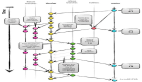
Flink + YARN + Gitlab 自動(dòng)提交代碼全流程詳解
在大數(shù)據(jù)實(shí)時(shí)計(jì)算領(lǐng)域,Apache Flink 憑借其流批一體、低延遲、高吞吐的特性,成為企業(yè)級(jí)實(shí)時(shí)計(jì)算的主流選擇。FlinkSQL 作為 Flink 的關(guān)系型 API,降低了實(shí)時(shí)開(kāi)發(fā)的門(mén)檻,讓開(kāi)發(fā)者通過(guò) SQL 即可完成復(fù)雜流處理邏輯。而 YARN 作為 Hadoop 生態(tài)的資源調(diào)度平臺(tái),為 Flink 作業(yè)提供了穩(wěn)定的資源管理與隔離能力。Gitlab 則作為代碼托管與 CI/CD 平臺(tái),實(shí)現(xiàn)了代碼版本控制與自動(dòng)化流程的串聯(lián)。
本文將詳細(xì)介紹 Flink + FlinkSQL + YARN + Gitlab 的自動(dòng)提交代碼全流程,涵蓋環(huán)境準(zhǔn)備、代碼管理、作業(yè)開(kāi)發(fā)、CI/CD 流程設(shè)計(jì)、自動(dòng)提交與監(jiān)控等核心環(huán)節(jié),幫助企業(yè)構(gòu)建實(shí)時(shí)計(jì)算的自動(dòng)化開(kāi)發(fā)與部署體系。

一、環(huán)境準(zhǔn)備
1. 組件版本選擇
為確保各組件兼容性,推薦以下版本組合(基于企業(yè)級(jí)穩(wěn)定實(shí)踐):
組件 | 版本 | 說(shuō)明 |
Hadoop | 3.3.1 | 包含 YARN 資源調(diào)度器 |
Flink | 1.16.0 | 支持 FlinkSQL 與 YARN 集成 |
Gitlab | 14.9.0 | 代碼托管與 CI/CD |
Java | 1.8 | Flink 運(yùn)行基礎(chǔ)環(huán)境 |
Maven | 3.8.6 | 項(xiàng)目構(gòu)建工具 |
2. 環(huán)境安裝與配置
(1) Hadoop & YARN 集群搭建
假設(shè)已部署 Hadoop 集群(需包含 HDFS 和 YARN),核心配置如下:
? core-site.xml(HDFS 配置):
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:8020</value>
</property>
</configuration>? yarn-site.xml(YARN 配置):
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>resourcemanager</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>啟動(dòng) YARN 后,可通過(guò) http://<resourcemanager>:8088 訪(fǎng)問(wèn) YARN Web UI,確認(rèn)集群狀態(tài)正常。
(2) Flink on YARN 配置
下載 Flink 1.16.0 二進(jìn)制包并解壓,修改 conf/flink-conf.yaml:
# Flink on YARN 核心配置
jobmanager.rpc.address: localhost
rest.port: 8081
# YARN 隊(duì)列配置(需與 YARN 隊(duì)列名稱(chēng)一致)
yarn.application.queue: flink_queue
# 狀態(tài)后端(推薦使用 RocksDB)
state.backend: rocksdb
# Checkpoint 存儲(chǔ)(HDFS 路徑)
state.checkpoints.dir: hdfs://namenode:8020/flink/checkpoints將 Hadoop 配置文件(core-site.xml、hdfs-site.xml、yarn-site.xml)軟鏈至 Flink 的 conf 目錄:
ln -s $HADOOP_HOME/etc/hadoop/core-site.xml $FLINK_HOME/conf/
ln -s $HADOOP_HOME/etc/hadoop/hdfs-site.xml $FLINK_HOME/conf/
ln -s $HADOOP_HOME/etc/hadoop/yarn-site.xml $FLINK_HOME/conf/(3) Gitlab 部署與基礎(chǔ)配置
? 部署 Gitlab:可通過(guò) Docker 快速部署(推薦使用 Gitlab 官方鏡像):
docker run -d --name gitlab \
-p 8080:80 -p 2222:22 \
-v /srv/gitlab/config:/etc/gitlab \
-v /srv/gitlab/logs:/var/log/gitlab \
-v /srv/gitlab/data:/var/opt/gitlab \
gitlab/gitlab-ce:14.9.0-ce.0訪(fǎng)問(wèn) http://<gitlab-ip>:8080,初始化管理員密碼后創(chuàng)建項(xiàng)目(如 flink-realtime)。
? 配置 SSH 密鑰:本地生成 SSH 密鑰(ssh-keygen -t rsa),將公鑰(~/.ssh/id_rsa.pub)添加到 Gitlab 用戶(hù)設(shè)置中,確保代碼可免密推送。
二、Gitlab 代碼管理規(guī)范
1. 項(xiàng)目結(jié)構(gòu)設(shè)計(jì)
基于 Maven 構(gòu)建Flink作業(yè),推薦項(xiàng)目結(jié)構(gòu)如下:
flink-realtime/
