Redis集群架構(gòu)了解一下?一致性Hash了解嗎?
在前幾年,redis 如果要搞幾個節(jié)點,每個節(jié)點存儲一部分的數(shù)據(jù),得借助一些中間件來實現(xiàn),比如說有 codis,或者 twemproxy,都有。有一些 redis 中間件,你讀寫 redis 中間件,redis 中間件負責將你的數(shù)據(jù)分布式存儲在多臺機器上的 redis 實例中。
這兩年,redis 不斷在發(fā)展,redis 也不斷有新的版本,現(xiàn)在的 redis 集群模式,可以做到在多臺機器上,部署多個 redis 實例,每個實例存儲一部分的數(shù)據(jù),同時每個 redis 主實例可以掛 redis 從實例,自動確保說,如果 redis 主實例掛了,會自動切換到 redis 從實例上來。
現(xiàn)在 redis 的新版本,大家都是用 redis cluster 的,也就是 redis 原生支持的 redis 集群模式,那么面試官肯定會就 redis cluster 對你來個幾連炮。要是你沒用過 redis cluster,正常,以前很多人用 codis 之類的客戶端來支持集群,但是起碼你得研究一下 redis cluster 吧。
如果你的數(shù)據(jù)量很少,主要是承載高并發(fā)高性能的場景,比如你的緩存一般就幾個 G,單機就足夠了,可以使用 replication,一個 master 多個 slaves,要幾個 slave 跟你要求的讀吞吐量有關(guān),然后自己搭建一個 sentinel 集群去保證 redis 主從架構(gòu)的高可用性。
redis cluster,主要是針對海量數(shù)據(jù)+高并發(fā)+高可用的場景。redis cluster 支撐 N 個 redis master node,每個 master node 都可以掛載多個 slave node。這樣整個 redis 就可以橫向擴容了。如果你要支撐更大數(shù)據(jù)量的緩存,那就橫向擴容更多的 master 節(jié)點,每個 master 節(jié)點就能存放更多的數(shù)據(jù)了。
redis cluster 介紹
- 自動將數(shù)據(jù)進行分片,每個 master 上放一部分數(shù)據(jù)
- 提供內(nèi)置的高可用支持,部分 master 不可用時,還是可以繼續(xù)工作的
在 redis cluster 架構(gòu)下,每個 redis 要放開兩個端口號,比如一個是 6379,另外一個就是 加1w 的端口號,比如 16379。
16379 端口號是用來進行節(jié)點間通信的,也就是 cluster bus 的東西,cluster bus 的通信,用來進行故障檢測、配置更新、故障轉(zhuǎn)移授權(quán)。cluster bus 用了另外一種二進制的協(xié)議,gossip 協(xié)議,用于節(jié)點間進行高效的數(shù)據(jù)交換,占用更少的網(wǎng)絡(luò)帶寬和處理時間。
節(jié)點間的內(nèi)部通信機制
基本通信原理
集群元數(shù)據(jù)的維護有兩種方式:集中式、Gossip 協(xié)議。redis cluster 節(jié)點間采用 gossip 協(xié)議進行通信。
集中式是將集群元數(shù)據(jù)(節(jié)點信息、故障等等)幾種存儲在某個節(jié)點上。集中式元數(shù)據(jù)集中存儲的一個典型代表,就是大數(shù)據(jù)領(lǐng)域的 storm。它是分布式的大數(shù)據(jù)實時計算引擎,是集中式的元數(shù)據(jù)存儲的結(jié)構(gòu),底層基于 zookeeper(分布式協(xié)調(diào)的中間件)對所有元數(shù)據(jù)進行存儲維護。
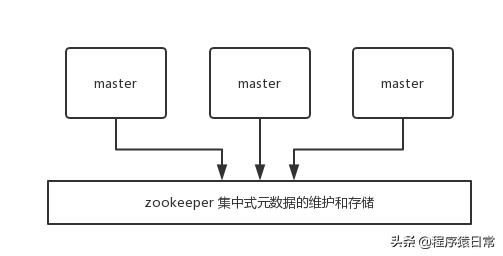
redis 維護集群元數(shù)據(jù)采用另一個方式, gossip 協(xié)議,所有節(jié)點都持有一份元數(shù)據(jù),不同的節(jié)點如果出現(xiàn)了元數(shù)據(jù)的變更,就不斷將元數(shù)據(jù)發(fā)送給其它的節(jié)點,讓其它節(jié)點也進行元數(shù)據(jù)的變更。
