本月你最值得關(guān)注的數(shù)據(jù)科學(xué)開(kāi)源項(xiàng)目!
如果你參加過(guò)大型的數(shù)據(jù)科學(xué)家職位的面試,你就會(huì)發(fā)現(xiàn)候選人的背景各不相同,比如軟件工程、機(jī)器學(xué)習(xí)、金融、市場(chǎng)營(yíng)銷等等,而且這些面試者基本都擁有一系列屬于自己的項(xiàng)目,盡管他可能在數(shù)據(jù)科學(xué)方面的經(jīng)驗(yàn)還不足。而招聘人員/經(jīng)理一般也都很欣賞那些手頭有一兩個(gè)優(yōu)秀開(kāi)源項(xiàng)目的應(yīng)聘者。
今天,和大家推薦6個(gè)優(yōu)秀的開(kāi)源的數(shù)據(jù)科學(xué)項(xiàng)目,對(duì)計(jì)算機(jī)視覺(jué)專家的需求每年都在穩(wěn)步增長(zhǎng),作為一名數(shù)據(jù)科學(xué)專業(yè)人士,有很多事情要做,有很多東西要學(xué)。希望這6個(gè)開(kāi)源項(xiàng)目對(duì)你有所幫助:
1、Few-Shot vid2vid
去年我偶然發(fā)現(xiàn)了視頻到視頻(vid2vid)合成的概念,并被它的有效性所震撼。vid2vid本質(zhì)上是將一個(gè)語(yǔ)義輸入視頻轉(zhuǎn)換為一個(gè)超真實(shí)的視頻輸出。
但是目前這些vid2vid模型有兩個(gè)主要的限制
- 他們需要大量的訓(xùn)練數(shù)據(jù)
- 這些模型很難推廣到訓(xùn)練數(shù)據(jù)之外
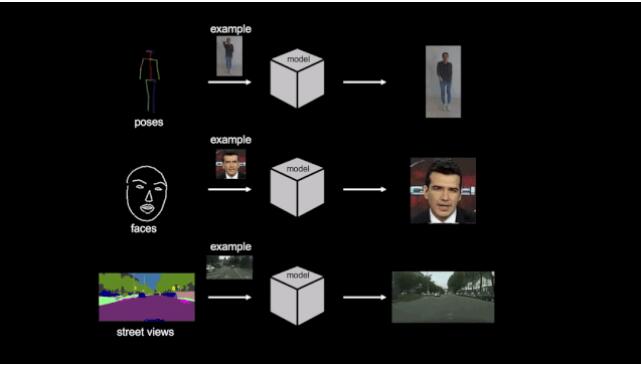
這就是英偉達(dá)viv2vid框架的厲害之處,它可以在分割蒙版、素描草圖、人體姿勢(shì)等多種輸入格式上,實(shí)現(xiàn)高分辨率、逼真、時(shí)間相干的視頻效果。

這個(gè)GitHub庫(kù)是一個(gè)PyTorch實(shí)現(xiàn),你可以通過(guò)以下這篇文章,開(kāi)始學(xué)習(xí)如何設(shè)計(jì)自己的視頻分類模型。(文章地址:https://www.analyticsvidhya.com/blog/2019/09/step-by-step-deep-learning-tutorial-video-classification-python/?utm_source=blog&utm_medium=6-open-source-data-science-projects)
Github地址:https://github.com/NVlabs/few-shot-vid2vid
2、Ultra-Light and Fast Face Detector
這是一個(gè)超輕版本的人臉檢測(cè)模型,這個(gè)人臉檢測(cè)模型的大小只有1MB。

該模型設(shè)計(jì)是針對(duì)邊緣計(jì)算設(shè)備或低算力設(shè)備(如用ARM推理)設(shè)計(jì)的,可以在低算力設(shè)備中如用ARM進(jìn)行實(shí)時(shí)的通用場(chǎng)景的人臉檢測(cè)推理,同樣適用于移動(dòng)端、PC。
Github地址:https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB
3、Gaussian_YOLOv3
我是自動(dòng)駕駛汽車的超級(jí)粉絲,因此,我認(rèn)為任何有關(guān)自動(dòng)駕駛的框架或算法有新的發(fā)展都是值得令人開(kāi)心的。
目標(biāo)檢測(cè)算法是這些自動(dòng)駕駛的核心,而高精度、快速的推理速度是保證駕駛安全的關(guān)鍵,那么,這個(gè)項(xiàng)目有哪些驚艷的特性呢?

