Pastebin設計之旅:從零設計網絡文本存儲系統
項目簡介:Pastebin是一個在線的文本存儲平臺,讓用戶可以存儲和分享代碼片段或者其他類型的文本。它支持多種編程和標記語言的語法高亮,用戶可以選擇讓他們的"paste"公開或私有。無需注冊就可以使用,但注冊用戶可以更方便地管理他們的"paste"。Pastebin常被開發者、系統管理員以及其他技術專業人員用于分享和協作。
現在讓我們來設計一個類似Pastebin的網絡服務,用戶可以在這里儲存純文本。用戶可以輸入一段文本,并獲取一個隨機生成的URL來訪問這段文本。
類似的產品有:pastebin.com,controlc.com,hastebin.com,privatebin.net
系統難度等級:初級
1、什么是Pastebin
Pastebin及類似服務讓用戶能夠在網絡(通常指的是互聯網)上存儲純文本或圖像,并生成唯一的URL來訪問上傳的數據。這樣的服務也被用來快速地在網絡上共享數據,用戶只需傳遞URL,其他用戶就可以查看其內容。
如果你以前沒有使用過pastebin.com,建議嘗試在那里創建一個新的“Paste”,并花些時間瀏覽他們服務提供的不同選項。這將在理解本章時有很大幫助。
對于類似于Pastebin這樣的代碼或文本分享平臺,中國并未有一款特別知名或廣泛使用的網站。很多開發者會使用GitHub Gist來分享代碼片段,此外,國內也有一些代碼托管平臺,比如Coding.net和Gitee,也提供代碼分享和協作的功能。
2、系統的需求和目標
Pastebin服務需要滿足以下要求:
功能需求:
- 用戶應能夠上傳或“粘貼”他們的數據,并獲得一個獨特的URL來訪問它。
- 用戶只能上傳文本。
- 數據和鏈接將在特定的時間段后自動過期;用戶應可以指定過期時間。
- 用戶可以選擇為他們的粘貼內容設置一個自定義的別名。
非功能性需求:
- 系統必須具有高度的可靠性,上傳的任何數據都不應丟失。
- 系統必須始終可用。這是因為如果我們的服務暫停,用戶將無法訪問他們的粘貼內容。
- 用戶應能實時訪問他們的粘貼內容,延遲要最小。
- 粘貼的鏈接不能被輕易猜出(不能被預測)。
擴展需求:
- 分析,例如,一個粘貼內容被訪問了多少次?
- 我們的服務也應該通過REST APIs供其他服務訪問。
3、注意事項
Pastebin與URL縮短服務(系統設計上一個案例)有一些相同的需求,但是我們還應該考慮一些額外的設計因素。
用戶每次粘貼的文本量應有何限制?我們可以限制用戶不得粘貼超過10MB10MB10MB的數據,以防止服務被濫用。
我們是否應對自定義URL的大小設置限制?由于我們的服務支持自定義URL,用戶可以選擇他們喜歡的任何URL,但是提供自定義URL并非強制性的。然而,對自定義URL設置大小限制是合理的(而且通常是我們期望的),這樣我們可以保持一致的URL數據庫。
4、容量估計與約束
我們的服務將是讀取密集型的;相比新建Paste,讀取請求會更多。我們可以假設讀取與寫入之間的比例是5:1。
流量預估:Pastebin類似的服務并不預期有如微信或今日頭條那樣的流量,這里我們假設每天有一百萬個新的粘貼內容添加到我們的系統中。這樣算來,我們每天有五百萬次的讀取。
每秒新粘貼內容:
1M / (24 小時 * 3600 秒) ~= 12 粘貼/秒
每秒粘貼讀取次數:
5M / (24 小時 * 3600 秒) ~= 58 讀取/秒
存儲預估:用戶最多可以上傳10MB的數據;一般來說,Pastebin類似的服務用于分享源代碼、配置文件或日志。這些文本并不大,所以我們假設每個粘貼內容平均含有10KB10KB10KB。
按照這個速率,我們每天將存儲10GB的數據。
1M * 10KB => 10 GB/天
如果我們想將這些數據存儲十年,那我們總共需要36TB的存儲容量。
