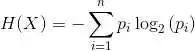譯者 | 朱先忠
審校 | 重樓
簡介
決策樹在機器學習中無處不在,因其直觀的輸出而備受喜愛。誰不喜歡簡單的“if-then”流程圖?盡管它們很受歡迎,但令人驚訝的是,要找到一個清晰、循序漸進的解釋來分析決策樹是如何工作的,還是一項具有相當挑戰(zhàn)性的任務。(實際上,我也很尷尬,我也不知道花了多長時間才真正理解決策樹算法的工作原理。)
所以,在本文中,我將重點介紹決策樹構建的要點。我們將按照從根到最后一個葉子節(jié)點(當然還有可視化效果)的順序來準確解析每個節(jié)點中發(fā)生的事情及其原因。
【注意】本文中所有圖片均由作者本人使用Canva Pro創(chuàng)建。
決策樹分類器定義
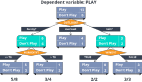
決策樹分類器通過創(chuàng)建一棵倒置的樹來進行預測。具體地講,這種算法從樹的頂部開始,提出一個關于數(shù)據(jù)中重要特征的問題,然后根據(jù)答案進行分支生成。當你沿著這些分支往下走時,每一個節(jié)點都會提出另一個問題,從而縮小可能性。這個問答游戲一直持續(xù)到你到達樹的底部——一個葉子節(jié)點——在那里你將得到最終的預測或分類結果。

決策樹是最重要的機器學習算法之一——它反映了一系列是或否的問題
示例數(shù)據(jù)集
在本文中,我們將使用人工高爾夫數(shù)據(jù)集(受【參考文獻1】啟發(fā))作為示例數(shù)據(jù)集。該數(shù)據(jù)集能夠根據(jù)天氣狀況預測一個人是否會去打高爾夫。
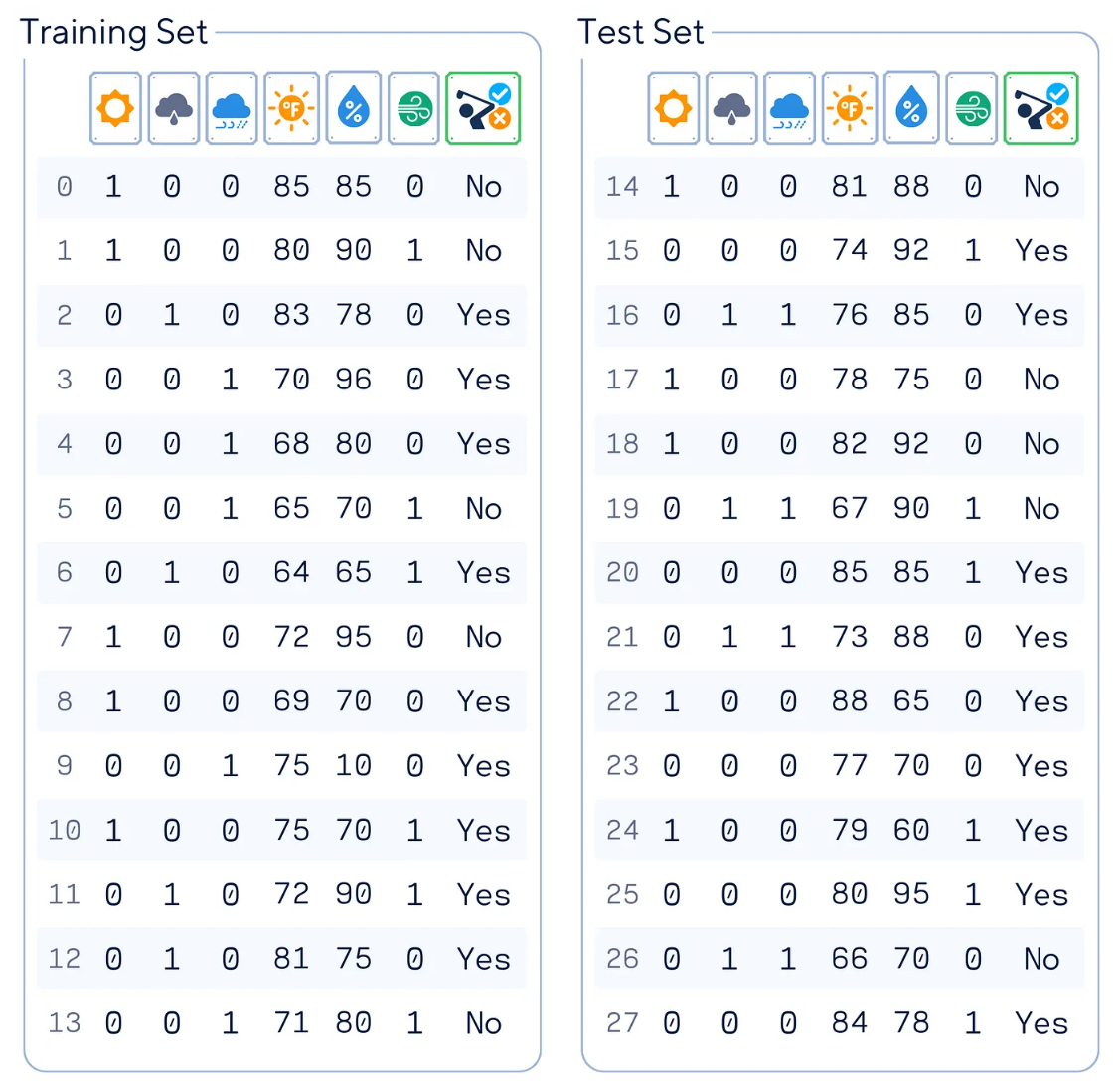
上圖表格中,主要的數(shù)據(jù)列含義分別是:
- “Outlook(天氣狀況)”:編碼為“晴天(sunny)”、“陰天(overcast)”或者“雨天(rainy)”
- “Temperature(溫度)”:對應華氏溫度
- “Humidity(濕度)”:用百分數(shù)%表示
- “Wind(風)”:是/否有風
- “Play(是否去打高爾夫)”:目標特征
#導入庫
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
import numpy as np
#加載數(shù)據(jù)