Gaussian_YOLOv3架構(gòu)提高了系統(tǒng)的檢測(cè)精度,支持實(shí)時(shí)操作,與傳統(tǒng)的YOLOv3相比,Gaussian YOLOv3分別將KITTI和Berkeley deep drive (BDD)數(shù)據(jù)集的平均精度(mAP)提高了3.09和3.5。
Github地址:https://github.com/jwchoi384/Gaussian_YOLOv3
4、T5
這個(gè)名單里怎么能少了谷歌的存在呢,谷歌在機(jī)器學(xué)習(xí)、深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)的研究上投入了大量的資金,他們的研究成果就反映了這一點(diǎn),你也可以從他們的開(kāi)源項(xiàng)目里學(xué)到很多知識(shí)。
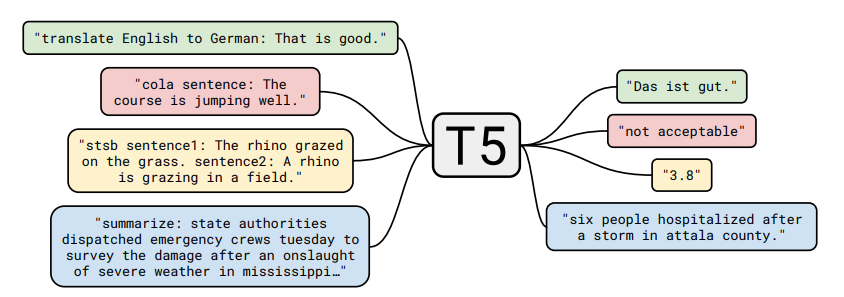
在T5這個(gè)GitHub存儲(chǔ)庫(kù)中,他們已經(jīng)開(kāi)源了數(shù)據(jù)集、預(yù)先訓(xùn)練的模型和T5背后的代碼。谷歌提出預(yù)訓(xùn)練模型 T5,參數(shù)量達(dá)到了 110 億,再次刷新 Glue 榜單,成為全新的 NLP SOTA 預(yù)訓(xùn)練模型。NLP是目前最熱門的領(lǐng)域,如果你不想錯(cuò)過(guò)它的最新成果,最好還是看看這個(gè)項(xiàng)目
Github地址:https://github.com/google-research/text-to-text-transfer-transformer
5、KnowledgeGraphData
史上最大規(guī)模1.4億中文知識(shí)圖譜開(kāi)源下載,數(shù)據(jù)是.csv格式的。簡(jiǎn)單地說(shuō)知識(shí)圖譜就是通過(guò)關(guān)聯(lián)關(guān)系將知識(shí)組成網(wǎng)狀的結(jié)構(gòu),然后我們的人工智能可以通過(guò)這個(gè)圖譜來(lái)認(rèn)識(shí)其代表的這一個(gè)現(xiàn)實(shí)事件,這個(gè)事件可以是現(xiàn)實(shí),也可以是虛構(gòu)的。

知識(shí)圖譜可以應(yīng)用于機(jī)器人問(wèn)答系統(tǒng),知識(shí)推薦等等,下圖為知識(shí)圖譜在機(jī)器人上的應(yīng)用。
Github地址:https://github.com/ownthink/KnowledgeGraphData
6、roughViz
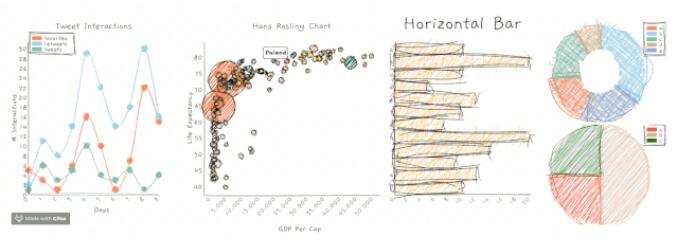
roughViz.js是可重用的JavaScript庫(kù),基于D3v5,roughjs和handy,用于在瀏覽器中創(chuàng)建粗略/手繪樣式的圖表。
你可以使用下面的命令在你的機(jī)器上安裝roughViz:
- npm install rough-viz
你可以通過(guò)roughViz生成以下圖表:
- 條形圖
- 柱狀圖
- 折線圖
- 餅狀圖
- 散點(diǎn)圖
Github地址:https://github.com/jwilber/roughViz