AI檢測器又活了?成功率高達98%,吊打OpenAI
現在AI文本檢測器,幾乎沒有辦法有效地區分AI生成的文字和人類的文字。
就連OpenAI開發的檢測工具,也因為檢測準確率太低,在上線半年后悄悄下線了。
但是最近,Nature報導了堪薩斯大學的一個團隊的研究成果,他們開發的學術AI檢測系統,能有效分辨論文中是否含有AI生成的內容,準確率高達98%!
文章地址:https://www.nature.com/articles/d41586-023-03479-4
研究團隊的核心思路是,不追求制作一個通用的檢測器,而只是針對某個具體領域的學術論文,來構建一個真正有用的AI文字檢測器。

論文地址:https://www.sciencedirect.com/science/article/pii/S2666386423005015?via%3Dihub
研究人員表示,通過針對特定類型的寫作文本定制檢測軟件,可能是通向開發出通用AI檢測器的一個技術路徑。
「如果可以快速、輕松地為某個特定領域構建檢測系統,那么為不同的領域構建這樣的系統就不那么困難了。」
研究人員提取了論文寫作風格的20個關鍵特征,然后將這些特征數據輸入XGBoost模型進行訓練,從而就能區分人類文本和AI文本。
而這二十個關鍵特征,包括句子長度的變化、某些單詞和標點符號的使用頻率等等要素。
研究人員表示「只需使用一小部分特征就能獲得很高的準確率」。
正確率高達98%
而在他們最新的研究中,檢測器是在美國化學學會(ACS)出版的十種化學期刊論文的引言部分進行了訓練。
研究小組之所以選擇「引言(Introduction)」部分,是因為如果ChatGPT能夠獲取背景文獻,那么論文的這一部分就相當容易撰寫。
研究人員用100篇已發表的引言作為人類撰寫的文本對工具進行了訓練,然后要求ChatGPT-3.5以ACS期刊的風格撰寫200篇引言。
對于GPT-3.5撰寫的200篇引言,其中的100篇,提供給了GPT-3.5論文標題來要求撰寫,而對于另外100篇,則提供了論文摘要作為寫作的依據。
最后,讓檢測器對同一期刊上由人類撰寫的引言和由人工智能生成的引言進行測試時。
檢測器識別出ChatGPT-3.5基于標題撰寫的引言部分的準確率為 100%。對于基于摘要撰寫的ChatGPT生成的引言,準確率略低,為 98%。
該工具對GPT-4撰寫的文本也同樣有效。
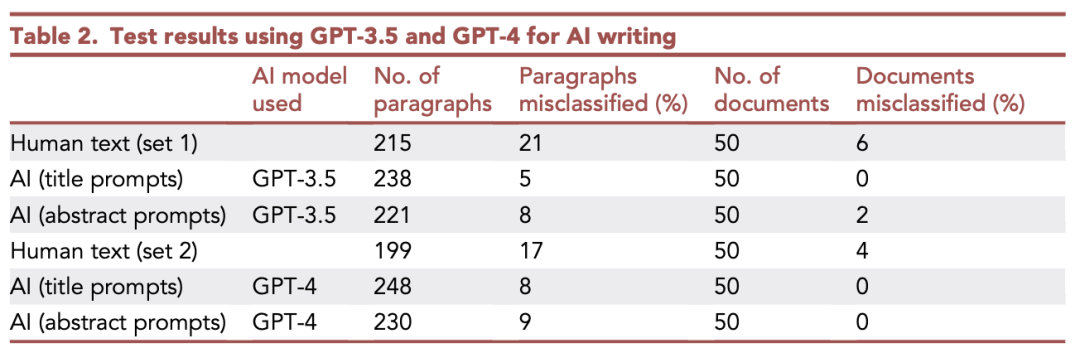
相比之下,通用AI檢測器ZeroGPT識別AI撰寫的引言的準確率只有35-65%左右,準確率取決于所使用的ChatGPT版本以及引言是根據論文標題還是摘要生成的。

由OpenAI制作的文本分類器工具(論文發表之時,OpenAI已經把這個檢測器下架了)也表現不佳,它能識別AI撰寫的引言的準確率只有10-55%。
