GPR:基于One Model端到端的生成式廣告推薦新范式
在人工智能領域,"One Model"(單一模型)范式正在成為一種新的技術信仰。從GPT系列統一自然語言處理任務,到DALL·E統一圖像生成;從國內快手 OneRec 再到如今騰訊廣告提出的GPR(Generative Pre-trained Recommender)——這種范式轉變背后的核心理念是:用一個端到端的生成式模型替代傳統的多階段級聯系統,實現目標一致、流程簡化和全局最優。
本文將深度解讀騰訊廣告與清華大學聯合發表的這篇突破性論文,重點關注GPR如何首次在工業級大規模廣告推薦業務中落地了端到端生成式框架,以及這一范式為何能在微信視頻號廣告系統中取得顯著的商業成功。
一、傳統范式的困境,為什么需要One Model?
1.級聯系統的固有難點
傳統的廣告推薦系統采用"檢索-預排序-排序"的多階段級聯架構,這種設計在工業界已經運行多年并高度優化。但論文指出,級聯系統是一個"局部最優"的系統,而非"全局最優"的系統,這種范式存在三個根本性問題:
- 目標錯位 Objective Misalignment:系統各部分在相互'掣肘',而非'協同'。檢索的優化,不等于排序的優化。檢索階段優化覆蓋率,排序階段優化業務指標(CTR、CVR等),各階段目標不一致,導致無法達到全局最優。
- 錯誤傳播 /信息瓶頸 Error Propagation:檢索階段的早期模型能力有限,可能過早地"錯殺”了高潛力的候選物料。一旦"金子"在第一關被丟掉,后續的排序模型(即使能力再強)也"永不"可能糾正這個錯誤。
- 工程負擔 Engineering Complexity:維護跨多個階段(模型、特征、目標)的一致性需要巨大的工程資源,這極大地阻礙了算法的快速迭代和系統擴展。每次優化都需要協調多個模塊,牽一發而動全身。
2.生成式推薦的挑戰
近年來,以LLM為代表的生成式模型展現了強大的能力。其核心理念是不再"排序",而是"直接生成"。模型直接根據對用戶興趣和上下文的"整體理解","生成"最優的推薦結果。這樣做的理論優勢是從根本上保證了"優化目標的一致性"徹底擺脫了級聯系統的多階段束縛。

雖然HSTU等工作已經將生成式建模引入推薦系統,但在大規模工業級廣告系統中仍面臨三大核心挑戰:
- 數據的極端異構性 Extreme Heterogeneity:廣告與有機內容在用戶序列中交錯,用戶行為異構(點擊、轉化、觀著、閱讀),數據分布極其嘈雜。這對模型的"統一表示能力"提出了極高要求。
- 效率與靈活性的權衡 Efficiency-Flexibility Trade-off:Decoder-only階段,訓練高效但推理靈活性差;Encoder-Decoder階段,推理靈活但訓練成本極高。廣告系統需要"兩者兼得":既要高效訓練,又要靈活解碼。
- 收入與多方價值優化 Revenue & Multi-stakeholder Value:廣告的"終極目標"不是點擊率,而是"生態系統總價值"(用戶體驗、廣告主ROI、平臺收入)的平衡。現有預訓練方法只關注單一的興趣建模,無法滿足實際需求,導致商業價值錯位。
這些挑戰使得現有生成式推薦模型難以在真實的工業廣告環境中落地。GPR的核心價值就在于系統性地解決了這些問題,實現了首次在工業級大規模廣告推薦業務中落地了端到端生成式框架。
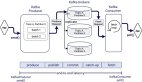
二、One Model 的設計哲學,GPR 的整體架構設計思路

