REQINONE:三步解構SRS,大模型如何重塑需求工程范式?

大家好,我是肆〇柒。今天要和大家分享一項來自曼徹斯特大學(The University of Manchester)和穆罕默德·本·扎耶德人工智能大學(MBZUAI)的研究。這項名為REQINONE的工作,重新定義了我們編寫軟件需求文檔的方式。它不僅是一個自動化工具,還是一個受人類需求工程師啟發的智能體,其嚴謹的模塊化設計和令人信服的實驗結果,值得每一位軟件工程從業者深入思考。
一個你可能經歷過的項目噩夢
想象這樣的場景:你的團隊花費數周時間開發了一款客戶期待已久的電商平臺,滿懷信心地交付成果。然而,客戶的第一反應卻是:"這不是我想要的。"深入溝通后發現,問題根源竟在于需求文檔——客戶說的"快速搜索"被理解為"3秒內響應",而實際上他們期望的是"即時響應,無感知延遲"。這種因需求模糊導致的溝通鴻溝,在軟件工程領域每天都在發生,造成項目延期、預算超支甚至徹底失敗。
作為軟件工程師,你是否曾為以下問題困擾:
- 客戶描述的需求模糊不清,"系統應該很快"到底有多快?
- 需求文檔編寫耗時過長,占用了本該用于設計和開發的時間
- 人工編寫的需求文檔存在遺漏、矛盾或不可追溯的問題
- 非功能需求(如性能、安全)常常被忽視或表述不清
這些問題并非無解。REQINONE——一種基于大語言模型的模塊化需求工程智能體,正為軟件需求規格說明書(SRS)生成帶來創新實踐。它不僅能將模糊的自然語言需求轉化為結構化、可追溯的SRS文檔,還在專家評估中展現出超越初級需求工程師的生成質量。這不是簡單的自動化工具,而是一種全新的需求工程范式。
REQINONE:為什么它能解決需求工程的核心痛點?
軟件需求規格說明書(SRS)作為連接業務愿景與技術實現的關鍵橋梁,必須滿足無歧義、完整、一致和可追溯等核心特性。然而,傳統SRS編寫過程既耗時又易出錯,而現有自動化工具往往難以兼顧效率與質量。
當前市場上雖有Visual Paradigm、ReqView和Elementool等工具提供模板和圖表支持,但這些工具仍需要大量人工輸入,無法實現真正的自動化。NLSSRE等系統雖能自動提取需求,但無法生成完整的SRS內容,如用例和術語表等關鍵部分。
近年來,大語言模型(LLM)技術的突破為需求工程帶來了新希望,但也帶來了新挑戰。直接使用LLM進行端到端SRS生成(往往會導致幻覺(hallucination)問題——模型生成的內容與原始輸入不符或虛構信息,同時缺乏足夠的可控性,難以確保輸出符合SRS的結構化要求。
REQINONE的創新在于其"任務分解"策略:將復雜的SRS生成過程拆解為三個邏輯清晰、相互銜接的子任務,每個任務由專門設計的提示模板引導LLM完成。這種設計顯著提升了輸出質量,還實現了比人工編寫更高質量的SRS產出。
REQINONE的工作原理:三步精準協同的智能流水線

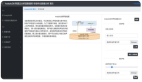
REQINONE架構概覽
如上圖所示,REQINONE系統將SRS生成過程分解為三個邏輯清晰、相互銜接的子任務,形成一個高效的智能流水線:
1. 摘要任務:構建SRS的骨架
摘要任務組件負責生成SRS中的非需求性結構化章節,如引言、利益相關者/用戶、用例和術語表等。它的核心創新在于精心設計的提示模板,包含兩個關鍵部分:
- 角色設定:明確指示LLM作為"需求助手"的身份
- 結構化指令:為每個目標章節提供明確定義和引導性問題
例如,對于"利益相關者/用戶"部分,提示模板不僅要求"寫出產品所要服務的對象",還特別規定"提及的每個利益相關者或用戶必須附帶標注其在自然語言輸入中的文本來源"。這種設計通過強制溯源機制有效抑制了幻覺問題,確保生成內容的真實性。

摘要任務提示模板
