自己動手實現一個RAG應用
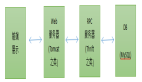
我們知道 RAG 有兩個核心的過程,一個是把信息存放起來的索引過程,一個是利用找到相關信息生成內容的檢索生成過程。所以,我們這個 RAG 應用也要分成兩個部分:索引和檢索生成。
RAG 是為了讓大模型知道更多的東西,所以,接下來要實現的 RAG 應用,用來增強的信息就是我們這門課程的內容,我會把開篇詞做成一個文件,這樣,我們就可以和大模型討論我們的課程了。LangChain 已經提供了一些基礎設施,我們可以利用這些基礎設施構建我們的應用。
我們先從索引的過程開始!
 圖片
圖片
下面是實現這個索引過程的代碼:
from langchain_community.document_loaders import TextLoader
loader = TextLoader("introduction.txt")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma(
collection_name="ai_learning",
embedding_functinotallow=OpenAIEmbeddings(),
persist_directory="vectordb"
)
vectorstore.add_documents(splits)出于簡化的目的,我這里直接從文本內容中加載信息源,而且選擇了 Chroma 作為向量數據庫,它對開發很友好,可以把向量數據存儲在本地的指定目錄下。
我們結合代碼來看一下。首先是 TextLoader,它負責加載文本信息。
loader = TextLoader("introduction.txt")
docs = loader.load()這里的 TextLoader 屬于 DocumentLoader。在 LangChain 中,有一個很重要的概念叫文檔(Document),它包括文檔的內容(page_content)以及相關的元數據(metadata)。所有原始信息都是文檔,索引信息的第一步就是把這些文檔加載進來,這就是 DocumentLoader 的作用。
除了這里用到的 TextLoader,LangChain 社區里已經實現了大量的 DocumentLoader,比如,從數據庫里加載數據的 SQLDatabaseLoader,從亞馬遜 S3 加載文件的 S3FileLoader。基本上,大部分我們需要的文檔加載器都可以找到直接的實現。
拆分加載進來的文檔是 TextSplitter 的主要職責。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)雖然都是文本,但怎樣拆分還是有講究的,拆分源代碼和拆分普通文本,處理方法就是不一樣的。LangChain 社區里同樣實現了大量的 TextSplitter,我們可以根據自己的業務特點進行選擇。我們這里使用了 RecursiveCharacterTextSplitter,它會根據常見的分隔符(比如換行符)遞歸地分割文檔,直到把每個塊拆分成適當的大小。
做好基礎的準備之后,就要把拆分的文檔存放到向量數據庫里了:
vectorstore = Chroma(
collection_name="ai_learning",
embedding_functinotallow=OpenAIEmbeddings(),
persist_directory="vectordb"
)
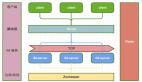
vectorstore.add_documents(splits)LangChain 支持了很多的向量數據庫,它們都有一個統一的接口:VectorStore,在這個接口中包含了向量數據庫的統一操作,比如添加、查詢之類的。這個接口屏蔽了向量數據庫的差異,在向量數據庫并不為所有程序員熟知的情況下,給嘗試不同的向量數據庫留下了空間。各個具體實現負責實現這些接口,我們這里采用的實現是 Chroma。
在 Chroma 初始化的過程中,我們指定了 Embedding 函數,它負責把文本變成向量。這里我們采用了 OpenAI 的 Embeddings 實現,你完全可以根據自己的需要選擇相應的實現,LangChain 社區同樣提供了大量的實現,比如,你可以指定 Hugging Face 這個模型社區中的特定模型來做 Embedding。
到這里,我們就完成了索引的過程,看上去還是比較簡單的。為了驗證我們索引的結果,我們可以調用 similarity_search 檢索向量數據庫的數據:
vectorstore = Chroma(
collection_name="ai_learning",
embedding_functinotallow=OpenAIEmbeddings(),
persist_directory="vectordb"
)
documents = vectorstore.similarity_search("專欄的作者是誰?")