這個新的ChatGPT檢測器甚至在處理未經過訓練的期刊時也有很出色的表現。
它還能識別出專門為了迷惑AI檢測器的提示生成的AI文本。
不過,雖然這個檢測系統對于科學期刊論文來說性能非常好,當被用來檢測大學報紙上的新聞文章時,識別效果就不太理想了。

柏林應用科學大學(HTW Berlin University of Applied Sciences)研究學術剽竊的計算機科學家Debora Weber-Wulff給予了這個研究非常高度的評價,他認為研究人員正在做的事情 「非常吸引人」。
論文細節
研究人員采用的方法依賴于20個關鍵特征和XGBoost算法。
提取的 20 個特征包括 :
(1) 每段落的句子數、(2) 每段落的單詞數、(3) 是否存在括號、(4) 是否存在破折號、(5) 是否存在分號或冒號,(6)是否存在問號,(7)是否存在撇號,(8)句子長度的標準偏差,(9)段落中連續句子的(平均)長度差異,(10 ) 存在少于 11 個單詞的句子,(11) 存在超過 34 個單詞的句子,(12) 存在數字,(13) 文本中存在兩倍以上的大寫字母(與句點相比)段落,并且存在以下詞語:(14)雖然,(15)但是,(16)但是,(17)因為,(18)這個,(19)其他人或研究人員,(20)等。
具體通過XGBoost訓練檢測器的詳細過程可以參見論文原文中的Experimental Procedure部分。
作者在之前做過一篇類似的工作,但原始工作的范圍非常有限。
為了將這種有前途的方法應用于化學期刊,需要根據該領域多個期刊的各種手稿進行審查。
此外,檢測AI文本的能力受到提供給語言模型的提示的影響,因此任何旨在檢測AI寫作的方法都應該針對可能混淆AI使用的提示進行測試,之前的研究中沒有評估這個變量。
最后,新版的ChatGPT即GPT-4已經推出,它比GPT-3.5有顯著改進。AI文本檢測器需要對來自GPT-4等新版本的語言模型的文本有效。
為了擴大了AI檢測器的適用范圍,這里的數據收集來自13個不同期刊和3個不同出版商、不同的AI提示以及不同的AI文本生成模型。
使用真實人類的文本和AI生成的文本訓練XGBoost分類器。然后通過真人寫作、 AI提示以及GPT-3.5和GPT-4等方式來生成新的范例用于評估模型。
結果表明,本文提出的這種簡單的方法非常有效。它在識別AI生成的文本方面的準確率為98%–100%,具體取決于提示和模型。相比之下,OpenAI最新的分類器的準確率在10% 到56% 之間。
本文的檢測器將使科學界能夠評估ChatGPT對化學期刊的滲透,確定其使用的后果,并在出現問題時迅速引入緩解策略。
結果與討論
