Meta「透視」AI思維鏈:CRV推理診斷,準(zhǔn)確率達(dá) 92%!
「Meta剛剛找到一種方法,可以實(shí)時(shí)觀察AI的思維過(guò)程崩潰。」
一條看似尋常的推文,在AI圈炸開(kāi)了鍋。

發(fā)帖人是研究員@JacksonAtkinsX,他稱(chēng)Meta的新技術(shù)能讓機(jī)器的思維「透明化」——不僅能看到模型在想什么,還能看見(jiàn)它在哪一步徹底「想錯(cuò)」。
在Meta FAIR團(tuán)隊(duì)剛發(fā)布的論文中,這項(xiàng)被稱(chēng)為CRV(Circuit-based Reasoning Verification)的新方法,就像一臺(tái)「AI腦部X光機(jī)」:
它能追蹤語(yǔ)言模型的每一次推理、記錄每一條電流路徑,甚至捕捉到思維崩潰的瞬間。

論文鏈接:https://arxiv.org/abs/2510.09312?utm_source
當(dāng)屏幕上那張電路圖突然從整潔的網(wǎng)狀,變成混亂的線(xiàn)團(tuán)——研究者第一次,看見(jiàn)了AI的思維是怎么崩潰的。
Meta「看見(jiàn)」了AI是怎么想錯(cuò)的
Meta剛剛找到一種方法,可以實(shí)時(shí)觀察AI的思維過(guò)程崩潰。
當(dāng)研究員Jackson Atkins發(fā)出這條推文時(shí),AI社區(qū)瞬間沸騰了
乍一聽(tīng)像科幻小說(shuō)的橋段。AI在思考的時(shí)候忽然斷鏈、炸裂,而研究者卻說(shuō)能直接看到那一刻。
但這不是夸張。在Meta FAIR團(tuán)隊(duì)剛發(fā)表的論文 《Verifying Chain-of-Thought Reasoning via Its Computational Graph》 中,他們提出了一種新方法:CRV(Circuit-based Reasoning Verification)。
這項(xiàng)技術(shù)能讓研究者在模型「思考」的過(guò)程中,看到它的推理電路。
當(dāng)模型推理正確時(shí),它的「內(nèi)部電路圖」干凈、有條理;一旦模型犯錯(cuò),電路圖立刻變得糾纏、雜亂。

推理指紋特征對(duì)比圖。錯(cuò)誤推理在這些特征上普遍更加分散、混亂。
研究團(tuán)隊(duì)將這種電路結(jié)構(gòu)稱(chēng)為模型的「推理指紋(reasoning fingerprint)」。
他們發(fā)現(xiàn),錯(cuò)誤并不是隨機(jī)的,而是有形、有跡可循:只要讀取這張「電路指紋圖」,就能預(yù)測(cè)模型是否即將犯錯(cuò)。

在算術(shù)推理實(shí)驗(yàn)中,CRV 的檢測(cè)精度(AUROC)從76.45提升至92.47,誤報(bào)率從63.33%降至37.09%。
更令人震撼的是,當(dāng)研究者關(guān)閉一個(gè)錯(cuò)誤激活的乘法特征神經(jīng)元后,模型立即修正了計(jì)算。

例如在表達(dá)式 (7 × ((5 + 9) + 7)) 中,模型原本輸出105,干預(yù)后改為147——完全正確。
錯(cuò)誤推理并非隨機(jī),而是電路執(zhí)行過(guò)程中的結(jié)構(gòu)性失敗。
Meta FAIR的研究者用一句話(huà)概括他們的目標(biāo):要讓AI不僅能「給出答案」,更能「證明自己想得對(duì)」。
重塑推理結(jié)構(gòu)
給機(jī)器裝上「透明大腦」
要想讓AI的思維過(guò)程變得「可見(jiàn)」,Meta做了一件幾乎顛覆常識(shí)的事:他們重新改造了語(yǔ)言模型的大腦結(jié)構(gòu)。
這項(xiàng)被命名為CRV(Circuit-based Reasoning Verification)的方法,核心思想不是提升模型性能,而是讓AI的每一步推理都能被驗(yàn)證、被追蹤。
我們的目標(biāo)不是讓模型更聰明,而是讓它的思考過(guò)程本身變得可驗(yàn)證。
AI的大腦不再是黑盒:每個(gè)「神經(jīng)元」都能被看見(jiàn)
研究團(tuán)隊(duì)首先將模型中的傳統(tǒng)MLP模塊替換為一種可解釋的稀疏結(jié)構(gòu)——Transcoder層。
在不同層將MLP替換為T(mén)ranscoder后,模型的損失值在短時(shí)間內(nèi)迅速下降并趨于穩(wěn)定。

