RAG多崗位簡歷篩選系統實踐:多租戶架構設計模式與源碼解讀

我在8月底的時候,發過一篇基于 LlamaIndex+LangChain 框架,開發的簡歷篩選助手的應用。后續有星球成員提出希望能增加多個崗位的管理功能,正好接下來的校招活動可以用的上。
這篇在原項目的基礎上,核心實現了多崗位并行管理(獨立 JD、候選人池、向量索引隔離)和 HR 工作流(標簽系統、分組展示、快速操作),同時進行了架構重構(分層設計、數據分庫、模塊化),并增強了大模型分析輸出(四級推薦等級、結構化優劣勢)和智能問答(按崗位過濾檢索、流式輸出)。
這篇試圖說清楚:
系統的實際效果演示、四層系統架構拆解、五點核心技術實現、三個二次開發場景指南,以及對端側模型應用的一些感想。
1、視頻效果展示
在開始講具體實現之前,老規矩先來看看整個系統的架構設計。下面這張圖展示了從用戶界面到數據存儲的完整數據流。

2.1為啥要分四層
在上一版單崗位系統里,UI 代碼、業務邏輯、AI 調用全都混在一起的,一開始寫起來確實快,但這次升級到多崗位管理的時候,改動起來難免顧此失彼,所以這次也算是做了下系統重構。
前端交互層這部分依然采用了輕量化的 Streamlit,搭建了三個 Tab 頁面:候選人概覽、候選人詳情和智能問答。這一層只管顯示數據和響應用戶操作,不關心數據從哪來以及怎么處理。

業務服務層這部分是整個系統的核心處理邏輯所在。一份簡歷從上傳到展示,需要經過:先提取文本,再調用大模型分析,然后存入數據庫,最后建立向量索引。這些流程編排都在ResumeProcessor這個類里完成。還有一個PositionService,專門管理崗位的增刪改查。這一層的好處是,如果以后想改業務流程,比如在大模型分析前加一個簡歷去重檢查,只需要在這一層加幾行代碼,不用動其他地方。
核心引擎層這部分封裝了所有大模型相關的能力。這一層最重要的是RAGEngine,包括了簡歷文本向量化、存入 ChromaDB,以及在用戶提問時檢索相關內容等功能。
數據存儲層這部分用了三種存儲方式:SQLite 存儲崗位信息和候選人結構化數據,ChromaDB 存儲向量索引,文件系統存儲原始簡歷文件。所有復雜的 SQL 邏輯都封裝在各個 Store 類里,這樣以后如果要把 SQLite 換成 MySQL,只需要改 Store 類的實現,上層代碼完全不用動。
2.2多崗位數據隔離
為了保證不同崗位的數據不會串臺,我在三個層面做了隔離設計。
文件系統按崗位分目錄
最簡單直接的辦法,就是把不同崗位的簡歷文件分開存。我在uploaded_resumes/目錄下,給每個崗位創建一個子目錄,目錄名就是崗位 ID。比如"AI 產品經理"的崗位 ID 是position_001,這樣做的好處是刪除崗位的時候可以直接把整個目錄刪掉。
關系數據庫用外鍵關聯
在 SQLite 里,我給candidates表、ai_analysis表、hr_tags表都加上了position_id字段,并且設置了外鍵約束。每次查詢候選人數據,SQL 語句里必須帶上WHERE position_id = ?,從源頭上避免跨崗位查詢。
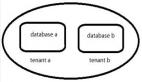
向量數據庫按崗位分 collection
這是整個隔離機制里最關鍵的一環,ChromaDB 支持創建多個 collection(可以理解為不同的向量數據庫),我給每個崗位創建一個獨立的 collection。比如position_001對應的 collection 叫resumes_position_001,position_002對應的叫resumes_position_002。
可能會有人問為啥不用 metadata 過濾呢?比如所有簡歷存在一個 collection 里,然后在 metadata 里標記position_id,檢索的時候再過濾。這個方案看起來更簡單,但有個致命問題是,實際使用的時候性能會隨著候選人總數線性下降。假設系統里有 10 個崗位,每個崗位 100 個候選人,那全局就有 1000 個候選人的向量。每次檢索都要在 1000 個向量里搜索,然后再用 metadata 過濾,這無疑會很慢。
而用 collection 隔離,每個崗位的檢索只在自己那 100 個向量里進行,性能只跟該崗位的候選人數相關,跟其他崗位完全無關。這就是物理隔離優于邏輯過濾的典型場景。這點非常像我在做 ibm rag 冠軍賽項目拆解中提到的“疑一文一庫”的做法。