dataset_dict = {
'Outlook': ['sunny', 'sunny', 'overcast', 'rainy', 'rainy', 'rainy', 'overcast', 'sunny', 'sunny', 'rainy', 'sunny', 'overcast', 'overcast', 'rainy', 'sunny', 'overcast', 'rainy', 'sunny', 'sunny', 'rainy', 'overcast', 'rainy', 'sunny', 'overcast', 'sunny', 'overcast', 'rainy', 'overcast'],
'Temperature': [85.0, 80.0, 83.0, 70.0, 68.0, 65.0, 64.0, 72.0, 69.0, 75.0, 75.0, 72.0, 81.0, 71.0, 81.0, 74.0, 76.0, 78.0, 82.0, 67.0, 85.0, 73.0, 88.0, 77.0, 79.0, 80.0, 66.0, 84.0],
'Humidity': [85.0, 90.0, 78.0, 96.0, 80.0, 70.0, 65.0, 95.0, 70.0, 80.0, 70.0, 90.0, 75.0, 80.0, 88.0, 92.0, 85.0, 75.0, 92.0, 90.0, 85.0, 88.0, 65.0, 70.0, 60.0, 95.0, 70.0, 78.0],
'Wind': [False, True, False, False, False, True, True, False, False, False, True, True, False, True, True, False, False, True, False, True, True, False, True, False, False, True, False, False],
'Play': ['No', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No', 'No', 'Yes', 'Yes', 'No', 'No', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No', 'Yes']
}
df = pd.DataFrame(dataset_dict)
