云原生大數(shù)據(jù)架構(gòu)中實(shí)時計(jì)算維表和結(jié)果表的選型實(shí)踐
一、前言
傳統(tǒng)的大數(shù)據(jù)技術(shù)起源于 Google 三架馬車 GFS、MapReduce、Bigtable,以及其衍生的開源分布式文件系統(tǒng) HDFS,分布式計(jì)算引擎 MapReduce,以及分布式數(shù)據(jù)庫 HBase。最初的大數(shù)據(jù)技術(shù)與需求往往集中在超大規(guī)模數(shù)據(jù)存儲、數(shù)據(jù)處理、在線查詢等。在這個階段,很多公司會選擇自建機(jī)房部署 Hadoop 的方式,大數(shù)據(jù)技術(shù)與需求集中在離線計(jì)算與大規(guī)模存儲上,常見的體現(xiàn)方式有 T+1 報表,大規(guī)模數(shù)據(jù)在線查詢等。
隨著互聯(lián)網(wǎng)技術(shù)的日漸發(fā)展、數(shù)據(jù)規(guī)模的擴(kuò)大與復(fù)雜的需求場景的產(chǎn)生,傳統(tǒng)的大數(shù)據(jù)架構(gòu)無法承載。大數(shù)據(jù)架構(gòu)在近些年的演進(jìn)主要體現(xiàn)下以下幾方面:
1. 規(guī)模化:這里的規(guī)模化主要體現(xiàn)在大數(shù)據(jù)技術(shù)的使用規(guī)模上和數(shù)據(jù)規(guī)模的增長。大數(shù)據(jù)技術(shù)的使用規(guī)模增長代表越來越多的復(fù)雜需求產(chǎn)生,而數(shù)據(jù)規(guī)模的增長決定了傳統(tǒng)的準(zhǔn)大數(shù)據(jù)技術(shù)(如 MySQL)無法解決所有問題。因此,拿存儲組件舉例來說,通常會劃分到不同的數(shù)據(jù)分層,面向規(guī)模、成本、查詢和分析性能等不同維度的優(yōu)化偏向,以滿足多樣性的需求。
2. 實(shí)時化:傳統(tǒng)的 T+1 的離線大數(shù)據(jù)技術(shù)無法滿足推薦、監(jiān)控類近實(shí)時的需求,整個大數(shù)據(jù)生態(tài)和技術(shù)架構(gòu)在過去十年發(fā)生了很大的升級換代。就存儲上來說,傳統(tǒng)的 HDFS 文件存儲、Hive 數(shù)倉無法滿足低成本,可更新迭代的需求,因此滋生出 Hudi 等數(shù)據(jù)方案。就計(jì)算上來說,傳統(tǒng)的 MapReduce 批處理的能力無法做到秒級的數(shù)據(jù)處理,先后出現(xiàn) Storm 較原始的實(shí)時處理和 Spark Streaming 的微批處理,目前由 Flink 基于 Dataflow 模型的實(shí)時計(jì)算框架在實(shí)時計(jì)算領(lǐng)域占據(jù)絕對主導(dǎo)地位。
3. 云原生化:傳統(tǒng)的公司往往會選擇自建機(jī)房,或者在云上購買機(jī)器部署實(shí)例這種云托管的形式,但這種架構(gòu)存在低谷期利用率低,存儲計(jì)算不分離導(dǎo)致的存儲和計(jì)算彈性差,以及升級靈活度低等各種問題。云原生大數(shù)據(jù)架構(gòu)就是所謂的數(shù)據(jù)湖,其本質(zhì)就是充分利用云上的彈性資源來實(shí)現(xiàn)一個統(tǒng)一管理、統(tǒng)一存儲、彈性計(jì)算的大數(shù)據(jù)架構(gòu),變革了傳統(tǒng)大數(shù)據(jù)架構(gòu)基于物理集群和本地磁盤的計(jì)算存儲架構(gòu)。其主要技術(shù)特征是存儲和計(jì)算分離和 Serverless。在云原生大數(shù)據(jù)架構(gòu)中,每一層架構(gòu)都在往服務(wù)化的趨勢演進(jìn),存儲服務(wù)化、計(jì)算服務(wù)化、元數(shù)據(jù)管理服務(wù)化等。每個組件都被要求拆分成不同的單元,具備獨(dú)立擴(kuò)展的能力,更開放、更靈活、更彈性。
本篇文章將基于云原生大數(shù)據(jù)架構(gòu)的場景,詳細(xì)討論實(shí)時計(jì)算中的維表和結(jié)果表的架構(gòu)選型。
二、大數(shù)據(jù)架構(gòu)中的實(shí)時計(jì)算
1、實(shí)時計(jì)算場景
大數(shù)據(jù)的高速發(fā)展已經(jīng)超過 10 年,大數(shù)據(jù)也正在從計(jì)算規(guī)模化向更加實(shí)時化的趨勢演進(jìn)。實(shí)時計(jì)算場景主要有以下幾種最常見的場景:
- 實(shí)時數(shù)倉:實(shí)時數(shù)倉主要應(yīng)用在網(wǎng)站 PV / UV 統(tǒng)計(jì)、交易數(shù)據(jù)統(tǒng)計(jì)、商品銷量統(tǒng)計(jì)等各類交易型數(shù)據(jù)場景中。在這種場景下,實(shí)時計(jì)算任務(wù)通過訂閱業(yè)務(wù)實(shí)時數(shù)據(jù)源,將信息實(shí)時秒級分析,最終呈現(xiàn)在業(yè)務(wù)大屏中給決策者使用,方便判斷企業(yè)運(yùn)營狀況和活動促銷的情況。
- 實(shí)時推薦:實(shí)時推薦主要是基于 AI 技術(shù),根據(jù)用戶喜好進(jìn)行個性化推薦。常見于短視頻場景、內(nèi)容資訊場景、電商購物等場景。在這種場景下,通過用戶的歷史點(diǎn)擊情況實(shí)時判斷用戶喜好,從而進(jìn)行針對性推薦,以達(dá)到增加用戶粘性的效果。
