微軟C++四面終極拷問:手撕線程安全RingBuffer
在微軟 C++ 面試的四面環節,經常會出現一道極具挑戰性的題目 —— 手撕線程安全 RingBuffer 。這可不是一道簡單的編程題,它綜合考查了面試者對 C++ 語言特性、多線程編程、數據結構設計等多方面的深度理解與靈活運用能力。RingBuffer,也就是環形緩沖區,是一種在多線程編程場景中極為常用的數據結構。它就像一個首尾相接的環形軌道,數據的寫入和讀取在這個環形軌道上循環進行。這種結構在處理生產者 - 消費者模型時,有著獨特的優勢。想象一下,在一個數據處理系統中,有多個線程不斷地產生數據(生產者),同時又有其他線程需要持續地處理這些數據(消費者),RingBuffer 就能夠很好地在兩者之間起到緩沖和協調的作用。
而線程安全則是在多線程環境下必須要重點考慮的因素。多個線程同時對 RingBuffer 進行讀寫操作時,如果沒有合理的機制來保證數據的一致性和操作的原子性,就會出現諸如數據競爭、臟讀、寫覆蓋等嚴重問題。微軟在四面設置這樣的題目,旨在篩選出那些不僅掌握了基礎知識,更具備解決復雜實際問題能力的優秀候選人。接下來,讓我們深入探討如何實現一個線程安全的 RingBuffer ,看看在這一過程中會涉及哪些關鍵技術與要點。
Part1.什么是RingBuffer?
1.1 RingBuffer概述
RingBuffer,中文名是環形緩沖區,也被叫做循環緩沖區 ,從名字就能看出它的獨特之處。簡單來說,它是一種固定大小、頭尾相連的緩沖區,就像一個環形的跑道。在這個環形結構里,數據的寫入和讀取操作就像是運動員在跑道上跑步,當寫到緩沖區末尾時,會自動回到開頭繼續寫入;讀取時也是如此,循環往復。
 圖片
圖片
為了更形象地理解,大家可以想象一下食堂里的餐盤回收區,餐盤就像數據,回收員不斷把餐盤放到傳送帶上(寫入數據),而食堂工作人員則從傳送帶的另一端拿走餐盤清洗(讀取數據) 。傳送帶的長度是固定的(緩沖區大小固定),當傳送帶上餐盤放滿了,新送上來的餐盤就會把最開始的餐盤擠出去(緩沖區滿時新數據覆蓋舊數據)。這就是 RingBuffer,是不是很好理解?
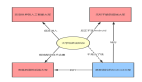
一般構建一個環形緩沖區需要一段連續的內存空間以及4個指針:
- pHead指針:指向內存空間中的首地址;
- pTail指針:指向內存空間的尾地址;
- pValidRead:指向內存空間存儲數據的起始位置(讀指針);
- pValidWrite:指向內存空間存儲數據的結尾位置(寫指針)。
相比于傳統的線性緩沖區,RingBuffer 有著諸多優勢。傳統緩沖區在數據處理過程中,一旦寫滿,就需要重新分配內存或者等待數據被讀取,這會帶來額外的開銷和復雜的管理工作。而 RingBuffer 因為其循環利用空間的特性,無需頻繁進行內存的分配與釋放,極大地提高了內存的使用效率 。在數據處理速度上,RingBuffer 也表現出色,它能更高效地處理連續數據流,減少數據處理的延遲,就像高速公路上暢通無阻的環形立交橋,車輛可以持續不斷地通行,而不會出現擁堵等待的情況。
1.2 線程安全
在單線程環境下,RingBuffer 的實現和使用相對簡單,就像一個人獨占一條跑道,想怎么跑就怎么跑,不用擔心會和別人撞車。但在多線程環境中,情況就變得復雜起來,多個線程就像多個運動員在同一條跑道上跑步,如果沒有合理的規則,很容易就會發生碰撞,也就是我們所說的線程安全問題。
當多個線程同時訪問和操作 RingBuffer 時,就可能會出現競爭條件(Race Condition) 。比如,一個線程正在往 RingBuffer 里寫入數據,還沒寫完,另一個線程就來讀取數據,這時候讀出來的數據可能就是不完整的,或者是舊的數據,這就導致了數據不一致的問題。再比如,兩個線程同時嘗試往已滿的 RingBuffer 中寫入數據,或者從空的 RingBuffer 中讀取數據,也會引發錯誤。
為了解決這些線程安全問題,常見的方法有使用鎖機制、原子操作和無鎖數據結構 。鎖機制就像是給 RingBuffer 加上了一把鎖,當一個線程要訪問 RingBuffer 時,先獲取這把鎖,其他線程就只能等待,直到鎖被釋放。這樣就能保證同一時間只有一個線程能操作 RingBuffer,避免了競爭條件。但鎖機制也有缺點,它會帶來額外的開銷,而且如果鎖使用不當,還可能會導致死鎖。
原子操作則是利用硬件提供的原子指令,保證對數據的操作是不可分割的,不會被其他線程打斷。比如,對一個整數的自增操作,如果使用原子操作,就可以保證在多線程環境下也能正確執行,不會出現數據不一致的情況。
無鎖數據結構則是一種更高級的解決方案,它通過巧妙的設計,避免了使用鎖,從而提高了并發性能。像一些基于 CAS(Compare-And-Swap)算法實現的無鎖 RingBuffer,在高并發場景下表現出色。但無鎖數據結構的實現難度較大,需要對底層原理有深入的理解 。
在實現層面,環形緩沖區通常采用數組來存儲數據,同時設置 head 和 tail 兩個指針 ——head 指向緩沖區的隊首位置,tail 則指向隊尾位置。讀取數據時,head 指針向前移動;寫入數據時,tail 指針向前移動。不過,這樣的基礎實現并不不具備線程安全性。
當多個線程同時進行讀寫操作時,需要通過同步機制來保證數據操作的正確性。但存在一種特殊場景:當只有一個讀線程和一個寫線程時,可以實現無鎖的線程安全環形緩沖區。這種情況下,通過特定的指針操作設計,無需額外的鎖機制就能避免數據競爭,確保讀寫操作的安全性。其核心思路是利用單生產者 - 單消費者模型的特性,通過指針間的邏輯關系來控制讀寫邊界,從而在無鎖情況下保證線程安全,代碼如下:
public class RingBuffer<T> {
private volatile T[] elements;
private volatile int head;
private volatile int tail;
public RingBuffer(int capacity){
this.elements=(T[])new Object[capacity];
this.head=0;
this.tail=-1;
}
private boolean isEmpty(){
