













海量數據下的分庫分表及ClickHouse解決方案

背景
最近在做的業務中,用戶相關的數據不斷增長,給系統帶來了不小的壓力,在 SQL優化實戰-千萬量級后的慢查 一文中也總結了一些針對慢查的解決方案。但每次活動下來,都會有幾百上千萬的用戶相關數據產生,單純的sql優化已經無法解決,本文站在前人肩膀上,總結了海量數據情景下的解決方案。
分區&分庫分表
目前業務中使用的是MySQL,針對關系型數據庫,可以采用分區或者分庫分表的策略。首先看一下其各自的實現原理及優缺點:
(1)分區
- 分區原理:分區表是由多個相關的底層表實現,存儲引擎管理分區的各個底層表和管理普通表一樣,只是分區表在各個底層表上各自加上一個相同的索引(分區表要求所有的底層表都必須使用相同的存儲引擎)。
- 分區優點:它對用戶屏蔽了sharding的細節,即使查詢條件沒有sharding column,它也能正常工作(只是這時候性能一般)。
- 分區缺點:連接數、網絡吞吐量等資源都受到單機的限制;并發能力遠遠達不到互聯網高并發的要求。(主要因為雖然每個分區可以獨立存儲,但是分區表的總入口還是一個MySQL示例)。
- 適用場景:并發能力要求不高;數據不是海量(分區數有限,存儲能力就有限)。
(2)分庫分表
互聯網行業處理海量數據的通用方法:分庫分表。 分庫分表中間件全部可以歸結為兩大類型:
- CLIENT模式;
- PROXY模式;
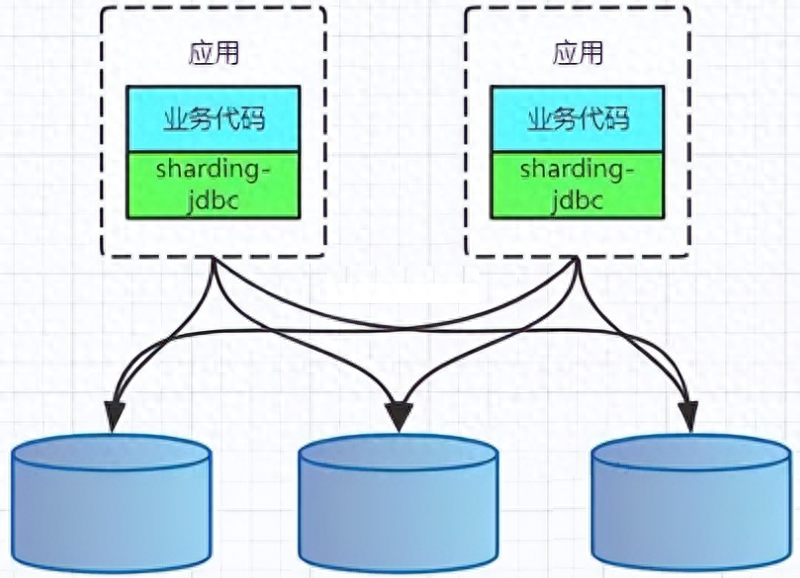
CLIENT模式代表有阿里的TDDL,開源社區的sharding-jdbc(sharding-jdbc的3.x版本即sharding-sphere已經支持了proxy模式)。架構如下:
PROXY模式代表有阿里的cobar,民間組織的MyCAT。架構如下:
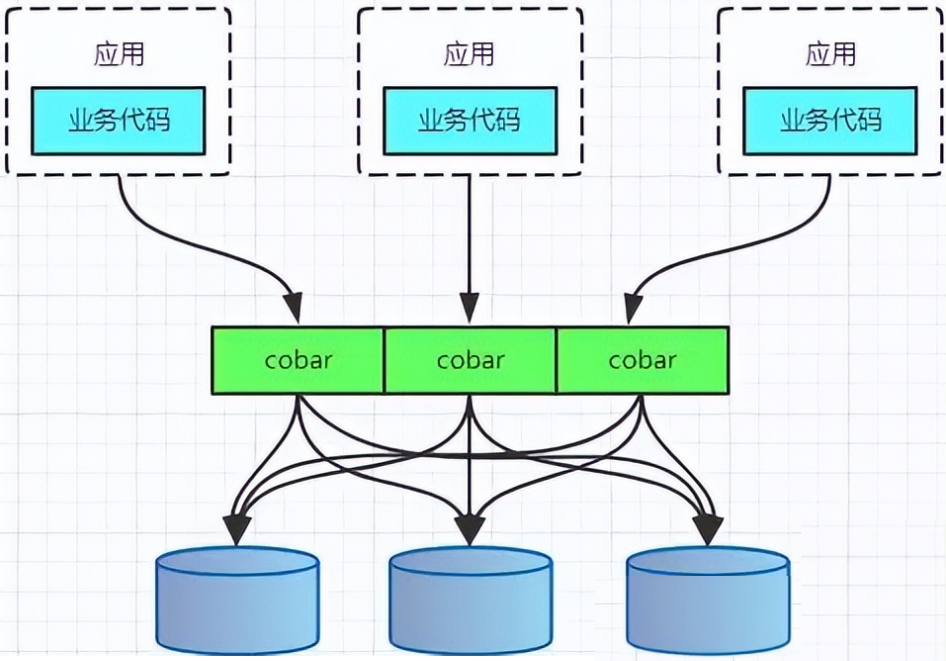
無論是CLIENT模式,還是PROXY模式。幾個核心的步驟是一樣的:SQL解析,重寫,路由,執行,結果歸并。
分庫分表實現(MYSQL)
針對分區與分庫分表的適用場景,選擇分庫分表的實現方案。結合實際業務:學生(user表)定期參加體能測試(detect表),每一次體測之后,保留對應檢測數據(data表),因此,數據data表中的核心數據:
data_id | 數據ID |
user_id | 學生ID |
detect_id | 檢測任務ID |
project_id | 檢測項目ID,如跳高、跳遠 |
project_result | 檢測結果 |
分庫分表第一步也是最重要的一步,即sharding column的選取,sharding column選擇的好壞將直接決定整個分庫分表方案最終是否成功。sharding column的選取跟業務強相關。
- 選擇方法:分析你的API流量,將流量比較大的API對應的SQL提取出來,將這些SQL共同的條件作為sharding column。
- 選擇示例:例如一般的OLTP系統都是對用戶提供服務,這些API對應的SQL都有條件用戶ID,那么,用戶ID就是非常好的sharding column。
