













開(kāi)源數(shù)據(jù)庫(kù)這么多,你知道幾種
數(shù)據(jù)庫(kù)從字面上的理解就是數(shù)據(jù)的倉(cāng)庫(kù),其實(shí)我們平時(shí)說(shuō)的數(shù)據(jù)庫(kù)是指數(shù)據(jù)庫(kù)管理系統(tǒng)(Database Management System),它是一種操縱和管理數(shù)據(jù)庫(kù)的大型軟件,用于建立、使用和維護(hù)數(shù)據(jù)庫(kù),簡(jiǎn)稱DBMS。嚴(yán)格來(lái)說(shuō)數(shù)據(jù)庫(kù)是數(shù)據(jù)庫(kù)管理系統(tǒng)的實(shí)例,一個(gè)數(shù)據(jù)庫(kù)管理系統(tǒng)可以有多個(gè)數(shù)據(jù)庫(kù)實(shí)例。
數(shù)據(jù)庫(kù)種類很多,我們平時(shí)接觸最多的恐怕就是Oracle數(shù)據(jù)庫(kù),或者M(jìn)ySQL數(shù)據(jù)。兩者是應(yīng)用最廣泛的關(guān)系型數(shù)據(jù)。如圖1是2018年12月份使用情況排名,從排名也可以看出上述兩個(gè)數(shù)據(jù)庫(kù)分別排***名和第二名。
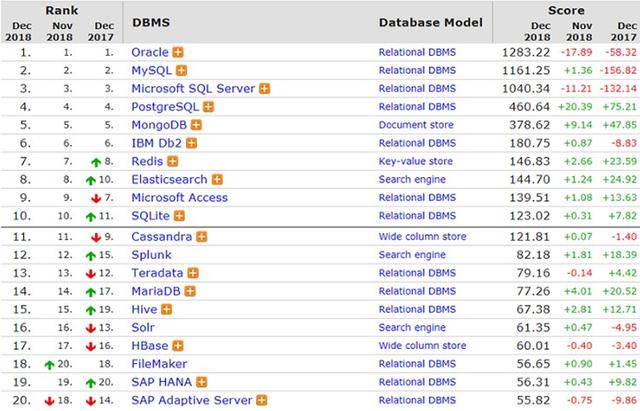
圖1 數(shù)據(jù)庫(kù)排名
數(shù)據(jù)庫(kù)的分類
如果仔細(xì)看圖1的排名就可以看到,數(shù)據(jù)庫(kù)不僅僅有我們平時(shí)學(xué)到的關(guān)系型數(shù)據(jù)庫(kù),還有鍵值(Key-Value)數(shù)據(jù)庫(kù)、列存儲(chǔ)數(shù)據(jù)庫(kù)、文檔數(shù)據(jù)庫(kù)和搜索引擎等類型。下面本文將簡(jiǎn)單介紹一下各種類型的數(shù)據(jù)。
關(guān)系型數(shù)據(jù)庫(kù): 這種類型的數(shù)據(jù)庫(kù)是最古老的數(shù)據(jù)庫(kù)類型,關(guān)系型數(shù)據(jù)庫(kù)模型是把復(fù)雜的數(shù)據(jù)結(jié)構(gòu)歸結(jié)為簡(jiǎn)單的二元關(guān)系(即二維表格形式), 如圖2是一個(gè)二維表的實(shí)例。通常該表***行為字段名稱,描述該字段的作用,下面是具體的數(shù)據(jù)。在定義該表時(shí)需要指定字段的名稱及類型。
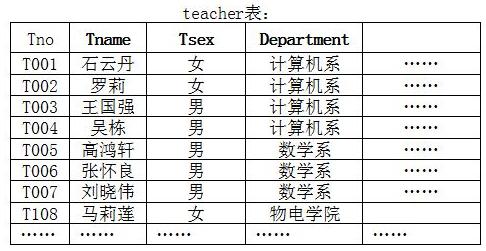
圖2 數(shù)據(jù)庫(kù)表實(shí)例
在關(guān)系型數(shù)據(jù)庫(kù)中,對(duì)數(shù)據(jù)的操作幾乎全部建立在一個(gè)或多個(gè)關(guān)系表格上。在大型系統(tǒng)中通常有多個(gè)表,且表之間有各種關(guān)系。實(shí)際使用就是通過(guò)對(duì)這些關(guān)聯(lián)的表格分類、合并、連接或選取等運(yùn)算來(lái)實(shí)現(xiàn)數(shù)據(jù)庫(kù)的管理。
鍵值存儲(chǔ)數(shù)據(jù)庫(kù):鍵值數(shù)據(jù)庫(kù)是一種非關(guān)系數(shù)據(jù)庫(kù),它使用簡(jiǎn)單的鍵值方法來(lái)存儲(chǔ)數(shù)據(jù)。鍵值數(shù)據(jù)庫(kù)將數(shù)據(jù)存儲(chǔ)為鍵值對(duì)集合,其中鍵作為唯一標(biāo)識(shí)符。
