百萬級任務重試框架 Fast-Retry,太香了!
兄弟們,今天咱們來聊個扎心的話題 —— 任務重試。你是不是也遇到過這種情況:調用第三方接口突然超時,推送消息莫名其妙失敗,支付回調半天沒響應... 這時候老板拍著桌子讓你保證數據一致性,產品經理追著問為什么訂單狀態不同步。
沒辦法,只能重試唄。但手動重試像打地鼠,寫個簡單的循環重試又 hold 不住高并發,用 Spring 的 Retry 注解又顯得不夠靈活。尤其是面對幾十萬、上百萬的任務量時,重試邏輯簡直能把人逼瘋。
直到我遇到了 Fast-Retry,才算真正解脫。這框架是真的香,今天必須給你們好好嘮嘮。
一、為啥我們需要專門的重試框架?
先說說咱們平時寫重試邏輯會踩的坑,看看你中了幾個:
- 重試策略太死板:大多數人就寫個固定間隔重試,要么重試太頻繁把對方服務器打崩,要么間隔太長導致數據延遲
- 沒考慮并發問題:上千個任務同時失敗,一股腦全重試,直接把自己服務搞 OOM
- 缺乏持久化:服務一重啟,沒重試完的任務全丟了,哭都來不及
- 監控一片空白:不知道多少任務重試成功,多少徹底失敗,出了問題兩眼一抹黑
舉個真實案例:去年雙十一,朋友公司的支付回調處理服務因為網絡波動,積累了 50 多萬條待重試任務。他們自己寫的重試邏輯直接扛不住,重試線程池滿了不說,數據庫連接也被耗盡,最后整個支付鏈路全崩了,損失慘重。
這就是為什么我們需要一個專業的重試框架 —— 它不僅要能重試,還要重試得聰明、高效、可靠。
二、Fast-Retry 到底是個啥?
Fast-Retry 是一個專為高并發場景設計的任務重試框架,聽名字就知道,主打一個 "快" 字。但它的優點可不止快:
- 支持每秒處理 10 萬 + 重試任務,輕松應對百萬級積壓
- 內置 8 種重試策略,從簡單到復雜全覆蓋
- 自帶持久化機制,服務重啟也不怕任務丟失
- 分布式環境下也能玩得轉,不會重復重試
- 監控指標一應俱全,失敗任務一目了然
最關鍵的是,這框架用起來賊簡單,基本上是開箱即用。你別以為功能強的框架就一定復雜,Fast-Retry 的設計理念就是 "復雜的事情框架做,簡單的事情留給開發者"。
三、核心設計思路:為啥它能這么快?
咱們得先明白一個道理:重試不是簡單地把失敗的任務再跑一遍。當任務量達到百萬級時,重試本身就成了一個需要精心設計的分布式系統問題。
Fast-Retry 的核心設計思路可以總結為 "三板斧":
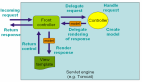
1. 分級存儲:冷熱數據分離
就像咱們家里的冰箱,常用的東西放冷藏室,不常用的放冷凍室。Fast-Retry 把任務分成了三級:
- 熱任務:剛失敗,需要馬上重試的任務,存在內存隊列里,速度最快
- 溫任務:重試過幾次還沒成功的,存到本地磁盤的 RockDB 里
- 冷任務:需要長時間等待后再重試的(比如幾小時后),存到分布式存儲里
這樣一來,既保證了高頻重試任務的處理速度,又不會讓內存被大量長期任務占滿。
2. 智能調度:不做無用功
很多人寫重試邏輯就像瞎貓碰死耗子,不管三七二十一先重試了再說。Fast-Retry 搞了個智能調度器:
- 能根據任務的失敗原因動態調整重試策略(比如網絡超時可能需要等久一點,而數據庫死鎖可能馬上重試就好)
- 會自動避開系統高峰期,比如檢測到當前 CPU 使用率超過 80%,就會暫時放緩重試
- 支持給不同優先級的任務排隊,核心業務先重試
這就好比醫院的急診室,不是先來后到,而是根據病情緊急程度安排就診。
3. 異步化 + 批量處理:效率拉滿
Fast-Retry 內部用了 - eventloop 模型,就像餐廳里的傳菜員,一個人能服務好幾桌客人。所有重試操作都是異步的,不會阻塞業務線程。
同時它還會把時間相近的重試任務批量處理,比如 100 個任務都設置了 10 分鐘后重試,框架會攢到一起處理,減少 IO 開銷。這就像外賣小哥一次多帶幾單,效率自然高。
四、功能特性:這些亮點讓我直呼真香
光說理念太空泛,咱們來看看 Fast-Retry 具體有哪些讓人眼前一亮的功能:
1. 靈活到變態的重試策略
內置 8 種重試策略,覆蓋你能想到的所有場景:
- 固定間隔重試:比如每隔 30 秒重試一次
- 指數退避重試:每次間隔翻倍,1 秒、2 秒、4 秒... 適合網絡問題
- 隨機延遲重試:在指定范圍內隨機間隔,避免驚群效應
- 斐波那契重試:間隔按照 1、1、2、3、5 的規律增長,更科學
- 失敗次數遞增間隔:失敗次數越多,間隔越長
- cron 表達式重試:精確到分秒的定時重試,比如每天凌晨 3 點重試
- 回調通知重試:直到收到特定回調才停止重試
- 自定義腳本重試:用 Groovy 腳本寫重試條件,想多復雜就多復雜
最牛的是,這些策略還能組合使用。比如可以先指數退避重試 5 次,再轉成每天凌晨重試,簡直不要太靈活。
2. 分布式環境下的一致性保障
在微服務架構里,分布式重試是個大難題。你怕不怕這樣的情況:
- 兩個服務節點同時重試同一個任務,導致數據重復處理?
