作者 | 崔皓
審校 | 重樓
開篇
在大模型時代,每一位 AI 玩家都面臨著嚴重的“顯存焦慮”。當你試圖在本地運行 Qwen2-72B 或者 Llama-3-70B 這樣的大參數模型時,現實往往會給你一記重錘——單張 RTX 3060 甚至 RTX 4090 的顯存根本不夠用,滿屏的 OOM(Out Of Memory)讓人絕望。
更尷尬的是,很多朋友手里其實不止一臺電腦:也許你有一臺主力臺式機,還有一臺舊的游戲本,或者像我一樣,正好有兩臺配置不錯的 PC(比如兩臺 RTX 3060 12G)。算力分散在兩臺物理機上,能不能把它們“合體”,像堆積木一樣擴展顯存?
答案是肯定的。本文將記錄從零開始,在 Windows WSL2 環境下,利用 vLLM(當前最火的推理框架)和 Ray(分布式計算框架),將兩臺消費級 PC 組成推理集群的全過程。不需要重裝 Linux 系統,也能享受原生的分布式推理體驗。
文章結構更像一本分布式大模型部署的操作手冊,大家可以按照順序一次閱讀。我們會從最簡單的顯卡驅動以及 CUDA 安裝開始,做到真正的 0 基礎部署分布式大模型系統。在開始分布式部署之前,會先進行單機 LLM 的部署作為熱身,確保單臺機器基礎環境正常,實現單機推理。然后在兩臺主機 A 和 B (Windows)通過WSL2 去安裝 Linux 系統,同時會解決虛擬系統帶來的網絡橋接問題。接著 vLLM +Ray 的組合搭建大模型推理集群。最后進行成果驗收,編寫對話界面,見證雙機集群驅動的本地對話網頁。
安裝前準備
本次我們的目的是在兩臺主機上安裝 LLM 并且實現分布式推理,在進行部署之前需要做一些必要的準備。比如顯卡驅動、CUDA 等安裝,如果已經完成上述安裝,可以跳過這個步驟。
安裝顯卡驅動
本例中我們使用的是英偉達 RTX3060 的顯卡,需要安裝驅動程序,去到官網下載最新顯卡驅動。
如下圖所示,輸入顯卡相關信息。

選擇完畢之后,點擊“Find”按鈕在隨后的頁面中,如下圖所示,點擊“View”選擇 “NVIDIA Studio驅動程序”。

緊接著,如下圖所示, 點擊“Download”按鈕進行驅動的下載。

安裝過程比較簡單,這里就不贅述了,可以選擇“精簡安裝”,其他選項使用“默認”。
安裝 CUDA
顯卡驅動安裝完成后,如下圖所示,在NVIDIA控制面板中查看驅動支持CUDA 的最高版本。我們看到的是 CUDA 13.0.84,也就是說我們安裝的 CUDA 版本不高于這個版本就可以了。