2.3RAG 引擎與業務邏輯的解耦
在上一版系統里,我把 RAG 的代碼直接寫在業務邏輯里,結果就是代碼復用性很差。這次重構我專門抽出了一個通用的RAGEngine類,只提供三個核心能力:建索引、檢索、問答。
業務層想用的時候,把數據準備好,調用對應的方法就行。比如ResumeProcessor在處理簡歷的時候,會調用RAGEngine.build_index()把簡歷文本向量化;在智能問答的時候,會調用RAGEngine.query_with_rag()執行 RAG 流程。
這種解耦帶來的好處是,如果各位想換一個向量數據庫,比如從 ChromaDB 換成 Milvus,只需要改RAGEngine的內部實現,業務層的代碼一行都不用動。或者如果想把這套 RAG 引擎用到其他項目,比如做一個標準的企業知識庫問答系統,直接復制core/rag_engine_v2.py這個文件過去,寫一個新的 Processor 類就能跑起來。
3、核心技術實現拆解
前面講完了架構設計,這部分從代碼層面講幾個關鍵的技術實現,這部分會聚焦在私以為有一定工程借鑒價值的地方。
3.1簡歷完整向量化的考量
一個好用的 RAG 系統設計,一個繞不開問題是如何精準的切分文檔。上一版系統里,因為目的是要演示完整的系統流程,所以演示的簡歷部分也是針對性的進行了設計,分塊部分按照"核心技能"、"工作經歷"等章節標題進行處理。但這顯然不符合實際五花八門的簡歷格式情況。 這次重構,我做了一個看似偷懶實則更務實的做法,就是把每份簡歷作為一個完整的 node,不做分塊處理。
class MultiPositionNodeParser(NodeParser):
"""
支持多崗位的簡歷Node解析器(無分塊版本)
設計策略:
- 每份簡歷作為一個完整的node,不進行分塊
- 在metadata中添加position_id用于多崗位隔離
- 添加candidate_name用于候選人識別
優勢:
- 保留完整上下文,避免信息碎片化
- 簡歷通常很短,適合整體向量化
- 檢索時一次性獲得候選人所有信息
"""
def _parse_nodes(self, documents: List[Document], **kwargs) -> List[BaseNode]:
all_nodes = []
position_id = kwargs.get('position_id')
# 按文件路徑分組(一個PDF可能有多頁)
docs_by_filepath = defaultdict(list)
for doc in documents:
docs_by_filepath[doc.metadata.get("file_path")].append(doc)
for file_path, doc_parts in docs_by_filepath.items():
# 合并所有頁面為完整文本
doc_parts.sort(key=lambda d: int(d.metadata.get("page_label", "0")))
full_text = "\n\n".join([d.get_content().strip() for d in doc_parts])
# 創建包含整份簡歷的node
metadata = {
"position_id": position_id,
"candidate_name": Path(file_path).stem,
"chunk_type": "full_resume",
"resume_length": len(full_text)
}
node = TextNode(text=full_text, metadata=metadata)
all_nodes.append(node)
return all_nodes首先有個共識是,簡歷通常很短,一般 2-4 頁,毛估 2000-4000 字左右,完全在主流嵌入模型的處理范圍內。這次演示用的bge-m3模型支持 8192 tokens,處理一份完整簡歷應該說毫無壓力。
其次,完整向量化也避免了信息碎片化。當 HR 問“張三有沒有 RAG 項目經驗”的時候,如果簡歷被切成 10 個 chunk,可能需要檢索多個 chunk 才能拼湊出完整答案。而整份簡歷作為一個 node,一次檢索就能拿到所有相關信息,LLM 可以看到完整上下文進行推理。