在上述學生體測業務中,我們需要匯總統計一次體測任務中,所有學生各項的體測結果,所以按照上述的原則,需要根據體測任務ID,即detect_id進行分表,以盡量減少在統計一次體測任務的數據時的跨表查詢;但實際業務中,在學生端也有縱向對比的需求,即學生需要查看自己所有參加過的體測任務中的數據,這樣的話,按照detect_id分表,再以user_id作為查詢條件,就需要跨表查詢,效率會很低。因此,最終方案是:不同字段冗余分表。
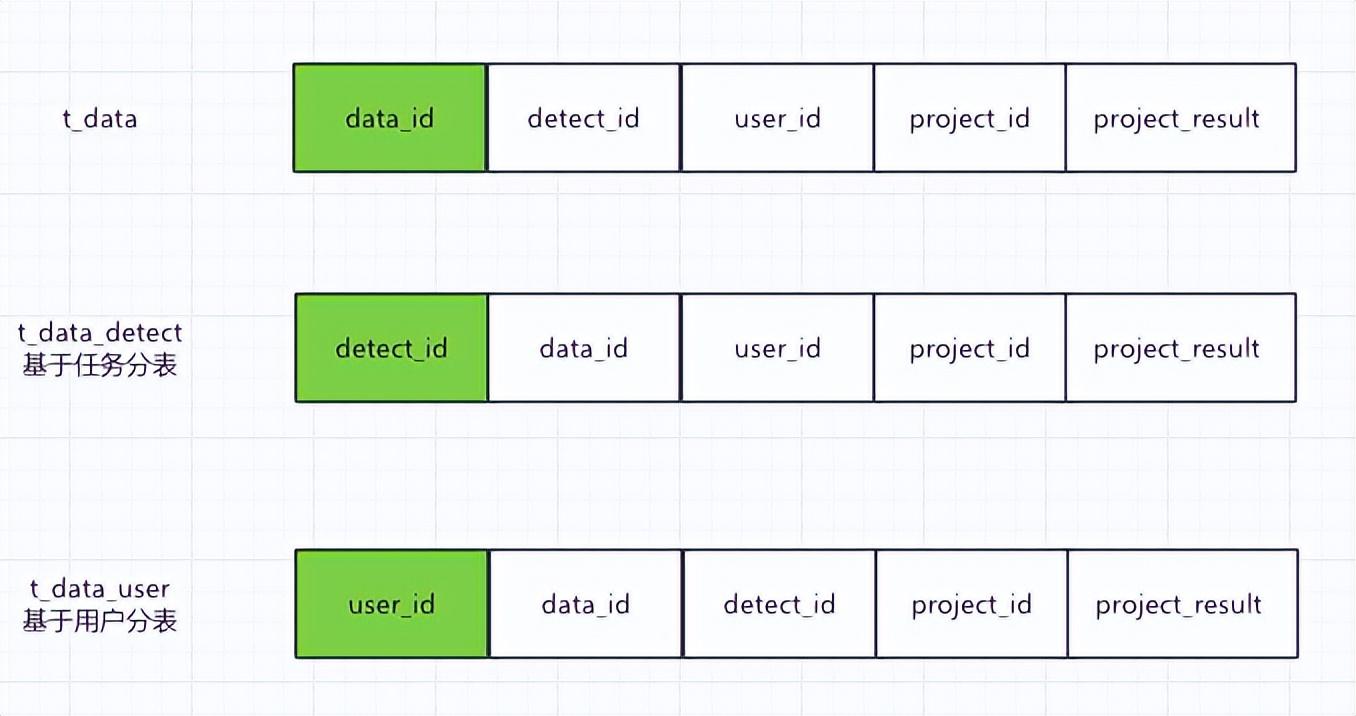
(1)冗余全量表
每個sharding列對應的表的數據都是全量的。以用戶體測數據為例:分別使用三個獨立的sharding column,即data_id(數據ID),detect_id(體測任務ID),user_id(學生ID)。
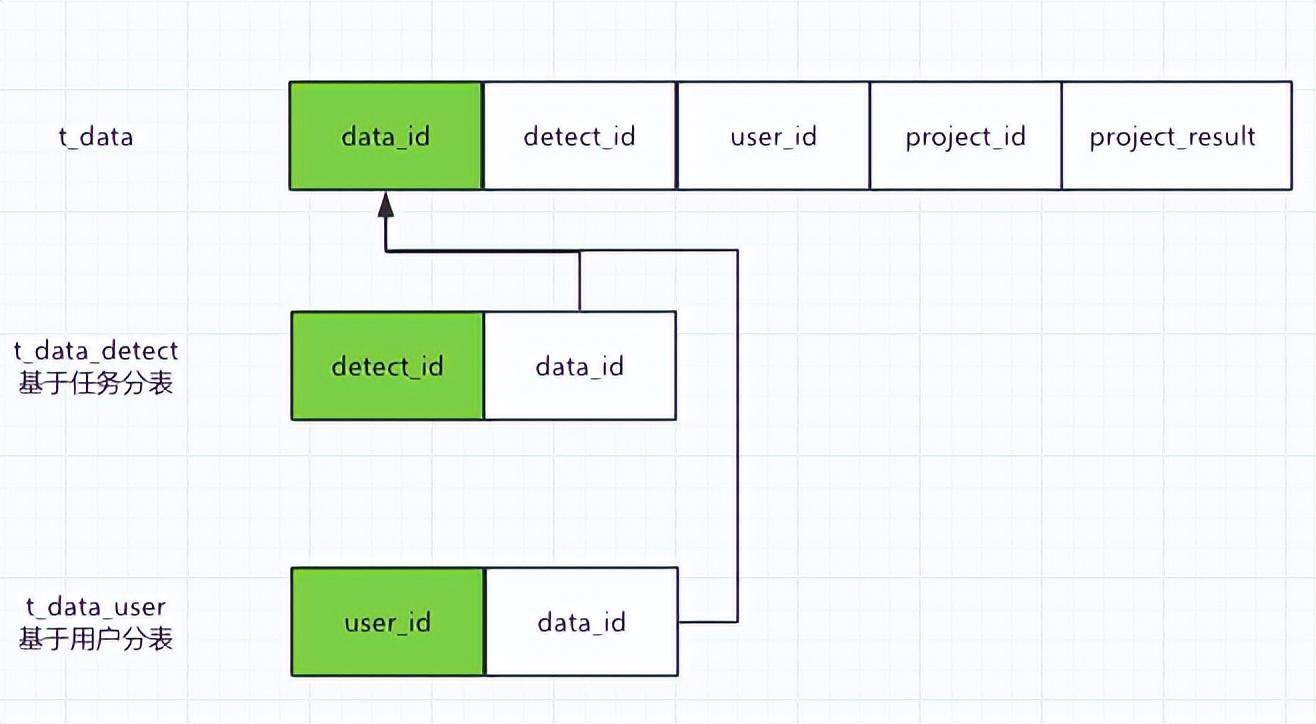
(2)冗余關系表選擇
只有一個sharding column的分庫分表的數據是全量的,其他分庫分表只是與這個sharding column的關系表。實際使用中可能會冗余更多常用字段,如學生姓名、體測任務名稱等。
(3)冗余全量表 VS 冗余關系表
- 速度對比:冗余全量表速度更快,冗余關系表需要二次查詢,即使有引入緩存,還是多一次網絡開銷;
- 存儲成本:冗余全量表需要幾倍于冗余關系表的存儲成本;
- 維護代價:冗余全量表維護代價更大,涉及到數據變更時,多張表都要進行修改。
選擇冗余全量表還是索引關系表,這是一種架構上的權衡,兩者的優缺點明顯,在我們的業務中采用冗余全量表的方式。
非關系型數據庫(ClickHouse)
上面提到的都是條件中有sharding column的SQL執行。但是,總有一些查詢條件是不包含sharding column的,同時,我們也不可能為了這些請求量并不高的查詢,無限制的冗余分庫分表。另外,在分表前,我們會事先定義好分表的數量,隨著業務擴張,單表數據達到大幾千萬甚至上億,對于MySQL而言,還是不大友好的,再去增加分表數量,也是不大現實的。因此,專業的事情最好還是使用專業的工具-ClickHouse。
ClickHouse 是近年來備受關注的開源列式數據庫,主要用于數據分析(OLAP)領域。目前國內社區火熱,各個大廠紛紛跟進大規模使用:
- 今日頭條內部用 ClickHouse 來做用戶行為分析,內部一共幾千個 ClickHouse 節點,單集群最大 1200 節點,總數據量幾十 PB,日增原始數據 300TB 左右。
- 騰訊內部用 ClickHouse 做游戲數據分析,并且為之建立了一整套監控運維體系。
- 攜程內部從 18 年 7 月份開始接入試用,目前 80% 的業務都跑在 ClickHouse 上。每天數據增量十多億,近百萬次查詢請求。
- 快手內部也在使用 ClickHouse,存儲總量大約 10PB, 每天新增 200TB, 90% 查詢小于 3S。