return tail+1==head;
}
private boolean isFull(){
return tail+1-elements.length==head;
}
public void push(T element) throws IllegalArgumentException{
if(isFull())
throw new IllegalArgumentException("full queue");
elements[(tail+1)%elements.length]=element;
tail++;
}
public T pop() throws IllegalArgumentException{
if(isEmpty())
throw new IllegalArgumentException("empty queue");
T element=elements[head%elements.length];
head++;
return element;
}
}為什么這樣的實現能保證線程安全呢?原因在于:創建 RingBuffer 后,tail 指針僅由寫線程修改,head 指針僅由讀線程修改,且始終維持單一的讀寫線程,不存在多個線程同時寫入或同時讀取的情況,因此不會產生并發寫沖突。
不過需要注意,讀寫操作本身并非原子性的,讀操作可能穿插在寫操作過程中,反之亦然。這理論上可能引發兩個問題:讀線程在緩沖區為空時,可能讀取到尚未寫入完成的數據;寫線程在緩沖區已滿時,可能覆蓋尚未讀取的數據。
但實際中,由于我們設計了特定的操作順序 —— 寫操作時先更新數據元素(elements)再移動 tail 指針,讀操作時先讀取數據元素再移動 head 指針 —— 這就從根本上避免了上述問題。因此,這種 RingBuffer 不僅是線程安全的,還實現了無鎖設計,能獲得更高的性能表現。
Part2.RingBuffer的原理剖析
2.1核心機制:循環讀寫
RingBuffer 的核心機制是循環讀寫,這使得它能夠在有限的空間內高效地處理數據。通過特別的算法設計,RingBuffer 在邏輯上實現了一個環形的存儲區域,數據的寫入和讀取都圍繞這個環形結構進行。
假設我們有一個大小為 7 的環形緩沖區,初始時,緩沖區為空,沒有任何數據。當我們開始寫入數據時,第一個數據 1 被寫入到緩沖區的某個位置(對于環形緩沖區來說,最初的寫入位置在哪里是無關緊要的)。接著,繼續寫入數據 2 和 3,它們會依次追加到 1 之后。此時,緩沖區中的數據分布為 1、2、3。
當需要讀出數據時,根據先進先出(FIFO)的原則,最先寫入的 1 和 2 會被讀出,緩沖區中就只剩下 3。隨后,繼續向緩沖區寫入六個元素 4、5、6、7、8、9,隨著數據的不斷寫入,緩沖區逐漸被填滿。
當緩沖區已滿,如果還要寫入新的數據,就需要采取相應的處理策略。常見的策略有兩種:一種是覆蓋掉最老的數據,即丟棄最早寫入的數據,為新數據騰出空間;另一種是返回錯誤碼或者拋出異常,告知用戶緩沖區已滿,無法寫入新數據 。如果選擇覆蓋策略,當寫入兩個新元素 A 和 B 時,它們會覆蓋掉最早的 3 和 4。此時再讀出兩個元素,就會是 5 和 6,因為 3 和 4 已經被 A 和 B 覆蓋掉了。
2.2關鍵要素:讀寫索引
要實現 RingBuffer 的讀寫操作,需要以下 4 個關鍵信息:
- 內存中的實際開始位置:它可以是一片內存的頭指針,也可以是數組的第一個元素指針,用于確定緩沖區在內存中的起始地址。
- 內存中的實際結束位置:或者通過緩沖區實際空間大小,結合開始位置來計算出結束位置,以此定義緩沖區的邊界。
- 寫索引值:在緩沖區中進行寫操作時的索引值,標記下一個要寫入數據的位置。
- 讀索引值:在緩沖區中進行讀操作時的索引值,標記下一個要讀取數據的位置。
其中,讀索引和寫索引是實現循環讀寫的關鍵。它們分別標記了緩沖區進行讀操作和寫操作時的具體位置。當環形緩沖區為空時,讀索引和寫索引指向相同的位置,因為此時沒有數據,讀寫位置自然重合。當向緩沖區寫入一個元素時,元素會被寫入寫索引當前所指向的位置,然后寫索引加 1,指向下一個位置,為下一次寫入做準備。例如,先寫入元素 A,A 被存放在寫索引指向的位置,接著寫索引加 1。當再寫入一個元素 B 時,B 就會被寫入更新后的寫索引位置,然后寫索引再次加 1 。如此循環,當連續寫入 C、D、E、F、G 五個元素后,緩沖區就滿了,這時寫索引又回到了和讀索引相同的位置,這和緩沖區為空時的情況一樣,但此時緩沖區的狀態是滿的。
從緩沖區中讀出數據的過程也類似。當從緩沖區中讀出一個元素 A 時,讀索引當前所在位置的元素被讀出,然后讀索引加 1,指向下一個位置。繼續讀出元素 B 時,同樣是讀索引當前所在位置的元素被讀出,然后讀索引再加 1 。通過這種方式,讀索引和寫索引不斷移動,實現了數據的循環讀寫。
通過下面這張圖,我們可以更直觀地理解 RingBuffer 的典型讀寫過程:
 圖片
圖片
從圖中可以清晰地看到,隨著數據的寫入和讀取,讀寫索引如何在環形緩沖區中移動,以及緩沖區滿和空時的狀態變化。這種基于讀寫索引的循環讀寫機制,是 RingBuffer 高效處理數據的基礎。
Part3.RingBuffer 的應用場景
3.1數據采集與處理:忠實的數據管家
在數據采集與處理的領域中,RingBuffer 宛如一位忠實可靠的數據管家,默默守護著數據的有序流轉。隨著物聯網技術的迅猛發展,各類傳感器如繁星般遍布在我們生活的各個角落,從工業生產線上監測設備運行狀態的振動傳感器,到環境監測中檢測空氣質量的氣體傳感器 ,再到可穿戴設備里追蹤運動數據的加速度傳感器,它們無時無刻不在產生海量的數據。
然而,傳感器產生數據的速度往往與數據處理的速度難以匹配。就像在一場接力賽中,傳感器作為第一棒選手,全力奔跑,快速地將數據傳遞出去;而數據處理模塊作為后續的選手,由于處理復雜數據需要更多時間,速度相對較慢。這就導致了如果沒有一個合適的 “緩沖地帶”,數據很容易在傳遞過程中出現丟失或混亂的情況。