集中式的好處在于,元數(shù)據(jù)的讀取和更新,時效性非常好,一旦元數(shù)據(jù)出現(xiàn)了變更,就立即更新到集中式的存儲中,其它節(jié)點讀取的時候就可以感知到;不好在于,所有的元數(shù)據(jù)的更新壓力全部集中在一個地方,可能會導(dǎo)致元數(shù)據(jù)的存儲有壓力。
gossip 好處在于,元數(shù)據(jù)的更新比較分散,不是集中在一個地方,更新請求會陸陸續(xù)續(xù)打到所有節(jié)點上去更新,降低了壓力;不好在于,元數(shù)據(jù)的更新有延時,可能導(dǎo)致集群中的一些操作會有一些滯后。
- 10000 端口:每個節(jié)點都有一個專門用于節(jié)點間通信的端口,就是自己提供服務(wù)的端口號+10000,比如 7001,那么用于節(jié)點間通信的就是 17001 端口。每個節(jié)點每隔一段時間都會往另外幾個節(jié)點發(fā)送 ping 消息,同時其它幾個節(jié)點接收到 ping 之后返回 pong。
- 交換的信息:信息包括故障信息,節(jié)點的增加和刪除,hash slot 信息等等。
gossip 協(xié)議
gossip 協(xié)議包含多種消息,包含 ping,pong,meet,fail 等等。
- meet:某個節(jié)點發(fā)送 meet 給新加入的節(jié)點,讓新節(jié)點加入集群中,然后新節(jié)點就會開始與其它節(jié)點進行通信。
redis-trib.rbadd-node
其實內(nèi)部就是發(fā)送了一個 gossip meet 消息給新加入的節(jié)點,通知那個節(jié)點去加入我們的集群。
- ping:每個節(jié)點都會頻繁給其它節(jié)點發(fā)送 ping,其中包含自己的狀態(tài)還有自己維護的集群元數(shù)據(jù),互相通過 ping 交換元數(shù)據(jù)。
- pong:返回 ping 和 meeet,包含自己的狀態(tài)和其它信息,也用于信息廣播和更新。
- fail:某個節(jié)點判斷另一個節(jié)點 fail 之后,就發(fā)送 fail 給其它節(jié)點,通知其它節(jié)點說,某個節(jié)點宕機啦。
ping 消息深入
ping 時要攜帶一些元數(shù)據(jù),如果很頻繁,可能會加重網(wǎng)絡(luò)負擔。
每個節(jié)點每秒會執(zhí)行 10 次 ping,每次會選擇 5 個最久沒有通信的其它節(jié)點。當然如果發(fā)現(xiàn)某個節(jié)點通信延時達到了 cluster_node_timeout / 2,那么立即發(fā)送 ping,避免數(shù)據(jù)交換延時過長,落后的時間太長了。比如說,兩個節(jié)點之間都 10 分鐘沒有交換數(shù)據(jù)了,那么整個集群處于嚴重的元數(shù)據(jù)不一致的情況,就會有問題。所以 cluster_node_timeout 可以調(diào)節(jié),如果調(diào)得比較大,那么會降低 ping 的頻率。
每次 ping,會帶上自己節(jié)點的信息,還有就是帶上 1/10 其它節(jié)點的信息,發(fā)送出去,進行交換。至少包含 3 個其它節(jié)點的信息,最多包含 總節(jié)點數(shù)減 2 個其它節(jié)點的信息。
分布式尋址算法
- hash 算法(大量緩存重建)
- 一致性 hash 算法(自動緩存遷移)+ 虛擬節(jié)點(自動負載均衡)
- redis cluster 的 hash slot 算法
hash 算法
來了一個 key,首先計算 hash 值,然后對節(jié)點數(shù)取模。然后打在不同的 master 節(jié)點上。一旦某一個 master 節(jié)點宕機,所有請求過來,都會基于最新的剩余 master 節(jié)點數(shù)去取模,嘗試去取數(shù)據(jù)。這會導(dǎo)致大部分的請求過來,全部無法拿到有效的緩存,導(dǎo)致大量的流量涌入數(shù)據(jù)庫。
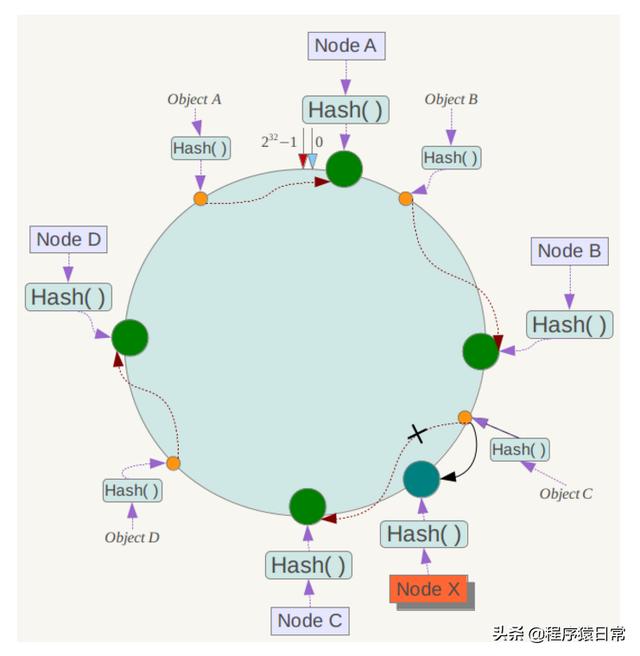
一致性 hash 算法