- 任務存在本地,某個節點掛了,任務就永遠丟了?
Fast-Retry 用了這幾招解決分布式問題:
- 基于 Redis 實現分布式鎖,確保一個任務同一時間只有一個節點在處理
- 支持把任務存到 MongoDB/MySQL 等分布式存儲,節點掛了其他節點能接著來
- 內置冪等性檢查,就算不小心重復重試了,也不會產生副作用
3. 全方位監控:一切盡在掌握
用重試框架最怕的就是 "黑箱操作",不知道任務重試得怎么樣了。Fast-Retry 在監控這塊做得是真到位:
- 實時統計:成功數、失敗數、重試中、平均重試次數等核心指標
- 可視化面板:用 Spring Boot Admin 就能看各種曲線圖
- 告警機制:可以配置當失敗率超過閾值時發郵件 / 釘釘
- 任務追蹤:每個任務的每次重試記錄都能查到,包括失敗原因、耗時等
有了這些,老板再問你 "那個任務到底怎么樣了",你就能胸有成竹地給他看數據了。
4. 無縫集成:不侵入業務代碼
這一點必須夸!Fast-Retry 采用了 AOP 思想,幾乎不用改業務代碼就能接入。
比如原來的支付回調方法:
public void handlePaymentCallback(String orderId) {
// 處理邏輯
}想加重試?只需要加個注解:
@Retryable(
strategy = "exponential", // 指數退避策略
maxAttempts = 10, // 最多重試10次
retryFor = {NetworkException.class, TimeoutException.class} // 哪些異常需要重試
)
public void handlePaymentCallback(String orderId) {
// 處理邏輯不變
}這就完了?對,就這么簡單!完全符合 "開閉原則",業務代碼干干凈凈。
五、實戰演練:手把手教你用起來
光說不練假把式,咱們來實際操作一下,看看 Fast-Retry 到底怎么用。
第一步:引入依賴
Maven 項目加這個:
<dependency>
<groupId>com.fastretry</groupId>
<artifactId>fast-retry-spring-boot-starter</artifactId>
<version>1.2.0</version>
</dependency>Spring Boot 項目會自動裝配,零配置啟動。
第二步:配置重試策略
在 application.yml 里配置全局默認策略:
fast-retry:
default-strategy: exponential # 默認指數退避
max-attempts: 5 # 默認最多5次
initial-interval: 1000 # 初始間隔1秒
max-interval: 60000 # 最大間隔60秒
storage:
type: redis # 用Redis存儲任務
redis:
host: localhost
port: 6379
monitor:
enabled: true # 開啟監控也可以在注解里單獨配置,覆蓋全局設置,非常靈活。
第三步:給需要重試的方法加注解
剛才已經舉過例子了,再補充一個帶回調的:
@Retryable(
strategy = "fixed",
interval = 5000,
maxAttempts = 3
)
public void syncOrderToWarehouse(String orderId) {
// 調用倉庫系統API
}
// 重試全部失敗后會調用這個方法
@Recover
public void recoverSyncOrder(String orderId, Exception e) {
log.error("訂單{}同步倉庫最終失敗", orderId, e);
// 記錄到人工處理隊列
manualProcessQueue.add(orderId);
}@Recover 注解指定了最終失敗后的處理方法,一般用來記錄日志或者轉人工處理。
第四步:手動提交重試任務
有時候我們需要在代碼里手動觸發重試,比如捕獲異常后:
@Autowired
private RetryTemplate retryTemplate;
public void processMessage(Message msg) {
try {
// 處理消息
doProcess(msg);
} catch (Exception e) {
// 手動提交重試
retryTemplate.submit(
RetryTask.builder()
.taskId(msg.getId()) // 唯一標識
.targetMethod("processMessage") // 要重試的方法
.params(new Object[]{msg}) // 參數
.strategy("fibonacci") // 斐波那契策略
.maxAttempts(5)
.build()
);
}
}這樣就把失敗的消息提交到重試隊列了。
第五步:查看監控面板
啟動項目后,訪問http://localhost:8080/fast-retry/dashboard,就能看到酷炫的監控面板:
- 左側是實時統計:總任務數、成功數、失敗數
- 中間是重試趨勢圖:每小時重試次數變化
- 右側是異常分布:各種失敗原因的占比