再者,實現邏輯簡單也減少了 bug 風險。代碼的核心邏輯就是把多頁 PDF 合并成一個字符串,然后塞進一個 node,沒有復雜的正則匹配、沒有邊界判斷,代碼清晰好維護。在實際使用中實測效果很好,檢索準確率明顯提升,而且及時是 8b 尺寸的量化模型推理過程也很穩定。
3.2Pydantic 驅動的結構化分析
如何讓 LLM 穩定地輸出結構化數據,這也是個繞不開的挑戰。好的工程實踐,無非也是一套圍繞模型動態邊界構建的解決方案。這次我用了在歷史企業項目中常用的 Pydantic 模型 + 詳細 Prompt 的組合,實現了相對可靠的結構化輸出。先定義數據模型:
class AIResumeAnalysis(BaseModel):
"""AI簡歷分析結果 - 定性分析 + 結構化提取"""
recommendation_level: str = Field(
default="可考慮",
descriptinotallow="推薦等級: 強烈推薦 | 推薦 | 可考慮 | 不推薦"
)
key_strengths: List[str] = Field(
default_factory=list,
descriptinotallow="具體、可驗證的優勢,優先列出與崗位強相關的亮點"
)
key_concerns: List[str] = Field(
default_factory=list,
descriptinotallow="需要關注的方面,誠實指出但不夸大"
)
one_sentence_summary: str = Field(
default="",
descriptinotallow="核心特征概括,幫助HR快速建立印象"
)
total_years_experience: int = Field(default=0)
work_experience: List[WorkExperienceExtracted] = Field(default_factory=list)
project_experience: List[ProjectExperienceExtracted] = Field(default_factory=list)
# 字段校驗器
@field_validator('recommendation_level')
@classmethod
def validate_level(cls, v):
valid_levels = ["強烈推薦", "推薦", "可考慮", "不推薦"]
if v not in valid_levels:
return "可考慮"
return v
@field_validator('key_strengths')
@classmethod
def validate_strengths_count(cls, v):
if not v or len(v) == 0:
return ["請查看簡歷原文進行人工評估"]
return v[:5] # 最多5條Pydantic 的好處是,它不僅定義了數據結構,還內置了校驗邏輯。比如recommendation_level必須是四個等級之一,key_strengths至少有 1 條最多 5 條,這些規則會自動執行。然后在 Prompt 中明確輸出格式:
RESUME_ANALYSIS_PROMPT = """
你是一位專業的招聘顧問,請根據崗位描述和候選人簡歷,輸出結構化評估。
# 輸出要求
請嚴格按照以下 JSON 格式輸出,不要添加任何其他文字:
{
"recommendation_level": "強烈推薦",
"key_strengths": [
"5年 AI 產品經驗,主導過 3 個 RAG 項目成功上線",
"具備完整的 B 端產品設計能力(需求分析 → 原型設計 → 上線運營)"
],
"key_concerns": [
"缺乏制造業行業背景(現有經驗集中在互聯網行業)"
],
"one_sentence_summary": "技術型 AI 產品專家,RAG 項目經驗豐富,需補足制造業行業背景",
...
}
# 評估標準
### key_strengths(關鍵優勢)
- 輸出 3-5 條具體、可驗證的優勢
- 優先列出與崗位強相關的亮點
- 盡量包含數據支撐(如"5年經驗"、"主導3個項目")
- 避免空洞描述(?"能力強" ?"5年AI產品經驗,主導3個RAG項目")
...