接著來到官網 CUDA Toolkit Archive,如下圖所示,選擇CUDA 12.8.1,為什么不下載更高的 CUDA 13 的版本,后面我們給出解釋。

按照上圖下載完畢之后,就可以按照默認選項安裝,比較簡單,此處不描述了。
重點來了,由于后面要安裝的是 vllm v0.11.0 版本,通過官方文檔可以得知,vLLM 最新版本的二進制文件默認使用 CUDA 12.8,當我安裝的時候最新版本的 vLLM 就是v0.11.0。因此,vLLM v0.11.0 默認使用的是 CUDA 12.8。
說白了,就是最新版本的 vLLM 默認支持 CUDA 12.8 ,如果你的顯卡支持其他版本的 CUDA 就需要手動安裝 vLLM 安裝包。所以, 這里為了偷懶,我們直接為顯卡安裝 CUDA 12.8 版本,反正我們的顯卡低于 CUDA 13 的版本都可以支持,主要是使用vllm v0.11.0 版本已經默認安裝好的對應CUDA 12.8 的包。否則,就需要手動安裝 vLLM 的相關組件。
下面內容引用自 vLLM 官網。
截至目前,vLLM 的二進制文件默認使用 CUDA 12.8 和公開的 PyTorch 發行版本編譯。我們還提供了使用 CUDA 12.6、11.8 以及公開 PyTorch 發行版本編譯的 vLLM 二進制文件:
# Install vLLM with a specific CUDA version (e.g., 11.8 or 12.6).
export VLLM_VERSION=$(curl -s https://api.github.com/repos/vllm-project/vllm/releases/latest | jq -r .tag_name | sed 's/^v//')
export CUDA_VERSION=118 # or 126
uv pip install https://github.com/vllm-project/vllm/releases/download/v${VLLM_VERSION}/vllm-${VLLM_VERSION}+cu${CUDA_VERSION}-cp38-abi3-manylinux1_x86_64.whl --extra-index-url https://download.pytorch.org/whl/cu${CUDA_VERSION}由于我們使用的是 Windows 系統,打開PowerShell,執行如下命令查看CUDA版本:
nvcc --version
部署單節點 vLLM
在完成了顯卡驅動和 CUDA 安裝之后,我們現在單機上安裝 vLLM 練練手。這里我們采取 Docker 的安裝方式,建議先安裝好 Docker Desktop,由于安裝比較簡單這里不贅述,我給出其安裝地址。
在 Windows PowerShell中執行如下命令:
docker run --name Qwen2-0.5B --runtime nvidia --gpus all -p 8000:8000 -e
VLLM_USE_MODELSCOPE=true --ipc=host vllm/vllm-openai:latest --model Qwen/Qwen2.5-0.5B-Instruct --gpu-memory-utilization 0.7指令參數 | 含義說明 |
--name Qwen2-0.5B | 給啟動的 Docker 容器命名為 Qwen2-0.5B,方便后續通過 docker stop/rm Qwen2-0.5B管理 |
--runtime nvidia | 指定容器使用 nvidia 運行時,核心作用是讓容器能訪問宿主機的 NVIDIA GPU |
--gpus all | 給容器分配宿主機所有 NVIDIA GPU 資源;若只想分配 1 塊,可改為 --gpus device=0 (指定第 1 塊 GPU) |
-p 8000:8000 | 端口映射:將宿主機的 8000 端口映射到容器內的 8000 端口,外部可通過 http://宿主機IP:8000訪問模型服務 |
-e VLLM_USE_MODELSCOPE=true | 設置容器內環境變量,告訴 vLLM 框架從「魔搭(ModelScope)」下載 Qwen 模型(無需手動下載模型文件,框架自動拉取) |
--ipc=host | 讓容器使用宿主機的 IPC(進程間通信)命名空間,解決大模型運行時共享內存不足的問題(避免 OOM 或性能下降) |
vllm/vllm-openai:latest | 使用 vLLM 官方提供的鏡像:- vllm/vllm-openai,集成了 vLLM 框架 + OpenAI 兼容接口的鏡像 |
--model Qwen/Qwen2.5-0.5B-Instruct | 指定要加載的模型名稱(魔搭上的標準模型名),vLLM 會自動從 ModelScope 拉取該模型 |
--gpu-memory-utilization 0.7 | 設置 GPU 顯存利用率為 70%(即只使用 GPU 顯存的 70%),預留 30% 顯存避免顯存溢出(比如 16G 顯存的 GPU 最多用 11.2G) |
執行命令之后, 如下圖所示,開始從魔搭社區拉取模型。

下載完成之后可以在Docker Desktop 中看到運行中的 “Qwen2-0.5B”容器。

測試模型
在單節點部署完成后,可運行下面的腳本啟動streamlit頁面進行對話。需要說明的是,這套腳本會用到之后的分布式部署,所以在完成分布式模型部署之后,還會用到它一次。
輸入如下指令,安裝依賴組件。
pip install streamlit requests openai腳本內容比較簡單,主要就是通過 URL 調用 Docker 中的 vLLM 服務,并返回大模型推理的結果。
腳本中的 vllm_hostvllm_portapi_keymodel_name 需要根據 vllm 服務啟動參數來修改。
import streamlit as st
import time
from openai import OpenAI
# 設置頁面配置
st.set_page_config(
page_title="VLLM 對話助手",
page_icon="??",
layout="wide"
)
# 頁面標題和說明
st.title("?? VLLM 對話助手")
# 側邊欄 - API設置
with st.sidebar:
st.header("OpenAI 兼容 API 配置")
st.info("請確保vLLM服務已啟動并啟用OpenAI兼容模式")
# 調試模式開關
debug_mode = st.checkbox("啟用調試模式", value=False)
# API設置
vllm_host = st.text_input("vLLM 主機地址", value="localhost",
help="Docker主機地址,通常是localhost或容器IP")
vllm_port = st.text_input("vLLM 端口", value="8000",
help="Docker映射的端口")
api_key = st.text_input("API 密鑰", value="token-123",
help="vLLM啟動時設置的API密鑰")
model_name = st.text_input("模型名稱", value="Qwen/Qwen2.5-0.5B-Instruct",
help="vLLM中部署的模型名稱")
# 模型參數設置
st.subheader("生成參數")
temperature = st.slider("Temperature", 0.0, 1.0, 0.7, 0.1)
max_tokens = st.slider("最大生成 tokens", 100, 2000, 500)
top_p = st.slider("Top P", 0.0, 1.0, 0.95, 0.05)
# 重置對話按鈕
if st.button("重置對話"):
st.session_state.messages = []
st.success("對話已重置")
# 初始化對話歷史
if "messages" not in st.session_state:
st.session_state.messages = []
# 顯示對話歷史
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# 處理用戶輸入
if prompt := st.chat_input("請輸入你的問題..."):
# 添加用戶消息到對話歷史
st.session_state.messages.append({"role": "user", "content": prompt})
# 顯示用戶消息
with st.chat_message("user"):
st.markdown(prompt)
# 調用VLLM OpenAI兼容API
with st.chat_message("assistant"):
message_placeholder = st.empty()
full_response = ""
try:
# 初始化OpenAI客戶端,指向vLLM服務
client = OpenAI(
base_url=f"http://{vllm_host}:{vllm_port}/v1",
api_key=api_key
)
# 調試信息
if debug_mode:
with st.expander("調試信息", expanded=False):
st.write(f"API地址: http://{vllm_host}:{vllm_port}/v1")
st.write(f"使用模型: {model_name}")
st.write("對話歷史:", st.session_state.messages)
# 發送請求(流式)
stream = client.chat.completions.create(
model=model_name,
messages=st.session_state.messages,
temperature=temperature,
max_tokens=max_tokens,
top_p=top_p,
stream=True
)
# 處理流式響應
for chunk in stream:
if chunk.choices[0].delta.content is not None:
full_response += chunk.choices[0].delta.content
message_placeholder.markdown(full_response + "▌")
time.sleep(0.02) # 控制顯示速度
message_placeholder.markdown(full_response)
# 添加助手回復到對話歷史
st.session_state.messages.append({"role": "assistant", "content": full_response})
except Exception as e:
error_msg = f"發生錯誤: {str(e)}"
message_placeholder.markdown(error_msg)
if debug_mode:
st.exception(e) # 在調試模式下顯示完整異常信息
# 頁腳信息
st.caption("使用OpenAI客戶端連接vLLM | 支持完整對話歷史")特別說明一下api_key 參數可以手動設置,我這里就沒有設置,所以在腳本中隨便寫了一個不會影響結果。這個參數在本例中不填,不會影響結果。現在這里的目的是讓大家知道可以設置它,如果要對外暴露你的 vLLM 推理服務可以通過它提高安全權限。
通過如下指令,啟動streamlit。
streamlit run chat_vllm.py啟動成功。