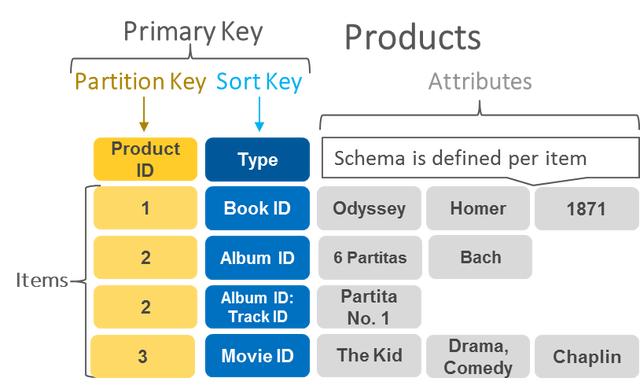
圖2 鍵值數(shù)據(jù)庫(kù)基本原理
如圖2是某公有云的鍵值存儲(chǔ)示意圖,其中鍵包含分區(qū)鍵和排序鍵,而值包含更多的實(shí)際信息。比如實(shí)際使用是可以以學(xué)號(hào)為鍵,姓名、性別、年齡和班級(jí)等信息為值進(jìn)行存儲(chǔ)。實(shí)際存儲(chǔ)形式很靈活,是業(yè)務(wù)需求自行定義即可。
列存儲(chǔ)數(shù)據(jù)庫(kù):列式存儲(chǔ)(column-based)是相對(duì)于傳統(tǒng)關(guān)系型數(shù)據(jù)庫(kù)的行式存儲(chǔ)(Row-basedstorage)來(lái)說(shuō)的。簡(jiǎn)單來(lái)說(shuō)兩者的區(qū)別就是對(duì)表中數(shù)據(jù)的存儲(chǔ)形式的差異。
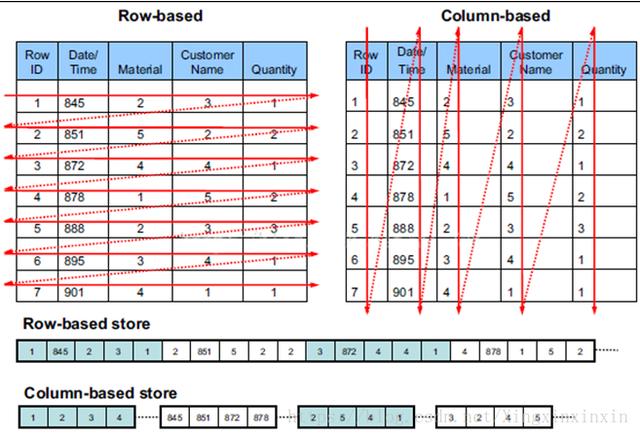
圖3 列存儲(chǔ)數(shù)據(jù)
如圖3是傳統(tǒng)行數(shù)據(jù)庫(kù)和列數(shù)據(jù)庫(kù)表中數(shù)據(jù)在磁盤(pán)上的存儲(chǔ)形式的差異對(duì)比。對(duì)于行存儲(chǔ)數(shù)據(jù)庫(kù),表中的數(shù)據(jù)是以行為單位逐行存儲(chǔ)在磁盤(pán)上的;而對(duì)于列存儲(chǔ)數(shù)據(jù)庫(kù),表中的數(shù)據(jù)則是以列為單位逐列存儲(chǔ)在磁盤(pán)中。
列存儲(chǔ)解決的主要問(wèn)題是數(shù)據(jù)查詢問(wèn)題。我們知道,平時(shí)的查詢大部分都是條件查詢,通常是返回某些字段(列)的數(shù)據(jù)。對(duì)于行存儲(chǔ)數(shù)據(jù),數(shù)據(jù)讀取時(shí)通常將一行數(shù)據(jù)完全讀出,如果只需要其中幾列數(shù)據(jù)的情況,就會(huì)存在冗余列,出于縮短處理時(shí)間的考量,消除冗余列的過(guò)程通常是在內(nèi)存中進(jìn)行的。而列存儲(chǔ),每次讀取的數(shù)據(jù)是集合的一段或者全部,不存在冗余性問(wèn)題。這樣,通過(guò)這種存儲(chǔ)方式的調(diào)整,使得查詢性能得到極大的提升。
面向文檔數(shù)據(jù)庫(kù):此類數(shù)據(jù)庫(kù)可存放并獲取文檔,可以是XML、JSON、BSON等格式,這些文檔具備可述性(self-describing),呈現(xiàn)分層的樹(shù)狀結(jié)構(gòu)(hierarchical tree data structure),可以包含映射表、集合和純量值。數(shù)據(jù)庫(kù)中的文檔彼此相似,但不必完全相同。文檔數(shù)據(jù)庫(kù)所存放的文檔,就相當(dāng)于鍵值數(shù)據(jù)庫(kù)所存放的“值”。文檔數(shù)據(jù)庫(kù)可視為其值可查的鍵值數(shù)據(jù)庫(kù)。