- 數(shù)據(jù) ETL:實(shí)時的 ETL 場景常見于數(shù)據(jù)同步任務(wù)中。比如數(shù)據(jù)庫中不同表的同步、轉(zhuǎn)化,或者是不同數(shù)據(jù)庫的同步,或者是進(jìn)行數(shù)據(jù)聚合預(yù)處理等操作,最終將結(jié)果寫入數(shù)據(jù)倉庫或者數(shù)據(jù)湖進(jìn)行歸檔沉淀。這種場景主要是為后續(xù)的業(yè)務(wù)深度分析進(jìn)行前期準(zhǔn)備工作。
- 實(shí)時診斷:這種常見于金融類或者是交易類業(yè)務(wù)場景。在這些場景中,針對行業(yè)的獨(dú)特性,需要有反作弊監(jiān)管,根據(jù)實(shí)時短時間之內(nèi)的行為,判定用戶是否為作弊用戶,做到及時止損。該場景對時效性要求極高,通過實(shí)時計(jì)算任務(wù)對異常數(shù)據(jù)檢測,實(shí)時發(fā)現(xiàn)異常并進(jìn)行及時止損。
2、Flink SQL 實(shí)時計(jì)算
實(shí)時計(jì)算需要后臺有一套極其強(qiáng)大的大數(shù)據(jù)計(jì)算能力,Apache Flink 作為一款開源大數(shù)據(jù)實(shí)時計(jì)算技術(shù)應(yīng)運(yùn)而生。由于傳統(tǒng)的 Hadoop、Spark 等計(jì)算引擎,本質(zhì)上是批計(jì)算引擎,通過對有限的數(shù)據(jù)集進(jìn)行數(shù)據(jù)處理,其處理時效性是不能保證的。而 Apache Flink ,從設(shè)計(jì)之初就以定位為流式計(jì)算引擎,它可以實(shí)時訂閱實(shí)時產(chǎn)生的流式數(shù)據(jù),對數(shù)據(jù)進(jìn)行實(shí)時分析處理并產(chǎn)生結(jié)果,讓數(shù)據(jù)在第一時間發(fā)揮價值。
Flink 選擇了 SQL 這種聲明式語言作為頂層 API,方便用戶使用,也符合云原生大數(shù)據(jù)架構(gòu)的趨勢:
- 大數(shù)據(jù)普惠,規(guī)模生產(chǎn):Flink SQL 能夠根據(jù)查詢語句自動優(yōu)化,生成最優(yōu)的物理執(zhí)行計(jì)劃,屏蔽大數(shù)據(jù)計(jì)算中的復(fù)雜性,大幅降低用戶使用門檻,以達(dá)到大數(shù)據(jù)普惠的效果。
- 流批一體:Flink SQL 具備流批統(tǒng)一的特性,無論是流任務(wù)還是批處理任務(wù)都給用戶提供相同的語義和統(tǒng)一的開發(fā)體驗(yàn),方便業(yè)務(wù)離線任務(wù)轉(zhuǎn)實(shí)時。
- 屏蔽底層存儲差異:Flink 通過提供 SQL 統(tǒng)一查詢語言,屏蔽底層數(shù)據(jù)存儲的差異,方便業(yè)務(wù)在多樣性的大數(shù)據(jù)存儲中進(jìn)行靈活切換,對云上大數(shù)據(jù)架構(gòu)進(jìn)行更開放、靈活的調(diào)整。
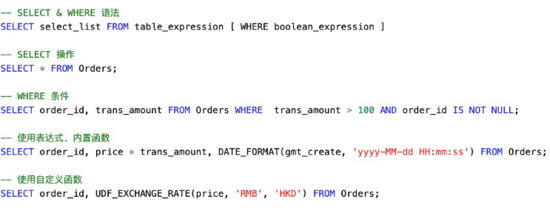
上圖是 Flink SQL 的一些基本操作。可以看到 SQL 的語法和標(biāo)準(zhǔn) SQL 非常類似,示例中包括了基本的 SELECT、FILTER 操作,可以使用內(nèi)置函數(shù)(如日期的格式化),也可以在注冊函數(shù)后使用自定義函數(shù)。
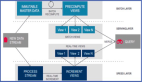
Flink SQL 將實(shí)時計(jì)算拆分成源表,結(jié)果表和維表三種,將這三種表的 DDL 語句(比如 CREATE TABLE)注冊各類輸入、輸出的數(shù)據(jù)源,通過 SQL 的 DML(比如 INSERT INTO)表示實(shí)時計(jì)算任務(wù)的拓?fù)潢P(guān)系,以達(dá)到通過 SQL 完成實(shí)時計(jì)算任務(wù)開發(fā)的效果。
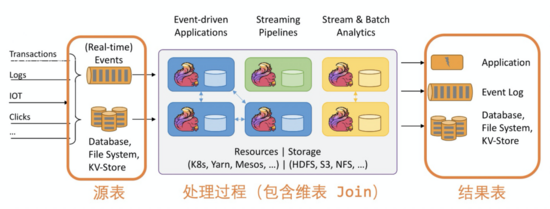
- 源表:主要代表消息系統(tǒng)類的輸入,比如 Kafka,MQ(Message Queue),或者 CDC(Change Data Capture,例如將 MySQL binlog 轉(zhuǎn)換成實(shí)時流)輸入。
- 結(jié)果表:主要代表 Flink 將每條實(shí)時處理完的數(shù)據(jù)寫入的目標(biāo)存儲,如 MySQL,HBase 等數(shù)據(jù)庫。
- 維表:主要代表存儲數(shù)據(jù)維度信息的數(shù)據(jù)源。在實(shí)時計(jì)算中,因?yàn)閿?shù)據(jù)采集端采集到的數(shù)據(jù)往往比較有限,在做數(shù)據(jù)分析之前,就要先將所需的維度信息補(bǔ)全,而維表就是代表存儲數(shù)據(jù)維度信息的數(shù)據(jù)源。常見的用戶維表有 MySQL,Redis 等。
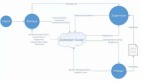
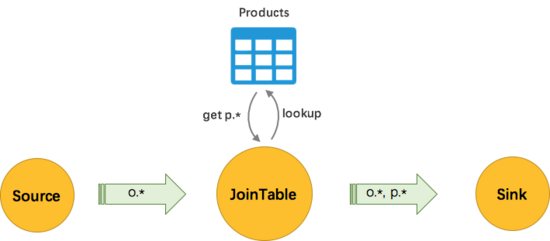