如何確定分布式部署策略?
好了,到這里我們快速地實現了 vLLM 在單機上的部署,由于使用了 Docker 部署的方式,所以沒有輸入任何一條 vLLM 命令就將其部署了。所以,大家對 vLLM 還沒有一個基本認識,在這里我們也介紹一下 vLLM。
vLLM 是用于大語言模型(LLM)推理和服務的庫,最初由加州大學伯克利分校的 Sky Computing 實驗室開發,后發展成社區驅動的項目。它協助工程師完成大模型部署和推理工作。在推理過程中,通過 PagedAttention 高效管理注意力鍵值內存,可對傳入請求進行連續批處理,利用 CUDA/HIP 圖實現快速模型執行,還支持多種量化方式及優化的 CUDA 內核,并且有投機解碼、分塊預填充等特性。
在使用方面,vLLM 靈活且方便。它能與流行的模型平臺無縫集成(本例 ModelScope),支持多種解碼算法實現高吞吐量服務,支持張量并行和流水線并行進行分布式推理,提供流式輸出和兼容 OpenAI 的 API 服務器。此外,它還支持多種硬件,有前綴緩存和多 LoRA 支持。因此,它能有效解決大模型部署中顯存焦慮、算力閑置等問題,提升部署效率和性能。
好了,給 vLLM 吹了一通彩虹屁之后,我們來到重點部分了。如何確認分布式部署的策略?答案是需要依據模型大小和可用計算資源來選擇。具體分為如下幾種情況考慮:
單 GPU 推理策略
當模型規模較小,能夠完整地放入單個 GPU 中時,通常無需使用分布式推理。這種情況下,直接利用單個 GPU 進行推理是最直接且有效的方式。因為單 GPU 推理避免了分布式推理帶來的額外通信開銷和復雜性,能夠更高效地完成推理任務。
單節點多 GPU 推理策略
若模型太大,單個 GPU 無法容納,但可以在擁有多個 GPU 的單個節點中運行,此時可采用張量并行推理策略。張量并行的規模取決于想使用的 GPU 數量。例如,在單個節點中有 4 個 GPU,就可以將張量并行規模設置為 4。通過這種方式,模型的張量可以在多個 GPU 之間并行處理,從而提高推理效率。
多節點多 GPU 推理策略
當模型規模極大,甚至單個節點都無法容納時,就需要同時使用張量并行和流水線并行推理策略。其中,張量并行的大小是每個節點中使用的 GPU 數量,流水線并行的大小是使用的節點數量。例如,有 2 個節點共 16 個 GPU(每個節點 8 個 GPU),可以將張量并行大小設置為 8,流水線并行大小設置為 2。
這樣,模型不僅可以在單個節點內的多個 GPU 上并行處理張量,還能在多個節點之間進行流水線式的并行處理,進一步提升推理性能。在添加足夠的 GPU 和節點以容納模型后,可運行 vLLM 評估當前配置下可服務的最大令牌數,若結果不理想,可繼續增加資源以提高吞吐量。
總而言之,模型能放入單個 GPU 時用單 GPU 推理;模型大到無法放入單個 GPU 但能放入單節點多 GPU 時采用張量并行推理;模型無法放入單個節點時則使用張量并行加流水線并行推理。添加足夠資源容納模型后,可運行 vLLM 評估可服務的最大令牌數,若不理想可繼續增加資源。
如何判斷模型占用 GPU 顯存
了解分布式模型部署策略之后,我們知道影響模型部署的關鍵因素是模型所占顯存的大小。為了方便大家估算,我們這里整理了一個簡單公式:
GPU存儲=大模型自身占用內存+KVCache內存+其他內存
坦率地說這個公式并不是很嚴謹,如果要做模型部署的朋友,可以去網絡上找一些工具協助估算。
比如我就經常用 https://tools.thinkinai.xyz/ 估算 DeepSeek 模型部署需要的資源。其他的工具大家可以自行查找,否則就有打廣告的嫌疑了。
我們回到技術上來,通過下面的表格讓大家了解模型占用空間的主要組成部分-KVCache內存。因為一般大模型自身占用內存,廠商都會給出通常數據和參數成正比。