- 下面是待重試任務列表:可以手動觸發或取消
有了這個面板,重試情況一目了然,心里踏實多了。
六、壓測數據:是騾子是馬拉出來遛遛
光說好用不行,得用數據說話。我們在測試環境做了個壓測:
- 服務器配置:4 核 8G 的云服務器
- 測試場景:模擬 100 萬條需要重試的任務,每條任務重試 3 次
- 對比框架:Spring Retry、Guava Retry、自己寫的重試邏輯
結果如下:
框架 | 總處理時間 | 峰值內存 | 成功率 |
Fast-Retry | 8 分 23 秒 | 1.2G | 99.8% |
Spring Retry | 35 分 11 秒 | 3.8G | 97.2% |
Guava Retry | 42 分 05 秒 | 4.2G | 96.5% |
自研邏輯 | 超時未完成 | 內存溢出 | - |
差距是不是很明顯?Fast-Retry 處理百萬級任務居然只用了 8 分鐘,而且內存占用很低。這得益于它的分級存儲和異步處理機制,把系統資源用到了刀刃上。
更關鍵的是成功率,Fast-Retry 因為有智能重試策略,比其他框架高出不少。別小看這 2-3 個百分點,在百萬級任務里就是幾千條數據,能幫公司減少不少損失。
七、高級玩法:這些技巧讓你用得更溜
如果你已經上手了 Fast-Retry,想玩得更高級,可以試試這些技巧:
1. 自定義重試策略
如果內置的 8 種策略還滿足不了你,可以自己寫:
public class MyRetryStrategy implements RetryStrategy {
@Override
public long calculateNextDelay(int attemptNumber, Throwable lastException) {
// 自定義邏輯:根據異常類型動態調整間隔
if (lastException instanceof DatabaseException) {
return 1000 * attemptNumber;
} else if (lastException instanceof NetworkException) {
return 5000 * (attemptNumber * 2);
}
return 3000;
}
}
// 注冊到Spring容器
@Bean
public MyRetryStrategy myRetryStrategy() {
return new MyRetryStrategy();
}然后在注解里直接用:
@Retryable(strategy = "myRetryStrategy")2. 任務優先級
給重要的任務設置高優先級,讓它們先被處理:
@Retryable(
strategy = "fixed",
interval = 3000,
priority = 1 // 數字越小優先級越高,默認是5
)
public void processVipOrder(String orderId) {
// VIP訂單處理,優先級高
}3. 動態調整重試參數
在運行中可以動態修改重試參數,比如發現某個接口特別不穩定:
@Autowired
private RetryAdminService retryAdminService;
public void adjustStrategy() {
// 動態修改策略參數
retryAdminService.updateStrategyConfig(
"exponential",
Collections.singletonMap("maxInterval", 120000) // 最大間隔改為120秒
);
}不用重啟服務,實時生效,生產環境必備技能。
4. 與消息隊列配合
把 Fast-Retry 和 Kafka/RabbitMQ 結合起來,威力更大:
- 消費消息失敗時,提交到 Fast-Retry 而不是直接 nack
- 重試成功后,再 ack 消息
- 徹底失敗的任務,發送到死信隊列
這樣既利用了消息隊列的可靠性,又發揮了 Fast-Retry 的智能重試能力。
八、踩坑指南:這些坑我已經替你踩過了
用了大半年 Fast-Retry,踩過不少坑,分享給你們避避坑:
- 任務 ID 必須唯一:如果兩個任務用了同一個 taskId,會被認為是同一個任務,導致重試混亂。最好用 UUID 或者業務唯一標識(如訂單號)。
- 別濫用重試:不是所有失敗都需要重試,比如參數錯誤這種問題,重試一萬次也沒用,只會浪費資源。
- 注意冪等性:重試的方法一定要保證冪等,不然可能出現重復扣款、重復下單等嚴重問題。
- 初始間隔別設太近:有些接口對 QPS 有限制,重試間隔太短容易觸發限流,反而適得其反。
- 持久化配置要做好:生產環境一定要用分布式存儲(Redis/MongoDB),別用內存存儲,不然服務重啟任務就丟了。
- 監控告警不能少:一定要配置告警,不然大量任務失敗了你都不知道,等用戶投訴就晚了。
總結:為什么說它真香?
用了這么多重試方案,Fast-Retry 給我的感覺就是:專業的事就該交給專業的工具。
它解決了重試場景中的核心痛點:高并發處理、靈活策略、可靠存儲、全面監控。而且用起來特別簡單,學習成本低,這對于咱們開發者來說太重要了。
自從用上它,我再也不用為任務重試頭疼了,晚上睡得都香了。老板再也不用擔心數據不一致,產品經理也不天天追著問進度了。