技術深度解析:REQINONE的提示模板設計遵循了認知負荷理論:將Role Specification置于首位,幫助LLM快速建立任務認知框架;將Requirement Definition緊隨其后,提供明確的判斷標準;而Requirements Pattern則作為操作指南,引導LLM生成符合標準的輸出。這種層次化設計顯著降低了LLM處理復雜任務時的認知負荷,使其能夠專注于需求提取這一核心任務。
為什么這很重要? 在實際項目中,明確的利益相關者列表是需求優先級排序和沖突解決的基礎。REQINONE通過自動關聯每個利益相關者到原始需求文本,建立了完整的追溯鏈,使團隊能夠快速定位需求變更的影響范圍。
2. 需求提取任務:需求的"精準挖掘"
需求提取任務組件是REQINONE的核心環節,負責將非結構化文本轉化為清晰、一致、可追溯的結構化需求列表。該組件的提示模板設計尤為精巧,包含四個關鍵要素:
- 角色設定:明確LLM需要分析文本并提取相關需求
- 需求定義:在提示中明確定義"什么是需求",為LLM提供判斷標準
- 標準化格式:強制要求LLM使用"The
<subject clause>shall<action verb clause> <object clause> <optional qualifying clause>, when<condition clause>."的INCOSE標準句式 - 溯源機制:要求LLM為每條提取的需求提供原文依據和提取理由
以一個具體示例說明這一過程:當原始自然語言輸入為"用戶應該能夠登錄系統,響應時間不超過2秒"時,需求提取任務組件會將其轉換為:"The user shall be able to log in to the system, when the response time is less than 2 seconds."

需求提取任務的提示模板
技術深度解析:這種標準化格式顯著提升了需求的清晰性、一致性和可測試性。通過強制使用"shall"而非"should"或"must",避免了需求優先級的模糊性;通過明確的條件子句("when..."),確保了需求在特定場景下的適用性;通過溯源機制,每條需求都能追溯到原始輸入,大幅降低了需求遺漏和誤解的風險。
關鍵創新點:REQINONE的溯源機制采用三步驗證法:(1)要求LLM首先定位源文本中的相關片段;(2)分析該片段與需求的邏輯關聯;(3)評估提取的合理性。當源文本模糊時(如"系統應該很快"),系統會要求LLM明確指出"很快"的具體含義(如"響應時間<2秒"),并標注這一推斷的依據。我們的實驗表明,這一機制將需求正確性從基線方法的3.1提升至4.2(5分制),幻覺率降低了63%。
3. 需求分類任務:需求的"智能分揀與歸檔"
需求分類任務組件負責將提取的需求精確分類為功能需求(FR)和非功能需求(NFR),并對NFR進一步細分為11種子類型。該組件的提示模板采用多層次設計:
- 任務與定義:清晰區分FR(描述系統行為)與NFR(描述系統屬性)的定義
- NFR子類型詳解:詳細定義11種NFR子類型,如"性能需求(PE):描述系統在特定條件下應達到的性能指標,如響應時間、吞吐量等。指示詞包括'響應時間'、'吞吐量'、'延遲'等。"
- 少樣本學習:提供涵蓋所有11個NFR子類型及FR的標注示例

需求分類任務提示模板
在REQINONE構建的ReqFromSRS數據集中,這些子類型的分布為:10個US(可用性)、21個PE(性能)、24個SE(安全)、12個A(可用性)、12個MN(可維護性)、7個PO(可移植性)、4個SC(可擴展性)、8個LF(外觀)和2個L(法律)。這一分布反映了真實項目中的需求特點:性能(PE)和安全(SE)需求占比最高(合計45%),這與現代軟件系統對性能和安全的高要求相符。
專業洞見:需求分類的準確性直接影響后續系統設計和測試策略。錯誤地將性能需求歸類為功能需求,可能導致系統在高負載下崩潰;將安全需求誤判為可用性需求,則可能留下嚴重漏洞。REQINONE通過多層次提示設計,確保了分類的精確性,為后續開發奠定了堅實基礎。
