













1780億個參數(shù),這個語言模型的誕生只為挑戰(zhàn)王者GPT-3?
有人要膽敢挑戰(zhàn)GPT-3壟斷地位!
GPT-3自問世以來就成為了最大的AI語言模型之一。
不僅可以寫電郵、寫文章、創(chuàng)建網(wǎng)站、甚至是生成用于Python深度學(xué)習(xí)的代碼。

最近,一個名叫「侏羅紀(jì)」模型號稱可以打敗GPT-3。
究竟是誰這么有勇氣,居然敢如此叫囂?
不是侏羅紀(jì)公園的恐龍!是Jurassic-1 Jumbo,還在公測的語言模型!
現(xiàn)在還可以免費(fèi)體驗:
https://studio.ai21.com/playground
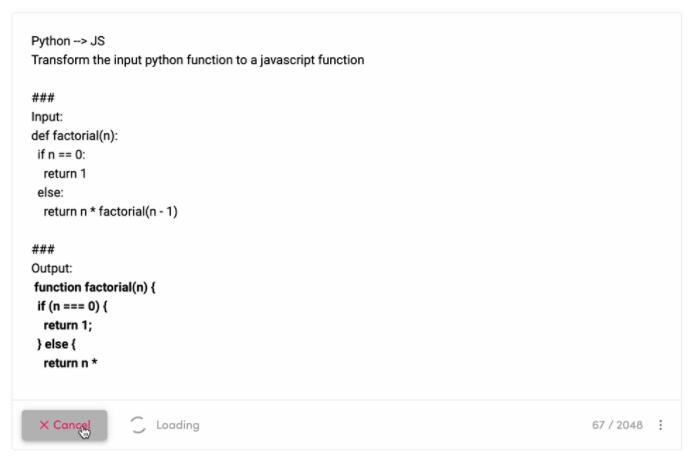
除了能將Python代碼轉(zhuǎn)成Javascript,這個語言模型還有什么過人之處?
膽大,但有實力
在機(jī)器學(xué)習(xí)中,參數(shù)是模型的一部分,從歷史訓(xùn)練數(shù)據(jù)中學(xué)來的。
一般來說,在語言領(lǐng)域,參數(shù)越多,模型就越復(fù)雜。
Jurassic-1 Jumbo這個模型包含了1780億個參數(shù)。
一下子就甩開GPT-3足足30億個參數(shù)!
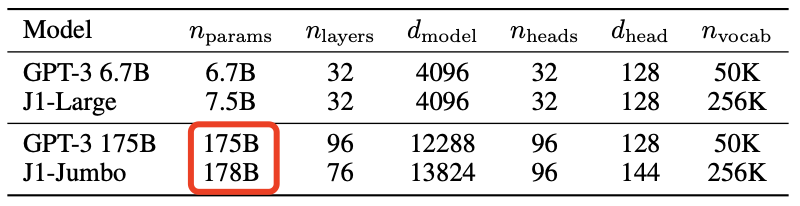
在詞匯項目上,GPT-3有50000個。
但Jurassic-1可以識別包括表達(dá)式、單詞和短語等共250000個。
涵蓋范圍比GPT-3在內(nèi)的大多數(shù)現(xiàn)有模型更大。
Jurassic-1模型經(jīng)過云訓(xùn)練,在一個公共服務(wù)上有數(shù)百個分布式GPU。
token是一種在自然語言中將文本片段分成更小的單元的方法,它可以是單詞、字符或單詞的一部分。
而Jurassic-1訓(xùn)練數(shù)據(jù)集就有3000億個token,全都是從維基百科、新聞出版物、StackExchange等英語網(wǎng)站編譯而來的。
模型的訓(xùn)練采用傳統(tǒng)的自監(jiān)督和自回歸的形式,對來自公開資源的3000億個token進(jìn)行訓(xùn)練。
優(yōu)化程序方面,研究人員對J1-Large和J1-Jumbo分別使用了1.2×10-4和0.6×10-4的學(xué)習(xí)率,以及200萬和320萬個token的批大小。
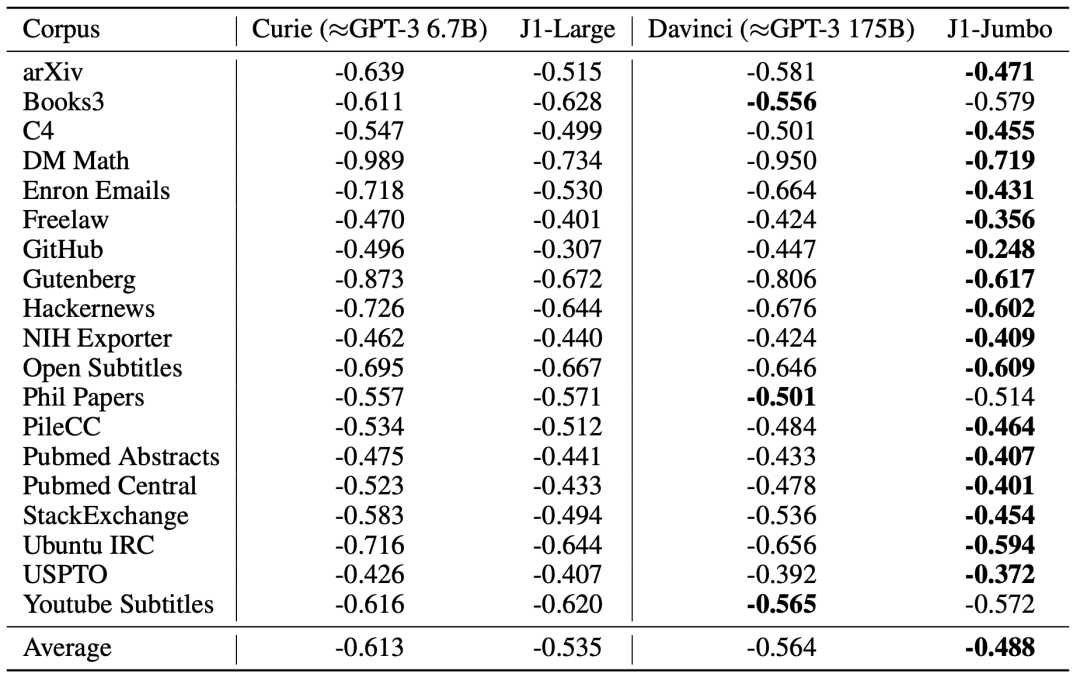
平均每字節(jié)對數(shù)概率表明模型在不同領(lǐng)域的適用性
研究人員表示,在幾乎所有的語料庫中,Jurassic-1模型都領(lǐng)先于GPT-3。
在小樣本學(xué)習(xí)的測試上則各有輸贏,不過平均得分兩個模型持平。
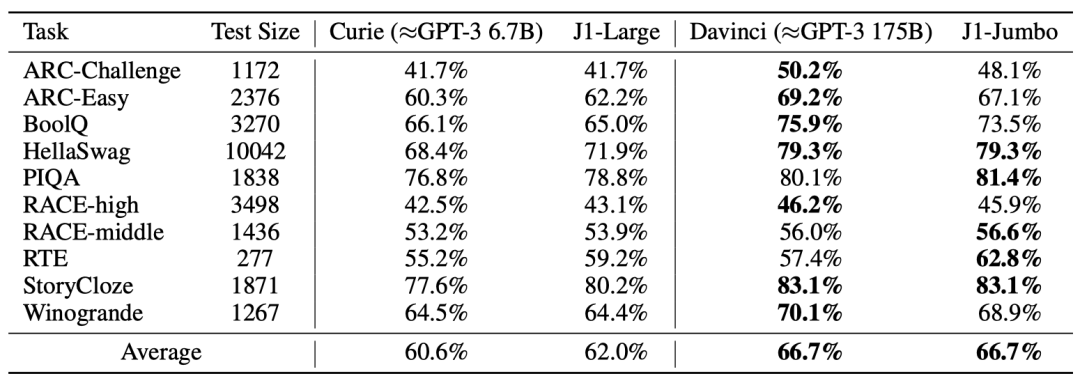
在基準(zhǔn)測試中,Jurassic-1回答學(xué)術(shù)和法律問題的表現(xiàn)已經(jīng)能與GPT-3相當(dāng),甚至表現(xiàn)得更好。
GPT-3需要11個token,但Jurassic-1只需要4個,樣本效率大大增加。
當(dāng)然,對于語言模型來說,最困難的莫過于邏輯和數(shù)學(xué)問題。
而Jurassic-1 Jumbo已經(jīng)可以解決兩個大數(shù)相加這種非常簡單的算術(shù)問題。

