達摩院提出目標重識別新范式,已向全球開發(fā)者開源
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯(lián)系出處。
德國哲學家萊布尼茨曾表示世上沒有兩片完全相同的樹葉,這樣的差異性也意味著世界上每一個物體都有自己獨有的ID。如今,AI已經逐漸掌握辨別物體細微差異的技能,從海量圖像中找到目標物體。
8月6日,據(jù)記者了解,達摩院首次將Pure Transformer模型(下文簡稱為Transformer模型/結構)引入目標重識別任務中,該方法可以高效完成細粒度的圖像檢索任務,并超越其它AI算法,在準確率和檢索時間上均取得了迄今為止最好的成績。該研究已被AI頂會ICCV 2021收錄,并斬獲CVPR 2021 AICity挑戰(zhàn)賽目標重識別賽道冠軍,目前,該技術已正式向全球開發(fā)者開源。

達摩院算法斬獲CVPR 2021 AICity挑戰(zhàn)賽目標重識別賽道冠軍
目標重識別是計算機領域研究的新趨勢,據(jù)統(tǒng)計,目前每1000篇計算機視覺論文就有30篇和目標重識別研究相關。不同于目標檢測、目標分割等任務,目標重識別的難度更高。例如同一個物體會因為視角、光線、遮擋等因素而產生外觀差異,不同的物體在同樣的角度和光線下在視覺上的相似度極高,即便通過肉眼也很難克服這些干擾信息,如何區(qū)分這其中的差異并精準找到目標物體一直都是業(yè)界的難題。
過去幾年,AI研究人員逐步嘗試用深度學習CNN模型來解決該問題,但CNN模型在處理目標重識別任務時容易丟失圖像部分細節(jié)信息,同時又無法有效挖掘圖像各特征的全局關聯(lián)性,從而導致其在復雜場景下的表現(xiàn)較差。此次,達摩院創(chuàng)新性將Pure Transformer模型應用于目標重識別任務中,并提出首個基于Pure Transformer結構的ReID框架TransReID,該框架借助水平切塊思想提取更加豐富的細節(jié)特征,同時可通過不同模態(tài)信息的融合來解決視角差異問題。經過測試顯示,該方法已在6個數(shù)據(jù)集上的成績超越了SOTA最好的算法成績。
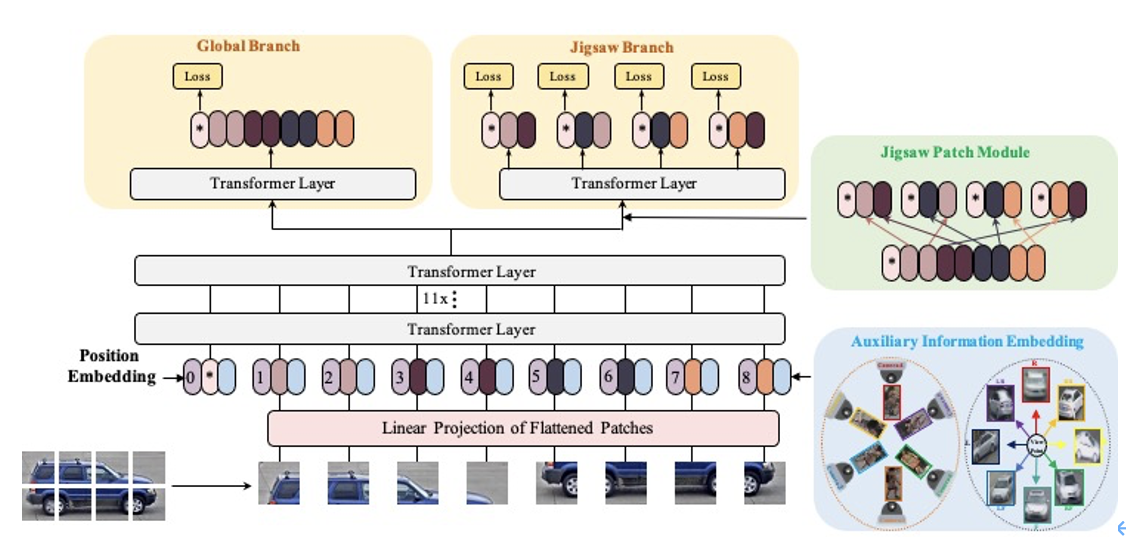
圖:達摩院TransReID首先將圖片物理切割成若干個圖片小塊,每個圖片小塊經過特征提取模塊提取各自的視覺特征,之后計算得到最終圖像的全局特征。此外該框架還能夠幫助模型克服相機帶來的外觀偏差以及提取更加魯棒的全局特征。
該項目研究負責人、達摩院算法專家羅浩表示:“過去Pure Transformer在NLP以及基礎視覺領域取得了較大成功,但在更加細粒度的圖像檢索任務上還未有過嘗試,達摩院此次研究引領了新的研究趨勢,這是行業(yè)的又一個里程碑。”
據(jù)悉,該技術的應用前景廣闊,達摩院研究團隊表示未來會將該技術應用于安全防護以及自然資源、動物保護等領域,例如通過算法來找回走失的珍稀動物。