在 1 億數據集體量的情況下,ClickHouse 的平均響應速度是 Vertica 的 2.63 倍、InfiniDB 的 17 倍、MonetDB 的 27 倍、Hive 的 126 倍、MySQL 的 429 倍以及Greenplum 的 10 倍。
ClickHouse更多內容參考:https://juejin.cn/post/7120519057761107999
在 OLAP 數據庫中,可變數據通常不受歡迎。ClickHouse 也不歡迎可變數據。然而現實情況,更新情況不可避免。比如,學生在體測過程中,是可以進行重復測試的,即需要進行更新數據。以下是關于clickhouse更新的解決方案:
參考:https://zhuanlan.zhihu.com/p/485645089
(1)Alter/Update Table
ClickHouse團隊在2018年發布了UPDATE和DELETE,但是它不是原生的UPDATE和DELETE語句,而是被實現為ALTER TABLE UPDATE語句,如下所示:
ALTER TABLE [db.]table UPDATE column1 = expr1 [, ...] WHERE filter_expr;如更新檢測結果,ALTER UPDATE語句如下:
ALTER TABLE UPDATE detect_result=1 WHERE detect_id = 1 and user_id=4;需要注意的是,ClickHouse的更新是一個異步的操作。當用戶執行一個如上的Update操作獲得返回時,ClickHouse內核其實只做了兩件事情:
- 檢查Update操作是否合法;
- 保存Update命令到存儲文件中,喚醒一個異步處理merge和mutation的工作線程;
異步線程的工作流程極其復雜,總結其精髓描述如下:先查找到需要update的數據所在datapart,之后對整個datapart做掃描,更新需要變更的數據,然后再將數據重新落盤生成新的datapart,最后用新的datapart做替代并remove掉過期的datapart。
這就是ClickHouse對update指令的執行過程,可以看出,頻繁的update指令對于ClickHouse來說將是災難性的。(當然,我們可以通過設置,將這個異步的過程變成同步的過程,詳細請看:Synchronicity of ALTER Queries,然而同步阻塞就會比較嚴重)。
(2)Incremental Log
Incremental log的思想是什么了?比如對于用戶瀏覽統計表中的一條數據,如下所示:
┌──────────────UserID─┬─PageViews─┬─Duration─┬─Sign─┐
│ 4324182021466249494 │ 5 │ 146 │ 1 │
└─────────────────────┴───────────┴──────────┴──────┘現在有更新了:用戶又瀏覽了一個頁面,所以我們應該改變pageview從5到6,以及持續時間從146到185。那么按照Incremental log的思想,再插入兩行:
┌──────────────UserID─┬─PageViews─┬─Duration─┬─Sign─┐
│ 4324182021466249494 │ 5 │ 146 │ -1 │
│ 4324182021466249494 │ 6 │ 185 │ 1 │
└─────────────────────┴───────────┴──────────┴──────┘第一個是刪除行。它和我們已經得到的行是一樣的只是Sign被設為-1。第二個更新行,所有數據設置為新值。之后我們有三行數據:
┌──────────────UserID─┬─PageViews─┬─Duration─┬─Sign─┐
│ 4324182021466249494 │ 5 │ 146 │ 1 │
│ 4324182021466249494 │ 5 │ 146 │ -1 │
│ 4324182021466249494 │ 6 │ 185 │ 1 │
└─────────────────────┴───────────┴──────────┴──────┘那么對于count,sum,avg的計算方法如下:
-- number of sessions
count() -> sum(Sign)
-- total number of pages all users checked
sum(PageViews) -> sum(Sign * PageViews)
-- average session duration, how long user usually spent on the website
avg(Duration) -> sum(Sign * Duration) / sum(Sign)這就是Incremental log方法,這種方法的不足之處在于:
- 首先需要獲取到原數據,那么就需要先查一遍CK,或者將數據保存到其他存儲中便于檢索查詢,然后我們才可以針對原數據插入一條 ‘delete’ rows;
- Sign operations在某些計算場景并不適合,比如min、max、quantile等其他場景;
- 額外的寫入放大:當每個對象的平均更新次數為個位數時,更適合使用。
針對Incremental log方式的寫入方案存儲開銷問題,clickhouse提供了CollapsingMergeTree,使用CollapsingMergeTree,“刪除”行和舊的“刪除”行將在合并過程中折疊。但是,注意這個引擎,只是解決了寫放大問題,并不是說查詢模式就不是Incremental Log這種,我們還是需要通過對sign的特殊計算方式,達到效果。
(3)Insert+xxxMergeTree
用Insert加特定引擎,也可以實現更新效果。該方法適用于xxxMergeTree,如ReplacingMergeTree或AggregatingMergeTree。但是了,更新是異步的。因此剛插入的數據,并不能馬上看到最新的結果,因此并不是準實時的。
比如使用AggregatingMergeTree,用法如下:
CREATE TABLE IF NOT EXISTS whatever_table ON CLUSTER default (