計算公式:
SKV Cache(Bytes)=2×l×b×h×n×dk×P。其中,2 代表 K 和 V 兩組向量;l 是模型層數;b 是批處理大小;h 是每層注意力頭數量;n 是當前序列長度;dk 是每個注意力頭維度;P 是元素精度(字節計)。
示例:
Size (bytes)=2?32?1?32?1000?128?2
Size=524,288,000 字節
大約 500 MB 內存占用
使用 Ray 創建模型集群
聊完了大模型的分布式部署思路和內存占用之后,我們來看看用什么工具對其進行分布式部署?答案是 Ray,Ray 是一個用于擴展 AI 和 Python 應用程序(如機器學習)的開源統一框架。它為并行處理提供計算層,讓用戶無需成為分布式系統專家。Ray 借助以下組件降低運行分布式工作流和端到端機器學習工作流的復雜度:針對常見機器學習任務的可擴展庫、對 Python 應用程序進行并行化和擴展的分布式計算原語,以及與現有工具和基礎設施的集成與實用程序。

- 數據(Data):可擴展、與框架無關的數據加載和轉換,適用于訓練、調優和預測階段。
- 訓練(Train):支持分布式多節點和多核的模型訓練,具備容錯能力,并且能與流行的訓練庫集成。
- 調優(Tune):可擴展的超參數調優,用于優化模型性能。
- 服務(Serve):可擴展且可編程的服務,用于部署模型以進行在線推理,還可選擇使用微批處理來提升性能。
- 強化學習庫(RLlib):可擴展的分布式強化學習工作負載處理能力。
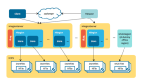
我們這里需要通過 Ray 幫我們創建 vLLM 推理集群,讓兩臺主機 A 和 B 作為集群的成員。因此, 需要了解 Ray 集群的概念。
如下圖所示,Ray 集群存在 Head 和 Worker 節點。

- Head node(主節點)
每個 Ray 集群都有一個節點被指定為集群的主節點。頭節點與其他工作節點相同,唯一不同的是它還運行負責集群管理的單例進程,例如 autoscaler、GCS 和 Ray 驅動進程。這些進程運行 Ray 任務。Ray 可能會像對待其他工作節點一樣,在頭節點上調度任務和其他節點,但在大規模集群中,這并不理想。有關大規模集群中的最佳實踐,請參見 配置頭節點。
- Worker node(工作節點)
工作節點不運行任何頭節點管理進程,僅用于在 Ray 任務和 actor 中運行用戶代碼。它們參與分布式調度,以及集群內存中 Ray 對象的存儲和分發。
分布式模型部署思路
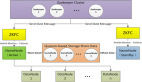
基于 Ray 集群的概念,我們設計主機 A 和 B 的集群思路如下圖所示。我們會在 Windows WSL 環境下使用 Ray 框架對大模型進行多主機分布式部署的架構和流程。
如下圖所示,將兩臺獨立的 Windows PC(主機 A 和主機 B)上的 WSL 實例虛擬化成一個 Ray 分布式集群,共同為 vLLM 提供算力。
這里我們對下圖內容進行簡單描述:
- 用戶請求入口:用戶請求首先發送到 主機 A 上的 vLLM 服務接口。
- Head 節點注冊:主機 A 上的 Ray 實例啟動時,加入集群并注冊成為 Head 節點(Head-A)。
- Worker 節點加入:主機 B 上的 Ray 實例啟動時,加入集群并注冊成為 Worker 節點(Worker-B),它會連接到 Head-A。
- 分布式推理:vLLM 服務利用 Ray 框架,將大模型(如 Qwen-0.5b,盡管圖中標注為 0.5b,但在實際分布式部署中通常是更大的模型)的計算任務拆分,分配給 Head 節點和 Worker 節點上的 GPU 共同進行推理。