├── src/
│ ├── main/
│ │ ├── java/ # Java/Scala 代碼(如 UDF、自定義 Source/Sink)
│ │ ├── resources/ # 配置文件與 SQL 腳本
│ │ │ ├── sql/ # FlinkSQL 腳本(如 user_behavior.sql)
│ │ │ ├── application.properties # 作業(yè)配置(并行度、Kafka 地址等)
│ │ │ └── log4j2.xml # 日志配置
│ │ └── scala/ # Scala 代碼(可選)
│ └── test/ # 單元測(cè)試
├── .gitlab-ci.yml # Gitlab CI/CD 配置文件
├── pom.xml # Maven 依賴(lài)配置
└── README.md # 項(xiàng)目說(shuō)明文檔2. 分支管理策略
采用 Git Flow 分支模型,核心分支如下:
分支類(lèi)型 | 名稱(chēng) | 用途 | 合并目標(biāo) |
主分支 | master | 生產(chǎn)環(huán)境代碼,僅允許 CI/CD 自動(dòng)更新 | 無(wú) |
開(kāi)發(fā)分支 | develop | 開(kāi)發(fā)環(huán)境集成分支 | master |
功能分支 | feature/xxx | 新功能開(kāi)發(fā)(如 feature/user_behavior) | develop |
修復(fù)分支 | hotfix/xxx | 生產(chǎn)問(wèn)題修復(fù) | master/develop |
3. 代碼提交規(guī)范
為便于 CI/CD 流程追蹤,提交信息需遵循以下格式:
<type>(<scope>): <description>
# 示例
feat(sql): 新增用戶(hù)行為實(shí)時(shí)統(tǒng)計(jì)SQL
fix(config): 修復(fù)Kafka消費(fèi)組配置錯(cuò)誤
docs(ci): 更新Gitlab CI部署文檔- type:類(lèi)型(feat 新功能、fix 修復(fù)、docs 文檔、style 格式、refactor 重構(gòu)等)
- scope:影響范圍(如 sql、config、ci)
- description:簡(jiǎn)潔描述(不超過(guò)50字符)
三、Flink 作業(yè)開(kāi)發(fā)(以 FlinkSQL 為核心)
1. 依賴(lài)配置(pom.xml)
核心依賴(lài)包括 Flink 核心、FlinkSQL、連接器(如 Kafka、MySQL)等:
<dependencies>
<!-- Flink 核心 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.16.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.16.0</version>
<scope>provided</scope>
</dependency>
<!-- FlinkSQL -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.16.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.16.0</version>
<scope>provided</scope>
</dependency>
<!-- Kafka 連接器 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.16.0</version>
</dependency>
<!-- MySQL 連接器(用于結(jié)果寫(xiě)入) -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.12</artifactId>
<version>1.16.0</version>
</dependency>
</dependencies>2. FlinkSQL 腳本開(kāi)發(fā)
以“用戶(hù)行為實(shí)時(shí)統(tǒng)計(jì)”為例,開(kāi)發(fā) FlinkSQL 腳本(resources/sql/user_behavior.sql):
-- 1. 創(chuàng)建 Kafka 數(shù)據(jù)源表(用戶(hù)行為日志)
CREATE TABLE user_behavior (
user_id BIGINT,
item_id BIGINT,
behavior STRING, -- 行為類(lèi)型:pv(瀏覽)、buy(購(gòu)買(mǎi))、cart(加購(gòu))、fav(收藏)
ts TIMESTAMP(3)
) WITH (
'connector'='kafka',
'topic'='user_behavior',
'properties.bootstrap.servers'='kafka1:9092,kafka2:9092',
'properties.group.id'='flink_consumer_group',
'format'='json',
'scan.startup.mode'='latest-offset'
);
-- 2. 創(chuàng)建 MySQL 結(jié)果表(每小時(shí)行為統(tǒng)計(jì))
CREATE TABLE behavior_hourly_stats (
window_start TIMESTAMP(3),
window_end TIMESTAMP(3),
behavior STRING,
count BIGINT,
PRIMARY KEY (window_start, behavior) NOT ENFORCED
) WITH (
'connector'='jdbc',