RingBuffer 正是解決這一問題的關鍵。以一個工業生產線上的溫度傳感器數據采集為例,傳感器每隔 10 毫秒就會采集一次溫度數據并寫入 RingBuffer。假設 RingBuffer 的大小為 100 個數據單元,寫指針會不斷地將新采集到的溫度數據按順序存入緩沖區。而數據處理程序可能因為要對數據進行復雜的分析、計算平均值、判斷是否超出閾值等操作,處理速度較慢,可能每 100 毫秒才從 RingBuffer 中讀取一次數據。
在這期間,RingBuffer 就像一個耐心的存儲倉庫,有條不紊地保存著傳感器產生的數據,確保數據不會因為處理不及時而丟失。即使在某些瞬間,傳感器數據產生的速度突然加快,RingBuffer 也能憑借其環形的特性,在緩沖區滿時,自動覆蓋最早的數據,保證始終能存儲最新的有效數據。
通過這種方式,RingBuffer 實現了數據采集與處理速度的有效平衡,為后續的數據處理提供了穩定、連貫的數據來源 ,確保整個數據處理流程的順暢進行,就如同在湍急的河流中筑起了一座堅固的堤壩,讓數據的洪流得以有序疏導。
3.2音視頻領域:流暢體驗的幕后英雄
(1)音頻處理
在音頻的世界里,RingBuffer 如同一位技藝高超的音樂指揮家,精準地掌控著每一個音符的流動,為我們帶來美妙而穩定的聽覺盛宴。無論是在音樂播放軟件中盡情享受喜愛的歌曲,還是在語音通話應用中與遠方的朋友暢所欲言,RingBuffer 都在幕后默默地發揮著關鍵作用。
以一款熱門的音樂 APP 為例,當我們點擊播放按鈕,音樂數據就開始了它在設備中的奇妙之旅。音樂文件通常存儲在磁盤或云端,在播放時需要被讀取并轉換為音頻信號輸出到揚聲器或耳機中。然而,從存儲設備讀取數據的速度可能會受到多種因素的影響,如磁盤的讀寫速度、網絡狀況等。如果沒有一個有效的緩沖機制,就可能會出現音頻卡頓、中斷的情況,嚴重影響我們的聽歌體驗。
RingBuffer 就像是一個音樂倉庫,在音樂播放前,預先將一部分音頻數據存儲其中。音頻解碼器不斷地從 RingBuffer 中讀取數據進行解碼,然后將解碼后的音頻信號發送到音頻輸出設備。同時,數據讀取模塊也持續地從存儲設備中讀取新的音頻數據寫入 RingBuffer,以保證緩沖區中有足夠的數據供應。這樣,即使在讀取數據的過程中遇到短暫的延遲,音頻解碼器依然可以從 RingBuffer 中獲取到數據,從而實現音樂的流暢播放,讓我們仿佛置身于一場完美的音樂會現場。
再看語音通話軟件,它對音頻的實時性要求極高。在通話過程中,麥克風不斷地采集我們的聲音信號,并將其轉換為數字音頻數據發送給對方。同時,我們也需要實時接收對方發送過來的音頻數據并播放出來。由于網絡傳輸存在不確定性,數據包可能會出現延遲、丟包等情況。RingBuffer 在語音通話中充當了一個穩定的橋梁,它將采集到的音頻數據暫時存儲起來,等待網絡傳輸模塊將其發送出去。在接收端,RingBuffer 則接收并緩存對方發送過來的音頻數據,確保音頻播放模塊能夠按照正確的順序和時間間隔讀取數據進行播放,避免了因網絡波動而導致的聲音斷斷續續或回聲等問題,讓我們能夠與對方進行清晰、自然的交流,仿佛彼此就在身邊。
(2)視頻處理
而在視頻領域,RingBuffer 同樣不可或缺,它就像一位高效的視頻剪輯師,巧妙地協調著視頻數據的各個環節,為我們呈現出流暢、精彩的視覺畫面。從在線視頻平臺上的海量影視劇,到視頻編輯軟件中創作者們精心雕琢的作品,RingBuffer 都在其中發揮著重要的支撐作用。
當我們在在線視頻平臺上觀看視頻時,視頻數據以流的形式從服務器傳輸到我們的設備。視頻流包含了視頻幀、音頻數據以及一些元信息等。由于網絡帶寬的限制和波動,視頻數據的傳輸速度并非恒定不變。如果直接將接收到的視頻數據進行播放,很容易出現畫面卡頓、跳幀等現象。RingBuffer 在這里起到了關鍵的緩沖和調節作用。它就像一個巨大的視頻素材庫,將接收到的視頻幀依次存儲起來。
視頻播放模塊按照一定的幀率從 RingBuffer 中讀取視頻幀進行解碼和顯示,同時,網絡接收模塊持續地將新的視頻幀寫入 RingBuffer。通過這種方式,即使網絡傳輸出現短暫的不穩定,RingBuffer 也能保證視頻播放模塊有足夠的視頻幀可供播放,從而實現視頻的流暢播放,讓我們沉浸在精彩的劇情中,感受視覺的震撼。
對于視頻編輯軟件來說,RingBuffer 更是提高編輯效率和保證視頻質量的重要工具。在視頻編輯過程中,創作者需要對視頻進行剪輯、添加特效、字幕等操作。這些操作往往需要頻繁地讀取和處理視頻幀數據。RingBuffer 可以預先加載一部分視頻幀到緩沖區中,當編輯軟件需要讀取某一幀時,能夠快速地從 RingBuffer 中獲取,大大減少了數據讀取的時間,提高了編輯的流暢性。同時,在進行一些復雜的特效處理或多軌道編輯時,RingBuffer 可以存儲中間處理結果,方便后續的進一步處理和合成,確保整個視頻編輯過程高效、穩定地進行,助力創作者將自己的創意完美地呈現在觀眾面前。
3.3網絡通信:數據傳輸的智慧樞紐
在網絡通信的廣袤天地里,RingBuffer 宛如一座智慧的樞紐,有條不紊地管理著數據的流動,確保信息能夠準確、高效地在網絡中傳輸。無論是我們日常使用的手機上網瀏覽新聞、觀看視頻,還是企業級服務器之間的數據交互,RingBuffer 都在其中扮演著不可或缺的角色。
當網絡數據在不同設備之間傳輸時,由于網絡狀況的復雜性和不確定性,數據的發送和接收速度往往存在差異 。就像在一條繁忙的高速公路上,車輛的行駛速度時快時慢,時而擁堵,時而暢通。如果沒有一個有效的緩沖機制,數據很容易在傳輸過程中出現丟失、亂序或處理不及時的情況。RingBuffer 的出現,完美地解決了這一難題。它就像高速公路旁的一個臨時停車場,當數據發送速度較快而接收方處理速度較慢時,數據可以暫時存儲在 RingBuffer 中等待處理;當網絡狀況不佳,數據接收出現延遲時,RingBuffer 中的數據也能保證接收方有足夠的數據進行處理,從而實現網絡通信的穩定和流暢。
以一個網絡服務器為例,它需要同時處理大量客戶端的請求。當客戶端發送請求數據包時,服務器的網卡首先接收這些數據包,并將它們寫入 RingBuffer 中。服務器的處理程序會從 RingBuffer 中讀取數據包,解析請求內容,并返回相應的響應。由于客戶端請求的并發量可能很大,而服務器處理能力有限,RingBuffer 就起到了緩沖的作用,防止數據包因為處理不及時而丟失。同時,RingBuffer 也保證了數據包按照接收的順序被處理,維護了通信的正確性。