下圖是一個完整的實(shí)時計(jì)算示例,示例中的 Flink SQL 任務(wù),這個任務(wù)的目標(biāo)是計(jì)算每分鐘不同商品分類的 GMV (Gross Merchandise Volume,即商品交易總額)。在這個任務(wù)中,F(xiàn)link 實(shí)時消費(fèi)用戶訂單數(shù)據(jù)的 Kafka 源表,通過 Redis 維表將商品 id 關(guān)聯(lián)起來獲取到商品分類,按照 1 分鐘間隔的滾動窗口按商品分類將總計(jì)的交易金額計(jì)算出來,將最后的結(jié)果寫入 RDS(Relational Database Service,如 MySQL) 結(jié)果表中。
- # 源表 - 用戶訂單數(shù)據(jù),代表某個用戶(user_id)在 timestamp 時按 price 的價格購買了商品(item_id)
- CREATE TEMPORARY TABLE user_action_source (
- `timestamp` BIGINT,
- `user_id` BIGINT,
- `item_id` BIGINT,
- `price` DOUBLE,SQs
- ) WITH (
- 'connector' = 'kafka',
- 'topic' = '<your_topic>',
- 'properties.bootstrap.servers' = 'your_kafka_server:9092',
- 'properties.group.id' = '<your_consumer_group>'
- 'format' = 'json',
- 'scan.startup.mode' = 'latest-offset'
- );
- # 維表 - 物品詳情
- CREATE TEMPORARY TABLE item_detail_dim (
- id STRING,
- catagory STRING,
- PRIMARY KEY (id) NOT ENFORCED
- ) WITH (
- 'connector' = 'redis',
- 'host' = '<your_redis_host>',
- 'port' = '<your_redis_port>',
- 'password' = '<your_redis_password>',
- 'dbNum' = '<your_db_num>'
- );
- # 結(jié)果表 - 按時間(分鐘)和分類的 GMV 輸出
- CREATE TEMPORARY TABLE gmv_output (
- time_minute STRING,
- catagory STRING,
- gmv DOUBLE,
- PRIMARY KEY (time_minute, catagory)
- ) WITH (
- type='rds',
- url='<your_jdbc_mysql_url_with_database>',
- tableName='<your_table>',
- userName='<your_mysql_database_username>',
- password='<your_mysql_database_password>'
- );
- # 處理過程
- INSERT INTO gmv_output
- SELECT
- TUMBLE_START(s.timestamp, INTERVAL '1' MINUTES) as time_minute,
- d.catagory,
- SUM(d.price) as gmv
- FROM
- user_action_source s
- JOIN item_detail_dim FOR SYSTEM_TIME AS OF PROCTIME() as d
- ON s.item_id = d.id
- GROUP BY TUMBLE(s.timestamp, INTERVAL '1' MINUTES), d.catagory;
這是一個很常見的實(shí)時計(jì)算的處理鏈路。后續(xù)章節(jié)中,我們將針對實(shí)時計(jì)算的維表和結(jié)果表的關(guān)鍵能力進(jìn)行展開分析,并分別進(jìn)行架構(gòu)選型的討論。
三、實(shí)時計(jì)算維表
1、關(guān)鍵需求
在數(shù)據(jù)倉庫的建設(shè)中,一般都會圍繞著星型模型和雪花模型來設(shè)計(jì)表關(guān)系或者結(jié)構(gòu)。實(shí)時計(jì)算也不例外,一種常見的需求就是為數(shù)據(jù)流補(bǔ)齊字段。因?yàn)閿?shù)據(jù)采集端采集到的數(shù)據(jù)往往比較有限,在做數(shù)據(jù)分析之前,就要先將所需的維度信息補(bǔ)全。比如采集到的交易日志中只記錄了商品 id,但是在做業(yè)務(wù)時需要根據(jù)店鋪維度或者行業(yè)緯度進(jìn)行聚合,這就需要先將交易日志與商品維表進(jìn)行關(guān)聯(lián),補(bǔ)全所需的維度信息。這里所說的維表與數(shù)據(jù)倉庫中的概念類似,是維度屬性的集合,比如商品維度、用戶度、地點(diǎn)維度等等。
作為保存用戶維度信息的數(shù)據(jù)存儲,需要應(yīng)對實(shí)時計(jì)算場景下的海量低延時訪問。根據(jù)這樣的定位,我們總結(jié)下對結(jié)構(gòu)化大數(shù)據(jù)存儲的幾個關(guān)鍵需求:
(1)高吞吐與低延時的讀取能力