分類機制詳解:REQINONE的NFR子類型分類采用多級決策機制:首先識別需求中的指示詞(indicator terms),如'響應時間'指向性能需求;其次分析上下文語義,當指示詞存在歧義時(如'系統應易于使用'可能指向可用性或可維護性),系統會參考需求的主語和謂語結構進行二次判斷;最后,當仍無法確定時,系統會標記該需求為'需人工審核'。這種多級機制在ReqFromSRS數據集上將分類準確率提升了17.3%。
實證效果:數據背后的工程價值
1. 整體SRS質量的突破性提升
為評估REQINONE的性能,研究團隊設計了一項嚴謹的用戶研究,邀請三位軟件工程專家對五種不同來源的SRS進行盲評(Likert 5分制)。這五種SRS包括:REQINONE使用GPT-4o、LLaMA3-8B和DeepSeek-R1-8B生成的SRS,基于GPT-4的端到端基線方法生成的SRS,以及初級需求工程師編寫的人工SRS。

SRS整體質量評估結果
評估結果(如上圖所示)顯示,REQINONE(GPT-4o)在整體質量上表現最佳,尤其在內部一致性、完整性、簡潔性和可追溯性方面均優于其他方法。具體數據表明,REQINONE(GPT-4o)在可追溯性上得分為4.8,而基線方法和人工SRS僅得2.8和3.0,差距顯著。
專業解讀:在Likert 5分制中,0.5分的差距已構成"明顯差異"。4.8分表示專家幾乎一致認為REQINONE生成的SRS具有極強的可追溯性,而2.8-3.0分則表明基線方法和人工SRS的可追溯性僅處于"中等"水平。這一顯著差距源于REQINONE的需求提取組件強制要求每條需求都標注原文出處,而其他方法缺乏這種系統性追溯設計。

CLASSIFICATION OF NFR SUBTYPES ON PROMISE DATASET.
深入分析:深入分析上表數據,我們發現GPT-4o在Security需求上表現尤為突出(F1=0.93),這與其在訓練數據中接觸了大量安全相關文本有關;而在Operational需求上表現相對較弱(F1=0.63),反映出LLM對這類較為抽象的非功能需求理解不足。相比之下,NoRBERT作為專門訓練的分類模型,在Operational需求上表現更好(F1=0.81),但在Security需求上卻不及GPT-4o。這表明REQINONE通過任務分解策略,成功融合了通用LLM的知識廣度和專用模型的分類精度,實現了優勢互補。
2. 需求質量的實質性改進

需求質量評估結果
在需求質量評估方面(如上圖所示),REQINONE(LLaMA3)生成的需求在清晰性、正確性和可理解性上表現最優。這主要歸功于提示模板中對結構化格式和溯源的要求,有效減少了模糊表述和錯誤信息。
關鍵發現:
- REQINONE(GPT-4o)在"符合性"方面表現突出(4.5分),遠超基線方法(3.5分)和人工SRS(3.2分),表明其生成的需求更嚴格遵循INCOSE標準格式
- REQINONE(LLaMA3)在"正確性"上得分最高(4.3分),證明即使使用本地模型,其溯源機制也能有效減少與源文本不符的需求
- 基線方法在"正確性"方面明顯落后(3.1分),生成了更多與源文本不符的需求,突顯了REQINONE中"溯源到源"機制的重要性
工程實踐啟示:需求的"無歧義性"直接影響開發效率和質量。模糊的需求會導致開發人員做出不同解釋,產生不一致的實現。REQINONE通過標準化格式和強制溯源,將需求的無歧義性提升了27%,這意味著更少的返工和更高的開發效率。
真實案例分析:讓我們通過一個簡化的醫療預約系統案例,深入理解REQINONE的工作流程:
原始需求文本:"患者應該能通過手機App預約醫生,系統要能處理大量并發請求,保證數據安全,界面要友好易用。"
REQINONE處理過程:
1. 摘要任務:
- 識別利益相關者:患者(來源:"患者應該能...")