再看路由器,作為網絡通信的關鍵節點,它需要對大量的網絡數據包進行轉發和路由選擇 。當路由器接收到來自不同網絡接口的數據包時,會將這些數據包存儲在 RingBuffer 中。路由器的路由算法會根據數據包的目的地址,從 RingBuffer 中讀取數據包并進行轉發。在這個過程中,RingBuffer 不僅能夠平衡不同網絡接口的數據傳輸速度差異,還能在網絡擁塞時,暫時存儲數據包,避免數據包的丟失,確保整個網絡的正常運行。
3.4多線程編程:線程協作的橋梁
在多線程編程的復雜世界里,線程之間的協作與數據共享就像一場精心編排的舞蹈,每個線程都有自己的節奏和任務,而 RingBuffer 則如同一位默契的舞伴,巧妙地協調著線程間的數據交換,成為線程協作的堅固橋梁。
在多線程環境中,不同線程之間經常需要傳遞和共享數據。然而,傳統的數據共享方式往往面臨諸多挑戰,如線程安全問題、數據同步困難以及頻繁的鎖競爭導致的性能下降等 。RingBuffer 的出現,為這些問題提供了優雅的解決方案。它作為一個線程安全的共享數據緩沖區,允許不同線程在不需要頻繁加鎖的情況下,高效地進行數據的寫入和讀取操作,大大提高了多線程程序的性能和穩定性。
以經典的生產者 - 消費者模型為例,這是多線程編程中一個非常常見的場景。在這個模型中,生產者線程負責生成數據并將其放入緩沖區,消費者線程則從緩沖區中取出數據進行處理。就像在一家面包店里,面包師傅(生產者)不停地制作面包(數據)并放入貨架(RingBuffer),而顧客(消費者)則從貨架上取走面包享用。如果沒有一個合適的緩沖區,面包師傅可能會因為貨架已滿而無處存放新制作的面包,顧客也可能因為貨架為空而無面包可買。
RingBuffer 在這里就充當了一個智能的貨架,它具有固定的大小,生產者線程將數據寫入 RingBuffer,當緩沖區滿時,新的數據會覆蓋最早的數據;消費者線程從 RingBuffer 中讀取數據,按照寫入的順序依次獲取。通過這種方式,生產者和消費者線程可以獨立地運行,無需擔心數據的同步和競爭問題,極大地提高了程序的執行效率和并發性能。
為了更直觀地理解,我們來看一段簡單的 C++代碼示例:
#include <iostream>
#include <vector>
class RingBuffer {
public:
RingBuffer(int size) : buffer(size), writeIndex(0), readIndex(0), count(0) {}
void write(int value) {
if (count == buffer.size()) {
// 緩存已滿,舊數據即將被覆蓋
std::cout << "Buffer is full. Overwriting oldest value." << std::endl;
readIndex = (readIndex + 1) % buffer.size();
} else {
count++;
}
buffer[writeIndex] = value;
writeIndex = (writeIndex + 1) % buffer.size();
}
int read() {
if (count == 0) {
// 緩存為空
std::cout << "Buffer is empty." << std::endl;
return -1;
}
int value = buffer[readIndex];
readIndex = (readIndex + 1) % buffer.size();
count--;
return value;
}
private:
std::vector<int> buffer;
int writeIndex;
int readIndex;
int count;
};
int main() {
RingBuffer rb(5);
rb.write(1);
rb.write(2);
rb.write(3);
rb.write(4);
rb.write(5);
rb.write(6); // 這里會覆蓋最舊的數據
std::cout << "Reading: " << rb.read() << std::endl;
std::cout << "Reading: " << rb.read() << std::endl;
std::cout << "Reading: " << rb.read() << std::endl;
std::cout << "Reading: " << rb.read() << std::endl;
std::cout << "Reading: " << rb.read() << std::endl;
return 0;
}(1)構造函數:
RingBuffer(int size) : buffer(size), writeIndex(0), readIndex(0), count(0) {}構造函數接受一個參數size,用于初始化環形緩沖區的大小。它創建了一個大小為size的std::vector<int>類型的buffer,用于存儲數據。同時,將寫指針writeIndex、讀指針readIndex初始化為 0,表示緩沖區的起始位置。count變量用于記錄當前緩沖區中存儲的數據個數,初始值為 0。
(2)寫入方法:
void write(int value) {
if (count == buffer.size()) {
// 緩存已滿,舊數據即將被覆蓋
std::cout << "Buffer is full. Overwriting oldest value." << std::endl;
readIndex = (readIndex + 1) % buffer.size();
} else {
count++;
}
buffer[writeIndex] = value;
writeIndex = (writeIndex + 1) % buffer.size();