Transcoder層的訓(xùn)練穩(wěn)定性證明。CRV 不是理論概念,而是可以在大模型上穩(wěn)定運(yùn)行的真實(shí)工程結(jié)構(gòu)。
每個(gè)Transcoder都像一組帶標(biāo)簽的神經(jīng)元,能代表特定的語(yǔ)義特征,例如「加法」「乘法」「括號(hào)」或「進(jìn)位」。
這樣一來(lái),研究者就能在推理過(guò)程中,看到哪些神經(jīng)元被激活、何時(shí)點(diǎn)亮、如何傳遞。
論文把這一步稱(chēng)為「X-Ray」,即為模型安裝一層「透視皮膚」。
研究者形容它像「在黑箱里裝上攝像機(jī)」:每一層的計(jì)算過(guò)程不再是難以解讀的向量,而是清晰的電路信號(hào)。
AI的思維可以畫(huà)出來(lái):Meta讓推理變成一張電路圖
當(dāng)模型執(zhí)行一步推理時(shí),系統(tǒng)會(huì)繪制出一張歸因圖(Attribution Graph),節(jié)點(diǎn)代表被激活的特征,邊表示它們之間的信息流動(dòng)。
每一次邏輯跳轉(zhuǎn)、每一個(gè)概念結(jié)合,都會(huì)在圖上留下痕跡。
這張圖不是靜態(tài)的,而是隨推理動(dòng)態(tài)變化的「思維軌跡」。
當(dāng)模型看到「3+5=」時(shí),研究者可以實(shí)時(shí)看到「加法特征」從底層被點(diǎn)亮、信息如何層層匯聚到輸出。
而當(dāng)模型出錯(cuò)時(shí),路徑就會(huì)打結(jié)、分叉、環(huán)繞——像一條錯(cuò)亂的神經(jīng)信號(hào)。

CRV 方法流程示意圖中展示了從「替換MLP模塊」、構(gòu)建歸因圖、提取結(jié)構(gòu)特征,到最后交由診斷分類(lèi)器判定「正確/錯(cuò)誤」的全過(guò)程。
讓AI自己暴露錯(cuò)誤:Meta發(fā)現(xiàn)「思維崩潰」的指紋
當(dāng)思維電路圖生成后,Meta提取了大量結(jié)構(gòu)特征:節(jié)點(diǎn)數(shù)量、圖密度、平均邊權(quán)、路徑長(zhǎng)度、中心性……
這些數(shù)據(jù)構(gòu)成了模型的「思維指紋」。
接著,他們訓(xùn)練了一個(gè)分類(lèi)器——它不讀文字,也不看答案,只看結(jié)構(gòu)。在實(shí)驗(yàn)中,研究者發(fā)現(xiàn):
當(dāng)圖結(jié)構(gòu)糾纏、分布混亂時(shí),模型幾乎一定在推理出錯(cuò)。
也就是說(shuō),模型是否思考正確,不必等它說(shuō)完答案,只要觀察那張「電路圖」的形態(tài),就能提前判斷。
CRV的出現(xiàn),讓語(yǔ)言模型第一次擁有了「可診斷的神經(jīng)結(jié)構(gòu)」。
Meta并沒(méi)有讓AI更聰明,而是讓人類(lèi)第一次能看見(jiàn)AI是如何出錯(cuò)的。
黑箱不再完全密封,智能第一次露出了自己的「電路斷層」。
不止是論文,更是AI研究的分水嶺
在Meta公布實(shí)驗(yàn)結(jié)果后,最直觀的震撼來(lái)自這組對(duì)比圖:
CRV與多種驗(yàn)證方法的性能對(duì)比。圖中展示了不同方法在算術(shù)推理任務(wù)下的檢測(cè)表現(xiàn)。
紅線(xiàn)代表 CRV,無(wú)論是在AUROC(檢測(cè)精度)、AUPR(正確預(yù)測(cè)率) 還是FPR@95(誤報(bào)率)上,都遠(yuǎn)高于或低于其他方法。
這意味著它不僅能看見(jiàn)推理電路的結(jié)構(gòu),更能精準(zhǔn)判斷模型是否會(huì)想錯(cuò)。