圖形數(shù)據(jù)庫(kù):圖形數(shù)據(jù)庫(kù)顧名思義,就是一種存儲(chǔ)圖形關(guān)系的數(shù)據(jù)庫(kù)。圖形數(shù)據(jù)庫(kù)是NoSQL數(shù)據(jù)庫(kù)的一種類型,它應(yīng)用圖形理論存儲(chǔ)實(shí)體之間的關(guān)系信息。關(guān)系型數(shù)據(jù)用于存儲(chǔ)明確關(guān)系的數(shù)據(jù),但對(duì)于復(fù)雜關(guān)系的數(shù)據(jù)存儲(chǔ)卻有些力不從心。如圖4這種人物之間的關(guān)系,如果用關(guān)系型數(shù)據(jù)庫(kù)則非常復(fù)雜,用圖形數(shù)據(jù)庫(kù)將非常簡(jiǎn)單。
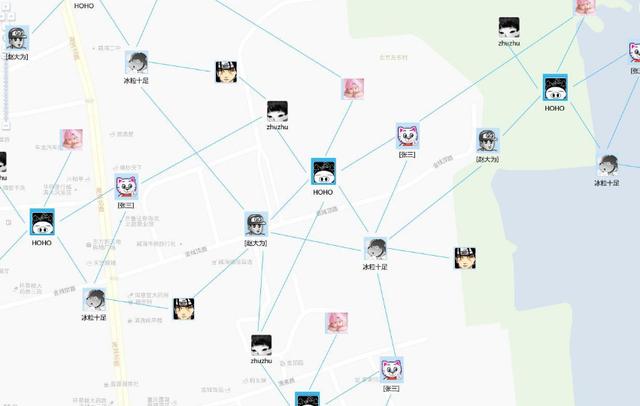
圖4 圖形數(shù)據(jù)庫(kù)示例
搜索引擎存儲(chǔ):搜索引擎數(shù)據(jù)庫(kù)是應(yīng)用在搜索引擎領(lǐng)域的數(shù)據(jù)存儲(chǔ)形式,由于搜索引擎會(huì)爬取大量的數(shù)據(jù),并以特定的格式進(jìn)行存儲(chǔ),這樣在檢索的時(shí)候才能保證性能***。
不同類型數(shù)據(jù)庫(kù)軟件
關(guān)系型數(shù)據(jù)庫(kù): 關(guān)系型數(shù)據(jù)庫(kù)最為經(jīng)典的開(kāi)源軟件就是MySQL,它***的開(kāi)源關(guān)系型數(shù)據(jù)庫(kù)管理系統(tǒng),在 WEB 應(yīng)用方面 MySQL 是***的 RDBMS(Relational Database Management System:關(guān)系數(shù)據(jù)庫(kù)管理系統(tǒng))應(yīng)用軟件之一。

SUN被甲骨文收購(gòu)后,MySQL 的原創(chuàng)人員有拉出另外一個(gè)分支,命名MariaDB 。該數(shù)據(jù)庫(kù)被維基百科,F(xiàn)acebook 甚至 Google 等技術(shù)巨頭使用。 MariaDB 是一種可為 MySQL 提供插件替換功能的數(shù)據(jù)庫(kù)服務(wù)器。開(kāi)發(fā)人員的首要關(guān)注點(diǎn)是安全性,在每個(gè)版本發(fā)布時(shí),開(kāi)發(fā)人員還會(huì)合并所有 MySQL 的安全修補(bǔ)程序,并在需要時(shí)對(duì)其進(jìn)行增強(qiáng)。
除此之外,還有很多開(kāi)源的關(guān)系型數(shù)據(jù)庫(kù),比如經(jīng)典的文件數(shù)據(jù)庫(kù)SQLite和針對(duì)Web服務(wù)進(jìn)行優(yōu)化的CUBRID 等。
鍵值存儲(chǔ)數(shù)據(jù)庫(kù):鍵值數(shù)據(jù)庫(kù)目前應(yīng)用最多的應(yīng)該是Redis,Redis是一個(gè)開(kāi)源的使用ANSI C語(yǔ)言編寫(xiě)、支持網(wǎng)絡(luò)、可基于內(nèi)存亦可持久化的日志型、Key-Value數(shù)據(jù)庫(kù),并提供多種語(yǔ)言的API。Redis通常最為普通關(guān)系型數(shù)據(jù)庫(kù)的緩存層,用于降低數(shù)據(jù)庫(kù)的訪問(wèn)壓力,提升系統(tǒng)性能。