首當(dāng)其沖,在不考慮開源引擎 Flink 自身維表的優(yōu)化外,維表必須能承擔(dān)實(shí)時計(jì)算場景下的海量(上萬 QPS)的數(shù)據(jù)訪問,也能在極低(毫秒級別)的延時下返回查詢數(shù)據(jù)。
(2)與計(jì)算引擎的高整合能力
在維表自身的能力之外,出于性能、穩(wěn)定性和成本的考慮,計(jì)算引擎自身往往也會有些流量卸載的能力,在一些情況下無需每次請求都需要去訪問下游維表。例如,F(xiàn)link 在維表場景下支持 Async IO 和緩存策略等優(yōu)化特性。 一個比較好的維表需要和開源計(jì)算引擎有著較高程度的對接,一方面可以提升計(jì)算層的性能,一方面也可以有效的卸載部分流量,保障維表不被過多訪問擊穿,并降低維表的計(jì)算成本。
(3)輕存儲下的計(jì)算能力的彈性
維表通常是一張共享表,存儲維度屬性等元數(shù)據(jù)信息,訪問規(guī)模往往較大,而存儲規(guī)模往往不會特別大。對維表的訪問規(guī)模極大地依賴實(shí)時數(shù)據(jù)流的數(shù)據(jù)量。比如,如果實(shí)時流的數(shù)據(jù)規(guī)模擴(kuò)大了數(shù)十倍,此時對維表的訪問次數(shù)會大大提升;又比如,如果新增了多個實(shí)時計(jì)算任務(wù)訪問該維表,該維表的查詢壓力會激增。在這些場景下,存儲規(guī)模往往不會顯著增加。
所以,計(jì)算最好是按需的,是彈性的。無論是新增或者下線實(shí)時計(jì)算任務(wù),或者增加訪問流量,都不會影響訪問性能。同時,計(jì)算和存儲是應(yīng)該分離的,不會單純因?yàn)樵L問計(jì)算量的激增就增加存儲成本。
2、架構(gòu)選型
MySQL
大數(shù)據(jù)和實(shí)時計(jì)算技術(shù)起步之初,互聯(lián)網(wǎng)早期大量流行 LAMP (Linux + Apache + MySQL + PHP)架構(gòu)快速開發(fā)站點(diǎn)。因此,由于業(yè)務(wù)歷史數(shù)據(jù)已經(jīng)存在 MySQL 中,在最初的實(shí)時計(jì)算維表選型中大量使用 MySQL 作為維表。
隨著大數(shù)據(jù)架構(gòu)的更新,MySQL 云上架構(gòu)也在不斷改進(jìn),但在維表的應(yīng)用場景下仍然存在以下問題:
- 存儲側(cè)擴(kuò)展靈活性差,擴(kuò)展成本較高:MySQL 在存儲側(cè)的擴(kuò)展需要進(jìn)行數(shù)據(jù)復(fù)制遷移,擴(kuò)展周期長且靈活性差。同時 MySQL 的分庫分表每次擴(kuò)展需要雙倍資源,擴(kuò)展成本較高。
- 存儲成本高:關(guān)系數(shù)據(jù)庫是結(jié)構(gòu)化數(shù)據(jù)存儲單位成本最高的存儲系統(tǒng),所以對于大數(shù)據(jù)場景來說,關(guān)系型數(shù)據(jù)庫存儲成本較高。
以上這些限制使 MySQL 在大數(shù)據(jù)維表場景下存在性能瓶頸,成本也比較高。但總體來說,MySQL 是非常優(yōu)秀的數(shù)據(jù)庫產(chǎn)品,在數(shù)據(jù)規(guī)模不怎么大的場景下,MySQL 絕對是個不錯的選擇。
Redis
在云上應(yīng)用架構(gòu)中,由于 MySQL 難以承載不斷增加的業(yè)務(wù)負(fù)載,往往會使用 Redis 作為 MySQL 的查詢結(jié)果集緩存,幫助 MySQL 來抵御大部分的查詢流量。
在這種架構(gòu)中,MySQL 作為主存儲服務(wù)器,Redis 作為輔助存儲,MySQL 到 Redis 的同步可以通過 binlog 實(shí)時同步或者 MySQL UDF + 觸發(fā)器的方式實(shí)現(xiàn)。在這種架構(gòu)中,Redis 可以用來緩存提高查詢性能,同時降低 MySQL 被擊穿的風(fēng)險。
由于在 Redis 中緩存了一份弱一致性的用戶數(shù)據(jù),Redis 也常常用來作為實(shí)時計(jì)算的維表。相比于 MySQL 作為維表,Redis 有著獨(dú)特的優(yōu)勢:
- 查詢性能極高:數(shù)據(jù)高速緩存在內(nèi)存中,可以通過高速 Key-Value 形式進(jìn)行結(jié)果數(shù)據(jù)查詢,非常符合維表高性能查詢的需求。
- 存儲層擴(kuò)展靈活性高:Redis 可以非常方便的擴(kuò)展分片集群,進(jìn)行橫向擴(kuò)展,支持?jǐn)?shù)據(jù)多副本的持久化。
Redis 有其突出的優(yōu)點(diǎn),但也有一個不可忽視的缺陷:雖然 Redis 有著不錯的擴(kuò)展方案,但由于高速緩存的數(shù)據(jù)存在內(nèi)存中,成本較高,如果遇到業(yè)務(wù)數(shù)據(jù)的維度屬性較大(比如用戶維度、商品維度)時,使用 Redis 作為維表存儲時成本極高。
Tablestore
Tablestore是阿里云自研的結(jié)構(gòu)化大數(shù)據(jù)存儲產(chǎn)品,具體產(chǎn)品介紹可以參考 官網(wǎng) 以及 權(quán)威指南 。在大數(shù)據(jù)維表的場景下,Tablestore 有著獨(dú)特的優(yōu)勢:
- 高吞吐訪問:Tablestore 采用了存儲計(jì)算分離架構(gòu),可以彈性擴(kuò)展計(jì)算資源,支持高吞吐下的數(shù)據(jù)查詢。
