倒反天罡!Gemini Flash表現超越Pro,“帕累托前沿已經反轉了”
倒反天罡!
Gemini 3 Flash的表現在SWE-Bench Verified測試中獲得了78%的分數,比超大杯Pro還略勝一籌。

而且Flash的速度和性價比,都是Pro版難以望其項背的。
谷歌解釋,這是因為Flash版當中的一些優化技術,還未在Pro里應用。
但用網友的話講,Flash這樣的表現的確提醒我們帕累托前沿已經反轉,是時候拋卻“旗艦版迷信”了。

Flash表現超越Pro
根據谷歌團隊最新披露的詳細評測數據,Gemini 3 Flash這一次不僅在智能程度上全面超越了上一代的Gemini 2.5 Pro,還在編程能力和多模態推理等核心性能維度上,直接反超了自家的旗艦Gemini 3 Pro以及競品GPT-5.2。
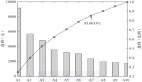
在衡量軟件工程能力的權威測試SWE-Bench Verified 中,Flash 一舉斬獲了 78% 的高分。這一成績不僅在智能程度上全面碾壓了上一代的Gemini 2.5 Pro,還反超了自家旗艦Gemini 3 Pro的76.2%。
在AIME 2025數學競賽基準測試中,結合代碼執行能力的Flash得分高達 99.7%,已無限逼近100%的滿分大關。
即便是在難度極高、被設計用來難倒現代大模型的Humanity’s Last Exam測試中,Flash的表現也緊追旗艦,在不使用工具的情況下獲得了33.7%的分數,與Pro版37.5%的成績已經處于同一梯隊。

除了硬核的智能指標,Flash的響應速度與成本也極具優勢。
數據表明,Gemini 3 Flash的推理速度是2.5 Pro的3倍,Token消耗量減少30%,價格也極具競爭力,輸入端僅需0.50美元每100萬Token,輸出端為3美元每100萬Token。
雖然略貴于Gemini 2.5 Flash(每百萬輸入0.3美元/每百萬輸出2.5美元),但考慮到其性能和速度,這一價格仍然相當具有吸引力。
如果輕量版已經如此強大,甚至在關鍵指標上實現了反超,那么“超大杯”存在的意義究竟是什么?
對于這個問題,谷歌核心團隊給出了一個意料之外的答案——這并非研發事故,而恰恰是他們頂層設計中最為關鍵的一環。
“Pro的作用就是蒸餾Flash”
就在前幾天,Gemini的三位負責人——DeepMind研究副總裁Oriol Vinyals、谷歌首席科學家Jeff Dean和Noam Shazeer,以及Google AI Studio產品負責人Logan Kilpatrick同臺,正式揭示了這背后的戰略邏輯。

在談及旗艦模型的定位時,Oriol Vinyals拋出了極為犀利的觀點,他直言Pro模型的主要作用其實就是拿來“蒸餾Flash。
團隊認為Flash這樣“小而強”的模型對用戶至關重要,隨著迭代,新一代Flash往往能達到甚至超過上一代Pro的水平。
在理想狀態下,Pro的目標是不計成本地探索智能上限,而Flash則通過蒸餾技術繼承Pro的能力,并極致優化延遲、成本和吞吐量,未來Pro甚至可能主要作為一個“生成器”,專門用來生產高質量的Flash模型。
但這并不意味著主宰AI發展多年的Scaling Law已經失效。
面對Flash這種“以小博大”的表現,外界很容易產生一種錯覺,認為大模型走到頭了。
然而在對話中,Vinyals旗幟鮮明地反駁了這一點,他明確表示,與目前流行的“Scaling 結束論”相反,Gemini 團隊通過持續擴大規模實現了巨大的性能飛躍,在他看來,前方依然“看不到墻”(No walls in sight)。

Scaling Law雖未消亡,但也確實在發生演變。
Noam認為單純靠預訓練階段堆砌參數來換取智能增長的路徑確實正在逼近極限,“規模神話”不再是唯一的真理,未來的擴展重點將從預訓練階段的算力堆疊,轉移到推理側的擴展(Test-time Compute)。
對于未來的演進,三位負責人一致認為后訓練(Post-training)是目前最大的“未開墾綠地”。
雖然代碼、推理和數學等基準測試已被逐漸“擊穿”,但在諸如“規劃舊金山旅行”這類開放式任務上,通過后訓練提升的空間依然巨大。
參數不再是迷信
Flash帶來的沖擊波正在引發一場關于“參數至上論”的大討論。
開發者們驚訝地發現,那個一直以來被視為鐵律的“帕累托前沿”竟然發生了倒轉——更便宜、更快的模型,現在竟然也是更聰明的模型。
這直接打破了“模型越大越好”的迷信。
針對Flash為何能反殺Pro,Google DeepMind的研究員Ankesh Anand揭示了背后的技術真相——答案在于強化學習。
他明確指出,Flash不僅僅是Pro的簡單蒸餾版,它還集成了大量最新的Agentic RL(代理強化學習)研究成果。

這一結果證明了一個核心命題:在提升模型能力的道路上,單純堆砌參數并不是唯一的路徑。
通過更先進的后訓練算法(如RL),小模型完全可以實現“降維打擊”,在軟件工程等關鍵領域戰勝參數量巨大的旗艦模型。
正如開發者所言,現在是時候停止對“旗艦版”的盲目崇拜了。