print(documents)我們這里用的 similarity_search 表示的是根據相似度進行搜索,還可以使用 max_marginal_relevance_search,它會采用 MMR(Maximal Marginal Relevance,最大邊際相關性)算法。這個算法可以在保持結果相關性的同時,盡量選擇與已選結果不相似的內容,以增加結果的多樣性。
檢索生成
現在,我們已經為我們 RAG 應用準備好了數據。接下來,就該正式地構建我們的 RAG 應用了。我在之前的聊天機器上做了一些修改,讓它能夠支持 RAG,代碼如下:
from operator import itemgetter
from typing import List
import tiktoken
from langchain_core.messages import BaseMessage, HumanMessage, AIMessage, ToolMessage, SystemMessage, trim_messages
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_openai import OpenAIEmbeddings
from langchain_openai.chat_models import ChatOpenAI
from langchain_chroma import Chroma
vectorstore = Chroma(
collection_name="ai_learning",
embedding_functinotallow=OpenAIEmbeddings(),
persist_directory="vectordb"
)
retriever = vectorstore.as_retriever(search_type="similarity")
def str_token_counter(text: str) -> int:
enc = tiktoken.get_encoding("o200k_base")
return len(enc.encode(text))
def tiktoken_counter(messages: List[BaseMessage]) -> int:
num_tokens = 3
tokens_per_message = 3
tokens_per_name = 1
for msg in messages:
if isinstance(msg, HumanMessage):
role = "user"
elif isinstance(msg, AIMessage):
role = "assistant"
elif isinstance(msg, ToolMessage):
role = "tool"
elif isinstance(msg, SystemMessage):
role = "system"
else:
raise ValueError(f"Unsupported messages type {msg.__class__}")
num_tokens += (
tokens_per_message
+ str_token_counter(role)
+ str_token_counter(msg.content)
)
if msg.name:
num_tokens += tokens_per_name + str_token_counter(msg.name)
return num_tokens
trimmer = trim_messages(
max_tokens=4096,
strategy="last",
token_counter=tiktoken_counter,
include_system=True,
)
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
model = ChatOpenAI()
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Context: {context}""",
),
MessagesPlaceholder(variable_name="history"),
("human", "{question}"),
]
)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
context = itemgetter("question") | retriever | format_docs
first_step = RunnablePassthrough.assign(cnotallow=context)
chain = first_step | prompt | trimmer | model
with_message_history = RunnableWithMessageHistory(
chain,
get_session_history=get_session_history,
input_messages_key="question",
history_messages_key="history",
)
config = {"configurable": {"session_id": "dreamhead"}}
while True:
user_input = input("You:> ")
if user_input.lower() == 'exit':
break
if user_input.strip() == "":
continue
stream = with_message_history.stream(
{"question": user_input},
cnotallow=config
)
for chunk in stream:
print(chunk.content, end='', flush=True)
print()為了進行檢索,我們需要指定數據源,這里就是我們的向量數據庫,其中存放著我們前面已經索引過的數據:
vectorstore = Chroma(
collection_name="ai_learning",
embedding_functinotallow=OpenAIEmbeddings(),
persist_directory="vectordb"
)
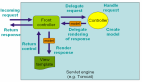
retriever = vectorstore.as_retriever(search_type="similarity")這段代碼引入了一個新的概念:Retriever。從名字不難看出,它就是充當 RAG 中的 R。Retriever 的核心能力就是根據文本查詢出對應的文檔(Document)。
為什么不直接使用向量數據庫呢?因為 Retriever 并不只有向量數據庫一種實現,比如,WikipediaRetriever 可以從 Wikipedia 上進行搜索。所以,一個 Retriever 接口就把具體的實現隔離開來。
回到向量數據庫上,當我們調用 as_retriever 創建 Retriever 時,還傳入了搜索類型(search_type),這里的搜索類型和前面講到向量數據庫的檢索方式是一致的,這里我們傳入的是 similarity,當然也可以傳入 mmr
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Context: {context}在這段提示詞里,我們告訴大模型,根據提供的上下文回答問題,不知道就說不知道。這是一個提示詞模板,在提示詞的最后是我們給出的上下文(Context)。這里上下文是根據問題檢索出來的內容。
有了這個提示詞,再加上聊天歷史和我們的問題,就構成了一個完整的提示詞模板:
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Context: {context}""",
),
MessagesPlaceholder(variable_name="history"),
("human", "{question}"),
]
)好,我們已經理解了這一講的新內容,接下來,就是把各個組件組裝到一起,構成一條完整的鏈:
context = itemgetter("question") | retriever | format_docs
first_step = RunnablePassthrough.assign(cnotallow=context)
chain = first_step | prompt | trimmer | model
with_message_history = RunnableWithMessageHistory(
chain,
get_session_history=get_session_history,
input_messages_key="question",
history_messages_key="history",
)在這段代碼里,我們首先構建了一個 context 變量,它也一條鏈。第一步是從傳入參數中獲取到 question 屬性,也就是我們的問題,然后把它傳給 retriever。retriever 會根據問題去做檢索,對應到我們這里的實現,就是到向量數據庫中檢索,檢索的結果是一個文檔列表。
文檔是 LangChain 應用內部的表示,要傳給大模型,我們需要把它轉成文本,這就是 format_docs 做的事情,它主要是把文檔內容取出來拼接到一起:
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)這里補充幾句實現細節。在 LangChain 代碼里, | 運算符被用作不同組件之間的連接,其實現的關鍵就是大部分組件都實現了 Runnable 接口,在這個接口里實現了 __or__ 和 __ror__。__or__ 表示這個對象出現在| 左邊時的處理,相應的 __ror__ 表示這個對象出現在右邊時的處理。
Python 在處理 a | b 這個表達式時,它會先嘗試找 a 的 __or__,如果找不到,它會嘗試找 b 的 __ror__。所以,在 context 的處理中, 來自標準庫的 itemgetter 雖然沒有實現
__or__,但 retriever 因為實現了 Runnable 接口,所以,它也實現了 __ror__。所以,這段代碼才能組裝出我們所需的鏈。
有了 context 變量,我們可以用它構建了另一個變量 first_step:
first_step = RunnablePassthrough.assign(cnotallow=context)還記得我們的提示詞模板里有一個 context 變量嗎?它就是從這里來的。
RunnablePassthrough.assign 這個函數就是在不改變鏈當前狀態值的前提下,添加新的狀態值。前面我們說了,這里賦給 context 變量的值是一個鏈,我們可以把它理解成一個函數,它會在運行期執行,其參數就是我們當前的狀態值。現在你可以理解 itemgetter(“question”) 的參數是從哪來的了。這個函數的返回值會用來在當前的狀態里添加一個叫 context 的變量,以便在后續使用。
其余的代碼我們之前已經講解過了,這里就不再贅述了。至此,我們擁有了一個可以運行的 RAG 應用,我們可以運行一下看看效果:
You:> 專欄的作者是誰?
專欄的作者是鄭曄。
You:> 作者還寫過哪些專欄?
作者鄭曄還寫過《10x程序員工作法》、《軟件設計之美》、《代碼之丑》和《程序員的測試課》這四個專欄。