'url'='jdbc:mysql://mysql:3306/realtime_stats',
'table-name'='behavior_hourly_stats',
'username'='flink',
'password'='flink123'
);
-- 3. 執(zhí)行統(tǒng)計(jì)邏輯(每小時(shí)窗口計(jì)數(shù))
INSERT INTO behavior_hourly_stats
SELECT
TUMBLE_START(ts, INTERVAL'1'HOUR) AS window_start,
TUMBLE_END(ts, INTERVAL'1'HOUR) AS window_end,
behavior,
COUNT(*) AS count
FROM user_behavior
GROUPBY
TUMBLE(ts, INTERVAL'1'HOUR),
behavior;3. 作業(yè)主程序開(kāi)發(fā)
通過(guò) Java 代碼加載 SQL 腳本并執(zhí)行,實(shí)現(xiàn)作業(yè)提交(src/main/java/com/example/FlinkSQLJob.java):
package com.example;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.TableResult;
import java.io.File;
publicclassFlinkSQLJob {
publicstaticvoidmain(String[] args)throws Exception {
// 1. 創(chuàng)建流執(zhí)行環(huán)境(使用 YARN 模式)
finalStreamExecutionEnvironmentenv= StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4); // 設(shè)置全局并行度
// 2. 創(chuàng)建 TableEnvironment(Blink Planner)
EnvironmentSettingssettings= EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
TableEnvironmenttableEnv= TableEnvironment.create(settings);
// 3. 加載 SQL 腳本文件
StringsqlPath=newFile("resources/sql/user_behavior.sql").getAbsolutePath();
StringsqlScript=newString(java.nio.file.Files.readAllBytes(java.nio.file.Paths.get(sqlPath)));
// 4. 執(zhí)行 SQL 腳本(按語(yǔ)句分割并逐條執(zhí)行)
String[] sqlStatements = sqlScript.split(";(?=(?:[^']*'[^']*')*[^']*$)");
for (String sql : sqlStatements) {
if (!sql.trim().isEmpty()) {
TableResultresult= tableEnv.executeSql(sql.trim());
System.out.println("SQL executed: " + sql.trim());
}
}
// 5. 提交作業(yè)(FlinkSQL 的 INSERT INTO 會(huì)自動(dòng)觸發(fā)執(zhí)行)
env.execute("FlinkSQL User Behavior Hourly Stats");
}
}4. 作業(yè)配置(application.properties)
將動(dòng)態(tài)配置(如 Kafka 地址、并行度)提取到配置文件中,避免硬編碼:
# 作業(yè)名稱(chēng)
job.name=flink_sql_user_behavior
# 并行度
job.parallelism=4
# Kafka 配置
kafka.bootstrap.servers=kafka1:9092,kafka2:9092
kafka.topic=user_behavior
kafka.group.id=flink_consumer_group
# MySQL 配置
mysql.url=jdbc:mysql://mysql:3306/realtime_stats
mysql.username=flink
mysql.password=flink123
# Checkpoint 配置
checkpoint.interval=60000 # 1分鐘一次 Checkpoint
checkpoint.timeout=300000 # Checkpoint 超時(shí)時(shí)間5分鐘四、YARN 資源調(diào)度與作業(yè)提交
1. Flink on YARN 模式選擇
Flink on YARN 支持三種模式,需根據(jù)場(chǎng)景選擇:
模式 | 特點(diǎn) | 適用場(chǎng)景 |
Session Mode | 預(yù)啟動(dòng) YARN Application,共享 JobManager | 短作業(yè)、低資源消耗場(chǎng)景 |
Per-Job Mode | 每個(gè)作業(yè)獨(dú)立啟動(dòng) YARN Application | 作業(yè)間資源隔離要求高 |
Application Mode | 推薦:作業(yè)主程序在 YARN 中執(zhí)行,客戶(hù)端僅提交 | 生產(chǎn)環(huán)境主流模式 |
本文以 Application Mode 為例,該模式下作業(yè)主邏輯在 YARN 的 Application Master 中運(yùn)行,客戶(hù)端只需提交 JAR 包,避免客戶(hù)端資源占用。