每天有1M的粘貼內容,十年后我們將有36億的粘貼內容。我們需要生成并存儲鍵來唯一地標識這些粘貼內容。如果我們使用Base64編碼([A-Z, a-z, 0-9, ., -]),我們將需要六個字符的字符串:
64^6 ~= 68.7億個唯一字符串
如果存儲一個字符需要一個字節,存儲36億個鍵所需的總大小將是:
3.6B?6=>22GB
相比于36TB,22GB微不足道。為了保留一些余量,我們將假設一個70%的容量模型(意味著我們在任何時候都不希望使用超過總存儲容量的70%),這將使我們的存儲需求增加到 51.4TB。
帶寬預估:對于寫入請求,我們預計每秒新增12個粘貼內容,導致每秒進入120KB的數據。
12?10KB=>120KB/s
至于讀取請求,我們預計每秒58個請求。因此,總的數據出口(發送給用戶)將是0.6MB/s。
58?10KB=>0.6MB/s
盡管總的進出口并不大,我們在設計服務時應記住這些數字。
內存預估:我們可以緩存一些被頻繁訪問的熱門粘貼內容。根據80-20原則,意味著20%的熱門粘貼內容產生了80%的流量,我們希望將這20%的粘貼內容進行緩存。
既然我們每天有500萬次的讀取請求,要緩存這些請求中的20%,我們需要:
0.2?5M?10KB =10GB
因此,我們大約需要10GB的內存來緩存那些熱門的粘貼內容。
5、系統API
我們可以有SOAP或REST API來公開我們服務的功能。以下是創建/檢索/刪除粘貼內容的API定義:
addPaste(api_dev_key, paste_data, custom_url=None user_name=None, paste_name=None, expire_date=None)參數:
api_dev_key (字符串): 已注冊帳戶的API開發者密鑰。這將用于基于分配的配額對用戶進行限流等操作。
paste_data (字符串): 粘貼的文本數據。
custom_url (字符串): 可選的自定義URL。
user_name (字符串): 可選的用于生成URL的用戶名。
paste_name (字符串): 粘貼內容的可選名稱。
expire_date (字符串): 粘貼內容的可選過期日期。
返回: (字符串)
成功插入返回可以訪問粘貼內容的URL,否則,它將返回一個錯誤碼。
類似地,我們可以有檢索和刪除粘貼內容的API:
getPaste(api_dev_key, api_paste_key)其中api_paste_key是一個表示要檢索的粘貼內容的粘貼鍵的字符串。這個API將返回粘貼內容的文本數據。
deletePaste(api_dev_key, api_paste_key)成功刪除返回true,否則返回false。
6、數據庫設計
關于我們存儲的數據性質,我們有一些觀察:
- 我們需要存儲數十億條記錄。
- 我們存儲的每個元數據對象都很小(小于1KB)。
- 我們存儲的每個粘貼對象大小適中(可以達到幾MB)。
- 記錄之間沒有關系,除非我們要存儲哪個用戶創建了哪個粘貼內容。
- 我們的服務主要是讀取操作。
數據庫架構:
我們需要兩個表,一個用于存儲粘貼內容的信息,另一個用于存儲用戶的數據。
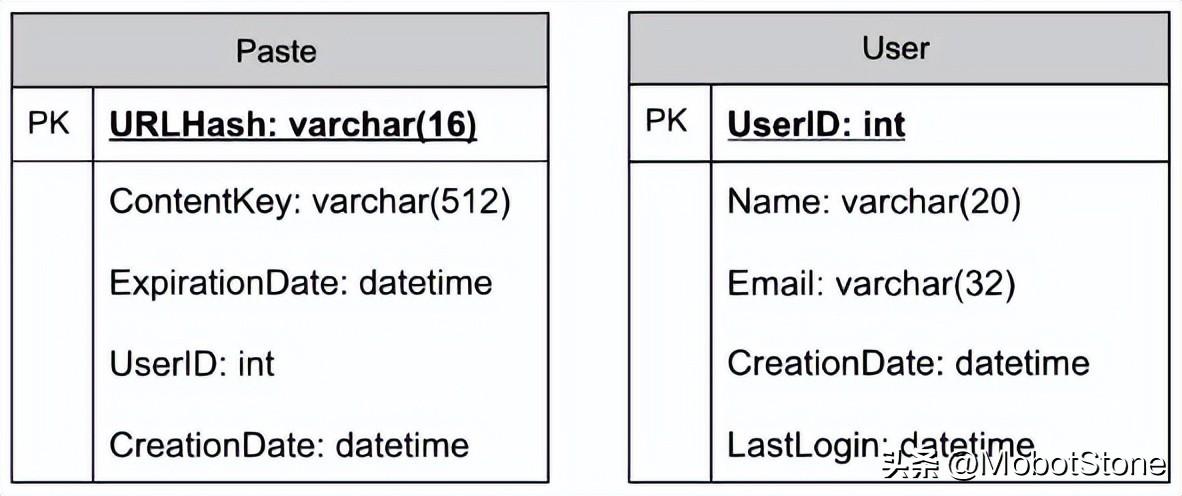
這里,URlHash是TinyURL的URL等效項,ContentKey是指向一個外部對象的引用,該對象存儲粘貼內容的內容;我們將在本章后面討論粘貼內容的外部存儲。
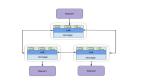
7、頂層設計
在頂層設計上,我們需要一個應用層來處理所有的讀取和寫入請求。應用層將與存儲層進行通信,以存儲和檢索數據。我們可以將存儲層劃分為兩部分,一部分數據庫存儲與每個粘貼內容、用戶等相關的元數據,另一部分將粘貼內容存儲在某些對象存儲中(如阿里云OSS)。這種數據的劃分也允許我們單獨進行擴展。

8、組件設計
A. 應用層
我們的應用層將處理所有的進出請求。應用服務器將與后端數據存儲組件進行通信以服務這些請求。