在GPR的整體架構設計中,騰訊廣告率先在廣告行業構建了一個統一的生態一體化模型:
在生成與排序階段深度融合了豐富的商業信息,從最底層通過基礎大模型的預訓練,全面捕捉用戶興趣偏好。在此基礎上,GPR構建了復雜的強化學習框架,精準模擬線上用戶行為,這對提升廣告的商業價值和企業效益起到了關鍵作用。與此同時,GPR在模型中整合了多項與大模型相關的先進技術,如思維鏈等機制,并進行了深入的探索與實踐,取得了顯著的效果提升。
1.統一表示:四類 Token 構建語義空間
GPR 的第一個創新是設計了統一輸入模式(Unified Input Schema),將用戶的完整歷程表示為四類Token的序列:
- U-Token:用戶屬性和偏好
- O-Token:自然內容(視頻、文章)
- E-Token:環境/請求上下文(時間、場景)
- I-Token:交互過的廣告物料
這種設計的深刻之處在于:所有信息都被統一為連續的 Token 序列。無論是廣告還是有機內容,都被編碼為離散的語義ID,實現了真正的"萬物皆Token"。
RQ-KMeans+:解決"碼本崩潰"
為了將多模態內容轉化為語義ID,GPR提出了RQ-KMeans+量化模型。傳統的RQ-VAE和RQ-Kmeans存在"碼本崩潰"(codebook collapse)問題——大量向量(碼字)變得"死亡"(從末被激活),導致語義空間利用率低下。這會嚴重降低模型的表達能力和泛化性能,無法有效捕獲物料的豐富語義信息。
RQ-KMeans+的創新在于:
- 用RQ-Kmeans初始化高質量碼本,避免隨機初始化導致的崩潰
- 引入殘差連接,確保早期訓練階段輸出分布接近輸入分布
- 保持潛在空間靈活性,允許碼本根據訓練數據自適應更新
2.異構分層解碼器(HHD):理解與生成的分離
GPR的核心架構是異構分層解碼器(Heterogeneous Hierarchical Decoder, HHD),它包含三個關鍵模塊:
(1)HSD:異構序列解碼器(主解碼器)
HSD的任務是理解用戶 User lntent Modeling,處理超長異構行為序列 (U/O/E/I Tokens),生成高質量的 "意圖嵌入" 解決 "我是誰?我〔用戶〕的意圖是什么?"的問題。
它引入了三個關鍵技術:
- 混合注意力(Hybrid Attention):在U/O/E Tokens區域使用雙向注意力,允許這些"提示詞"(prompt)Token之間自由交互;在物品預測區域使用因果注意力。這種設計使模型能充分利用上下文信息。
- Token感知歸一化和FFN:為不同類型Token分配獨立的歸一化層和前饋網絡,將它們投影到各自的語義子空間,充分捕捉異構序列的語義多樣性。
- 混合遞歸(MoR)和外部知識注入:通過Mixture-of-Recursions機制增加模型深度和推理能力;同時集成微調的LLM生成的"思考過程",增強語義理解。
(2)PTD:漸進式Token解碼器(思考-精煉-生成)
PTD (Progressive Token-wise Decoder)的核心任務是生成物品 Ad Generation。在 HSD 生成的"意圖"指導下,逐步生成目標廣告的語義 ID。解決 "基于我的意圖,我〔模型〕應該生成哪個廣告?"的問題。
PTD采用了獨特的"Thinking-Refining-Generation"范式:
- Thinking(思考):生成K個思考Token,從意圖嵌入中提取關鍵信息,過濾無關成分
- Refining(精煉):受LLM推理研究啟發,引入基于擴散范式的精煉模塊,迭代去噪提升推理質量
- Generation(生成):基于思考Token和精煉Token,生成多級語義代碼表示目標廣告
這種分層設計實現了用戶理解與廣告生成的解耦,使得模型能夠更精細地捕捉用戶偏好,從而實現更準確的預測。
(3)HTE:分層Token評估器(價值估計)
HTE (Hierarchical Token-wise Evaluator)的任務是評估價值Value Estimation, 預測每個語義 ID 和最終物品的"業務價值”,用于指導解碼和 RL 訓練。解決 "這個生成的廣告值多少錢〔eCPM, final_value〕?"的問題。
廣告推薦不同于內容推薦,必須同時優化多個業務指標(CTR、CVR、eCPM等)。HTE模塊為每個語義代碼和最終物品估計價值,這種端到端的價值估計使得生成過程能夠直接對齊商業目標,而不是孤立優化單一指標。
3.價值引導的Trie樹解碼
在推理階段,基于生成式的推理往往存在 "陷阱",生成式模型雖然強大,但容易"放飛自我" :
- 生成不存在的 ID 或已下線的廣告。
- 生成不符合 "定向約束"(Targeting)的廣告(如:把女性化妝品推給男性)。
- 傳統的 Beam Search 不僅慢,而且可能保留大量低價值候選。
為此,GPR提出了Value-Guided Trie-Based Beam Search高效的解碼方案:
- 個性化索引樹 Trie-based Pruning:根據用戶畫像(年齡、性別等)動態構建 Trie 樹約束。在解碼每一步,直接 "屏蔽" 掉所有不符合定向規則的分支。
- 價值剪枝 Value-Guided Beam Width:利用 HTE 模塊實時預測每個分支的價值 (Value)。對高價值路徑給予更大的 Beam Width,低價值路徑盡早截斷。
這確保了每一毫秒的算力都花在 '最可能賺錢' 且 '合規' 的廣告上。
三、多階段聯合訓練,MTP → VAFT → HEPO