}寫入方法write接受一個參數value,表示要寫入的數據。首先,檢查count是否等于緩沖區的大小buffer.size(),如果相等,說明緩沖區已滿。此時,打印提示信息 “Buffer is full. Overwriting oldest value.”,并將讀指針readIndex向后移動一個位置,通過(readIndex + 1) % buffer.size()實現循環移動。如果緩沖區未滿,則將count加 1,表示緩沖區中數據個數增加。然后,將數據value寫入到寫指針writeIndex指向的位置,即buffer[writeIndex] = value。最后,將寫指針writeIndex向后移動一個位置,同樣通過(writeIndex + 1) % buffer.size()實現循環移動。
(3)讀取方法:
int read() {
if (count == 0) {
// 緩存為空
std::cout << "Buffer is empty." << std::endl;
return -1;
}
int value = buffer[readIndex];
readIndex = (readIndex + 1) % buffer.size();
count--;
return value;
}讀取方法read用于從緩沖區中讀取數據。首先,檢查count是否為 0,如果為 0,說明緩沖區為空。此時,打印提示信息 “Buffer is empty.”,并返回 - 1,表示沒有數據可讀。如果緩沖區不為空,則從讀指針readIndex指向的位置讀取數據,即int value = buffer[readIndex]。然后,將讀指針readIndex向后移動一個位置,通過(readIndex + 1) % buffer.size()實現循環移動。接著,將count減 1,表示緩沖區中數據個數減少。最后,返回讀取到的數據value。
RingBuffer 的關鍵作用:
- 解耦生產者和消費者:RingBuffer 在生產者和消費者之間構建了一道靈活的橋梁,成功地實現了兩者的解耦。生產者只需將數據寫入 RingBuffer,而無需關心數據何時被消費以及被誰消費;消費者也只需從 RingBuffer 中讀取數據,無需了解數據的生成過程和生產者的狀態 。就像在上述面包店的例子中,面包師傅將面包放上貨架后,就可以繼續制作下一批面包,而不必等待顧客前來購買。顧客在自己方便的時候來到面包店,從貨架上挑選面包,整個過程中面包師傅和顧客之間沒有直接的依賴關系。這種解耦特性使得生產者和消費者的代碼可以獨立開發、維護和擴展,大大提高了系統的可維護性和可擴展性 。在一個分布式系統中,生產者可能是一個負責收集日志數據的模塊,消費者可能是多個不同的數據分析模塊。通過 RingBuffer,日志收集模塊可以將日志數據源源不斷地寫入 RingBuffer,而各個數據分析模塊可以根據自己的需求從 RingBuffer 中讀取數據進行分析,彼此之間互不干擾。
- 平衡生產和消費速度:在實際的多線程應用中,生產者和消費者的執行速度往往存在差異。有時生產者生成數據的速度非常快,而消費者處理數據的速度相對較慢,這就可能導致數據的積壓;反之,如果消費者處理數據的速度過快,而生產者生成數據的速度跟不上,消費者就可能處于等待狀態,造成資源的浪費 。RingBuffer 作為一個緩沖區,具有強大的存儲能力,可以有效地平衡這種速度差異。當生產者生成數據的速度超過消費者的處理速度時,多余的數據可以暫時存儲在 RingBuffer 中,避免數據的丟失。當消費者處理數據的速度較快時,也可以從 RingBuffer 中及時獲取數據,不會因為等待數據而閑置 。還是以面包店為例,如果在某個時間段內,面包師傅制作面包的速度非常快,貨架上的面包數量逐漸增多。當貨架快滿時,新制作的面包可以暫時存放在倉庫中(相當于 RingBuffer 的溢出處理)。而當顧客購買面包的速度較快,貨架上的面包數量減少時,倉庫中的面包可以及時補充到貨架上,保證顧客隨時都能買到面包 。
- 提升并發性能:在多線程環境下,鎖競爭是影響系統并發性能的一個重要因素。傳統的共享數據結構在進行讀寫操作時,通常需要使用鎖來保證數據的一致性和線程安全,這就導致了多個線程在競爭鎖的過程中會產生阻塞和上下文切換,大大降低了系統的并發性能 。RingBuffer 采用了一系列巧妙的設計,有效地避免了頻繁的鎖競爭。例如,一些 RingBuffer 的實現利用了原子操作來更新讀寫指針,確保了在多線程環境下數據的安全讀寫,同時避免了使用鎖帶來的開銷 。這種無鎖或輕量級鎖的設計使得生產者和消費者線程可以同時進行讀寫操作,極大地提高了系統的并發性能。在一個高并發的消息處理系統中,使用 RingBuffer 作為消息隊列,生產者線程可以快速地將消息寫入 RingBuffer,消費者線程可以同時從 RingBuffer 中讀取消息進行處理,而無需頻繁地獲取和釋放鎖,從而大大提高了消息處理的效率和系統的吞吐量 。
3.5數據庫優化:提升性能的秘密武器
在數據庫的領域中,性能優化始終是一場至關重要的戰役,而 RingBuffer 則像是一把秘密武器,為數據庫的高效運行提供了強大的支持。以 PostgreSQL 數據庫為例,RingBuffer 在處理批量操作時發揮著關鍵作用,能夠顯著提升數據庫的性能。
在傳統的數據庫緩沖管理中,當執行如全表掃描、VACUUM(清理和回收數據庫空間的操作)、批量寫入等需要訪問大量數據的操作時,存在一些潛在的問題。想象一下,數據庫的主緩沖池就像一個繁忙的圖書館書架,里面存放著各種常用的數據(緩存頁),方便快速取用。當進行全表掃描或 VACUUM 操作時,大量臨時數據需要被讀取和處理 ,就如同突然來了一大批新書要臨時放在書架上。這些臨時數據會占用主緩沖池的空間,將原本存儲在其中的熱點數據(經常被查詢的數據)擠出書架,導致后續查詢時緩存命中率降低,就像讀者想找的常用書被放在了難以找到的地方,只能重新從遠處的倉庫(磁盤)中讀取,增加了讀取時間和 I/O 負載 。
而 RingBuffer 的出現,巧妙地解決了這些問題。它就像圖書館里專門為臨時存放新書而設立的一個獨立小書架。當執行批量操作時,RingBuffer 會分配獨立的臨時緩沖區,將這些操作所涉及的數據存儲在這個臨時緩沖區中,而不是直接占用主緩沖池 。這樣一來,就避免了主緩沖池被大量臨時數據污染,確保了熱點數據能夠始終留在主緩沖池中,提高了后續查詢的緩存命中率。