將圖中出現的組件列出一個清單如下:
組件 | 對應的主機/系統 | 功能描述 |
主機 A & 主機 B | 物理主機 (Windows) | 提供硬件基礎(CPU/內存/GPU)。 |
WSL | Windows 子系統 (Linux) | 虛擬化環境,提供一個統一的 Linux 環境來運行 Ray 和 vLLM,解決了 Windows 上直接部署分布式環境的難題。 |
Ray 集群 | 跨 WSL 實例 | 分布式調度核心。負責節點的發現、資源的分配以及任務的調度。 |
Head 節點 (Head-A) | 主機 A 的 Ray 實例 | 集群大腦。負責接收用戶請求、管理 Worker 節點、并運行 Ray 的 GCS(全局控制服務)等管理進程。 |
Worker 節點 (Worker-B) | 主機 B 的 Ray 實例 | 算力提供者。不運行集群管理進程,僅用于執行 vLLM 分布式推理所需的計算任務和存儲 Ray 對象。 |
vLLM (Qwen-0.5b) | 跨 Ray 節點 | 大模型推理服務。它利用 Ray 集群的分布式能力,將大模型的不同部分(例如使用流水線并行)分布到 Head-A 和 Worker-B 上的 GPU 運行。 |
分布式模型部署
好了,思路說完了,接下來就是操作部分了。沒有廢話,大家按照步驟一步步執行。
當前環境有兩臺主機,分別為A和B。
主機A
處理器 12th Gen Intel(R) Core(TM) i7-12700K (3.60 GHz)
內存 64.0 GB (63.8 GB 可用)
顯卡 NVIDIA GeForce RTX 3060 12GB
CUDA版本 13.0
系統類型 64 位操作系統
基于 x64 的處理器版本 Windows 11 專業版版本號 24H2
操作系統版本 26100.7171
主機B
主機 B處理器 12th Gen Intel(R) Core(TM) i7-12700F (2.10 GHz)
內存 96.0 GB (95.8 GB 可用)
顯卡 NVIDIA GeForce RTX 3060 12GB
CUDA版本 13.0
系統類型 64 位操作系統
基于 x64 的處理器版本 Windows 11 專業版版本號 24H2
操作系統版本 26100.7171
請注意下面操作(1-6)需要在主機 A 和 B 上同時執行。步驟(7-9)會在主機 A 和 B 上分別執行, 我會特別標注。
1、安裝WSL ubuntu22.04
在PowerShell中執行命令,安裝ubuntu22.04。
wsl --install -d Ubuntu-22.04安裝完成后會提示輸入新用戶名和密碼,這里測試用戶和密碼都是user。
查看安裝結果:
wsl --list --verbose看到如下圖所示,表明 WSL 安裝完成。

然后執行,如下指令進入到 WSL 的虛擬系統中,執行后續網絡操作。
wsl -d Ubuntu-22.042、配置橋接網絡
這里我們需要處理兩個節點 A 和 B 之間的通訊,但是 vLLM 本身是安裝在 Windows 的 WSL 中的。 WSL 是 Windows Subsystem for Linux,從名字可以理解為是 Windows 操作系統中的 Linux 虛擬機。所以,這里需要解決從 A 主機的虛擬機與 B 主機的虛擬機之間的通訊問題。
先整理思路,我們需要創建一個橋接交換機,讓它鏈接 WSL 的網卡(虛擬)和主機的網卡(真實)。
如下圖所示,WSL 中的虛擬網卡通過虛擬交換機與 Windows 中管理的真實網卡進行通訊,再由真實網卡實現主機 A 和 B 之間的通信,從而實現集群的效果。

需要注意的是,由于我們使用的是 Windows 中的 WSL 系統,所以需要進行網卡的映射,如果使用 Linux 系統可以跳過這部分。
安裝Hyper-V
為了啟用橋接網絡,先要啟用 Windows 中的 Hyper-V 模塊協助完成。
Hyper-V 是 微軟開發的原生硬件虛擬化技術(Type-1 型虛擬機監控程序),直接運行在宿主機硬件之上,可在 Windows 系統中創建和管理多個獨立的虛擬機(VM)。
Hyper-V 主要完成硬件虛擬化的工作,為 WSL 的網卡提供虛擬化服務。
通過如下命令,安裝 Hyper-V :
Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Hyper-V -All如下圖所示,選擇“Y”,重啟計算機,從而完成安裝。

獲取物理網卡名字
接著,需要查找真實網卡的名字,用來創建橋接。
通過在PowerShell執行如下命令:
Get-NetAdapter輸出如下圖所示,我們使用的是 WiFi 作為網卡,所以“WLAN”就是網卡的名字。

設置虛擬交換機
獲取網卡名稱之后,就可以創建名為“WSLBridge”的虛擬交換機,指定網卡名為“WLAN”用來網絡橋接。
執行如下命令:
New-VMSwitch -Name "WSLBridge" -NetAdapterName "WLAN" -AllowManagementOS $true執行成功,會得到下圖內容:

配置橋接文件
最后,還需要配置橋接信息,讓 WSL 系統運行的時候,知道如何讓虛擬網卡通過哪個虛擬交換機與硬件網卡通訊。
按照如下路徑找到 “.wslconfig”文件,如果沒有這個文件可以創建一個新的。
C:\Users\<你的用戶名>\.wslconfig在文件中添加如下內容:
[wsl2]
networkingMode=bridged
vmSwitch=WSLBridge這兩行是關鍵:
配置項 | 作用 |
networkingMode=bridged | 讓 WSL2 虛擬機使用橋接模式(取代默認 NAT 模式) |
vmSwitch=WSLBridge | 指定使用的 Hyper-V 虛擬交換機名稱(前面創建的) |
確認橋接成功
關閉所有 WSL 實例,執行如下指令:
wsl --shutdown然后,重新啟動 WSL 系統:
wsl -d Ubuntu-22.04分別在主機 A 和 B 執行如下命令,檢測橋接之后的網絡設置是否正確。
hostname -I如果兩臺主機返回類似“192.168.0.x”的 IP 地址都在同一個網段,說明橋接成功了。
3、更新系統與基礎工具
針對 WSL 系統更新必要的工具和組件,如下:
# 更新系統
sudo apt update && sudo apt upgrade -y
# 安裝 Python3、pip、git、curl
sudo apt install -y python3 python3-pip git curl wget build-essential這段命令主要用于系統環境的更新與基礎工具的安裝。
首先,通過 `sudo apt update && sudo apt upgrade -y` 更新系統,`update` 用于獲取軟件包的最新信息,`upgrade` 則將已安裝軟件包升級到最新版本。接著,使用 `sudo apt install -y` 命令安裝 Python3、pip、git、curl 等常用工具及編譯所需的基礎組件。
4、安裝Ray 集群框架
接著,執行如下命令,命令用于配置和安裝 Ray 相關環境。首先,將 pip 源更換為清華源,以加快下載速度。接著,升級 pip 到最新版本。然后,使用 pip 安裝 Ray 2.50.0 版本,且包含分布式支持。最后,通過 Python 代碼導入 Ray 并打印其版本號,以此驗證 Ray 是否成功安裝。
# 更換pip源:清華源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 升級 pip
python3 -m pip install --upgrade pip
# 安裝 Ray(含分布式支持)
pip install "ray[default]==2.50.0"
# 驗證 Ray 安裝
python3 -c "import ray; print(ray.__version__)"上述工具會自動安裝到~/.local/bin下面,為了通過工具的命令直接執行工具,需要執行如下代碼,將其目錄保存到環境變量中。
# 添加PATH
echo 'export PATH=$PATH:~/.local/bin' >> ~/.bashrc
# 應用
source ~/.bashrc5、安裝 vLLM 推理服務
執行如下命令安裝 vLLM:
pip install "vllm==0.11.0"注意, 此時安裝 vllm 有可能會升級 click 的版本,通過如下命令查看click版本。
pip show click如果 click版本 > 8.2.1會導致ray運行出錯,因此需要通過如下命令重新安裝 click,保證其版本為 8.2.1。
# 先卸載
pip uninstall click -y
# 安裝低版本
pip install "click==8.2.1"安裝完畢之后,再查看ray版本。
ray --version正常輸出:ray, version 2.50.0 表明 click 8.2.1 安裝成功。
6、修改模型下載路徑
由于我們使用ModelScope 下載 LLM,最好設置一下模型存放目錄,避免將 C 盤占滿。
pip install modelscope
echo 'export VLLM_USE_MODELSCOPE=true' >> ~/.bashrc
echo 'export MODELSCOPE_CACHE=/mnt/e/vllm/model/.cache' >> ~/.bashrc
source ~/.bashrc上面的命令執行后不會有輸出,在下載模型時就可以看到路徑是/mnt/e/vllm/model/.cache。
使用 ModelScope 下載模型(在每個節點要配置):
- VLLM_USE_MODELSCOPE=true:默認使用ModelScope下載模型。
- MODELSCOPE_CACHE=/mnt/e/vllm/model/.cacheModelScope:默認下載模型路徑,/mnt/e/vllm/model/.cache是WSL中的路徑,其中/mnt/e對應的是Windows下的E盤,可以根據實際情況選擇其他盤來保存下載的模型。
7、啟動 Head 節點 (主機A)
我們切換到主機 A,創建如下腳本,存放到/mnt/e/vllm目錄中(e:/vllm),可以根據具體情況存放目錄。
vim start_head.sh此腳本用于 WSL 分布式推理,自動檢測節點信息,設置環境變量,啟動 Ray Head 節點和 vLLM 服務并顯示集群狀態。
#!/bin/bash
set -e
# ===============================
# 啟動 Ray Head 節點 + vLLM 的一鍵腳本(用于 WSL 分布式推理)
# ===============================
# -------------------------------
# 自動檢測當前節點的 IP 地址與默認網卡名
# -------------------------------
IP=$(hostname -I | awk '{print $1}') # 獲取第一個非回環地址(用于 Ray 通信)
IFNAME=$(ip route | grep default | awk '{print $5}') # 獲取默認出口網卡名,如 eth0、eth1
echo "?? Head Node Detected:"
echo " IP Address: $IP"
echo " Interface: $IFNAME"
echo "==================================="
# -------------------------------
# 設置分布式環境變量(非常關鍵)
# -------------------------------
export RAY_NODE_IP_ADDRESS=$IP
# ?? 告訴 Ray 當前節點的實際內網 IP(否則可能默認選 127.0.0.1)
export GLOO_SOCKET_IFNAME=$IFNAME
export NCCL_SOCKET_IFNAME=$IFNAME
# ?? 告訴 PyTorch/Gloo/NCCL 用哪個網卡進行分布式通信
# 否則默認選 127.0.0.1,導致 “Gloo connectFullMesh failed”
export MASTER_ADDR=$IP
export MASTER_PORT=29500
# ?? PyTorch 分布式初始化的主節點地址和端口(rendezvous 地址)
# Gloo 和 NCCL 都會用到這個端口進行節點間握手
# -------------------------------
# 啟動 Ray Head 節點
# -------------------------------
echo "?? Starting Ray Head Node..."
ray stop --force >/dev/null 2>&1 || true
# ?? 先強制清理舊的 Ray 進程,防止重復注冊節點導致錯誤
ray start --head \
--node-ip-address=$IP \
--port=6379 \
--dashboard-host=0.0.0.0
# ?? 啟動 Ray 集群的 Head 節點
# --node-ip-address 指定通信 IP
# --port 是 Ray 的主端口
# --dashboard-host=0.0.0.0 讓儀表盤能被其他機器訪問(默認 localhost)
echo "? Ray Head Started on $IP:6379"
echo "==================================="
# -------------------------------
# 顯示 Ray 集群狀態
# -------------------------------
ray status
# -------------------------------
# 啟動 vLLM 服務
# -------------------------------
echo "?? Starting vLLM Server..."
MODEL="Qwen/Qwen2-7B-Instruct"
PORT=8000
vllm serve $MODEL \
--host $IP \
--port $PORT \
--distributed-executor-backend ray \
--pipeline-parallel-size 2
# ?? 啟動 vLLM 服務并綁定到當前節點 IP
# --distributed-executor-backend ray 表示使用 Ray 分布式調度
# --pipeline-parallel-size 2 啟用兩節點流水線并行
# vLLM 會自動從 Ray 集群中分配 worker 節點執行上述腳本用于 WSL 分布式推理,先自動檢測當前節點的 IP 地址和默認網卡名,接著設置分布式環境變量,確保 Ray 和 PyTorch 等使用正確的通信地址和網卡。然后,強制清理舊的 Ray 進程,啟動 Ray Head 節點并指定通信 IP、端口等,顯示集群狀態。最后,啟動 vLLM 服務,綁定當前節點 IP,使用 Ray 分布式調度并啟用兩節點流水線并行。最重要的是,這里會開始下載模型:"Qwen/Qwen2-7B-Instruct"。
通過如下命令,給腳本添加可執行權限:
chmod +x start_head.sh如下命令執行腳本:
./start_head.sh如下圖所示,Head 節點已經啟動,正在等待 Worker 節點加入。我們注意到 Head 節點的 IP 為 192.168.0.14,這個 IP 在 worker 節點啟動的時候需要用到。