Jurassic可以解釋某個單詞的意思
在各種各樣的語言模型面前,Jurassic-1 Jumbo最多只能算是個后起之秀,也不是什么新奇的模型了。
不過和它的前輩們類似,如果問題描述不清,大概率出現(xiàn)的答案并不是你想要的。

堪稱產(chǎn)品經(jīng)理終結(jié)者。
偏見起來連自己人都「打」
Jurassic-1模型由AI21 Labs公司開發(fā),會通過AI21 Labs的Studio平臺提供服務(wù)。
開發(fā)人員可以在公開測試版中構(gòu)建虛擬代理和聊天機(jī)器人等應(yīng)用程序原型。
除此之外,在公測版中,Jurassic-1模型和Studio還能用于釋義和總結(jié),比如從產(chǎn)品描述中生成簡短的產(chǎn)品名稱。
根據(jù)新聞內(nèi)容給新聞分類
同時,開發(fā)者還可以訓(xùn)練自己的Jurassic-1模型,甚至只需要50-100個訓(xùn)練實例。
訓(xùn)練完成之后,就可以通過AI21 Studio使用這個自定義模型。
但是Jurassic-1也一樣面臨其它語言模型的「痛點」:對于性別、種族和宗教的偏見。
由于模型訓(xùn)練數(shù)據(jù)集中或多或少都會存在偏見,訓(xùn)練出來的模型也會跟著「學(xué)壞」。
有研究人員指出,GPT-3等類似的語言模型生成的文本可能會激化極右翼極端主義意識形態(tài)和行為。

Jurassic模型的輸出面臨預(yù)設(shè)場景問題
針對這一點,AI2 Labs就在限制可以在公測中生成的文本數(shù)量,打算手動審查每個微調(diào)模型。
不過就算是經(jīng)過微調(diào)的模型也難以擺脫訓(xùn)練過程中「染上的惡習(xí)」。
就像Open AI的Codex,還是一樣會生成種族主義或者其它令人反感的可執(zhí)行代碼。

雖然是以色列的研究人員開發(fā)的,但大概是受訓(xùn)練數(shù)據(jù)集的影響,Jurassic-1似乎對猶太人的歧視比GPT-3還更重一些。
在偏見與歧視這個問題上,各個模型都是「五十步笑百步」。
不過AI21 Labs的工程師則表示,Jurassic-1模型的偏見比GPT-3少那么一丟丟。

