如何處理寫入請求?在收到寫入請求后,我們的應用服務器將生成一個六位隨機字符串,這將作為粘貼的鍵(如果用戶沒有提供自定義鍵)。然后,應用服務器將粘貼的內容和生成的鍵存儲在數據庫中。成功插入后,服務器可以將鍵返回給用戶。這里可能存在的一個問題是由于鍵重復而導致插入失敗。由于我們是生成一個隨機鍵,所以新生成的鍵可能與現有的鍵相匹配。在這種情況下,我們應該重新生成一個新的鍵并再試一次。我們應該一直重試,直到我們不再因為重復鍵看到失敗。如果用戶提供的自定義鍵已經在我們的數據庫中存在,我們應該向用戶返回一個錯誤。
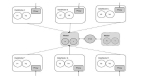
上述問題的另一種解決方案可能是運行一個獨立的鍵生成服務(KGS),它提前生成隨機的六位字符串,并將它們存儲在數據庫中(我們稱之為key-DB)。每當我們想要存儲一個新的粘貼,我們只需要取一個已經生成的鍵并使用它。這種方法將使事情變得非常簡單和快速,因為我們不會擔心重復或碰撞。KGS將確保所有插入key-DB的鍵都是唯一的。
KGS可以使用兩個表來存儲鍵,一個用于尚未使用的鍵,一個用于所有已使用的鍵。一旦KGS向應用服務器提供了一些鍵,它可以將這些移動到已使用的鍵表中。KGS可以始終在內存中保持一些鍵,以便每當服務器需要它們時,它可以快速提供。一旦KGS在內存中加載了一些鍵,它就可以將它們移動到已使用的鍵表中;這樣我們就可以確保每個服務器獲取到的鍵都是唯一的。如果KGS在使用所有加載到內存中的鍵之前死掉,我們將浪費這些鍵。我們可以忽略這些鍵,因為我們有大量的鍵。
KGS會出現單點故障嗎?會的。為了解決這個問題,我們可以有一個備用的KGS副本,每當主服務器死掉時,它可以接管來生成和提供鍵。
每個應用服務器可以從key-DB中緩存一些鍵嗎?是的,這肯定可以加快速度。雖然在這種情況下,如果應用服務器在消費所有鍵之前死掉,我們將最終丟失那些鍵。這可能是可以接受的,因為我們有68B個唯一的六位字母鍵,這比我們需要的要多得多。
如何處理粘貼讀取請求?在收到讀取粘貼請求后,應用服務層聯系數據存儲。數據存儲搜索鍵,如果找到了,就返回粘貼的內容。否則,返回一個錯誤碼。
B. 數據存儲層
我們可以將我們的數據存儲層分為兩部分:
- 元數據數據庫:我們可以使用像MySQL這樣的關系數據庫,或者像Dynamo或Cassandra這樣的分布式Key-Value存儲。
- 對象存儲:我們可以將我們的內容存儲在像阿里云OSS這樣的對象存儲中。每當我們感覺到我們的內容存儲容量已經滿了,我們可以通過平臺直接擴容。

9、數據分區和復制
為了擴展我們的數據庫,我們需要對其進行分區,以便它能存儲數十億個URL的信息。因此,我們需要設計一個分區方案,將我們的數據劃分并存儲到不同的數據庫中。
A. 基于范圍的分區:我們可以根據哈希鍵的第一個字母在不同的分區中存儲URL。因此,我們將所有以字母“A”(和“a”)開頭的URL哈希鍵存儲在一個分區中,將以字母“B”開頭的URL存儲在另一個分區中,以此類推。這種方法被稱為基于范圍的分區。我們甚至可以將某些出現頻率較低的字母組合到一個數據庫分區中。因此,我們應開發一個靜態分區方案,始終以可預測的方式存儲/查找URL。
這種方法的主要問題是可能導致數據庫服務器不平衡。例如,我們決定將所有以字母“E”開頭的URL放入一個數據庫分區,但后來我們發現以字母“E”開頭的URL過多。
B. 基于哈希的分區:在這種方案中,我們對存儲的對象進行哈希。然后,我們根據哈希值計算使用哪個分區。在我們的情況下,我們可以獲取key或短鏈接的哈希值,以確定我們存儲數據對象的分區。
我們的哈希函數將隨機地將URL分配到不同的分區(例如,我們的哈希函數可以始終將任何key映射到[1...256]之間的一個數字)。這個數字將表示我們存儲對象的分區。
這種方法仍然可能導致分區負載過大,這可以通過使用'一致性哈希'來解決。
10、緩存