RingBuffer 的實現機制也十分巧妙。它會根據操作類型分配固定大小的臨時緩沖區 ,比如在進行批量讀操作(如大表順序掃描)時,通常會分配 256KB 的緩沖區,這個大小恰好適合 L2 緩存,能夠提升操作系統緩存到共享緩存的傳輸效率;在批量寫操作(如 COPY FROM、CREATE TABLE AS 等)時,會分配 16MB 的緩沖區,以減少 WAL(Write-Ahead Logging,預寫式日志)日志的刷新頻率,提高寫入效率;在進行 VACUUM 操作時,同樣分配 256KB 的緩沖區,避免全表掃描時對主緩沖池的緩存污染。
同時,RingBuffer 采用簡化的時鐘掃描(Clock Sweep)策略管理緩沖區,優先淘汰那些未被頻繁訪問的頁面,確保臨時數據不會長期占用內存資源。并且,批量操作產生的臟頁(被修改但尚未寫入磁盤的數據頁)由后端進程直接寫入磁盤,減少了后臺寫入進程(Bgwriter)的壓力,就像圖書館工作人員直接將不需要的臨時書籍放回倉庫,而不是依賴其他忙碌的工作人員來處理。
在實際應用中,合理配置 RingBuffer 的參數對于提升數據庫性能至關重要。可以通過設置polar_ring_buffer_bulkread_size(批量讀緩沖區大小,默認 256KB)、polar_ring_buffer_bulkwrite_size(批量寫緩沖區大小,默認 16MB)、polar_ring_buffer_vacuum_size(VACUUM 緩沖區大小,默認 128MB)等參數來調整 RingBuffer 的性能。例如,在高 I/O 環境中,如果寫入操作頻繁,可以適當增大polar_ring_buffer_bulkwrite_size的值,以減少刷臟次數,提高寫入性能;同時,要結合主緩沖池的參數(如shared_buffers主緩沖池大小、effective_cache_size有效緩存大小)進行調整,確保主緩沖池與 Ring Buffer 能夠協同工作,避免內存競爭。
通過使用 RingBuffer,數據庫在處理批量操作時的性能得到了顯著提升,不僅減少了 I/O 負載,提高了緩存命中率,還優化了內存管理,為數據庫的穩定、高效運行奠定了堅實的基礎。它在數據庫領域中的應用,充分展示了其在解決復雜數據處理問題時的強大能力和獨特優勢。
Part4.無鎖Ringbuffer實現
在多線程共享程序中,為保障共享變量的 load - modify - store 代碼序列的功能正確性,常采用 mutex 進行保護。由于多個線程并發操作共享變量時,若缺乏有效管控,會引發數據不一致等問題。mutex 的工作機制是,在某線程訪問共享變量執行 “讀 - 修改 - 寫” 操作前,先獲取鎖,操作完成后釋放鎖。在此期間,其他線程若嘗試獲取鎖,只能處于等待狀態,直至鎖被釋放,以此確保同一時刻僅有一個線程能對共享變量進行操作 。
然而,mutex 在實際應用中存在明顯弊端。當多線程對 mutex 激烈競爭時,會帶來顯著的性能開銷。例如,在高并發場景下,頻繁的線程上下文切換、鎖的獲取與釋放操作,會消耗大量的 CPU 時間和系統資源,進而降低整個程序的執行效率 。鑒于此,探索無鎖的 Ringbuffer 實現具有重要意義。無鎖的 Ringbuffer 通過特定的數據結構設計和原子操作,可避免 mutex 帶來的性能瓶頸。在這種實現中,線程間無需等待鎖的釋放,而是利用原子指令對共享變量進行操作,從而提升程序在多線程環境下的執行效率和并發性能 。
4.1定義類結構
在 C++ 中,我們可以通過定義一個類來實現 RingBuffer。以下是 RingBuffer 類的基本結構,其中包含了一個用于存儲數據的std::vector容器,以及用于記錄寫入位置的writeIndex、讀取位置的readIndex和緩沖區中元素數量的count:
#include <iostream>
#include <vector>
class RingBuffer {
public:
// 構造函數,初始化緩沖區大小、讀寫索引和元素計數
RingBuffer(int size) : buffer(size), writeIndex(0), readIndex(0), count(0) {}
// 寫入數據的函數聲明
void write(int value);
// 讀取數據的函數聲明
int read();
private:
// 存儲數據的緩沖區
std::vector<int> buffer;
// 寫入索引,指示下一個寫入位置
int writeIndex;
// 讀取索引,指示下一個讀取位置
int readIndex;
// 緩沖區中當前元素的數量
int count;
};4.2寫入操作實現
接下來是write函數的具體實現。當向 RingBuffer 中寫入數據時,首先要檢查緩沖區是否已滿。如果已滿,就需要覆蓋最早寫入的數據,即將讀索引向前移動一位,然后再將新數據寫入當前寫索引位置。如果緩沖區未滿,則直接將數據寫入當前寫索引位置,并更新寫索引和元素計數:
void RingBuffer::write(int value) {
if (count == buffer.size()) {
// 緩沖區已滿,覆蓋最早的數據
std::cout << "Buffer is full. Overwriting oldest value." << std::endl;
readIndex = (readIndex + 1) % buffer.size();
} else {
// 緩沖區未滿,增加元素計數
count++;
}
// 將數據寫入當前寫索引位置
buffer[writeIndex] = value;
// 更新寫索引,指向下一個位置
writeIndex = (writeIndex + 1) % buffer.size();
}4.3讀取操作實現
read函數用于從 RingBuffer 中讀取數據。在讀取數據之前,需要先檢查緩沖區是否為空。如果為空,返回一個特定的值(這里返回 - 1)并輸出提示信息。如果緩沖區不為空,則返回當前讀索引位置的數據,并更新讀索引和元素計數:
int RingBuffer::read() {
if (count == 0) {
// 緩沖區為空