文章作者從美國化學學會(ACS)的10種化學期刊中選取了人類寫作樣本。
包括《無機化學》、《分析化學》、《物理化學雜志A》、《有機化學雜志》、《ACS Omega》、《化學教育雜志》、《ACS Nano》、《環境科學與技術》、《毒理學化學研究》和《ACS化學生物學》。
使用每個期刊中10篇文章的引言部分,訓練集中總共有100個人類寫作樣本。選擇介紹部分是因為在適當的提示下,這是最有可能由ChatGPT撰寫的文章的部分。
每個期刊僅使用10篇文章是一個異常小的數據集,但作者認為這并不是一個問題,恰恰相反,假設可以使用如此小的訓練集開發有效的模型,則可以使用最小的計算能力快速部署該方法。
而之前類似的模型使用了1000萬份文檔進行模型訓練。
提示設計是這些研究中的一個關鍵方面。對于每個人類編寫的文本,AI比較器都會使用兩種不同的提示生成,這兩種提示都旨在要求ChatGPT像化學家一樣寫作。
提示1是:「請以ACS期刊的風格為標題為xxx的文章寫一篇300到400字的簡介」。
提示2是:「請以ACS期刊的風格為帶有此摘要的文章寫一篇300到400字的簡介」。
正如預期的那樣,ChatGPT將摘要中的許多關鍵事實和詞匯納入了本集中的介紹中。
整個訓練數據集包含100個人工生成的介紹和200個ChatGPT生成的介紹;每個段落都成為一個「寫作示例」。
從每個段落中提取了20個特征的列表,這些特征涉及段落的復雜性、句子長度的變化、各種標點符號的使用以及在人類科學家或ChatGPT著作中可能更頻繁出現的「流行詞」。
該模型使用留一法交叉驗證策略(leave-one-out cross-validation strategy)進行優化。
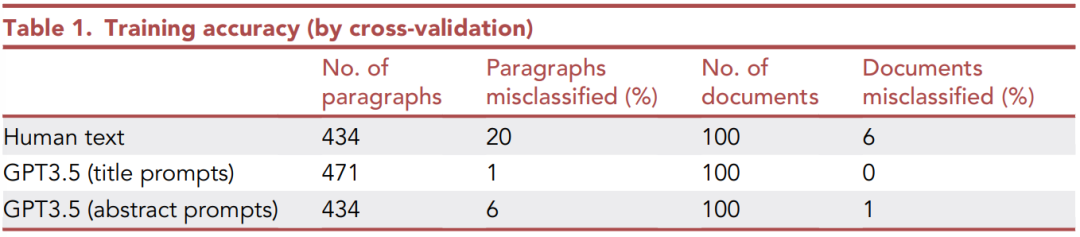
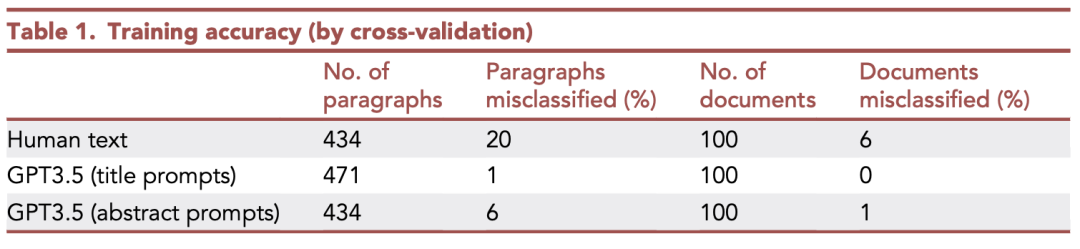
上表顯示了這些寫作樣本分類的訓練結果,包括完整文檔級別和段落級別。
最容易正確分類的文本類別是在提示1(標題)之下由ChatGPT生成的介紹。
該模型在單個段落級別的準確率是99%,在文檔級別的準確率是100%。
而在提示2(摘要)作用下的ChatGPT文本的分類精度略低。
人類生成的文本更難正確分配,但準確性仍然相當不錯。作為一個群體,人類的寫作風格比ChatGPT更加多樣化,這可能導致使用這種方法正確分類其寫作樣本的難度增大。
實驗的下一階段是使用訓練中未使用的新文檔來測試模型。
作者設計了簡單測試和困難測試。
簡單測試使用的測試數據與訓練數據性質相同(選取同一期刊的不同文章),使用新選擇的文章標題和摘要來提示ChatGPT。
而在困難測試中,使用GPT-4代替GPT-3.5來生成AI文本,由于已知GPT-4比GPT-3.5更好,那么分類精度是否會下降呢?