列存儲(chǔ)數(shù)據(jù)庫(kù):列存儲(chǔ)數(shù)據(jù)庫(kù)中最為出名的恐怕就是HBase了,HBase是 BigTable 的開(kāi)源 java 版本。是建立在 HDFS 之上,提供高可靠性、高性能、列存儲(chǔ)、 可伸縮、實(shí)時(shí)讀寫(xiě) NoSQL 的數(shù)據(jù)庫(kù)系統(tǒng)。
面向文檔數(shù)據(jù)庫(kù):文檔數(shù)據(jù)庫(kù)種類繁多,包括MongoDB、CouchDB、 Terrastore、RavenDB和OrientDB等多大十幾個(gè)。其中MongoDB是目前最為流行的文檔數(shù)據(jù)庫(kù),其介于關(guān)系數(shù)據(jù)庫(kù)和非關(guān)系數(shù)據(jù)庫(kù)之間的產(chǎn)品,是非關(guān)系數(shù)據(jù)庫(kù)當(dāng)中功能最豐富,最像關(guān)系數(shù)據(jù)庫(kù)的。其***的特點(diǎn)是分布式部署,可以隨著負(fù)載的增大動(dòng)態(tài)擴(kuò)容,從而滿足企業(yè)業(yè)務(wù)增長(zhǎng)的需求。
圖形數(shù)據(jù)庫(kù):圖形種類很多,比如Neo4J、ArangoDB、OrientDB、FlockDB、GraphDB、InfiniteGraph、Titan和Cayley等。其中Neo4j 是目前***的圖形數(shù)據(jù)庫(kù),支持完整的事務(wù),在屬性圖中,圖是由頂點(diǎn)(Vertex),邊(Edge)和屬性(Property)組成的,頂點(diǎn)和邊都可以設(shè)置屬性,頂點(diǎn)也稱作節(jié)點(diǎn),邊也稱作關(guān)系,每個(gè)節(jié)點(diǎn)和關(guān)系都可以由一個(gè)或多個(gè)屬性。Neo4j創(chuàng)建的圖是用頂點(diǎn)和邊構(gòu)建一個(gè)有向圖,其查詢語(yǔ)言cypher已經(jīng)成為事實(shí)上的標(biāo)準(zhǔn)。

搜索引擎存儲(chǔ):搜索引擎數(shù)據(jù)庫(kù)最近比較火的包括Solr和Elasticsearch等。Solr是Apache 的一個(gè)開(kāi)源項(xiàng)目,基于業(yè)界大名鼎鼎的java開(kāi)源搜索引擎Lucene。在過(guò)去的十年里,solr發(fā)展壯大,擁有廣泛的用戶群體。solr提供分布式索引、分片、副本集、負(fù)載均衡和自動(dòng)故障轉(zhuǎn)移和恢復(fù)功能。如果正確部署,良好管理,solr就能夠成為一個(gè)高可靠、可擴(kuò)展和高容錯(cuò)的搜索引擎。
Elasticsearch構(gòu)建在Apache Lucene庫(kù)之上,同是開(kāi)源搜索引擎。Elasticsearch在Solr推出幾年后才面世的,通過(guò)REST和schema-free的JSON文檔提供分布式、多租戶全文搜索引擎。并且官方提供Java,Groovy,PHP,Ruby,Perl,Python,.NET和Javascript客戶端。目前Elasticsearch與Logstash和Kibana配合,部署成日志采集和分析,簡(jiǎn)稱ELK,它們都是開(kāi)源軟件。最近新增了一個(gè)FileBeat,它是一個(gè)輕量級(jí)的日志收集處理工具(Agent),F(xiàn)ilebeat占用資源少,適合于在各個(gè)服務(wù)器上搜集日志后傳輸給Logstash。



