std::cout << "Buffer is empty." << std::endl;
return -1;
}
// 讀取當前讀索引位置的數據
int value = buffer[readIndex];
// 更新讀索引,指向下一個位置
readIndex = (readIndex + 1) % buffer.size();
// 減少元素計數
count--;
return value;
}通過以上代碼,我們實現了一個簡單的 RingBuffer。在實際應用中,還可以根據具體需求對其進行擴展和優化,例如添加更多的操作函數、處理線程安全問題等。
Part5.SPSC場景下的原子操作實現
5.1并發編程
并發編程允許程序在同一時間執行多個任務,充分利用多核處理器的優勢,提高程序的性能和響應速度。然而,并發編程也帶來了一系列挑戰,其中線程安全問題是最為關鍵的。
線程安全是指當多個線程訪問某個類或代碼段時,不會出現數據競爭、狀態不一致或其他意外行為,確保程序在多線程環境下的正確性和穩定性。簡單來說,就是多個線程同時訪問共享資源時,不會出現數據被破壞、讀取到臟數據等問題。例如,在一個多線程的銀行轉賬系統中,如果沒有正確處理線程安全問題,可能會出現兩個線程同時對同一個賬戶進行取款操作,導致賬戶余額出現錯誤。
在并發編程中,有多種場景需要考慮線程安全,其中單生產者單消費者(Single Producer Single Consumer,SPSC)場景是一種常見且相對簡單的并發模型。在 SPSC 場景中,只有一個生產者線程負責生成數據并將其放入共享數據結構中,同時只有一個消費者線程從該共享數據結構中取出數據進行處理。這種場景在許多實際應用中都有廣泛的應用,比如:
- 消息隊列:生產者線程將消息發送到消息隊列中,消費者線程從隊列中取出消息進行處理。例如,在一個分布式系統中,各個服務之間通過消息隊列進行通信,生產者服務將任務消息發送到隊列,消費者服務從隊列中獲取任務并執行。
- 日志系統:生產者線程將日志信息寫入日志緩沖區,消費者線程從緩沖區讀取日志信息并寫入磁盤。這樣可以避免頻繁的磁盤 I/O 操作,提高系統性能。
- 數據處理流水線:在數據處理流程中,前一個階段的線程作為生產者,將處理好的數據傳遞給下一個階段的線程(消費者)進行進一步處理。例如,在圖像識別系統中,圖像采集線程作為生產者將采集到的圖像數據傳遞給圖像識別線程(消費者)進行識別處理。
5.2原子操作
在多線程編程的領域中,原子操作是保障線程安全的關鍵基石,它就像是一個堅不可摧的護盾,為共享數據的操作保駕護航。原子操作,從定義上來說,是指那些在執行過程中不可被中斷的操作,就如同一個緊密咬合的齒輪組,一旦啟動,就會完整地運轉到結束,不會在中途被其他線程的干擾而停止或改變。這種不可分割性是原子操作的核心特性,也是它能夠確保線程安全的根本原因。
以對一個共享變量的自增操作 x++ 為例,在非原子操作的情況下,這個看似簡單的操作實際上包含了讀取變量值、增加 1、再將結果寫回變量這三個步驟。當多個線程同時執行這個操作時,就可能會出現數據競爭的問題。假設線程 A 讀取了變量 x 的值為 10,此時線程 B 也讀取了 x 的值 10,然后線程 A 將 x 的值增加 1 變為 11 并寫回,接著線程 B 也將自己讀取的值增加 1 變為 11 并寫回。原本期望經過兩次自增操作后 x 的值應該是 12,但實際上卻變成了 11,這就是因為操作沒有原子性導致的數據不一致問題。
而原子操作則能夠避免這種情況的發生。當使用原子自增操作時,系統會確保整個自增過程是一個不可分割的整體,要么所有步驟都成功執行,要么都不執行。這樣,無論有多少個線程同時嘗試對共享變量進行原子自增操作,最終的結果都能保證是正確的,從而有效地避免了數據競爭和不一致的問題,確保了多線程環境下共享數據操作的正確性和穩定性 ,為并發編程提供了堅實的保障。
5.3原子操作在 SPSC 隊列中的應用
在 SPSC 場景中,原子操作的應用非常廣泛,尤其是在實現高效的 SPSC 隊列時。SPSC 隊列是一種數據結構,它允許一個生產者線程將數據放入隊列,同時允許一個消費者線程從隊列中取出數據。由于只有一個生產者和一個消費者,因此可以使用一些特殊的技巧來實現高效的線程安全。
一種常見的實現方式是使用環形緩沖區(Circular Buffer)。環形緩沖區是一個固定大小的數組,它被視為一個環形結構。生產者和消費者通過移動指針來訪問緩沖區中的數據。當生產者向緩沖區中寫入數據時,它會將數據寫入當前寫指針指向的位置,然后將寫指針向后移動一位。如果寫指針到達了緩沖區的末尾,它會回到緩沖區的開頭。消費者從緩沖區中讀取數據的過程類似,它會從當前讀指針指向的位置讀取數據,然后將讀指針向后移動一位 。
為了確保線程安全,需要使用原子操作來更新讀指針和寫指針。以 C++ 代碼為例:
#include <atomic>
#include <iostream>
template<typename T, size_t Capacity>
class SPSCQueue {
private:
T buffer[Capacity];
std::atomic<size_t> readIndex{0};
std::atomic<size_t> writeIndex{0};
public:
bool enqueue(const T& item) {
size_t currentWriteIndex = writeIndex.load(std::memory_order_relaxed);
size_t nextWriteIndex = (currentWriteIndex + 1) % Capacity;
if (nextWriteIndex == readIndex.load(std::memory_order_acquire)) {
// 隊列已滿
return false;
}
buffer[currentWriteIndex] = item;
writeIndex.store(nextWriteIndex, std::memory_order_release);
return true;
}
bool dequeue(T& item) {
