超越DeepSeek-R1,數學形式化準確率飆升至84% | 字節&南大開源
當人工智能已經能下圍棋、寫代碼,如何讓機器理解并證明數學定理,仍是橫亙在科研界的重大難題。
字節跳動Seed團隊與南京大學聯合發布CriticLean框架,一舉將數學自然語言到Lean 4代碼的形式化準確率從38%提升至84%。
該框架創新性地將評估模型置于核心位置。通過強化學習訓練的CriticLeanGPT模型,能像數學專家一樣精準判斷形式化代碼是否貼合原始語義,配合迭代優化機制,讓生成的定理證明既符合語法規范,又忠實于數學邏輯。
?前論?和數據代碼倉庫均已對外公開,歡迎開源使用。

數學形式化領域的核心挑戰
將自然語言描述的數學命題轉化為機器可驗證的形式化代碼(如Lean 4定理),是自動化定理證明領域的基礎性難題,其核心挑戰不僅在于語法層面的準確轉換,更在于對數學語義的深度理解與忠實還原。
盡管現有研究在生成模型與編譯有效性上取得一定進展,但在復雜問題的語義對齊上仍存在顯著瓶頸,具體體現在以下三方面:
- 語義鴻溝:自然語言數學命題的隱含條件等難精準映射為形式邏輯,易出現前提翻譯偏差等問題,過往方法因缺語義一致性校驗,導致大量邏輯錯誤的形式化結果。
- 評價缺位:對形式化結果的評價依賴編譯檢查或 LLM 簡單判斷,存在錯誤類型覆蓋不全、評價可靠性不足的問題,難以識別邏輯矛盾等。
- 數據瓶頸:現有數學形式化數據集規模和多樣性不足、難度分布單一、語義校驗缺失,制約了模型應對復雜數學命題的能力。
引入Critic角色以實現可靠形式化
上述挑戰的核心在于:形式化流程中“評價”與“生成”的割裂。
CriticLean框架將引入強化學習的 Critic 模型,通過訓練專門的語義評價模型(CriticLeanGPT)、結合 Lean 4 編譯器反饋進行迭代生成。系統性解決語義對齊、評價可靠性與數據質量問題,為數學自動化形式化提供了全新范式。
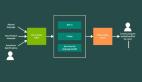
 圖1:CriticLean框架通過編譯器與評估器的雙重反饋,實現數學形式化的迭代優化
圖1:CriticLean框架通過編譯器與評估器的雙重反饋,實現數學形式化的迭代優化
CriticLeanGPT:會“挑錯”的數學評估專家
團隊基于Qwen2.5和Qwen3系列模型,通過兩步訓練打造專業評估器:
- 有監督微調(SFT):在4.8萬條包含:數學、代碼以及數學語句-形式化代碼對一致性相關的Critic數據CriticLeanInstruct數據集上訓練,增強其針對語義判斷的評估能力。
- 強化學習優化(RL):采用GRPO算法,以“判斷是否準確”和“輸出格式是否規范”作為獎勵信號,讓模型學會在評估中迭代提升。
該模型能識別12類常見錯誤,包括類型錯誤(占比24.9%)、數學表示錯誤(23.8%)等,能夠發現“代碼編譯通過但邏輯偏離原題”的隱性問題。

△圖2:不同類型錯誤的分布
CriticLeanBench:首個聚焦形式化任務語義評估的基準測試
CriticLeanBench是用于評估模型在數學形式化任務中關鍵推理能力的基準測試,旨在全面衡量模型將自然語言數學陳述轉化為經形式驗證的定理聲明等方面的表現.
其構建和實現過程如下:
CriticLeanBench 在數據收集階段,從多個數據來源選取數學陳述及對應的Lean 4 陳述,提交Lean 4陳述到編譯器。1)對于編譯失敗的語句,隨機采樣保留編譯器反饋信息。2)對于編譯成功的部分,通過使用 DeepSeek R1 結合專家校驗的方式保留正確和錯誤的樣本(錯誤的樣本保留錯誤信息)。
- 數據來源多樣:數學陳述選取了Omni-MATH、AIME、U-MATH等多個數據源,這些數據源涵蓋了不同難度層次和數學領域的問題。有助于更全面準確地評估模型在不同數學內容上的表現。
- 覆蓋多種錯誤類型:CriticLeanBench 覆蓋語法錯誤、語義錯誤、邏輯錯誤等多種問題,全面考察模型能力。
- 確保評估可靠有效:通過專家審查和大模型驗證相結合的方式來保證評估基準的可靠性和有效性。在不同類別中選取具有代表性的樣本,確保涵蓋各種錯誤類型,從而使評估結果更可靠。

△圖3: CriticLeanBench 構建的概覽

△表1:CriticLeanBench 數據集統計信息與各類代碼基準數據集的對比
在包含500組測試樣本的CriticLeanBench基準中,CriticLeanGPT的準確率達到87%,遠超GPT-4o(67.8%)和Claude 3.5(74.2%),甚至超過DeepSeek-R1(84%)的表現。
- 核心指標:Qwen3-32B-RL版本準確率達87%,true negative rate(正確識別錯誤樣本)達85.6%,遠超GPT-4o的40.0%。
- 對比優勢:在相同模型規模下,經CriticLean訓練的Qwen2.5-32B模型準確率(78.6%)較基礎版(73.0%)提升5.6%,且對錯誤樣本的識別能力提升明顯。

△表2:在 CriticLeanBench 上的性能表現
模型大小的Scaling分析表明,模型性能隨規模提升穩步增強。

△圖4: 大語言模型在 CriticLeanBench 上的擴展性分析(? 表示閉源的大語言模型)
FineLeanCorpus:28.5萬條高質量形式化數據
依托CriticLean框架,團隊構建了目前規模最大、質量最高的數學形式化數據集之一:
- 規模與多樣性:包含285,957條樣本,覆蓋從高中奧數到大學數學的16個領域,其中高難度子集(Diamond)含36,033條問題。
- 質量保障:每條樣本均通過編譯器語法檢查與CriticLeanGPT語義驗證,人工抽檢準確率達84%以上。
- 結構優勢:相比LeanWorkbook,其難度分布更均衡(多峰分布),領域覆蓋更全面(如解析幾何樣本量提升300%)。

△表3:FineLeanCorpus 的不同來源及數據集統計信息
與高度偏斜的 Lean-Workbook 相比,FineLeanCorpus 提供了更透明的批判過程、更高比例的頂級問題,以及更加平衡和多樣化的主題分布

△表4:數據集統計信息的對比
與高度偏斜的 Lean-Workbook 相比,FineLeanCorpus 提供了更透明的批判過程、更高比例的頂級問題,以及更加平衡和多樣化的主題分布

△圖5:數據集統計信息的對比()
實驗結果:大幅提高數學形式化準確率
將該框架應用于自動形式化流程,配合Kimina-Autoformalizer-7B生成器,準確率從38%(單輪生成)提升至84%(多輪迭代優化),其中語義評估環節貢獻了30個百分點的提升。

△表5:自動化形式化性能的人類評估準確率結果
論文鏈接:https://arxiv.org/pdf/2507.06181
項目鏈接:https://github.com/multimodal-art-projection/CriticLean