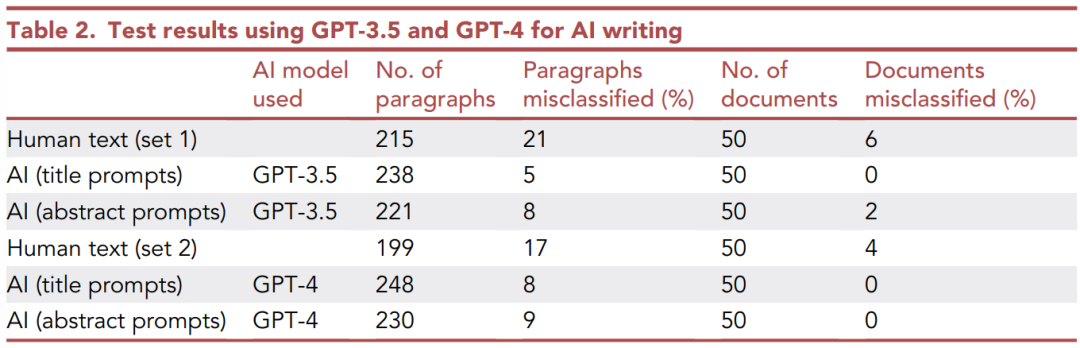
上面的表格顯示了分類的結果。與之前的結果相比,性能幾乎沒有下降。
在完整文檔級別,人工生成文本的分類準確率達到94%,提示2的AI生成文本準確率為98% , 提示1的AI文本分類正確率達到100%。
訓練集和測試集對于段落級別的分類精度也非常相似。
底部的數據顯示了使用GPT-3.5文本特征訓練的模型對GPT-4文本進行分類時的結果。所有類別的分類準確性都沒有下降,這是一個非常好的結果,證明了方法在GPT-3.5和GPT-4上的有效性。
雖然這種方法的整體準確性值得稱贊,但最好通過將其與現有的人工智能文本檢測器進行比較來判斷其價值。這里使用相同的測試集數據測試了兩種效果領先的檢測工具。
第一個工具是ChatGPT的制造商OpenAI提供的文本分類器。OpenAI承認該分類器并不完美,但仍然是他們最好的公開產品。
第二個檢測工具是ZeroGPT。其制造商聲稱檢測人工智能文本的準確率達到98%,并且該工具接受了1000萬份文檔的訓練。在目前的許多評估中,它是性能最好的分類器之一。而且,ZeroGPT制造者表示他們的方法對GPT-3.5和GPT-4都有效。
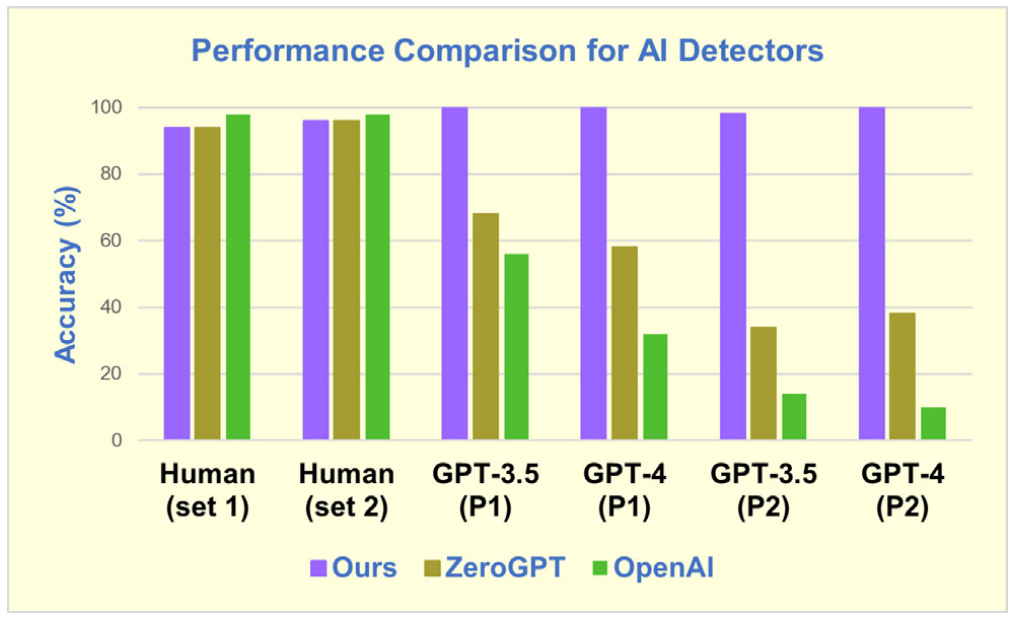
上圖顯示了本文的工具和上述兩個產品在完整文檔級別的性能比較。
三個檢測器在人類文本的識別上都有著相似的高精度;然而,在評估AI生成的文本時,三個工具存在顯著差異。
在使用提示1的情況下,本文的工具對GPT-3.5和GPT-4都有100% 的準確率,但ZeroGPT對于GPT-3.5文本的失敗率為32%,對于GPT-4文本的失敗率為42%。OpenAI產品的表現更差,在GPT-4文本上的失敗率接近70%。
在使用更難的提示2生成的AI文本時,后兩種方法的分類正確率進一步下降。
相比之下,本文的檢測器在該組測試的100個文檔中只犯了1個錯誤。
那么,該方法能否準確檢測不屬于訓練集的期刊中的ChatGPT寫作,以及如果使用不同的提示,該方法仍然有效嗎?