size_t currentReadIndex = readIndex.load(std::memory_order_relaxed);
if (currentReadIndex == writeIndex.load(std::memory_order_acquire)) {
// 隊列已空
return false;
}
item = buffer[currentReadIndex];
readIndex.store((currentReadIndex + 1) % Capacity, std::memory_order_release);
return true;
}
};在這段代碼中,enqueue函數負責將數據寫入隊列,dequeue函數負責從隊列中讀取數據。readIndex和writeIndex分別表示讀指針和寫指針,它們都是std::atomic<size_t>類型,確保了在多線程環境下的原子操作。
在enqueue函數中,首先讀取當前的寫指針currentWriteIndex,并計算下一個寫指針的位置nextWriteIndex。然后,通過std::memory_order_acquire內存序讀取讀指針readIndex,判斷隊列是否已滿。如果隊列未滿,則將數據寫入當前寫指針位置,并通過std::memory_order_release內存序更新寫指針。
dequeue函數的操作類似,先讀取當前讀指針currentReadIndex,通過std::memory_order_acquire內存序讀取寫指針writeIndex,判斷隊列是否為空。若不為空,則從當前讀指針位置讀取數據,并通過std::memory_order_release內存序更新讀指針。
這種內存序的使用確保了數據的一致性和可見性。std::memory_order_release操作會將之前的寫操作對其他線程可見,而std::memory_order_acquire操作會確保在讀取指針之前,之前的寫操作都已完成,從而避免了數據競爭和不一致的問題。
5.4解決 ABA 問題
在使用原子操作時,可能會遇到 ABA 問題。ABA 問題是指當一個線程讀取一個值 A,然后另一個線程將該值修改為 B,接著又將其改回 A。第一個線程在進行 CAS(Compare-And-Swap)操作時,會認為該值沒有發生變化,但實際上它已經被修改過了。
以一個簡單的鏈表刪除操作為例,假設鏈表結構如下:節點 A -> 節點 B -> 節點 C 。線程 1 想要刪除節點 A,它首先讀取到節點 A 的指針,然后準備進行刪除操作。此時,線程 2 介入,刪除了節點 A 和節點 B,并重新插入了一個新的節點 A,鏈表變為:新節點 A -> 節點 C 。當線程 1 繼續執行刪除操作時,它會發現當前節點 A 的指針與它之前讀取的一致,于是執行 CAS 操作成功,但實際上它刪除的是線程 2 新插入的節點 A,而不是原來的節點 A,這就導致了數據結構的錯誤。
ABA 問題在 SPSC 隊列中也可能發生,特別是在涉及指針操作時,會導致數據丟失或錯誤的刪除操作。為了解決 ABA 問題,可以使用版本計數器或標記刪除策略。
使用版本計數器的方法是,每次對數據進行修改時,都增加一個版本號。在進行 CAS 操作時,不僅要比較值,還要比較版本號。只有當值和版本號都匹配時,才執行操作。以下是一個使用版本計數器解決 ABA 問題的 C++ 示例代碼:
#include <atomic>
#include <iostream>
struct VersionedData {
int value;
int version;
};
std::atomic<VersionedData*> sharedData(nullptr);
void updateData() {
VersionedData* oldData;
VersionedData* newData;
do {
oldData = sharedData.load();
if (!oldData) {
newData = new VersionedData{1, 1};
} else {
newData = new VersionedData{oldData->value + 1, oldData->version + 1};
}
} while (!sharedData.compare_exchange_weak(oldData, newData));
delete oldData;
}
int main() {
// 模擬多線程操作
std::thread t1(updateData);
std::thread t2(updateData);
t1.join();
t2.join();
VersionedData* finalData = sharedData.load();
if (finalData) {
std::cout << "Final value: " << finalData->value << ", Version: " << finalData->version << std::endl;
delete finalData;
}
return 0;
}在上述代碼中,VersionedData結構體包含了數據值value和版本號version。sharedData是一個指向VersionedData的原子指針。updateData函數中,通過compare_exchange_weak進行 CAS 操作時,會同時比較指針和版本號,只有兩者都匹配才會更新,從而有效避免了 ABA 問題。
另一種解決 ABA 問題的策略是標記刪除策略,也稱為 “墓碑”(Tombstone)機制。當需要刪除一個元素時,不是立即將其從數據結構中移除,而是標記為已刪除(例如設置一個刪除標志位)。在后續的操作中,跳過這些被標記為已刪除的元素,只有在沒有其他線程訪問這些元素時,才真正將它們從數據結構中移除。例如,在一個鏈表結構中,當刪除一個節點時,將節點的isDeleted標志位設為true,遍歷鏈表時,遇到isDeleted為true的節點就跳過,這樣可以避免 ABA 問題中錯誤地操作已刪除并重新插入的數據 。
通過采用版本計數器或標記刪除策略等方法,可以有效地解決原子操作中的 ABA 問題,確保在 SPSC 場景下數據操作的正確性和線程安全性 。