這樣的結(jié)果讓許多研究者意識(shí)到:CRV不只是一次模型改造,而是一次觀念的翻轉(zhuǎn)。
過(guò)去,我們判斷一個(gè)模型是否推理正確,只能看它的答案。
它寫(xiě)出一段chain-of-thought,人類(lèi)再去揣測(cè)邏輯是不是連貫,結(jié)論是不是對(duì)的。
這一切都發(fā)生在黑箱之外——我們只能看到輸出,卻無(wú)法追蹤「它是怎么想的」。
而Meta的CRV,把這條思維鏈第一次攤在顯微鏡下。研究者不再靠猜,而是能直接看到模型內(nèi)部的邏輯路徑:
每一次特征被點(diǎn)亮,每一條信號(hào)被傳遞,都能在圖上找到對(duì)應(yīng)的「電路」。
他們不是在評(píng)估答案,而是在驗(yàn)證思維的結(jié)構(gòu)本身。
更重要的是,CRV讓「可解釋性」和「可靠性」第一次真正接上了。
在過(guò)去的研究里,前者關(guān)注看懂模型,后者追求信得過(guò)模型,兩條路幾乎平行——我們能看到熱力圖,卻依然不知道為什么模型會(huì)錯(cuò)。
而在Meta的實(shí)驗(yàn)中,研究者既能解釋模型為什么出錯(cuò),也能預(yù)測(cè)下一步它可能在哪出錯(cuò)。
CRV也許是通向「可控智能」的第一步。當(dāng)推理錯(cuò)誤能被結(jié)構(gòu)化地識(shí)別,就意味著它可以被預(yù)測(cè)、干預(yù),甚至被修復(fù)。
論文中有一個(gè)著名的例子——關(guān)閉一個(gè)錯(cuò)誤激活的神經(jīng)特征后,模型立刻修正答案。
這說(shuō)明錯(cuò)誤并非偶然,而是電路級(jí)的故障。如果未來(lái)能實(shí)時(shí)監(jiān)測(cè)這些特征,我們或許能在幻覺(jué)發(fā)生前按下「剎車(chē)」。
從這一刻起,AI的錯(cuò)誤不再是神秘的靈異事件。它們是有形的、可診斷的。

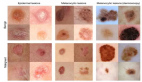
不同任務(wù)中正確與錯(cuò)誤推理的拓?fù)涮卣鞣植?/span>。圖中藍(lán)色表示正確推理,紅色表示錯(cuò)誤推理。
Meta把黑箱的蓋子掀開(kāi)了一條縫——讓人類(lèi)第一次有機(jī)會(huì),不只是造出智能,而是看懂智能本身。
能看懂AI的那天
我們離「可控智能」還有多遠(yuǎn)?
就算Meta已經(jīng)能「看見(jiàn)AI在想什么」,這項(xiàng)技術(shù)距離真正落地,仍有一段漫長(zhǎng)的路要走。
在論文結(jié)尾部分,研究團(tuán)隊(duì)自己就坦率地寫(xiě)下了「局限與未竟之處」。
我們的方法目前需要大量計(jì)算資源,因?yàn)楸仨殞⑺蠱LP層替換為T(mén)ranscoder層,并計(jì)算完整的歸因圖。
也就是說(shuō),要讓模型變得可見(jiàn),代價(jià)是巨大的:每一層都要被重建,每一個(gè)特征都要被追蹤。
光是繪制一次完整的歸因圖,就可能消耗掉普通訓(xùn)練的數(shù)十倍算力。這不是能隨意做出的功能,而是需要投入巨大的工程。
更現(xiàn)實(shí)的問(wèn)題是——規(guī)模。
實(shí)驗(yàn)僅在最大8B參數(shù)規(guī)模的模型上進(jìn)行,將其擴(kuò)展到更大模型仍需后續(xù)研究。
CRV目前只在中等體量的模型上被驗(yàn)證,而如今主流的大語(yǔ)言模型動(dòng)輒上百億、甚至上千億參數(shù),要讓整個(gè)推理電路都能被看見(jiàn),幾乎不可能在短期內(nèi)完成。
更棘手的是泛化問(wèn)題。
CRV在算術(shù)任務(wù)上表現(xiàn)亮眼,但一旦換到自然語(yǔ)言推理、常識(shí)問(wèn)答、代碼生成這類(lèi)復(fù)雜任務(wù)時(shí),歸因圖結(jié)構(gòu)的規(guī)律會(huì)完全不同,錯(cuò)誤特征不再穩(wěn)定,診斷效果明顯下降。
最后,Meta團(tuán)隊(duì)也提醒讀者:
Transcoder架構(gòu)只是原始MLP的一種近似,并非完美替代。
這意味著,研究者看到的那些「電路軌跡」,其實(shí)是經(jīng)過(guò)重新投影后的近似結(jié)構(gòu)。
Meta的CRV不是讓機(jī)器更聰明,而是讓人類(lèi)第一次得以窺見(jiàn)智能的內(nèi)部結(jié)構(gòu)。
那些曾被稱(chēng)為「幻覺(jué)」的錯(cuò)誤、不確定的跳躍、莫名的偏差,如今都能被描摹成一張電路圖,被一點(diǎn)點(diǎn)拆解、理解、修復(fù)。
或許距離真正「可靠」的AI還很遠(yuǎn),但這一步已經(jīng)改變了方向。
人類(lèi)不再只是 AI 的使用者,而是它的讀者、醫(yī)生,也是見(jiàn)證者。
當(dāng)機(jī)器的思維第一次被照亮,這束光也照進(jìn)了我們自己的認(rèn)知——照見(jiàn)了我們對(duì)智能的渴望、恐懼,以及那句始終懸在科學(xué)盡頭的問(wèn)題:
我們究竟是在教會(huì)機(jī)器思考,還是在學(xué)會(huì)看懂自己?