一致性 hash 算法將整個 hash 值空間組織成一個虛擬的圓環(huán),整個空間按順時針方向組織,下一步將各個 master 節(jié)點(使用服務(wù)器的 ip 或主機名)進行 hash。這樣就能確定每個節(jié)點在其哈希環(huán)上的位置。
來了一個 key,首先計算 hash 值,并確定此數(shù)據(jù)在環(huán)上的位置,從此位置沿環(huán)順時針“行走”,遇到的第一個 master 節(jié)點就是 key 所在位置。
在一致性哈希算法中,如果一個節(jié)點掛了,受影響的數(shù)據(jù)僅僅是此節(jié)點到環(huán)空間前一個節(jié)點(沿著逆時針方向行走遇到的第一個節(jié)點)之間的數(shù)據(jù),其它不受影響。增加一個節(jié)點也同理。
燃鵝,一致性哈希算法在節(jié)點太少時,容易因為節(jié)點分布不均勻而造成緩存熱點的問題。為了解決這種熱點問題,一致性 hash 算法引入了虛擬節(jié)點機制,即對每一個節(jié)點計算多個 hash,每個計算結(jié)果位置都放置一個虛擬節(jié)點。這樣就實現(xiàn)了數(shù)據(jù)的均勻分布,負載均衡。
redis cluster 的 hash slot 算法
redis cluster 有固定的 16384 個 hash slot,對每個 key 計算 CRC16 值,然后對 16384 取模,可以獲取 key 對應(yīng)的 hash slot。
redis cluster 中每個 master 都會持有部分 slot,比如有 3 個 master,那么可能每個 master 持有 5000 多個 hash slot。hash slot 讓 node 的增加和移除很簡單,增加一個 master,就將其他 master 的 hash slot 移動部分過去,減少一個 master,就將它的 hash slot 移動到其他 master 上去。移動 hash slot 的成本是非常低的。客戶端的 api,可以對指定的數(shù)據(jù),讓他們走同一個 hash slot,通過 hash tag 來實現(xiàn)。
任何一臺機器宕機,另外兩個節(jié)點,不影響的。因為 key 找的是 hash slot,不是機器。
redis cluster 的高可用與主備切換原理
redis cluster 的高可用的原理,幾乎跟哨兵是類似的。
判斷節(jié)點宕機
如果一個節(jié)點認為另外一個節(jié)點宕機,那么就是 pfail,主觀宕機。如果多個節(jié)點都認為另外一個節(jié)點宕機了,那么就是 fail,客觀宕機,跟哨兵的原理幾乎一樣,sdown,odown。
在 cluster-node-timeout 內(nèi),某個節(jié)點一直沒有返回 pong,那么就被認為 pfail。
如果一個節(jié)點認為某個節(jié)點 pfail 了,那么會在 gossip ping 消息中,ping 給其他節(jié)點,如果超過半數(shù)的節(jié)點都認為 pfail 了,那么就會變成 fail。
從節(jié)點過濾
對宕機的 master node,從其所有的 slave node 中,選擇一個切換成 master node。
檢查每個 slave node 與 master node 斷開連接的時間,如果超過了 cluster-node-timeout * cluster-slave-validity-factor,那么就沒有資格切換成 master。
從節(jié)點選舉
每個從節(jié)點,都根據(jù)自己對 master 復(fù)制數(shù)據(jù)的 offset,來設(shè)置一個選舉時間,offset 越大(復(fù)制數(shù)據(jù)越多)的從節(jié)點,選舉時間越靠前,優(yōu)先進行選舉。
所有的 master node 開始 slave 選舉投票,給要進行選舉的 slave 進行投票,如果大部分 master node(N/2 + 1)都投票給了某個從節(jié)點,那么選舉通過,那個從節(jié)點可以切換成 master。
從節(jié)點執(zhí)行主備切換,從節(jié)點切換為主節(jié)點。
與哨兵比較
整個流程跟哨兵相比,非常類似,所以說,redis cluster 功能強大,直接集成了 replication 和 sentinel 的功能。