8、啟動 Worker節點(主機B)
完成 Head 節點啟動之后,接著需要啟動 Worker 節點,并且指定 Head 節點的 IP 地址,從而讓 Worker 節點加到 Ray 集群中。這樣當用戶訪問 Head 節點的時候就可以將請求分發到 Worker 節點上。
我們切換到主機 B, 創建 start_worker.sh 腳本。
vim start_worker.sh該腳本用于啟動 Ray Worker 節點,檢查 Head 節點 IP 參數,自動檢測本節點信息,設置環境變量后加入 Ray 集群。
#!/bin/bash
set -e
# ===============================
# 啟動 Ray Worker 節點的腳本
# 用法:
# ./worker.sh <HEAD_IP>
# 示例:
# ./worker.sh 192.168.0.14
# ===============================
# -------------------------------
# 參數檢查
# -------------------------------
if [ -z "$1" ]; then
echo "? 請指定 Head 節點 IP,例如:./worker.sh 192.168.0.14"
exit 1
fi
HEAD_IP=$1
# -------------------------------
# 自動檢測本節點 IP 和網卡名
# -------------------------------
IP=$(hostname -I | awk '{print $1}') # 當前節點 IP
IFNAME=$(ip route | grep default | awk '{print $5}') # 當前節點網卡名
echo "?? Worker Node Detected:"
echo " 本機 IP: $IP"
echo " 網卡接口: $IFNAME"
echo " Head 節點 IP: $HEAD_IP"
echo "==================================="
# -------------------------------
# 設置環境變量
# -------------------------------
export RAY_NODE_IP_ADDRESS=$IP # ?? 指定本 worker 在 Ray 集群中的注冊 IP
export GLOO_SOCKET_IFNAME=$IFNAME # ?? 告訴 Gloo 通信使用的物理網卡
export NCCL_SOCKET_IFNAME=$IFNAME # ?? 告訴 NCCL 通信使用的物理網卡
# -------------------------------
# 啟動 Ray Worker 節點
# -------------------------------
echo "?? 正在啟動 Ray Worker Node..."
# 清理舊的 Ray 實例(防止重復注冊)
ray stop --force >/dev/null 2>&1 || true
# 加入已有的 Ray 集群
ray start \
--address=${HEAD_IP}:6379 \
--node-ip-address=$IP
# -------------------------------
# 啟動完成提示
# -------------------------------
echo "? Ray Worker 已成功連接到 ${HEAD_IP}:6379"啟動 Ray Worker 節點的腳本,運行時需傳入 Head 節點 IP 作為參數。腳本會先檢查參數是否為空,若為空則提示并退出。接著,自動檢測本節點的 IP 和網卡名,設置 Ray 節點 IP 及通信所用物理網卡的環境變量。清理舊的 Ray 實例后,讓本節點加入指定 Head 節點所在的 Ray 集群,最后給出啟動完成提示。
依舊添加可執行權限,如下:
chmod +x start_worker.sh在執行腳本的時候需要傳入“192.168.0.14” ,也就是 Head 節點的 IP,從而讓 Worker 節點添加到 Ray 集群中。
./start_worker.sh 192.168.0.14執行完畢之后,可以通過如下圖看到,“Ray Worker 已經成功連接到 192.168.0.14:6379”的字樣。