我們可以緩存頻繁訪問的URL。我們可以使用任何現成的解決方案,比如Memcached,它可以存儲完整的URL及其對應的哈希值。因此,應用服務器在訪問后端存儲之前,可以快速檢查緩存是否有所需的URL。
我們應該有多少緩存內存?我們可以從日流量的20%開始,根據客戶的使用模式,我們可以調整需要多少緩存服務器。如上所估計,我們需要170GB的內存來緩存日流量的20%。目前的一些服務器可以擁有256GB的內存,我們可以輕松將所有緩存放入一臺機器。或者,我們可以使用幾臺小一點的服務器來存儲所有這些熱門URL。
哪種緩存驅逐策略最適合我們的需求?當緩存滿了,我們想用一個新的/更熱門的URL替換一個鏈接,我們應該如何選擇?最近最少使用(LRU)可能是我們系統的一個合理策略。根據這個策略,我們首先丟棄最近最少使用的URL。我們可以使用Linked Hash Map或類似的數據結構來存儲我們的URL和哈希值,這也會記錄最近訪問過的URL。
為了進一步提高效率,我們可以復制我們的緩存服務器來分配它們之間的負載。
每個緩存副本如何更新?每當有一個緩存未命中,我們的服務器會訪問后端數據庫。當這種情況發生,我們可以更新緩存,并將新的條目傳遞給所有的緩存副本。每個副本都可以通過添加新的條目來更新其緩存。如果副本已經有了該條目,它可以簡單地忽略它。

11、負載均衡(LB)
我們可以在系統中的三個位置添加負載均衡層:
- 客戶端與應用服務器之間
- 應用服務器與數據庫服務器之間
- 應用服務器與緩存服務器之間
最初,我們可以使用一個簡單的輪詢方法,將進入的請求均等地分配到后端服務器。這種負載均衡方法簡單易行,不會引入任何額外的開銷。這種方法的另一個優點是,如果一個服務器死機,負載均衡器會將其從輪詢中移除,停止向其發送任何流量。
輪詢負載均衡的一個問題是,我們沒有考慮到服務器的負載。如果一個服務器過載或運行緩慢,負載均衡器不會停止向該服務器發送新的請求。為了處理這個問題,我們可以放置一個更優的負載均衡解決方案,它定期查詢后端服務器的負載,并根據負載情況調整流量。
12、清除或數據庫清理
key條目是否應永久存在,還是應該被清除?如果達到用戶設定的過期時間,鏈接應該怎么處理?
如果我們選擇持續尋找過期鏈接并將其刪除,這將對我們的數據庫產生很大壓力。相反,我們可以慢慢地刪除過期的鏈接,進行懶人清理。我們的服務將確保只刪除過期的鏈接,盡管有些過期鏈接可能會存在更長時間,但永遠不會被返回給用戶。
- 每當用戶試圖訪問一個已過期的鏈接,我們可以刪除該鏈接并向用戶返回錯誤。
- 我們可以設置一個單獨的清理服務,定期從我們的存儲和緩存中刪除過期的鏈接。這個服務需要非常輕量,只在預計用戶流量較低的時候運行。
- 我們可以為每個鏈接設定一個默認的過期時間(例如兩年)。
- 刪除過期鏈接后,我們可以將該Key重新放回Key-DB,以供重復使用。
- 我們是否應刪除一段時間(比如說六個月)內沒有被訪問過的鏈接?這可能有點不合適。由于存儲成本越來越低,我們可以決定永久保存鏈接。

13、數據跟蹤
我們如何統計短鏈接被使用的次數、用戶的位置等信息?我們如何儲存這些統計信息?如果它是數據庫中的一部分,每次查看都需要更新,那么當一個流行的短鏈接被大量并發請求瞬間涌入時,會發生什么?
一些值得追蹤的統計數據:訪客的國家、訪問的日期和時間、引導點擊的網頁、訪問頁面的瀏覽器或平臺。
14、安全和權限
用戶能否創建私有URL或者允許特定的用戶組訪問某個URL?
我們可以在數據庫中每個URL的條目里存儲訪問權限級別(公開/私有)。我們也可以創建一個單獨的表來存儲有權訪問特定URL的用戶的UserID。如果一個用戶沒有權限但試圖訪問一個URL,我們可以返回一個錯誤(HTTP 401)。考慮到我們的數據儲存在一個類似Cassandra的NoSQL寬列數據庫中,儲存權限的表的key將是‘哈希值’(或KGS生成的key)。列將儲存有權查看URL的用戶的UserID。