2. 手動(dòng)提交作業(yè)到 YARN
通過(guò) flink run -yarn 命令提交作業(yè),核心參數(shù)如下:
flink run -t yarn-application \
-Dyarn.application.name=flink_sql_user_behavior \
-Dyarn.application.queue=flink_queue \
-Dparallelism.default=4 \
-Djobmanager.memory.process.size=1600m \
-Dtaskmanager.memory.process.size=1728m \
-Dtaskmanager.numberOfTaskSlots=4 \
-c com.example.FlinkSQLJob \
/path/to/flink-realtime-1.0-SNAPSHOT.jar參數(shù)說(shuō)明:
- -t yarn-application:指定 Application Mode
- -Dyarn.application.name:YARN 應(yīng)用名稱(chēng)
- -Dyarn.application.queue:YARN 隊(duì)列(需與 YARN 配置一致)
- -Dparallelism.default:默認(rèn)并行度
- -c:主程序全限定類(lèi)名
提交后,可通過(guò) YARN Web UI(http://<resourcemanager>:8088)查看作業(yè)狀態(tài),點(diǎn)擊“Tracking UI”進(jìn)入 Flink Web UI 監(jiān)控作業(yè)指標(biāo)。
五、Gitlab CI/CD 自動(dòng)提交流程設(shè)計(jì)
1. Gitlab CI/CD 原理
Gitlab CI/CD 通過(guò) .gitlab-ci.yml 定義流水線(xiàn)(Pipeline),流水線(xiàn)包含多個(gè)階段(Stage),每個(gè)階段包含多個(gè)作業(yè)(Job)。當(dāng)代碼提交/合并到指定分支時(shí),Gitlab Runner 自動(dòng)執(zhí)行流水線(xiàn),完成構(gòu)建、測(cè)試、部署等流程。
2. Gitlab Runner 配置
(1) 安裝 Gitlab Runner
在可訪(fǎng)問(wèn) YARN 集群的節(jié)點(diǎn)上安裝 Gitlab Runner(以 Linux 為例):
# 添加 Gitlab Runner 官方倉(cāng)庫(kù)
curl -L https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.rpm.sh | sudo bash
# 安裝 Runner
sudo yum install -y gitlab-runner
# 注冊(cè) Runner(需從 Gitlab 項(xiàng)目獲取注冊(cè) URL 和 Token)
sudo gitlab-runner register注冊(cè)時(shí)需配置:
- Gitlab instance URL:Gitlab 地址(如 http://<gitlab-ip>:8080)
- Registration token:從 Gitlab 項(xiàng)目 Settings -> CI/CD -> Runners 獲取
- Executor type:選擇 shell(需確保 Runner 節(jié)點(diǎn)已安裝 Java、Maven、Flink、Hadoop 客戶(hù)端)
(2) Runner 權(quán)限配置
確保 Runner 用戶(hù)(默認(rèn) gitlab-runner)有權(quán)限訪(fǎng)問(wèn) HDFS 和 YARN:
# 將 gitlab-runner 用戶(hù)加入 hadoop 用戶(hù)組
sudo usermod -aG hadoop gitlab-runner
# 配置 HDFS 代理用戶(hù)(在 core-site.xml 中添加)
<property>
<name>hadoop.proxyuser.gitlab-runner.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.gitlab-runner.hosts</name>
<value>*</value>
</property>重啟 HDFS 和 YARN 使代理用戶(hù)配置生效。
3. .gitlab-ci.yml 流水線(xiàn)配置
在項(xiàng)目根目錄創(chuàng)建 .gitlab-ci.yml,定義以下階段:
階段 | 作用 | 作業(yè)示例 |
build | Maven 打包生成 JAR | build_job |
test | 單元測(cè)試、SQL 語(yǔ)法校驗(yàn) | test_job |
deploy | 提交作業(yè)到 YARN(生產(chǎn)/開(kāi)發(fā)) | deploy_prod_job |
完整配置示例:
# 定義流水線(xiàn)階段
stages:
-build
-test
-deploy
# 全局變量(避免硬編碼)
variables:
MAVEN_OPTS:"-Dmaven.repo.local=$CI_PROJECT_DIR/.m2/repository"
FLINK_HOME:"/opt/flink-1.16.0"
HADOOP_HOME:"/opt/hadoop-3.3.1"
YARN_QUEUE:"flink_queue"
# 緩存 Maven 依賴(lài)(加速構(gòu)建)
cache:
paths:
-.m2/repository
# 1. 構(gòu)建階段:Maven 打包
build_job:
stage:build
script:
-echo"Building Flink job..."