- 低延時查詢:Tablestore 按照 LSM 存儲引擎實(shí)現(xiàn),支持 Block Cache 加速查詢,用戶也通過配置豐富的索引,優(yōu)化業(yè)務(wù)查詢。
- 低成本存儲和彈性計(jì)算成本:在存儲成本上,Tablestore 屬于結(jié)構(gòu)化 NoSQL 存儲類型,數(shù)據(jù)存儲成本比起關(guān)系型數(shù)據(jù)庫或者高速緩存要低很多;在計(jì)算成本上,Tablestore 采用了存儲計(jì)算架構(gòu),可以按需彈性擴(kuò)展計(jì)算資源。
- 與 Flink 維表優(yōu)化的高度對接:Tablestore 支持 Flink 維表優(yōu)化的所有策略,包括 Async IO 和不同緩存策略。
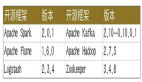
方案對比
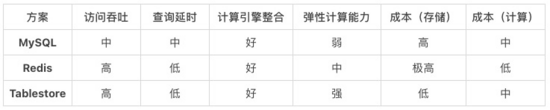
上面是前文提到的幾個維表方案在各個維度的對比。接下來,將舉幾個具體的場景細(xì)致對比下成本:
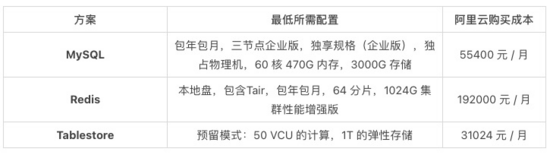
1. 高存儲高計(jì)算:維表需要存 100 億條訂單維度的數(shù)據(jù),總計(jì)存儲量需要 1T,盡管業(yè)務(wù)在 Flink 任務(wù)端配置了緩存策略,但仍然有較高的 KV 查詢下沉到維表,到維表的 QPS 峰值 10 萬,均值 2.5 萬。不同維表所需的配置要求和購買成本如下:
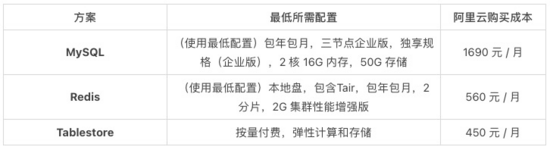
2. 低存儲低計(jì)算:維表需要存 100 萬條地域維度的數(shù)據(jù),總計(jì)存儲量需要 10M,業(yè)務(wù)端在 Flink 任務(wù)中的維表配置了 LRU 緩存策略抵御了絕大部分的流量,到維表的 QPS 峰值 1000 均值 250。不同維表所需的配置要求和購買成本如下:
3. 高存儲低計(jì)算:維表需要存 100 億條訂單維度的數(shù)據(jù),總計(jì)存儲量需要 1T,業(yè)務(wù)端在 Flink 任務(wù)中的維表配置了 LRU 緩存策略抵御了絕大部分的流量,到維表的 QPS 峰值 1000 均值 250。不同維表所需的配置要求和購買成本如下:

4. 低存儲高計(jì)算:Redis 作為內(nèi)存數(shù)據(jù)庫,具有超高頻的數(shù)據(jù) KV 查詢能力,僅 4 核 8G 內(nèi)存的 Redis集群,即可支持 16 萬 QPS的并發(fā)訪問,成本預(yù)計(jì) 1600 元 / 月,在低存儲高計(jì)算場景有著鮮明的成本優(yōu)勢。
從上面的成本對比報告中可見:
1)MySQL 由于缺乏存儲和計(jì)算的彈性,以及關(guān)系型數(shù)據(jù)庫固有的缺點(diǎn),在不同程度的存儲和計(jì)算規(guī)模下成本均較高。
2)Redis 作為內(nèi)存數(shù)據(jù)庫,在低存儲(約 128G 以下)高計(jì)算場景有著鮮明的成本優(yōu)勢,但由于內(nèi)存存儲成本很高、缺乏彈性,隨著數(shù)據(jù)規(guī)模的提升,成本呈指數(shù)增長。
3)Tablestore 基于云原生架構(gòu)可以按量對存儲和計(jì)算進(jìn)行彈性,在數(shù)據(jù)存儲和訪問規(guī)模不大時成本較低。
4)Tablestore 作為 NoSQL 數(shù)據(jù)庫存儲成本很低,在高存儲(128G 以上)場景下有著鮮明的成本優(yōu)勢。
四、實(shí)時計(jì)算結(jié)果表
1、需求分析
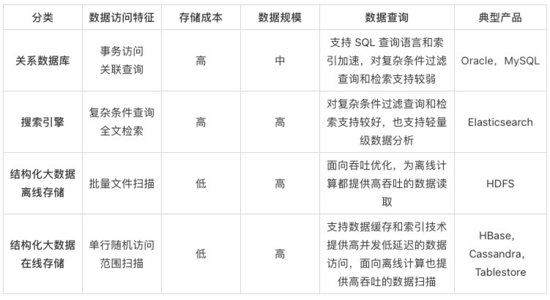
結(jié)果表作為實(shí)時計(jì)算完成后數(shù)據(jù)導(dǎo)入的存儲系統(tǒng),主要可分為關(guān)系數(shù)據(jù)庫、搜索引擎、結(jié)構(gòu)化大數(shù)據(jù)離線存儲、結(jié)構(gòu)化大數(shù)據(jù)在線存儲幾種分類,具體差異通過以下表格進(jìn)行了歸納。
對于這幾種數(shù)據(jù)產(chǎn)品,在各自場景下各有優(yōu)勢,起源的先后也各有不同。為了方便探究,我們將問題域縮小,僅僅考慮實(shí)時計(jì)算的場景下,一個更好的結(jié)果表存儲需要承擔(dān)什么樣的角色。
上文提到了實(shí)時計(jì)算的主要幾個場景中,實(shí)時數(shù)倉,實(shí)時推薦,實(shí)時監(jiān)控三個場景需要考慮結(jié)果表的選型。我們一一分析。
- 實(shí)時數(shù)倉:實(shí)時數(shù)倉主要應(yīng)用在網(wǎng)站實(shí)時 PV / UV 統(tǒng)計(jì)、交易數(shù)據(jù)統(tǒng)計(jì)等實(shí)時分析場景。實(shí)時分析(即OLAP)場景分為預(yù)聚合、搜索引擎和 MPP(Massively Parallel Processing,即大規(guī)模并行處理)三種 OLAP 模型。對于預(yù)聚合模型來說,可以通過 Flink 計(jì)算層進(jìn)行數(shù)據(jù)聚合寫入結(jié)果表,也可以全量寫入結(jié)果表中,通過結(jié)果表自身的預(yù)聚合能力進(jìn)行數(shù)據(jù)存儲,在這種形態(tài)中極大地依賴結(jié)果表數(shù)據(jù)查詢與分析能力的支撐。