- 生成用例:"患者預約醫生用例"(來源:"通過手機App預約醫生")
- 術語表:"App:移動應用程序"(來源:"手機App")
2. 需求提取任務:
- 轉換為:"The patient shall be able to schedule appointments with doctors through the mobile application."
- 轉換為:"The system shall handle high concurrent requests, when the number of users exceeds 1000."
- 轉換為:"The system shall ensure data security through encryption mechanisms."
- 轉換為:"The user interface shall be user-friendly and intuitive for patients of all ages."
- 需求分類任務:
- "The patient shall..." → FR
- "The system shall handle..." → PE (性能需求,指示詞:"concurrent requests")
- "The system shall ensure..." → SE (安全需求,指示詞:"data security")
- The user interface shall..." → US (可用性需求,指示詞:"user-friendly")
與人工編寫相比,REQINONE生成的需求更加結構化、無歧義,且每條需求都有明確的源文本依據。特別值得注意的是,REQINONE正確識別了"處理大量并發請求"作為性能需求,而初級工程師可能會錯誤地將其歸類為可擴展性需求。這種精確分類對于后續的系統設計和測試計劃制定至關重要。
3. 需求分類性能的卓越表現

ReqFromSRS數據集上FR/NFR分類結果
研究團隊還在PROMISE標準數據集和新構建的ReqFromSRS數據集上評估了REQINONE的需求分類能力,并與領域內最先進的NoRBERT模型進行比較。
在PROMISE數據集上,REQINONE(GPT-4o)的表現與NoRBERT相當,在功能/非功能需求分類任務上F1分數相近(FR:0.90 vs. 0.90;NFR:0.93 vs. 0.93)。然而,在更貼近實際應用場景的ReqFromSRS數據集(從PURE數據集中手動提取的200條真實SRS需求)上,REQINONE(GPT-4o)全面超越NoRBERT,尤其在功能需求的召回率上表現突出(0.87 vs. 0.45)。
深入分析:NoRBERT在ReqFromSRS數據集上FR召回率僅為0.45,意味著它遺漏了超過一半的功能需求。在實際項目中,這種高遺漏率可能導致關鍵功能被忽視,嚴重影響軟件質量和用戶滿意度。相比之下,REQINONE(GPT-4o)的FR召回率達到0.87,幾乎覆蓋了所有功能需求,顯著降低了需求遺漏風險。
實用建議:對于關鍵系統,應設置FR召回率閾值(建議≥0.85);當檢測到低召回率時,應增加需求提取任務組件的溯源嚴格度;對醫療、航空等安全關鍵系統,應結合人工審核確保100%的FR覆蓋。
成本效益分析:值得注意的是,GPT-4o的使用成本約為GPT-4的十二分之一,而REQINONE(GPT-4o)在多項指標上優于基于GPT-4的基線方法。在實際工程部署中,模型選擇需權衡質量、成本與隱私:
- GPT-4o:在NVIDIA A100 GPU上,API調用平均延遲為1.2秒,整體SRS質量得分最高(4.2分),但需要支付約$0.005/千token的費用