user_id UInt64,
gender SimpleAggregateFunction(anyLast, Nullable(Enum('女' = 0, '男' = 1))),
...
)
ENGINE = AggregatingMergeTree() partition by toYYYYMMDD(reg_date) ORDER BY user_id;就以上建標語句展開分析,AggregatingMergeTree會將除主鍵(user)外的其余列,配合anyLast函數,替換每行數據為一種預聚合狀態。其中anyLast聚合函數聲明聚合策略為保留最后一次的更新數據。
實時性: 非準實時。
優點在于:
ClickHouse提供的這些mergeTree引擎,可以幫助我們達到最終一致性。
缺點在于:
xxxMergeTree并不能保證任何時候的查詢都是聚合過后的結果,并且也沒有提供標志位用于查詢數據的聚合狀態與進度。因此,為了確保數據在查詢前處于已聚合的狀態,還需手動下發optimize指令強制聚合過程的執行。
(4)Insert+xxxxMergeTree+Final
用xxxMergeTree是異步的,如何達到準實時的效果了?ClickHouse提供了FINAL關鍵字來解決這個問題。當指定FINAL后,ClickHouse會在返回結果之前完全合并數據,從而執行給定表引擎合并期間發生的所有數據轉換。
用法
首先Insert數據:
INSERT INTO test_a (*) VALUES (1, 'a', 1) ;查詢時,加入final關鍵字,如下所示:
SELECT COUNT()FROM test_a FINAL優缺點
對上述語句,explain后,查詢執行計劃如下所示:
Expression ((Projection + Before ORDER BY))
Aggregating
Expression (Before GROUP BY)
SettingQuotaAndLimits (Set limits and quota after reading from storage)
Expression (Remove unused columns after reading from storage)
MergingFinal (Merge rows for FINAL)
Expression (Calculate sorting key expression)
ReadFromStorage (MergeTree with final)從執行計劃可以看出代價比較高:
- 是一個串行過程;
- 會進行分區合并;
因此,這個FINAL,也不宜頻繁的使用。
總結
本文結合業務,尋求海量數據的解決方案。現有業務使用的是MySQL數據庫,且數據量暫時可控,因此目前采用分庫分表的策略。同時,也在為日益膨脹的數據做準備,擬采用ClickHouse,并使用Insert+ReplacingMergeTree及查詢中去重的方案解決其更新問題。最后,歡迎有經驗的伙伴多多指點!





