作者從三個期刊中選出了150篇新文章的介紹:Cell Reports Physical Science,Cell Press期刊;Nature Chemistry,來自自然出版集團;以及Journal of the American Chemical Society,這是一份未包含在訓練集中的ACS期刊。
此外,還收集了由大學生于2022年秋季撰寫并發表在10種不同大學報紙上的一組100篇報紙文章。由于本文的檢測器是專門針對科學寫作而優化的,因此可以預計新聞報道不會被高精度地分類。
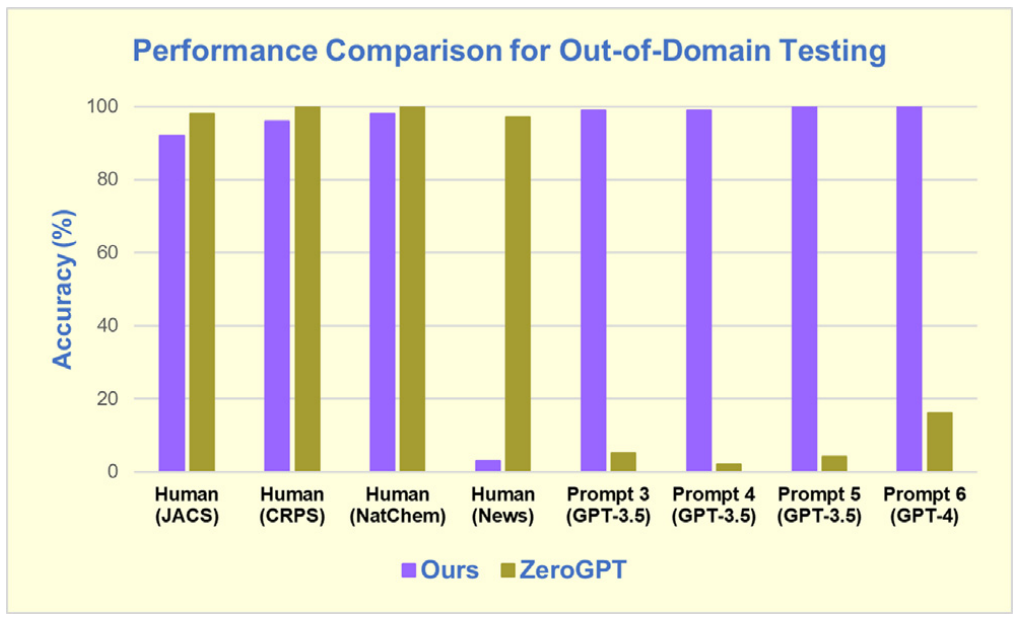
從圖中可以看到,應用相同的模型,并使用ACS期刊的文本對這組新示例進行訓練后,正確分類率為92%–98%。這與訓練集中得到的結果類似。
也正如預期的那樣,大學生撰寫的報紙文章沒有被正確歸類為人類生成的文章。
事實上,當使用本文描述的特征和模型進行評估時,幾乎所有文章都比人類科學文章更類似于人工智能生成的文本。
但是本方法旨在處理科學出版物上的檢測問題,并不適合將其擴展到其他領域。