元素。
隨機干飯
在生活中,實際上干飯并不復雜,難點在于選擇吃什么。因此,我們可以將所有菜譜解析并存儲在一個列表中,然后讓程序隨機選擇菜譜。這樣,就能更輕松地解決每頓飯吃什么的難題了。
隨機選取一道菜時,可以使用以下示例代碼:
from urllib.request import urlopen,Request
from bs4 import BeautifulSoup as bf
for i in range(3):
url = f"https://www.meishij.net/chufang/diy/jiangchangcaipu/?&page={i}"
html = urlopen(url)
# 獲取的html內(nèi)容是字節(jié),將其轉(zhuǎn)化為字符串
html_text = bytes.decode(html.read())
# print(html_text)
obj = bf(html_text,'html.parser')
index_hotlist = obj.find_all('img')
for p in index_hotlist:
if p.get('alt'):
print(p.get('alt'))這里我們在這個網(wǎng)站上找到了新的鏈接地址,我已經(jīng)獲取了前三頁的數(shù)據(jù),并進行了隨機選擇,你可以選擇全部獲取。
菜譜教程
其實上一步已經(jīng)完成了,接下來只需下單外賣了。外賣種類繁多,但對于像我這樣的顧家奶爸來說并不合適,因此我必須自己動手做飯。這時候教程就顯得尤為重要了。
我們現(xiàn)在繼續(xù)深入解析教程內(nèi)容:
from urllib.request import urlopen,Request
import urllib,string
from bs4 import BeautifulSoup as bf
url = f"https://so.meishij.net/index.php?q=紅燒排骨"
url = urllib.parse.quote(url, safe=string.printable)
html = urlopen(url)
# 獲取的html內(nèi)容是字節(jié),將其轉(zhuǎn)化為字符串
html_text = bytes.decode(html.read())
obj = bf(html_text,'html.parser')
index_hotlist = obj.find_all('a',class_='img')
# 分別打印每個圖片的信息
url = index_hotlist[0].get('href')
html = urlopen(url)
html_text = bytes.decode(html.read())
obj = bf(html_text,'html.parser')
index_hotlist = obj.find_all('div',class_='step_content')
for div in index_hotlist:
for p in div.find_all('p'):
print(p.get_text())包裝一下
上面提到的方法已經(jīng)滿足了我們的需求,但是重復手動執(zhí)行每個步驟并不是一個高效的方式。因此,我將這些步驟封裝成一個簡單的應(yīng)用程序。這個應(yīng)用程序使用控制臺作為用戶界面,不需要依賴任何第三方庫。讓我們一起來看一下這個應(yīng)用程序吧:
# 導入urllib庫的urlopen函數(shù)
from urllib.request import urlopen,Request
import urllib,string
# 導入BeautifulSoup
from bs4 import BeautifulSoup as bf
from random import choice,sample
from colorama import init
from os import system
from termcolor import colored
from readchar import readkey
FGS = ['green', 'yellow', 'blue', 'cyan', 'magenta', 'red']
print(colored('搜索食譜中.....',choice(FGS)))
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'}
req = Request("https://www.meishij.net/?from=space_block",headers=headers)
# 發(fā)出請求,獲取html
# 獲取的html內(nèi)容是字節(jié),將其轉(zhuǎn)化為字符串
html = urlopen(req)
html_text = bytes.decode(html.read())
hot_list = []
all_food = []
food_page = 3
# '\n'.join(pos(y, OFFSET[1]) + ' '.join(color(i) for i in l)
def draw_menu(menu_list):
clear()
for idx,i in enumerate(menu_list):
print(colored(f'{idx}:{i}',choice(FGS)))
print(colored('8:隨機選擇',choice(FGS)))
def draw_word(word_list):
clear()
for i in word_list:
print(colored(i,choice(FGS)))
def clear():
system("CLS")
def hot_list_func() :
global html_text
# 用BeautifulSoup解析html
obj = bf(html_text,'html.parser')
# print(html_text)
# 使用find_all函數(shù)獲取所有圖片的信息
index_hotlist = obj.find_all('a',class_='sancan_item')
# 分別打印每個圖片的信息
for ul in index_hotlist:
for li in ul.find_all('strong',class_='title'):
hot_list.append(li.get_text())
# print(li.get_text())
def search_food_detail(food) :
print('正在搜索詳細教程,請稍等30秒左右!')