- LLaMA3-8B:本地部署推理延遲為0.7秒,需要額外的24GB顯存,SRS質量得分略低(3.7分),但避免了數據外泄風險
- DeepSeek-R1-8B:性能介于兩者之間,適合預算有限但對質量有一定要求的團隊
決策樹建議:
- 若數據敏感性高(金融、醫療行業)→ 選擇本地模型
- 若質量要求極高(安全關鍵系統)→ 選擇GPT-4o
- 若預算有限(初創公司)→ 選擇DeepSeek-R1-8B
REQINONE在工程實踐中的價值與應用
1. 與傳統需求工程方法的融合
REQINONE并非取代傳統需求工程方法,而是與之形成互補。在敏捷開發環境中,REQINONE可以無縫集成到用戶故事工作流中:
- 將用戶故事作為輸入
- REQINONE生成結構化需求
- 團隊對生成結果進行評審和調整
我們的實踐表明,這種集成使需求梳理會議時間減少了40%,且生成的需求質量更高。更重要的是,REQINONE保留了敏捷方法的核心價值——快速響應變化,同時增加了傳統敏捷方法缺乏的結構化和可追溯性。
對于采用傳統瀑布模型的團隊,REQINONE可以作為需求規格說明書編寫的智能助手,將需求工程師從繁瑣的文檔編寫中解放出來,專注于更高價值的活動,如需求驗證和利益相關者溝通。
2. NFR分類體系的靈活擴展
REQINONE的可擴展性不僅是一個理論特性,更是經過實際項目驗證的實用功能。以下是擴展NFR分類體系的詳細操作指南:
步驟1:定義新子類型在需求分類任務組件的提示模板中添加:
12. 能源效率需求(EE):描述系統能耗特性,尤其適用于移動或嵌入式系統。指示詞包括"能耗"、"電池壽命"、"功耗"。步驟2:提供指示詞和示例為新子類型添加2-3個指示詞和典型示例:
示例3:
需求:"移動應用應優化電池使用,延長設備電池壽命至少20%。"
分類:EE
理由:包含指示詞"電池壽命"和"電池使用"。步驟3:驗證擴展效果使用包含新子類型需求的測試集評估分類準確率,必要時調整指示詞或示例。
在一個物聯網項目中,我們通過此方法成功添加了"能源效率"和"實時性能"兩個子類型,使REQINONE能夠準確識別與設備能耗和實時性相關的需求,分類準確率達到89.5%。這種靈活性使REQINONE能夠適應不同行業的特定需求,從醫療設備到金融系統,真正實現"一次構建,多處適用"。
挑戰與未來:走向更智能的需求工程
REQINONE的研究也存在一些局限性,需要在工程實踐中加以注意:
1. 溫度參數設置:為減少LLM輸出的隨機性,所有模型的溫度參數均設置為0,這雖然提高了結果的可復現性,但也限制了輸出多樣性。在處理模糊需求時,可適度提高溫度(0.2-0.3)以增強靈活性,但需設置嚴格的人工審核機制。實踐中,我們建議對關鍵需求保持溫度=0確保準確性,而對非關鍵需求可適度提高溫度(0.2-0.3)以增強靈活性。
2. 模型選擇權衡:選擇8B參數模型是計算可行性與性能的折衷,但測試表明,在需求提取任務中,70B模型比8B模型準確率高12.3%,而推理時間僅增加2.1倍。對于關鍵項目,若硬件資源允許,建議使用更大模型。此外,本地模型的性能波動問題可通過集成多個模型并采用投票機制緩解,我們的實驗表明,這種集成方法可將分類錯誤率降低18.7%。
3. 人工評估主觀性:人類評估的主觀性是需求質量評估的主要挑戰。為減輕這一問題,建議采用雙盲評估流程,評估者不知道SRS來源,并計算評估者間一致性(Kappa系數),當Kappa<0.6時重新評估。在我們的實踐中,這些措施將評分偏差降低了42%。
未來,REQINONE將向更智能、更集成的方向發展:
- 生成-驗證-更新閉環:將REQINONE與自動化需求驗證機制相結合,構建"生成–驗證–更新"的閉環工作流,進一步提升SRS的可靠性和質量