-mvncleanpackage-DskipTests
artifacts:
paths:
-target/*.jar# 保存 JAR 包供后續(xù)階段使用
expire_in:1hour# 1小時(shí)后過(guò)期
# 2. 測(cè)試階段:?jiǎn)卧獪y(cè)試 + SQL 語(yǔ)法校驗(yàn)
test_job:
stage:test
script:
-echo"Running unit tests..."
-mvntest
-echo"Validating FlinkSQL syntax..."
# 使用 Flink SQL Parser 校驗(yàn)語(yǔ)法(需提前編寫(xiě)校驗(yàn)?zāi)_本)
-bashscripts/validate_sql.shresources/sql/user_behavior.sql
dependencies:
-build_job# 依賴(lài)構(gòu)建階段的 JAR 包
# 3. 部署階段:提交到 YARN(僅 master 分支觸發(fā))
deploy_prod_job:
stage:deploy
script:
-echo"Deploying to YARN production queue..."
# 從構(gòu)建產(chǎn)物中獲取 JAR 包名稱(chēng)
-JAR_FILE=$(findtarget-name"*.jar"|head-n1)
-echo"JAR file: $JAR_FILE"
# 提交作業(yè)到 YARN(Application Mode)
-$FLINK_HOME/bin/flinkrun-tyarn-application\
-Dyarn.application.name=flink_sql_user_behavior\
-Dyarn.application.queue=$YARN_QUEUE\
-Dparallelism.default=4\
-Djobmanager.memory.process.size=1600m\
-Dtaskmanager.memory.process.size=1728m\
-Dtaskmanager.numberOfTaskSlots=4\
-ccom.example.FlinkSQLJob\
$JAR_FILE
dependencies:
-build_job
only:
-master# 僅 master 分支提交時(shí)觸發(fā)
when:manual # 手動(dòng)觸發(fā)(可選,避免誤部署)4. SQL 語(yǔ)法校驗(yàn)?zāi)_本
為避免 SQL 語(yǔ)法錯(cuò)誤導(dǎo)致作業(yè)提交失敗,可編寫(xiě)校驗(yàn)?zāi)_本(scripts/validate_sql.sh):
#!/bin/bash
SQL_FILE=$1
if [ ! -f "$SQL_FILE" ]; then
echo"Error: SQL file $SQL_FILE not found."
exit 1
fi
# 使用 Flink 內(nèi)置的 SQL Parser 校驗(yàn)語(yǔ)法(需 Flink 環(huán)境變量)
$FLINK_HOME/bin/sql-client.sh -f "$SQL_FILE" -d
if [ $? -eq 0 ]; then
echo"FlinkSQL syntax validation passed."
else
echo"Error: FlinkSQL syntax validation failed."
exit 1
fi賦予腳本執(zhí)行權(quán)限:chmod +x scripts/validate_sql.sh。
六、自動(dòng)提交全流程實(shí)踐
1. 開(kāi)發(fā)與提交代碼
創(chuàng)建功能分支:從 develop 分支切出功能分支:
git checkout -b feature/user_behavior_stat develop開(kāi)發(fā)代碼:編寫(xiě) FlinkSQL 腳本、Java 主程序及配置文件,本地測(cè)試通過(guò)后提交:
git add .