"""Prompt 里不僅給出了 JSON 格式,還詳細說明了每個字段的要求,以及提供了好例子和壞例子的對比。這種高指令性的 Prompt 實測可以明顯提升 LLM 輸出的質量和穩定性。最后在解析時做好容錯處理:
def _parse_response(self, response_text: str) -> AIResumeAnalysis:
"""解析LLM響應為AIResumeAnalysis對象"""
try:
# 嘗試1:直接解析
data = json.loads(response_text)
return AIResumeAnalysis(**data)
except json.JSONDecodeError:
# 嘗試2:提取JSON塊
json_match = re.search(r'\{.*\}', response_text, re.DOTALL)
if json_match:
data = json.loads(json_match.group(0))
return AIResumeAnalysis(**data)
# 嘗試3:清理后解析(移除markdown代碼塊等)
cleaned = self._clean_json_text(response_text)
if cleaned:
data = json.loads(cleaned)
return AIResumeAnalysis(**data)
# 降級策略:返回默認值
return self._get_fallback_analysis()這套機制總結來說有三層容錯:先嘗試直接解析,不行就用正則提取 JSON 塊,再不行就清理格式后解析,最后還有一個降級策略返回默認值。實際使用中,絕大部分情況第一次就能成功解析,少數格式異常的也能被后續邏輯兜住,系統健壯性非常高。
3.3簡歷處理的五步流水線
一份簡歷從上傳到最終可用,需要經歷多個步驟。原版系統這些邏輯散落在各處,這次我用ResumeProcessor類把整個流程標準化成五步流水線:
def process_uploaded_file(self, uploaded_file, position_id, job_description):
"""處理上傳的簡歷文件(完整流程)"""
result = {
'steps': {
'extract': False, # 步驟1:文本提取
'validate': False, # 步驟2:內容驗證
'analyze': False, # 步驟3:AI分析
'index': False, # 步驟4:向量索引
'save': False # 步驟5:保存數據
}
}
# 步驟1:文本提取
text, extract_success = extract_text_from_file(temp_path)
result['steps']['extract'] = extract_success
if not extract_success:
return False, f"? 文件解析失敗", result
# 步驟2:內容驗證
is_valid = validate_resume_content(text)
result['steps']['validate'] = is_valid
if not is_valid:
return False, f"?? 文件內容疑似不是簡歷", result
# 步驟3:AI分析
analysis, analyze_success = self.analyzer.analyze(text, job_description)
result['steps']['analyze'] = analyze_success
# 步驟4:向量索引
index_success = self.rag_engine.ingest_resume(temp_path, position_id)
result['steps']['index'] = index_success
# 步驟5:保存到數據庫
profile = self._create_candidate_profile(...)
candidate_id = self.candidate_store.save(profile, analysis)
result['steps']['save'] = candidate_id > 0
return True, "? 處理成功", result這個設計有幾個好處:
首先,每一步都有明確的輸入輸出和成功標志。result['steps']字典記錄了每一步的執行狀態,方便調試和監控。如果處理失敗,可以立刻看到是在哪一步出的問題。
其次,失敗快速返回,避免無效計算。如果文本提取就失敗了,后面的大模型分析、向量索引都不用做了,直接返回錯誤信息。這種 fail-fast 策略節省資源,也讓錯誤信息更清晰。
最后,result字典不僅包含每一步的狀態,還包含候選人 ID、分析結果、文件路徑等信息,上層 UI 可以根據這些信息給用戶精準的反饋。
這種流水線模式在企業級應用中非常常見,它把復雜流程拆解成清晰的步驟,每步職責單一,容易測試和維護。
3.4多崗位檢索的元數據過濾機制
前面架構部分提到,我用 metadata 過濾實現多崗位隔離。這里展示一下具體的檢索代碼:
def retrieve(self, query: str, position_id: int = None, top_k: int = 5):
"""檢索相關文檔節點"""
# 構建metadata過濾器
filters = None
if position_id is not None:
filters = MetadataFilters(
filters=[
MetadataFilter(
key="position_id",
value=position_id,
operator=FilterOperator.EQ
)
]
)
# 創建檢索器
retriever = self.index.as_retriever(
similarity_top_k=top_k,
filters=filters
)
