













通過(guò)有效的錯(cuò)誤管理提高系統(tǒng)的魯棒性
譯文通常,系統(tǒng)的魯棒性來(lái)自全面有效的錯(cuò)誤管理。由于在我們的軟硬件系統(tǒng)環(huán)境中,任何一個(gè)部分都可能發(fā)生錯(cuò)誤,因此我們需要以不同的方式予以處理。例如:
- 數(shù)據(jù)中心——整個(gè)數(shù)據(jù)中心(DC)可能由于電源故障、網(wǎng)絡(luò)連接故障、環(huán)境災(zāi)難等,而變得不可用。
- 硬件設(shè)備——服務(wù)器、存儲(chǔ)部件可能出現(xiàn)硬盤(pán)故障、磁盤(pán)寫(xiě)滿(mǎn)、可分配的資源耗盡、以及其他硬件錯(cuò)誤等問(wèn)題。
- 軟件應(yīng)用——無(wú)論應(yīng)用程序的技術(shù)堆棧如何,都可能出現(xiàn)應(yīng)用報(bào)錯(cuò)、軟件行為異常、以及程序級(jí)別的缺陷等。
為了應(yīng)對(duì)上述來(lái)自各個(gè)方面的故障,我們往往需要通過(guò)如下手段,來(lái)提供系統(tǒng)的自愈能力:
- 通過(guò)監(jiān)控,提供電源、網(wǎng)絡(luò)、冷卻系統(tǒng)、以及其他方面的冗余,來(lái)實(shí)現(xiàn)數(shù)據(jù)中心的高可用性。
- 通過(guò)云端部署,來(lái)減少錯(cuò)誤的實(shí)例,使用更加成熟的技術(shù)堆,基于微服務(wù)的分布式架構(gòu)。
- 監(jiān)控服務(wù)器的各種參數(shù),采用各種高可用性的部署模式,運(yùn)用帶有DevOps強(qiáng)大功能的容器化模式。
- 通過(guò)應(yīng)用各種可替代的架構(gòu)與設(shè)計(jì)模式,來(lái)最小化錯(cuò)誤。例如,用戶(hù)請(qǐng)求的異步處理,可以有助于避免服務(wù)器過(guò)載的出現(xiàn),并能夠?yàn)橛脩?hù)提供一致性的體驗(yàn)。
可見(jiàn),無(wú)論是系統(tǒng)架構(gòu)師、還是應(yīng)用設(shè)計(jì)人員,他們的主要目標(biāo)都要根據(jù)實(shí)際業(yè)務(wù)需求和成本影響,精心考慮和設(shè)計(jì)各個(gè)組件的高可用性,并能夠優(yōu)雅地處理應(yīng)用程序的錯(cuò)誤。
模式的簡(jiǎn)要說(shuō)明
目前,業(yè)界有許多種架構(gòu)模式和方法,可以滿(mǎn)足不同的應(yīng)用架構(gòu)范式、功能需求、NFR(Non-Failure Request)、以及應(yīng)用程序的故障恢復(fù)能力。例如:
- 如果應(yīng)用是基于微服務(wù)的,那么我們的重點(diǎn)就應(yīng)當(dāng)放在微服務(wù)的集成依賴(lài)性的容錯(cuò)上。
- 如果應(yīng)用是基于事件的架構(gòu),那么除了正常的錯(cuò)誤處理之外,我們還應(yīng)該注意處理冪等性、以及在出現(xiàn)問(wèn)題時(shí)可能造成的數(shù)據(jù)丟失上。
- 基于API同步的應(yīng)用程序,雖然可以便捷地將錯(cuò)誤返回給調(diào)用者,但是如果問(wèn)題持續(xù)更長(zhǎng)的時(shí)間,我們則需要更加實(shí)用的監(jiān)控、以及事件管理機(jī)制。
- 在基于批處理的組件中,我們可能應(yīng)該將重點(diǎn)放在以?xún)绲鹊姆绞剑匦聠?dòng)或恢復(fù)原有的批處理能力上。
錯(cuò)誤代碼
如果沒(méi)有關(guān)于錯(cuò)誤代碼的通用約定與指南,每個(gè)應(yīng)用或系統(tǒng)將會(huì)按照自定義的默認(rèn)錯(cuò)誤代碼方式,根據(jù)用例和設(shè)計(jì)自行處理。而這有可能會(huì)導(dǎo)致不同方式相互之間的沖突。可見(jiàn),在應(yīng)用程序的錯(cuò)誤處理過(guò)程中,我們?cè)撌孪榷x好錯(cuò)誤代碼,通過(guò)標(biāo)準(zhǔn)化且直觀的錯(cuò)誤處理方式,既提高解決問(wèn)題的效率,又能夠通過(guò)離線(xiàn)分析的方式,統(tǒng)計(jì)錯(cuò)誤數(shù)量、負(fù)載峰值、以及特定類(lèi)型故障的影響等細(xì)節(jié)。