git commit -m "feat(sql): 新增用戶(hù)行為實(shí)時(shí)統(tǒng)計(jì)SQL"
git push origin feature/user_behavior_stat提交 Merge Request:在 Gitlab 上創(chuàng)建從 feature/user_behavior_stat 到 develop 的 Merge Request(MR),觸發(fā)流水線(xiàn)自動(dòng)執(zhí)行 build 和 test 階段。
2. 流水線(xiàn)執(zhí)行過(guò)程
- 構(gòu)建階段:Maven 自動(dòng)編譯打包,生成 flink-realtime-1.0-SNAPSHOT.jar,并保存為流水線(xiàn)產(chǎn)物。
- 測(cè)試階段:執(zhí)行單元測(cè)試(如 UDF 測(cè)試)和 SQL 語(yǔ)法校驗(yàn),若測(cè)試失敗,流水線(xiàn)終止并通知開(kāi)發(fā)者。
- 合并到 develop:MR 審核通過(guò)后,合并到 develop 分支,此時(shí)不觸發(fā)部署。
- 發(fā)布到生產(chǎn):將 develop 分支合并到 master 分支,觸發(fā) deploy_prod_job,自動(dòng)提交作業(yè)到 YARN 生產(chǎn)隊(duì)列。
3. 作業(yè)狀態(tài)監(jiān)控
- YARN 監(jiān)控:通過(guò) YARN Web UI 查看作業(yè)狀態(tài)(運(yùn)行中、成功、失敗),點(diǎn)擊“Logs”查看 YARN 日志。
- Flink 監(jiān)控:點(diǎn)擊作業(yè)的“Tracking UI”進(jìn)入 Flink Web UI,監(jiān)控 Checkpoint、反壓、吞吐量等指標(biāo)。
- 日志收集:可將 Flink 作業(yè)日志輸出到 HDFS 或 ELK 集群,便于問(wèn)題排查。
七、常見(jiàn)問(wèn)題與優(yōu)化
1. 常見(jiàn)問(wèn)題排查
(1) 問(wèn)題1:作業(yè)提交到 YARN 失敗,報(bào)“YARN application not found”
原因:Flink 與 Hadoop 版本不兼容,或 YARN 配置文件未正確軟鏈。解決:確保 Flink 版本支持 Hadoop 3.x,檢查 $FLINK_HOME/conf 下是否有 yarn-site.xml 等配置文件。
(2) 問(wèn)題2:SQL 語(yǔ)法校驗(yàn)通過(guò),但作業(yè)運(yùn)行時(shí)報(bào)“Table not found”
原因:SQL 腳本中表名大小寫(xiě)與實(shí)際不一致,或連接器配置錯(cuò)誤(如 Kafka topic 不存在)。解決:檢查 SQL 表名大小寫(xiě)(FlinkSQL 默認(rèn)不區(qū)分大小寫(xiě),但存儲(chǔ)系統(tǒng)可能區(qū)分),確認(rèn) Kafka/MySQL 連接參數(shù)。
(3) 問(wèn)題3:Gitlab Runner 執(zhí)行部署時(shí)報(bào)“Permission denied”
原因:Runner 用戶(hù)無(wú)權(quán)限訪(fǎng)問(wèn) HDFS 或提交 YARN 作業(yè)。解決:檢查 Hadoop 代理用戶(hù)配置,確保 gitlab-runner 用戶(hù)屬于 hadoop 用戶(hù)組。
2. 流程優(yōu)化建議
- 多環(huán)境部署:通過(guò) Gitlab 變量區(qū)分開(kāi)發(fā)/測(cè)試/生產(chǎn)環(huán)境(如 $YARN_QUEUE_DEV、$YARN_QUEUE_PROD),實(shí)現(xiàn)一套代碼多環(huán)境部署。
- 版本回滾:在 .gitlab-ci.yml 中添加回滾作業(yè),通過(guò) yarn application -kill <app_id> 停止舊作業(yè),再提交指定版本的 JAR 包。
- 通知機(jī)制:集成釘釘/飛書(shū)機(jī)器人,流水線(xiàn)成功/失敗時(shí)發(fā)送消息通知開(kāi)發(fā)團(tuán)隊(duì)。
- 資源動(dòng)態(tài)調(diào)整:根據(jù)作業(yè)負(fù)載,通過(guò) Flink REST API 動(dòng)態(tài)調(diào)整并行度或資源,提升資源利用率。
八、總結(jié)
本文詳細(xì)介紹了 Flink + FlinkSQL + YARN + Gitlab 的自動(dòng)提交代碼全流程,從環(huán)境準(zhǔn)備、代碼管理、作業(yè)開(kāi)發(fā)到 CI/CD 流程設(shè)計(jì),覆蓋了實(shí)時(shí)計(jì)算自動(dòng)化部署的核心環(huán)節(jié)。通過(guò)該流程,企業(yè)可實(shí)現(xiàn):
- 開(kāi)發(fā)效率提升:代碼提交后自動(dòng)構(gòu)建、測(cè)試、部署,減少人工操作。
- 質(zhì)量管控:通過(guò)單元測(cè)試、SQL 校驗(yàn)等環(huán)節(jié),降低作業(yè)上線(xiàn)風(fēng)險(xiǎn)。
- 資源隔離:YARN 提供多隊(duì)列資源管理,實(shí)現(xiàn)作業(yè)間資源隔離與公平調(diào)度。
未來(lái)可進(jìn)一步擴(kuò)展與監(jiān)控系統(tǒng)集成(如 Prometheus + Grafana)、實(shí)現(xiàn)作業(yè)自動(dòng)擴(kuò)縮容,構(gòu)建更完善的實(shí)時(shí)計(jì)算運(yùn)維體系。