url = f"https://so.meishij.net/index.php?q={food}"
# print(url)
url = urllib.parse.quote(url, safe=string.printable)
html = urlopen(url)
# 獲取的html內(nèi)容是字節(jié),將其轉(zhuǎn)化為字符串
html_text = bytes.decode(html.read())
obj = bf(html_text,'html.parser')
index_hotlist = obj.find_all('a',class_='img')
# 分別打印每個圖片的信息
url = index_hotlist[0].get('href')
# print(url)
html = urlopen(url)
html_text = bytes.decode(html.read())
# print(html_text)
obj = bf(html_text,'html.parser')
random_color = choice(FGS)
print(colored(f"{food}做法:",random_color))
index_hotlist = obj.find_all('div',class_='step_content')
# print(index_hotlist)
random_color = choice(FGS)
for div in index_hotlist:
for p in div.find_all('p'):
print(colored(p.get_text(),random_color))
def get_random_food():
global food_page
if not all_food :
for i in range(food_page):
url = f"https://www.meishij.net/chufang/diy/jiangchangcaipu/?&page={i}"
html = urlopen(url)
# 獲取的html內(nèi)容是字節(jié),將其轉(zhuǎn)化為字符串
html_text = bytes.decode(html.read())
# print(html_text)
obj = bf(html_text,'html.parser')
index_hotlist = obj.find_all('img')
for p in index_hotlist:
if p.get('alt'):
all_food.append(p.get('alt'))
my_food = choice(all_food)
print(colored(f'隨機選擇,今天吃:{my_food}',choice(FGS)))
return my_food
init() ## 命令行輸出彩色文字
hot_list_func()
print(colored('已搜索完畢!',choice(FGS)))
my_array = list(range(0, 9))
my_key = ['q','c','d','m']
my_key.extend(my_array)
print(colored('m:代表今日菜譜',choice(FGS)))
print(colored('c:代表清空控制臺',choice(FGS)))
print(colored('d:代表菜譜教程',choice(FGS)))
print(colored('q:退出菜譜',choice(FGS)))
print(colored('0~8:選擇菜譜中的菜',choice(FGS)))
while True:
while True:
move = readkey()
if move in my_key or (move.isdigit() and int(move) <= len(random_food)):
break
if move == 'q': ## 鍵盤‘Q’是退出
break
if move == 'c': ## 鍵盤‘C’是清空控制臺
clear()
if move == 'm':
random_food = sample(hot_list,8)
draw_menu(random_food)
if move.isdigit() and int(move) <= len(random_food):
if int(move) == 8:
my_food = get_random_food()
else:
my_food = random_food[int(move)]
print(my_food)
if move == 'd' and my_food : ## 鍵盤‘D’是查看教程
search_food_detail(my_food)
my_food = ''完成一個簡單的小爬蟲其實并不復雜,如果不考慮額外的封裝步驟,僅需5分鐘即可完成,這已經(jīng)足夠快速讓你入門爬蟲技術(shù)。開始爬取某個網(wǎng)站的數(shù)據(jù)實際上是一項細致的工作。只需在網(wǎng)上搜索相關(guān)技術(shù)信息,找到適合的方法即可,如果有效就繼續(xù)使用,不行就試試其他方法。
總結(jié)
本文的重點在于引導讀者如何初步掌握爬蟲技術(shù)。初步掌握爬蟲技術(shù)并不難,但是在實際操作中可能會遇到一些困難,比如一些網(wǎng)站不允許直接訪問,需要登錄或者進行各種人機驗證等。因此,最好先從爬取一些新聞資訊類的網(wǎng)站開始,因為這樣相對容易。涉及用戶支付等敏感信息的網(wǎng)站就不那么容易獲取了。因此,在入門階段,建議不要糾結(jié)于選擇一個復雜的網(wǎng)站,先嘗試入門即可。一旦理解了基本原理,遇到問題時就可以考慮添加組件或者使用第三方庫來解決。