GPR的訓練策略是One Model范式成功的關鍵,它分為三個階段,構建了一個無縫統一"興趣建模"、"價值對齊"和"策略優化"的完整訓練流程。
1.預訓練:多Token預測(MTP)
傳統的Next-Token Prediction(NTP)假設用戶有單一主導興趣軌跡,容易對多重興趣進行平均化,限制覆蓋范圍。GPR采用Multi-Token Prediction(MTP),捕獲用戶的"多重并行興趣"。通過擴展解碼器,使其"并行"(N個Head)預測N個不同的物料。這種設計使得GPR能夠同時建模用戶的多重并行興趣,而不是將它們混合成一個平均化的表示。
2.價值感知微調(VAFT)
雖然MTP能有效捕捉多興趣,但它對所有廣告賦予同等權重,忽略了經濟價值的差異。Value-Aware Fine-Tuning(VAFT):通過引入每個位置的價值權重,由"eCPM"和"行為類型"(轉化 > 點擊 > 曝光)共同決定。這使得模型在保持多興趣覆蓋的同時,將梯度更新偏向高價值廣告,實現興趣和價值的平衡,找到有價值的興趣。
3.強化學習:分層增強策略優化(HEPO)
監督學習只能從歷史曝光和交互中學習,存在行為覆蓋有限的問題——許多高價值候選從未被探索過。GPR引入強化學習來突破這一限制,提出了Hierarchy Enhanced Policy Optimization(HEPO)算法,通過"反事實探索"發現高價值策略。使用強化學習在"高保真模擬環境"中訓練,探索日志之外的優化空間。實現了"從模仿者到探索者的關鍵轉變"。
四、實驗驗證,從離線到線上的全面突破
1.離線實驗
不同編碼器的性能:

最終的實驗表明,RQ-KMeans+的碼本利用率達到99.36%,碰撞率僅為20.60%,顯著優于基線方法。這為后續的統一生成奠定了堅實基礎。
HHD 架構性能:

GPR在百萬級物品庫的預測任務上達到27.32% HitR@100,比基線提升40%以上。消融實驗顯示HSD增強意圖編碼、PTD提升生成質量、MTP捕捉多興趣(+17.9%最大增益)、HTE對齊競價目標,各組件協同發揮作用。
擴展實驗:

擴展實驗驗證了scaling law,模型越大性能越好。
訓練與對齊性能:

實驗對比了四種訓練策略的商業價值對齊效果。MTP+VAFT通過價值重加權小幅提升nDCG和OPR,MTP+DPO通過成對偏好優化顯著改善排序質量(nDCG 0.4383)和final_value,而MTP+HEPO表現最佳(nDCG 0.4413、平均final_value 0.2630、最大final_value 0.7619),證明分層過程獎勵和模擬環境探索能最有效地將生成策略與業務目標對齊。
2.線上A/B測試:商業指標全面提升
GPR已在微信視頻號廣告系統全面上線,面向數億用戶和千萬級廣告庫。線上測試經歷五輪演進:

整體提升:
- GMV(商品交易總額):首輪+2.11%,第二輪+0.70%,累計提升持續疊加
- CTCVR(點擊轉化率):顯著提升
- CTR、CVR:全部正向增長
- 成本指標:優化改善

分組效果:
- 新廣告冷啟動:GMV +2.97%(老廣告+1.65%)
- 新用戶:各指標顯著提升
- 低/高活躍用戶:所有分組均錄得多項指標增長
這些結果證明:GPR作為端到端單一模型,在高度優化的成熟級聯系統面前仍保持強競爭力,并在冷啟動、復雜場景下表現更加優異。
五、結語
GPR代表了廣告推薦系統從多階段級聯向端到端生成式單一模型范式的重要轉變。通過統一表示、分層解碼、價值對齊三位一體的設計,GPR成功將整個模型和廣告主的商業價值進行了對齊,在理論創新和工業落地之間找到了優雅的平衡點。
在微信視頻號這樣數億用戶規模的真實生產環境中取得的顯著商業成功,證明了One Model范式不僅是學術探索,更是具有實際經濟價值的技術革新。這為推薦系統乃至整個AI領域的范式演進提供了寶貴的實踐經驗。
One Model不是終點,而是新的起點。隨著生成式AI技術的持續演進,我們有理由期待更多統一、端到端、全局最優的智能系統出現,推動人工智能從"多模型拼接"走向"單一模型統御"的新時代。