錯(cuò)誤處理
下面的示意圖展示了如何在基于事件的應(yīng)用程序中,處理各種錯(cuò)誤。當(dāng)然,其中具體涉及到的步驟,可能會(huì)因架構(gòu)模式的不同而有所差異。
首先,我們應(yīng)當(dāng)區(qū)分應(yīng)用程序的可重試(retryable)錯(cuò)誤和不可重試(non-retryable)錯(cuò)誤。例如,當(dāng)輸入的消息本身存在問(wèn)題時(shí),通常除非得到人工干預(yù),否則重試此類(lèi)錯(cuò)誤是沒(méi)有意義的。而那些數(shù)據(jù)庫(kù)連接方面的問(wèn)題,是值得進(jìn)行重試的。
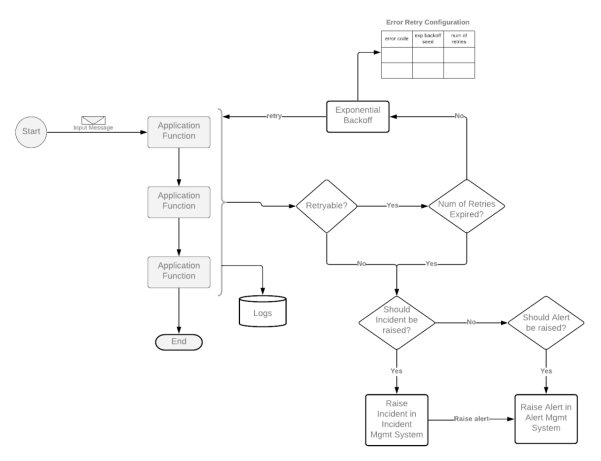
當(dāng)應(yīng)用程序出現(xiàn)重試類(lèi)型的錯(cuò)誤時(shí),我們可以選擇統(tǒng)一的“錯(cuò)誤重試配置”方式,來(lái)進(jìn)行微調(diào)處理。如下表所示,在基于事件的服務(wù)中,一旦基礎(chǔ)設(shè)施組件出現(xiàn)可用性的缺失,我們需要通過(guò)預(yù)定義的反復(fù)重試機(jī)制,來(lái)及時(shí)確認(rèn)運(yùn)營(yíng)商是否已及時(shí)修復(fù)。這往往比直接懷疑和處置由并發(fā)量請(qǐng)求所引發(fā)的問(wèn)題可能性,要更加符合常理。
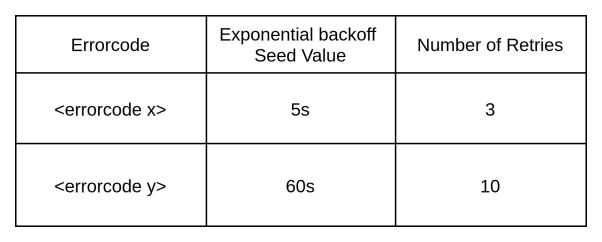
觸發(fā)事件
在所有重試都以失敗告終時(shí),我們需要有一種方法,來(lái)觸發(fā)事件并升級(jí)錯(cuò)誤。在簡(jiǎn)單情況下,我們可以將問(wèn)題的相關(guān)信息,直接以通知的形式,反饋給用戶(hù),并且建議其重新提交所需的請(qǐng)求。但是有些問(wèn)題源于某個(gè)內(nèi)部技術(shù)問(wèn)題,所引發(fā)并導(dǎo)致的用戶(hù)體驗(yàn)度的驟降。例如,在基于事件的架構(gòu)中,異步集成模式通常使用DLQ(譯者注:Dead Letter Queue,死信隊(duì)列)作為錯(cuò)誤處理模式。不過(guò),DLQ只是整個(gè)過(guò)程中的一個(gè)臨時(shí)步驟。我們?nèi)匀恍枰ㄟ^(guò)觸發(fā)事件或發(fā)送警報(bào)的方式,去可靠地升級(jí)錯(cuò)誤。那么,我們?cè)撊绾卧O(shè)計(jì)一個(gè)事件與警報(bào)相集成的管理系統(tǒng)呢?下面,我們將討論兩種主要的方法:
第一種方法:當(dāng)應(yīng)用程序完成了所有重試之后,我們需要利用其可用的日志功能,構(gòu)建可靠的錯(cuò)誤報(bào)告路徑,以減少丟失出錯(cuò)信息的可能。雖然業(yè)界已有成熟的日志記錄標(biāo)準(zhǔn)。但是,我們?nèi)匀恍枰獙⒏鱾€(gè)錯(cuò)誤日志區(qū)別開(kāi)來(lái),以免事件管理系統(tǒng)中充滿(mǎn)了不相關(guān)的錯(cuò)誤信息。我們通常將此類(lèi)日志稱(chēng)為“錯(cuò)誤警報(bào)”。它們往往是由專(zhuān)用的代碼庫(kù)和組件,按照預(yù)先設(shè)定的格式,及時(shí)產(chǎn)生大量的錯(cuò)誤信息。下面是一段代碼示例:
Java
{
"logType": "ErrorAlert",
"errorCode": "subA.compA.DB.DatabaseA.Access_Error",
"businessObjectId": "234323",
"businessObjectName": "ACCOUNT",
"InputDetails" : "<Input object/ event object>",
"InputContext" : " any context info with the input",
"datetime": "date time of the error",
"errorDetails" : "Error trace",
"..other info as needed": "..."