# 執行檢索
retrieved_nodes = retriever.retrieve(query)
return retrieved_nodesLlamaIndex 的MetadataFilters功能非常強,支持多種操作符(EQ、GT、LT、IN等),可以組合多個條件。這里我只用了最簡單的等值匹配,但如果以后需要更復雜的查詢,比如"工作年限大于 5 年且有制造業背景",只需要添加更多的MetadataFilter就行。在向量化這一步,我把position_id、candidate_name等信息存入 node 的 metadata:
metadata = {
"position_id": position_id,
"candidate_name": Path(file_path).stem,
"chunk_type": "full_resume",
"resume_length": len(full_text)
}
node = TextNode(text=full_text, metadata=metadata)檢索的時候,ChromaDB 會先在全局向量空間找到語義最相似的 top-K 個結果,然后用 metadata 過濾器篩選出符合條件的 node。語義匹配 + 精確過濾的組合,既保證了檢索質量,又實現了數據隔離。
需要注意的是,我在架構設計部分提到過 collection 隔離性能更好。但實際開發時我發現 LlamaIndex 對多 collection 管理不太友好,需要為每個崗位創建獨立的 index 對象,代碼會變得很復雜。所以我在單 collection + metadata 過濾和多 collection 隔離之間做了權衡,選擇了前者。
這也是說明了理論最優方案不一定是工程最優方案。要考慮框架限制、開發成本、可維護性等多方面因素。目前這個方案在候選人數量不超過 200 的情況下性能完全夠用,如果以后數據量真的上去了,再重構成多 collection 也不遲。
3.5基于 Session 的多輪對話記憶
智能問答如果只能單輪回答,用戶體驗無疑會很差。我用 Streamlit 的session_state實現了按崗位隔離的對話記憶。
def render_chat_tab(position_id: int, position_name: str, ...):
"""渲染智能問答Tab"""
# 初始化聊天歷史 - 每個崗位獨立的對話記憶
chat_key = f"chat_history_{position_id}"
if chat_key not in st.session_state:
st.session_state[chat_key] = []
# 顯示歷史消息
recent_messages = st.session_state[chat_key][-15:] # 只顯示最近15條
for message in recent_messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# 用戶輸入
if prompt := st.chat_input("請在此輸入您的問題..."):
# 添加用戶消息到歷史
st.session_state[chat_key].append({"role": "user", "content": prompt})
# ... 執行RAG檢索和LLM推理 ...
# 保存AI回答到歷史
st.session_state[chat_key].append({
"role": "assistant",
"content": answer_content,
"think_content": think_content # 推理過程
})首先是按崗位 ID 隔離對話歷史。不同崗位的問答互不干擾,HR 在"AI 產品經理"崗位的對話,不會影響到"算法工程師"崗位。其次,只顯示最近 N 條消息。對話歷史完整保存在session_state里,但頁面上只顯示最近 15 條,避免頁面過長影響體驗。

最后,保存推理過程。除了最終答案,我還把 LLM 的 thinking 過程保存下來。這樣用戶可以在st.expander里查看 AI 的推理鏈路,提升可解釋性。這個實現雖然簡單,但在實際使用中效果很好。多輪對話讓 HR 可以不斷追問,獲得更深入的候選人情況了解。
4、二次開發指南
在實際使用中,不同企業或者用戶會有不同的定制需求。這部分我根據和一些從業者的溝通,介紹三個高頻需求場景,作為二次開發的參考。
4.1批量導入簡歷
從招聘網站批量下載的簡歷通常打包在 zip 文件里,每次都要手動解壓再上傳,非常低效。如果能直接上傳 zip 包,系統自動解壓并批量處理,能節省掉不必要的手動操作。
# 核心邏輯:解壓zip并批量處理
import zipfile
from pathlib import Path
if uploaded_file.name.endswith('.zip'):
# 解壓到臨時目錄
with zipfile.ZipFile(uploaded_file) as zip_ref:
zip_ref.extractall('./temp_extract')
# 掃描所有簡歷文件
resume_files = list(Path('./temp_extract').rglob('*.pdf')) + \
list(Path('./temp_extract').rglob('*.docx'))
# 調用現有的批量處理
processor.batch_process(resume_files, position_id, job_description)核心實現思路是在上傳組件支持 zip 格式,解壓后遞歸掃描所有簡歷文件,然后調用現有的批量處理邏輯即可。
4.2薪資期望范圍提取與預算匹配
薪資是招聘決策中的關鍵因素,但人工查看每份簡歷判斷是否在預算內,無疑會浪費大量時間在預算不匹配的候選人上。如果系統能自動提取薪資期望并與崗位預算對比,就可以在篩選階段就過濾掉不合適的候選人。
# 1. 擴展數據模型
class AIResumeAnalysis(BaseModel):