9、檢查 Worker 節點是否添加到集群
我們切換到主機 B, 會看到如下圖所示的場景。當 Worker節點加入集群,Head 節點會自動建立與 Worker 節點的通信,并開始將模型分發到 Worker 節點。

啟動完成。

測試分布式模型部署
好了,開始測試分布式模型部署,下面的腳本和單機部署的腳本完全一樣。不過,此時“vLLM 主機地址”需要換成 Head node 所在的機器的 IP 地址。本例中的 Head node 的 IP 是 192.168.0.14 。你部署完畢之后,需要設置成對應的 Head node 的 IP 地址。
import streamlit as st
import time
from openai import OpenAI
# 設置頁面配置
st.set_page_config(
page_title="VLLM 對話助手",
page_icon="??",
layout="wide"
)
# 頁面標題和說明
st.title("?? VLLM 對話助手")
# 側邊欄 - API設置
with st.sidebar:
st.header("OpenAI 兼容 API 配置")
st.info("請確保vLLM服務已啟動并啟用OpenAI兼容模式")
# 調試模式開關
debug_mode = st.checkbox("啟用調試模式", value=False)
# API設置
vllm_host = st.text_input("vLLM 主機地址", value="localhost",
help="Docker主機地址,通常是localhost或容器IP")
vllm_port = st.text_input("vLLM 端口", value="8000",
help="Docker映射的端口")
api_key = st.text_input("API 密鑰", value="token-abc123",
help="vLLM啟動時設置的API密鑰")
model_name = st.text_input("模型名稱", value="Qwen/Qwen2.5-0.5B-Instruct",
help="vLLM中部署的模型名稱")
# 模型參數設置
st.subheader("生成參數")
temperature = st.slider("Temperature", 0.0, 1.0, 0.7, 0.1)
max_tokens = st.slider("最大生成 tokens", 100, 2000, 500)
top_p = st.slider("Top P", 0.0, 1.0, 0.95, 0.05)
# 重置對話按鈕
if st.button("重置對話"):
st.session_state.messages = []
st.success("對話已重置")
# 初始化對話歷史
if "messages" not in st.session_state:
st.session_state.messages = []
# 顯示對話歷史
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# 處理用戶輸入
if prompt := st.chat_input("請輸入你的問題..."):
# 添加用戶消息到對話歷史
st.session_state.messages.append({"role": "user", "content": prompt})
# 顯示用戶消息
with st.chat_message("user"):
st.markdown(prompt)
# 調用VLLM OpenAI兼容API
with st.chat_message("assistant"):
message_placeholder = st.empty()
full_response = ""
try:
# 初始化OpenAI客戶端,指向vLLM服務
client = OpenAI(
base_url=f"http://{vllm_host}:{vllm_port}/v1",
api_key=api_key
)
# 調試信息
if debug_mode:
with st.expander("調試信息", expanded=False):
st.write(f"API地址: http://{vllm_host}:{vllm_port}/v1")
st.write(f"使用模型: {model_name}")
st.write("對話歷史:", st.session_state.messages)
# 發送請求(流式)
stream = client.chat.completions.create(
model=model_name,
messages=st.session_state.messages,
temperature=temperature,
max_tokens=max_tokens,
top_p=top_p,
stream=True
)
# 處理流式響應
for chunk in stream:
if chunk.choices[0].delta.content is not None:
full_response += chunk.choices[0].delta.content
message_placeholder.markdown(full_response + "▌")
time.sleep(0.02) # 控制顯示速度
message_placeholder.markdown(full_response)
# 添加助手回復到對話歷史
st.session_state.messages.append({"role": "assistant", "content": full_response})
except Exception as e:
error_msg = f"發生錯誤: {str(e)}"
message_placeholder.markdown(error_msg)
if debug_mode:
st.exception(e) # 在調試模式下顯示完整異常信息
# 頁腳信息
st.caption("使用OpenAI客戶端連接vLLM | 支持完整對話歷史")啟動streamlit。
streamlit run chat_vllm.py啟動成功。


作者介紹
崔皓,51CTO社區編輯,資深架構師,擁有18年的軟件開發和架構經驗,10年分布式架構經驗。