對于搜索引擎模型來說,數(shù)據(jù)將全量寫入結(jié)果表中,通過搜索引擎的倒排索引和列存特性進(jìn)行數(shù)據(jù)分析,在這種形態(tài)中需要結(jié)果表有高吞吐的數(shù)據(jù)寫入能力和大規(guī)模數(shù)據(jù)存儲能力。MPP 模型是計(jì)算引擎,如果訪問的是列式存儲,可以更好地發(fā)揮分析查詢特性。實(shí)時 OLAP 存儲和計(jì)算引擎眾多,在一個完整的數(shù)據(jù)系統(tǒng)架構(gòu)下,需要有多個存儲組件并存。并且根據(jù)對查詢和分析能力的不同要求,需要數(shù)據(jù)派生派生能力在必要時擴(kuò)展到其他類型存儲。另外,實(shí)時數(shù)倉中隨著業(yè)務(wù)規(guī)模的擴(kuò)大,存儲量會大幅增長,相較來說數(shù)據(jù)查詢等計(jì)算規(guī)模變化一般不會特別明顯,所以結(jié)果表需要做到存儲和計(jì)算成本分離,極大地控制資源成本。
- 實(shí)時推薦:實(shí)時推薦主要是根據(jù)用戶喜好進(jìn)行個性化推薦,在常見的用戶商品個性化推薦場景下,一種常見的做法是將用戶的特征寫入結(jié)構(gòu)化大數(shù)據(jù)存儲(如 HBase )中,而該存儲將作為維表另一條用戶點(diǎn)擊消費(fèi)行為數(shù)據(jù)進(jìn)行關(guān)聯(lián),提取出用戶特征與行為關(guān)聯(lián)輸入,作為推薦算法的輸入。這里的存儲既需要作為結(jié)果表提供高吞吐的數(shù)據(jù)寫入能力,也需要作為維表提供高吞吐低延時的數(shù)據(jù)在線查詢能力。
- 實(shí)時監(jiān)控:應(yīng)用的實(shí)時監(jiān)控常見于金融類或者是交易類業(yè)務(wù)場景,該場景對時效性要求極高,通過對異常數(shù)據(jù)檢測,可以實(shí)時發(fā)現(xiàn)異常情況而做出一個止損的行為。在這種場景下無論是通過閾值進(jìn)行判斷還是通過異常檢測算法,都需要實(shí)時低延時的數(shù)據(jù)聚合查詢能力。
2、關(guān)鍵能力
通過以上的需求分析,我們可以總結(jié)出幾項(xiàng)實(shí)時大數(shù)據(jù)結(jié)果表的關(guān)鍵能力:
1. 大規(guī)模數(shù)據(jù)存儲
結(jié)果表存儲的定位是集中式的大規(guī)模存儲,作為在線數(shù)據(jù)庫的匯總,或者是實(shí)時計(jì)算(或者是離線)的輸入和輸出,必須要能支撐 PB 級規(guī)模數(shù)據(jù)存儲。
2. 豐富的數(shù)據(jù)查詢與聚合分析能力
結(jié)果表需要擁有豐富的數(shù)據(jù)查詢與聚合分析能力,需要為支撐高效在線查詢做優(yōu)化。常見的查詢優(yōu)化包括高速緩存、高并發(fā)低延遲的隨機(jī)查詢、復(fù)雜的任意字段條件組合查詢以及數(shù)據(jù)檢索。這些查詢優(yōu)化的技術(shù)手段就是緩存和索引,其中索引的支持是多元化的,面向不同的查詢場景提供不同類型的索引。例如面向固定組合查詢的基于 B+tree 的二級索引,面向地理位置查詢的基于 R-tree 或 BKD-tree 的空間索引或者是面向多條件組合查詢和全文檢索的倒排索引。
3. 高吞吐寫入能力
實(shí)時計(jì)算的數(shù)據(jù)表需要能承受大數(shù)據(jù)計(jì)算引擎的海量結(jié)果數(shù)據(jù)集導(dǎo)出。所以必須能支撐高吞吐的數(shù)據(jù)寫入,通常會采用一個為寫入而優(yōu)化的存儲引擎。
4. 數(shù)據(jù)派生能力
一個完整的數(shù)據(jù)系統(tǒng)架構(gòu)下,需要有多個存儲組件并存。并且根據(jù)對查詢和分析能力的不同要求,需要在數(shù)據(jù)派生體系下對存儲進(jìn)行動態(tài)擴(kuò)展。所以對于大數(shù)據(jù)存儲來說,也需要有能擴(kuò)展存儲的派生能力,來擴(kuò)展數(shù)據(jù)處理能力。而判斷一個存儲組件是否具備更好的數(shù)據(jù)派生能力,就看是否具備成熟的 CDC 技術(shù)。
5. 云原生架構(gòu):存儲與計(jì)算成本分離
在云原生大數(shù)據(jù)架構(gòu)中,每一層架構(gòu)都在往服務(wù)化的趨勢演進(jìn),存儲服務(wù)化、計(jì)算服務(wù)化、元數(shù)據(jù)管理服務(wù)化等。每個組件都被要求拆分成不同的單元,作為結(jié)果表也不例外,需要具備獨(dú)立擴(kuò)展的能力,更開放、更靈活、更彈性。
單就從結(jié)果表來說,只有符合云原生架構(gòu)的組件,即基于存儲計(jì)算分離架構(gòu)實(shí)現(xiàn)的產(chǎn)品,才能做到存儲和計(jì)算成本的分離,以及獨(dú)立擴(kuò)展。存儲和計(jì)算分離的優(yōu)勢,在大數(shù)據(jù)系統(tǒng)下會更加明顯。舉一個簡單的例子,結(jié)構(gòu)化大數(shù)據(jù)存儲的存儲量會隨著數(shù)據(jù)的積累越來越大,但是數(shù)據(jù)寫入量是相對平穩(wěn)的。所以存儲需要不斷的擴(kuò)大,但是為了支撐數(shù)據(jù)寫入或臨時的數(shù)據(jù)分析而所需的計(jì)算資源,則相對來說比較固定,是按需的。
3、架構(gòu)選型
MySQL