# ... 原有字段 ...
expected_salary_min: int = Field(default=0, descriptinotallow="期望月薪下限(K)")
expected_salary_max: int = Field(default=0, descriptinotallow="期望月薪上限(K)")
# 2. 在Prompt中增加提取指令(analysis_prompts.py)
# "從簡歷中提取薪資期望,統一轉為月薪,如'20-25K'或'年薪30萬'→25K"
# 3. 在UI中顯示匹配狀態
if candidate.expected_salary_max <= position.salary_budget_max:
st.success(f"? 預算內 ({candidate.expected_salary_min}-{candidate.expected_salary_max}K)")核心實現思路,是在大模型分析的 Pydantic 模型中增加薪資字段,在 Prompt 中增加提取指令,大模型會自動識別各種薪資表述("20-25K"、"年薪 30 萬"等)并歸一化為統一格式。
4.3AI 生成面試問題清單
篩選出候選人后需要準備面試問題,要仔細讀簡歷找出可以深挖的點。如果系統能根據簡歷和崗位要求自動生成針對性的面試問題,可以大幅提升面試準備效率。
# 生成面試問題的核心Prompt
PROMPT = """基于簡歷和崗位要求,生成面試問題:
- 能力驗證: 驗證簡歷中的技能是否真實
- 項目深挖: 了解關鍵項目的實際貢獻
- 短板確認: 針對"{key_concerns}"提問
輸出JSON: {{"ability": [...], "project": [...], "weakness": [...]}}
"""
# 調用LLM生成
response = llm.complete(PROMPT.format(key_cnotallow=candidate.ai_concerns))
questions = json.loads(response.text)
# 在詳情頁展示
st.subheader("?? AI生成的面試問題")
for category, qs in questions.items():
for q in qs:
st.write(f"? {q}")核心實現思路是設計一個專門的 Prompt,讓 LLM 基于簡歷內容和分析結果,生成分類的面試問題(能力驗證、項目深挖、短板確認等)。
5、寫在最后
現在,當大家談論大模型企業應用落地的時候,默認的潛臺詞都是企業主導、集中部署。而現實情況是,企業去落地一個面向于不同部門的大模型應用,是一個道阻且長的過程。但實際上像 HR、律師、會計這類專業工作者,每天也在做大量重復勞動。如果能把這套系統打包成一個開箱即用的桌面應用,內置嵌入模型、向量數據庫、開源 LLM,完全本地運行,不依賴云服務,可以更加短平快的的給很多崗位帶來提效或者解放雙手。
這個項目中演示時使用的 qwen3:8b(Q4 量化版)5.2GB大小,在我的 24GB 內存 MacBook 上,首字響應時間大概 5 秒,后續 token 生成速度相對比較流暢。但這個性能對大部分 HR 的工作電腦來說是個不小的挑戰。DeepSeek 年初開源的蒸餾后的小尺寸模型,在智力水平和電腦性能要求上都不夠實用,但現在似乎重新來到了端側模型應用重新爆發的臨界點。一方面,1.5B-3B 的小模型配合垂直領域微調,完全可以勝任簡歷篩選這類專業場景。其次,更優秀的小尺寸開源模型更新的速度我想也會超出大家的預期。
從創業視角來看,這不僅是 2B 市場的機會,更是面向專業個人用戶(像 Cursor 面向開發者那樣)的增量市場。讓專業工作者都能擁有自己的大模型應用助手,而不是一味的等待企業采購,這或許是接下來非常值得保持關注的長尾需求。