}
由于大多數(shù)組織會(huì)使用不同的日志監(jiān)控技術(shù)棧,因此,我在此以日志聚合器(log aggregator)為例,會(huì)將各種日志路由到不同的組件處,以便讀取日志事件、對(duì)應(yīng)的配置,并按需觸發(fā)警報(bào)。如下圖所示,如果出現(xiàn)需要在監(jiān)控的基礎(chǔ)上,去解決被發(fā)現(xiàn)的問(wèn)題時(shí),我們往往需要再次調(diào)用DLQ予以處理。
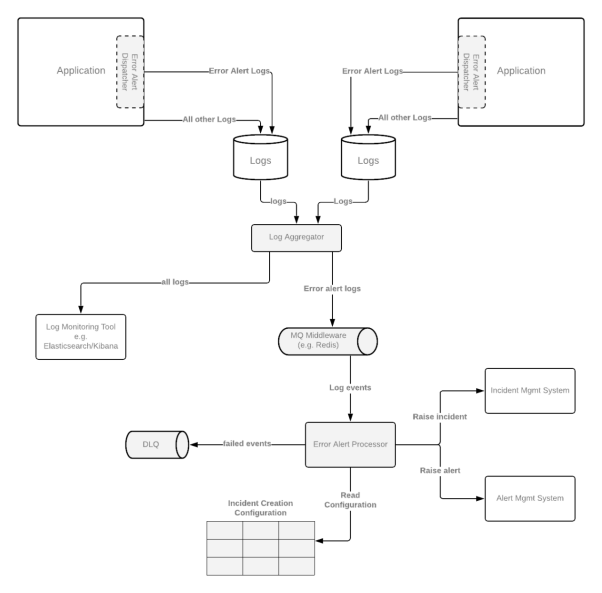
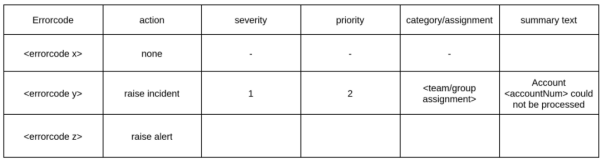
為了讓警報(bào)能夠反應(yīng)有意義且具有操作性的事件,我們通常需要對(duì)它們進(jìn)行必要的配置。由于組織采用的事件管理系統(tǒng)存在著差異性,因此不同的配置可能會(huì)驅(qū)動(dòng)不同類(lèi)型的后續(xù)操作。以下是各種需要配置屬性的示例。其錯(cuò)誤代碼會(huì)在整個(gè)系統(tǒng)中遵循特定的分類(lèi)方法。當(dāng)然,它們也可以按需集中到一個(gè)中央的配置管理系統(tǒng)中。
如下圖所示,第二種方法是將錯(cuò)誤警報(bào)的調(diào)度程序組件寫(xiě)入DLQ,而非各個(gè)日志中,而其他方面則與第一種方法基本相似。也就是說(shuō),它是基于DLQ的。
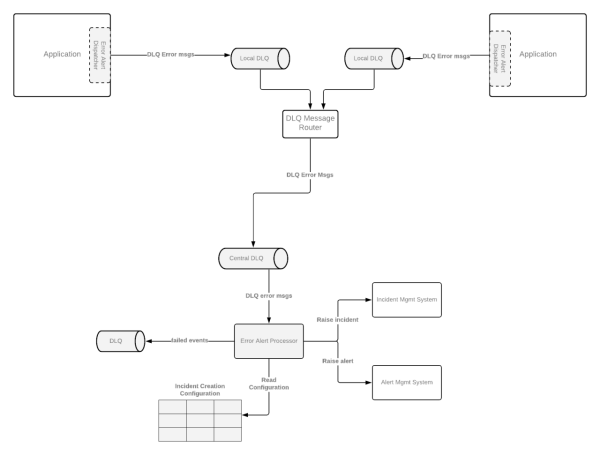
哪種方法更好?