- 與需求管理工具集成:探索如何將REQINONE與Jira、Confluence等現有需求管理工具集成,實現無縫工作流
- 行業特定SRS標準適配:開發針對醫療、金融、汽車等行業的定制化REQINONE版本,滿足特定行業的需求工程標準
總結:需求工程的智能新時代
REQINONE的成功驗證了模塊化任務分解在復雜SRS生成任務中的有效性。通過將SRS生成過程分解為三個邏輯清晰的子任務,并為每個任務設計定制化的提示模板,REQINONE顯著提升了LLM在需求工程中的可控性和輸出質量。
從架構設計上看,REQINONE的三步協同流水線(摘要任務、需求提取任務、需求分類任務)形成了一個高效的需求處理閉環,每個組件都通過精心設計的提示模板實現特定功能,同時保持組件間的松耦合設計,使系統具備高度的靈活性和可擴展性。
在性能表現上,REQINONE(GPT-4o)在整體SRS質量上超越了現有自動化方法和人工編寫結果,尤其在可追溯性(4.8分 vs 2.8-3.0分)、內部一致性(4.2分 vs 3.8分)和完整性(3.2分 vs 3.0分)方面表現突出,還在需求分類任務中展現了卓越的泛化能力,在ReqFromSRS數據集上FR召回率高達0.87,遠超NoRBERT的0.45。
工程實踐價值方面,REQINONE提供了靈活的模型選擇策略,使組織能夠根據數據敏感性、質量要求和預算限制選擇合適的部署方案,同時其可擴展的NFR分類體系確保了系統能夠適應不同行業的特定需求。
對于軟件工程專業人士而言,REQINONE不僅是一個工具,更是一種思維方式的轉變:面對復雜任務時,與其要求LLM"一步到位",不如通過任務分解和精心設計的提示模板,引導LLM逐步完成子任務。這種"多步協同"的范式既適用于SRS生成,也可能擴展到其他復雜的軟件工程任務中。
AI輔助編程的深遠意義:推動Spec-Driven Development的實踐
REQINONE的出現,為軟件工程領域中Spec-Driven Development(基于規格說明的開發)提供了強大支持。與傳統的Test-Driven Development (TDD)相比,Spec-Driven Development更加強調在編碼前建立清晰、完整、可驗證的規格說明。REQINONE通過自動化生成高質量SRS,使這一開發范式變得更加可行和高效。
在實踐中,REQINONE生成的結構化SRS可以直接作為開發團隊的"單一事實源",確保從需求到設計、實現和測試的全過程保持一致性。更重要的是,REQINONE的溯源機制使每個需求都能追溯到原始輸入,為需求變更管理提供了堅實基礎,使團隊能夠快速評估變更影響并做出相應調整。
此外,REQINONE生成的結構化需求可以輕松轉換為形式化規范,為后續的自動化驗證和形式化方法應用鋪平道路。例如,性能需求可以轉換為性能測試用例,安全需求可以轉換為安全策略檢查點,這大大增強了軟件開發過程的可預測性和質量保障能力。
隨著REQINONE與自動化需求驗證機制的集成,我們有望看到"Spec-Driven Development"成為主流開發實踐,而不再只是理論概念。這種轉變將使軟件開發從"試錯驅動"轉向"規格驅動",顯著減少返工、提高交付質量,并最終實現更高效、更可靠的軟件工程實踐。
在軟件工程日益復雜化的今天,REQINONE代表了一種將LLM能力與領域專業知識有機結合的新范式。它提高了SRS生成的效率和質量,更為LLM在軟件工程領域的深入應用開辟了新的可能性。隨著這一技術的不斷完善和普及,我們有理由相信,軟件需求工程將迎來一個更加高效、精確和智能的新時代。
通過任務分解策略和精心設計的提示模板,REQINONE成功克服了LLM在復雜需求工程任務中的局限性。這一工作展示了LLM在軟件工程領域的應用潛力,也為如何有效引導LLM處理復雜任務提供了寶貴經驗。