和維表一樣,大數(shù)據(jù)和實(shí)時計(jì)算技術(shù)起步之初,MySQL 是一個萬能存儲,幾乎所有需求都可以通過 MySQL 來完成,因此應(yīng)用規(guī)模非常廣,結(jié)果表也不例外。隨著數(shù)據(jù)規(guī)模的不斷擴(kuò)展和需求場景的日漸復(fù)雜,MySQL 有點(diǎn)難以承載,就結(jié)果表的場景下主要存在以下問題:
1. 大數(shù)據(jù)存儲成本高:這個在之前討論維表時已經(jīng)提到,關(guān)系數(shù)據(jù)庫單位存儲成本非常高。
2. 單一存儲系統(tǒng),提供的查詢能力有限:隨著數(shù)據(jù)規(guī)模的擴(kuò)大,MySQL 讀寫性能的不足問題逐漸顯現(xiàn)了出來。另外,隨著分析類 AP 需求的產(chǎn)生,更適合 TP 場景的 MySQL 查詢能力比較有限。
3. 高吞吐數(shù)據(jù)寫入能力較差:作為 TP 類的關(guān)系型數(shù)據(jù)庫,并不是特別擅長高吞吐的數(shù)據(jù)寫入。
4. 擴(kuò)展性差,擴(kuò)展成本較高:這個在之前討論維表時已經(jīng)提到,MySQL 在存儲側(cè)的擴(kuò)展需要進(jìn)行數(shù)據(jù)復(fù)制遷移,且需要雙倍資源,因此擴(kuò)展靈活性差,成本也比較高。
以上這些限制使 MySQL 在大數(shù)據(jù)結(jié)果表場景下存在性能瓶頸,成本也比較高,但作為關(guān)系型數(shù)據(jù)庫,不是特別適合作為大數(shù)據(jù)的結(jié)果表使用。
HBase
由于關(guān)系型數(shù)據(jù)庫的天然瓶頸,基于 BigTable 概念的分布式 NoSQL 結(jié)構(gòu)化數(shù)據(jù)庫應(yīng)運(yùn)而生。目前開源界比較知名的結(jié)構(gòu)化大數(shù)據(jù)存儲是 Cassandra 和 HBase,Cassandra 是 WideColumn 模型 NoSQL 類別下排名 Top-1 的產(chǎn)品,在國外應(yīng)用比較廣泛。這篇文章中,我們重點(diǎn)提下在國內(nèi)應(yīng)用更多的 HBase。 HBase 是基于 HDFS 的存儲計(jì)算分離架構(gòu)的 WideColumn 模型數(shù)據(jù)庫,擁有非常好的擴(kuò)展性,能支撐大規(guī)模數(shù)據(jù)存儲,它的優(yōu)點(diǎn)為:
1. 大數(shù)據(jù)規(guī)模存儲,支持高吞吐寫入:基于 LSM 實(shí)現(xiàn)的存儲引擎,支持大規(guī)模數(shù)據(jù)存儲,并為寫入優(yōu)化設(shè)計(jì),能提供高吞吐的數(shù)據(jù)寫入。
2. 存儲計(jì)算分離架構(gòu):底層基于 HDFS,分離的架構(gòu)可以按需對存存儲和計(jì)算分別進(jìn)行彈性擴(kuò)展。
3. 開發(fā)者生態(tài)成熟,與其他開源生態(tài)整合較好:作為發(fā)展多年的開源產(chǎn)品,在國內(nèi)也有比較多的應(yīng)用,開發(fā)者社區(qū)很成熟,與其他開源生態(tài)如 Hadoop,Spark 整合較好。
HBase有其突出的優(yōu)點(diǎn),但也有幾大不可忽視的缺陷:
1. 查詢能力弱,幾乎不支持?jǐn)?shù)據(jù)分析:提供高效的單行隨機(jī)查詢以及范圍掃描,復(fù)雜的組合條件查詢必須使用 Scan + Filter 的方式,稍不注意就是全表掃描,效率極低。HBase 的 Phoenix 提供了二級索引來優(yōu)化查詢,但和 MySQL 的二級索引一樣,只有符合最左匹配的查詢條件才能做索引優(yōu)化,可被優(yōu)化的查詢條件非常有限。
2. 數(shù)據(jù)派生能力弱:前面章節(jié)提到 CDC 技術(shù)是支撐數(shù)據(jù)派生體系的核心技術(shù),HBase 不具備 CDC 技術(shù)。
3. 非云原生 Serverless 服務(wù)模式,成本高:前面提到結(jié)構(gòu)化大數(shù)據(jù)存儲的關(guān)鍵需求之一是存儲與計(jì)算的成本分離,HBase 的成本取決于計(jì)算所需 CPU 核數(shù)成本以及磁盤的存儲成本,基于固定配比物理資源的部署模式下 CPU 和存儲永遠(yuǎn)會有一個無法降低的最小比例關(guān)系。即隨著存儲空間的增大,CPU 核數(shù)成本也會相應(yīng)變大,而不是按實(shí)際所需計(jì)算資源來計(jì)算成本。因此,只有云原生的 Serverless 服務(wù)模式,才要達(dá)到完全的存儲與計(jì)算成本分離。
4. 運(yùn)維復(fù)雜:HBase 是標(biāo)準(zhǔn)的 Hadoop 組件,最核心依賴是 Zookeeper 和 HDFS,沒有專業(yè)的運(yùn)維團(tuán)隊(duì)幾乎無法運(yùn)維。
國內(nèi)的高級玩家大多會基于 HBase 做二次開發(fā),基本都是在做各種方案來彌補(bǔ) HBase 查詢能力弱的問題,根據(jù)自身業(yè)務(wù)查詢特色研發(fā)自己的索引方案,例如自研二級索引方案、對接 Solr 做全文索引或者是針對區(qū)分度小的數(shù)據(jù)集的 bitmap 索引方案等等。總的來說,HBase 是一個優(yōu)秀的開源產(chǎn)品,有很多優(yōu)秀的設(shè)計(jì)思路值得借鑒。
