基于 Arthas 量化監控診斷 Java 應用方法論與實踐
應用系統監控也是軟件研發中最重要的一環,從研發的角度來說,明確指出自己業務維度明確指出個人負責功能業務維度的系統監控指標,同時具備實時監控診斷的應對方法,是軟件架構成功的重要的一環。所以本文將針對故障和監控兩個重要概念展開探討,同時給出一種理想化的架構結合實踐案例基于參考,希望對你有所幫助。

一、淺談監控的基本概念
1. 故障的生命周期
故障的生命周期分為以下幾個階段:
- 故障開始
- 故障發現
- 故障定位
- 及時修復
- 系統恢復
這其中,故障發現和通知在市面上已經有一套相對成熟的體系參考,無論是運維還是研發總會有一套自己系統監控的理論,并在應用中完成運用實現監控和告警。 那么問題來了,從研發的角度,針對系統監控各項性能指標,如何明確定位到具體的錯誤?例如:
- 系統提示CPU飆升,面對宏觀的性能指標,我們如何知曉故障線程?
- web請求全體夯死,系統監控全面告知線程處于wating狀態,我們如何定位到問題的根因并優化?
- 程序堆內存飆升達到與之,我們如何定位到進程級別的具體問題對象從而定位到問題的棧幀?
如下圖,這就是筆者面板中最常見的容器線程直線飆升導致大量請求夯死超時,按照現有體系中的grafana監控面板,面對成百上千的接口請求,即時我們能夠準確的做到故障發現,也無法非常快速精準的做到故障定位:

缺少精準的定位動作,就看導致止損動作對故障恢復沒有任何幫助,就需要進行重新定位,進而導致負責人員花費大量時間在故障發現和止損動作之間循環往復的執行。
2. 筆者理想中的監控體系
監控是可以確保提前暴露被即時發現解決,同時也可以作為日常循環后系統調優的佐證。所以量化一切監控體系之后,我們就需要搭建一個完善、安全、成熟的監控診斷體系來排查定位問題, 以筆者研發的java應用為例,主流的應用監控會通過micrometer采集目標監控指標,并將其同步到prometheus并通過grafana進行增強渲染,在此基礎之上通過Nightingale針對這些告急的監控及時下發企微消息或者短信告警讓研發人員介入解決問題:

按照筆者上面的說法,這種做法存在如下幾個問題:
- 市面僅僅指定常見系統級別監控指標,粒度在如今的應用系統中顯得過于寬泛。
- 團隊指定指標往往會因為各種原因無法精準、明確,可快速定位檢索各種異常和監控故障的應用級別監控指標。
- grafana和Nightingale是面向于運維和研發的通用,且著重于監控可視化和閾值告警,并不能很好的做到監控診斷。
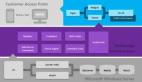
所以,在此基礎之上筆者也給出了一套基于自己常見的工具所衍生了一套帶有監控診斷的監控運維體系架構,即在上述監控體系下集成強阿里系中強大的監控診斷工具arthas。
如下圖,在這套監控體系下,通過arthas tunel遠程統一管理所有被arthas agent代理的java應用程序,當其他監控運維工具感知異常時,我們就可以快速通過瀏覽器attach到存在故障的進程中,以超細粒度靈活的指令和表達式定位java程序中對象內存占用、CPU利用率甚至是棧幀的調用細節:

二、基于arhtas的應用遠程監控實踐
1. arthas監控診斷體系說明
基于上述的說明,我們大體了解的監控診斷的一套理想架構,而本文將針對該架構進行演示和實踐,按照arthas官網的說明,對于spring boot項目,我們在項目中引入arthas-spring-boot-starter,其底層會啟動一個arthas進程并attach到裝配的應用上,由此構建出當前服務的arthas agent:

這一點,我們可以通過ArthasConfiguration的arthasAgent這個bean得以印證,可以看到它會拉取spring boot配置后,通過這個配置構建arthasAgent并調用init完成如下工作:
- 通過Instrumentation注冊字節碼轉換器即ClassFileTransformer,后續通過該技術實現類加載或者運行時字節碼動態增強
- 拉取一個artahs agent并attach到當前進程構成artahs服務端,監聽客戶端指令完成目標類增強:
對應筆者也給出這段源碼的視線入口,讀者可以自行參閱:
@ConditionalOnMissingBean
@Bean
public ArthasAgent arthasAgent(@Autowired Map<String, String> arthasConfigMap,
@Autowired ArthasProperties arthasProperties) throws Throwable {
arthasConfigMap = StringUtils.removeDashKey(arthasConfigMap);
// 給配置全加上前綴
Map<String, String> mapWithPrefix = new HashMap<String, String>(arthasConfigMap.size());
for (Entry<String, String> entry : arthasConfigMap.entrySet()) {
mapWithPrefix.put("arthas." + entry.getKey(), entry.getValue());
}
//基于配置完成構建artahs agent,完成arthas agent服務端初始化,監聽客戶端指令完成字節碼增強
final ArthasAgent arthasAgent = new ArthasAgent(mapWithPrefix, arthasProperties.getHome(),
arthasProperties.isSlientInit(), null);
arthasAgent.init();
logger.info("Arthas agent start success.");
return arthasAgent;
}同時,考慮到當前應用體系下成百個服務,我們需要有一個統一的入口集中化監控管理,所以為了能夠有一個統一的入口集中管理所有的agent,我們會專門用一臺與外界隔離的服務器部署一個Arthas Tunnel,讓所有的應用程序生成agent后統一與tunel建立連接,后續我們就可以通過tunel暴露的端口,統一管理監控診斷存在異常風險的應用程序:

2. 項目中集成arthas
對于需要arthas agent的程序,我們首先需要引入arthas 腳手架依賴包:
<dependency>
<groupId>com.taobao.arthas</groupId>
<artifactId>arthas-spring-boot-starter</artifactId>
<version>3.4.1</version>
</dependency>然后配置agent唯一id并指定tunel的注冊地址(默認暴露端口為7777):
arthas.agent-id=hsehdfsfghhwertyfad
arthas.tunnel-server=ws://127.0.0.1:7777/ws隨后我們到官網下載并啟動tunel:
java -jar arthas-tunnel-server-4.1.2-fatjar.jar此時我們就可以啟動我們的java程序了,控制臺出現如下提示,則說明服務啟動并成功注冊到arthas了:
2025-12-07 22:09:21.370 INFO 68696 --- [ main] c.a.arthas.spring.ArthasConfiguration : Arthas agent start success.
2025-12-07 22:09:21.483 INFO 68696 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 18080 (http)此時鍵入http://127.0.0.1:8080/即可進入tunel面板,鍵入剛剛的agentid即可直接進入監控面板:

這里補充說明一下感興趣的讀者可以到官網拉取arhtas的源碼包,以筆者為例這里選擇arhtas-all-3.6.0版本,并在配置文件中關閉redis監控,避免本機沒有redis服務端連接導致自動裝配階段報錯:
management.health.redis.enabled=false通過運行ArthasTunnelApplication將tunel啟動:

3. arthas tunel系統架構監控實踐
回到最早的問題,面對大量飆升處于wating狀態的線程因為監控工具和指標的局限性而發做到快速的監控診斷,有了arthas監控診斷體系架構,筆者用下面這樣的一個接口模擬一個存在問題的分頁查詢并演示一下快速的解決步驟:
@GetMapping("/slow-request")
public JSONObject handleUserPageQuery() {
// 調用service的用戶分頁列表查詢方法
return userService.getUserPageList();
}查看UserService的getUserPageList,可以看到其內部用休眠模擬分頁查詢的長耗時:
public JSONObject getUserPageList() {
log.info("開始查詢用戶分頁列表");
// 模擬耗時的用戶分頁列表查詢,休眠1分鐘
ThreadUtil.sleep(1, TimeUnit.DAYS);
// 構造分頁列表結果
JSONObject result = new JSONObject();
result.set("code", 200);
result.set("message", "success");
JSONObject data = new JSONObject();
data.set("total", 100);
data.set("pageSize", 10);
data.set("currentPage", 1);
// 模擬用戶列表數據
JSONObject user1 = new JSONObject();
user1.set("id", 1);
user1.set("name", "張三");
user1.set("email", "zhangsan@example.com");
JSONObject user2 = new JSONObject();
user2.set("id", 2);
user2.set("name", "李四");
user2.set("email", "lisi@example.com");
data.set("users", new JSONObject[]{user1, user2});
result.set("data", data);
log.info("用戶分頁列表查詢完成");
return result;
}通過上文的tunel入口,我們很快的進入到程序內部,簡單快速的定位的tomcat那些存在timewating的問題線程:

非常簡單干脆的定位到了問題線程的棧幀,很好的完成監控體系中的監控診斷這一步:

三、小結
筆者認為,一個健壯的系統運維監控體系是著重于強調量化且可感知觀測的,在日常工作的對接中,我發現大量研發人員都有一種計算機文科化的趨勢,小到應用程序指標調測,達到故障定位暴力迭代結合日志盲目推測。 結合這些問題,筆者通過這篇文章給出一個理想的監控體系,也希望對讀者有所啟發。