從應(yīng)用程序的角度來(lái)看,基于日志的方法更具有靈活性,當(dāng)然也存在著如下缺點(diǎn):
- 在錯(cuò)誤到達(dá)事件管理系統(tǒng)之前,我們需要處理各個(gè)部件之間的相互集成。
- 一般來(lái)說(shuō),日志數(shù)據(jù)的關(guān)鍵性程度并不是很高,但是如果我們用它來(lái)觸發(fā)事件的話(huà),那么就需要檢查它是否存在著丟失或不全的風(fēng)險(xiǎn)。在曾經(jīng)的系統(tǒng)實(shí)施的過(guò)程中,我就曾碰到過(guò)應(yīng)用請(qǐng)求出現(xiàn)的峰值,導(dǎo)致日志數(shù)據(jù)丟失的問(wèn)題。當(dāng)時(shí)我們就不得不放棄了該方法。當(dāng)然,這是一種極端的情況,并非所有的日志記錄環(huán)境都會(huì)遇到此類(lèi)狀況。
而基于DLQ的方法則存在著如下優(yōu)、缺點(diǎn):
- 我們可以在消息傳遞系統(tǒng)上,將基于DLQ的方法,作為非DLQ方式的冗余傳輸鏈路。當(dāng)然,是否真的需要此類(lèi)冗余機(jī)制,則完全取決于所傳輸?shù)臄?shù)據(jù)的重要性。
- 如果我們需要結(jié)合現(xiàn)有系統(tǒng)中的其他應(yīng)用,那么在將其連接至中央總線(xiàn)(central bus)并發(fā)送錯(cuò)誤警報(bào)時(shí),消息路由器的數(shù)量則可能會(huì)受到一定的限制。而就這種結(jié)合方案本身而言,它不但會(huì)增加系統(tǒng)的復(fù)雜性,而且提高了額外出錯(cuò)的可能性。
- 推倒重來(lái)的方式只是“看起來(lái)很美”。畢竟越少的組件或總線(xiàn)需要被集成,錯(cuò)誤警報(bào)事件傳輸?shù)目煽啃圆艜?huì)越高。
小結(jié)
可見(jiàn),為了有效地處理應(yīng)用程序中可能出現(xiàn)的錯(cuò)誤,我們需要一種整體的解決方法,能夠無(wú)縫地集成到現(xiàn)有的IT系統(tǒng)中,實(shí)現(xiàn)對(duì)于錯(cuò)誤和問(wèn)題的有效管理。雖然上文主要討論的是如何將應(yīng)用程序的錯(cuò)誤處理,集成到事件管理系統(tǒng)中,但是對(duì)于本文開(kāi)頭提到的各種硬件問(wèn)題,此類(lèi)思路與方法同樣具有適用性。當(dāng)然,所有這些都應(yīng)當(dāng)以自動(dòng)化的方式,聚集到一處,以便它們能夠進(jìn)一步關(guān)聯(lián)上各種錯(cuò)誤與問(wèn)題,進(jìn)而采用單一的解決方案,來(lái)處置所有可能出現(xiàn)的問(wèn)題。
前文也向您展示了兩種依賴(lài)于事件管理系統(tǒng)、并能夠與現(xiàn)代技術(shù)(如API或某種SDK)相集成的處置方法。當(dāng)然,具體方法的采用也會(huì)因平臺(tái)而異。不過(guò)值得注意的是,在根據(jù)問(wèn)題創(chuàng)建重復(fù)性事件時(shí),為了避免“淹沒(méi)”事件管理系統(tǒng)。我們應(yīng)當(dāng)盡量少地使用集成,而盡量多地采用開(kāi)箱即用的事件管理系統(tǒng)。對(duì)此,一些自動(dòng)化的、智能化的事件去重方案,往往能夠有效地解決此類(lèi)問(wèn)題。
譯者介紹
陳 峻 (Julian Chen),51CTO社區(qū)編輯,具有十多年的IT項(xiàng)目實(shí)施經(jīng)驗(yàn),善于對(duì)內(nèi)外部資源與風(fēng)險(xiǎn)實(shí)施管控,專(zhuān)注傳播網(wǎng)絡(luò)與信息安全知識(shí)與經(jīng)驗(yàn);持續(xù)以博文、專(zhuān)題和譯文等形式,分享前沿技術(shù)與新知;經(jīng)常以線(xiàn)上、線(xiàn)下等方式,開(kāi)展信息安全類(lèi)培訓(xùn)與授課。
原文標(biāo)題:Building Resiliency With Effective Error Management,作者:Shailesh Agarwal

