HBase + Elasticsearch
為了解決 HBase 查詢能力弱的問題,國內(nèi)很多公司通過 Elasticsearch 來加速數(shù)據(jù)檢索,按照 HBase + Elasticsearch 的方案實(shí)現(xiàn)他們的架構(gòu)。其中,HBase 用于做大數(shù)據(jù)存儲和歷史冷數(shù)據(jù)查詢,Elasticsearch 用于數(shù)據(jù)檢索,其中,由于 HBase 不具備 CDC 技術(shù),所以需要業(yè)務(wù)方應(yīng)用層雙寫 HBase 和 Elasticsearch,或者啟動數(shù)據(jù)同步任務(wù)將 HBase 同步至 Elasticsearch。
這個方案能通過 Elasticsearch 極大地補(bǔ)足 HBase 查詢能力弱的問題,但由于 HBase 和 Elasticsearch 本身的一些能力不足,會存在以下幾個問題:
1. 開發(fā)成本高,運(yùn)維更加復(fù)雜:客戶要維護(hù)至少兩套集群,以及需要完成 HBase 到 Elasticsearch 的數(shù)據(jù)同步。如果要保證 HBase 和 Elasticsearch 的一致性,需要通過前文提到的應(yīng)用層多寫的方式,這不是解耦的架構(gòu)擴(kuò)展起來比較復(fù)雜。另外整體架構(gòu)比較復(fù)雜,涉及的模塊和技術(shù)較多,運(yùn)維成本也很高。
2. 成本很高:客戶需要購買兩套集群,以及維護(hù) HBase 和 Elasticsearch 的數(shù)據(jù)同步,資源成本很高。
3. 仍沒有數(shù)據(jù)派生能力:這套架構(gòu)中,只是將數(shù)據(jù)分別寫入 HBase 和 Elasticsearch 中,而 HBase 和 Elasticsearch 均沒有 CDC 技術(shù),仍然無法靈活的將數(shù)據(jù)派生到其他系統(tǒng)中。
Tablestore
Tablestore 是阿里云自研的結(jié)構(gòu)化大數(shù)據(jù)存儲產(chǎn)品,具體產(chǎn)品介紹可以參考 官網(wǎng) 以及 權(quán)威指南 。Tablestore 的設(shè)計(jì)理念很大程度上顧及了數(shù)據(jù)系統(tǒng)內(nèi)對結(jié)構(gòu)化大數(shù)據(jù)存儲的需求,并且基于派生數(shù)據(jù)體系這個設(shè)計(jì)理念專門設(shè)計(jì)和實(shí)現(xiàn)了一些特色的功能。簡單概括下 Tablestore 的技術(shù)理念:
1. 大規(guī)模數(shù)據(jù)存儲,支持高吞吐寫入:LSM 和 B+ tree 是主流的兩個存儲引擎實(shí)現(xiàn),其中 Tablestore 基于 LSM 實(shí)現(xiàn),支持大規(guī)模數(shù)據(jù)存儲,專為高吞吐數(shù)據(jù)寫入優(yōu)化。
2. 通過多元化索引,提供豐富的查詢能力:LSM 引擎特性決定了查詢能力的短板,需要索引來優(yōu)化查詢。而不同的查詢場景需要不同類型的索引,所以 Tablestore 提供多元化的索引來滿足不同類型場景下的數(shù)據(jù)查詢需求。
3. 支持 CDC 技術(shù),提供數(shù)據(jù)派生能力:Tablestore 的 CDC 技術(shù)名為 Tunnel Service,支持全量和增量的實(shí)時數(shù)據(jù)訂閱,并且能無縫對接 Flink 流計(jì)算引擎來實(shí)現(xiàn)表內(nèi)數(shù)據(jù)的實(shí)時流計(jì)算。
4. 存儲計(jì)算分離架構(gòu):采用存儲計(jì)算分離架構(gòu),底層基于飛天盤古分布式文件系統(tǒng),這是實(shí)現(xiàn)存儲計(jì)算成本分離的基礎(chǔ)。
5. 云原生架構(gòu),Serverless 產(chǎn)品形態(tài),免運(yùn)維:云原生架構(gòu)的最關(guān)鍵因素是存儲計(jì)算分離和 Serverless 服務(wù)化,只有存儲計(jì)算分離和 Serverless 服務(wù)才能實(shí)現(xiàn)一個統(tǒng)一管理、統(tǒng)一存儲、彈性計(jì)算的云原生架構(gòu)。由于是 Serverless 產(chǎn)品形態(tài),業(yè)務(wù)方無需部署和維護(hù) Tablestore,極大地降低用戶的運(yùn)維成本。
方案對比
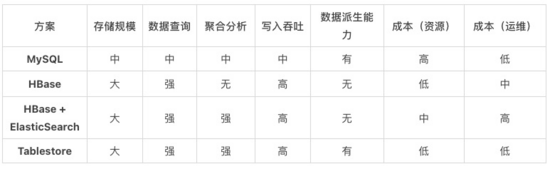
舉一個具體的場景,結(jié)果表需要存千億級別的電商訂單交易數(shù)據(jù),總計(jì)存儲量需要 1T,用戶需要對于這類數(shù)據(jù)進(jìn)行查詢與靈活的分析。日常訂單查詢與數(shù)據(jù)檢索頻率為 1000 次/秒,數(shù)據(jù)分析約每分鐘查詢 10 次左右。
以下是不同架構(gòu)達(dá)到要求所需的配置,以及在阿里云上的購買成本:

五、總結(jié)
本篇文章談了云原生大數(shù)據(jù)架構(gòu)下的實(shí)時計(jì)算維表和結(jié)果表場景下的架構(gòu)設(shè)計(jì)與選型。其中,阿里云 Tablestore 在這些場景下有一些特色功能,希望能通過本篇文章對我們有一個更深刻的了解。