#預處理數(shù)據(jù)集
df = pd.get_dummies(df, columns=['Outlook'], prefix='', prefix_sep='', dtype=int)
df['Wind'] = df['Wind'].astype(int)
df['Play'] = (df['Play'] == 'Yes').astype(int)
#重新排列各數(shù)據(jù)列
df = df[['sunny', 'overcast', 'rainy', 'Temperature', 'Humidity', 'Wind', 'Play']]
# 是否出玩和目標確定
X, y = df.drop(columns='Play'), df['Play']
# 分割數(shù)據(jù)
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.5, shuffle=False)
# 顯示結果
print(pd.concat([X_train, y_train], axis=1), '\n')
print(pd.concat([X_test, y_test], axis=1))主要原理
決策樹分類器基于信息量最大的特征遞歸分割數(shù)據(jù)來進行操作。其工作原理如下:
- 從根節(jié)點處的整個數(shù)據(jù)集開始。
- 選擇最佳特征來分割數(shù)據(jù)(基于基尼不純度(Gini impurity)等指標)。
- 為選定特征的每個可能值創(chuàng)建子節(jié)點。
- 對每個子節(jié)點重復步驟2-3,直到滿足停止條件(例如,達到最大深度、每個葉子的最小樣本或純?nèi)~子節(jié)點)。
- 將主要的類型結果值分配給每個葉子節(jié)點。
訓練步驟
在scikit-learn開源庫中,決策樹算法被稱為CART(分類和回歸樹)。它可以用于構建一棵二叉樹,通常遵循以下步驟:
1. 從根節(jié)點中的所有訓練樣本開始。
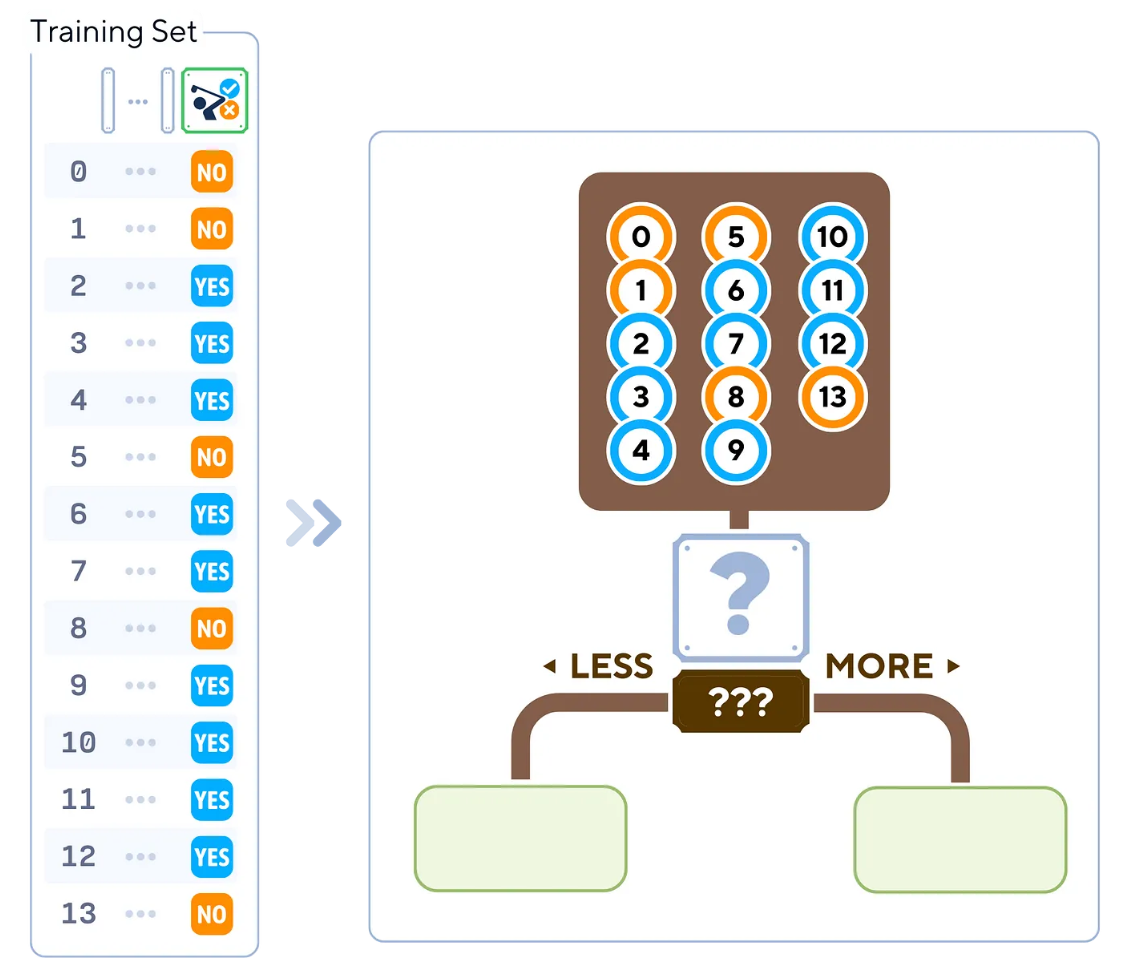
從包含所有14個訓練樣本的根節(jié)點開始,我們將找出最佳方式特征和分割數(shù)據(jù)的最佳點,以開始構建樹
2.對于每個特征,執(zhí)行如下操作:
a.對特征值進行排序。
b.將相鄰值之間的所有可能閾值視為潛在的分割點。
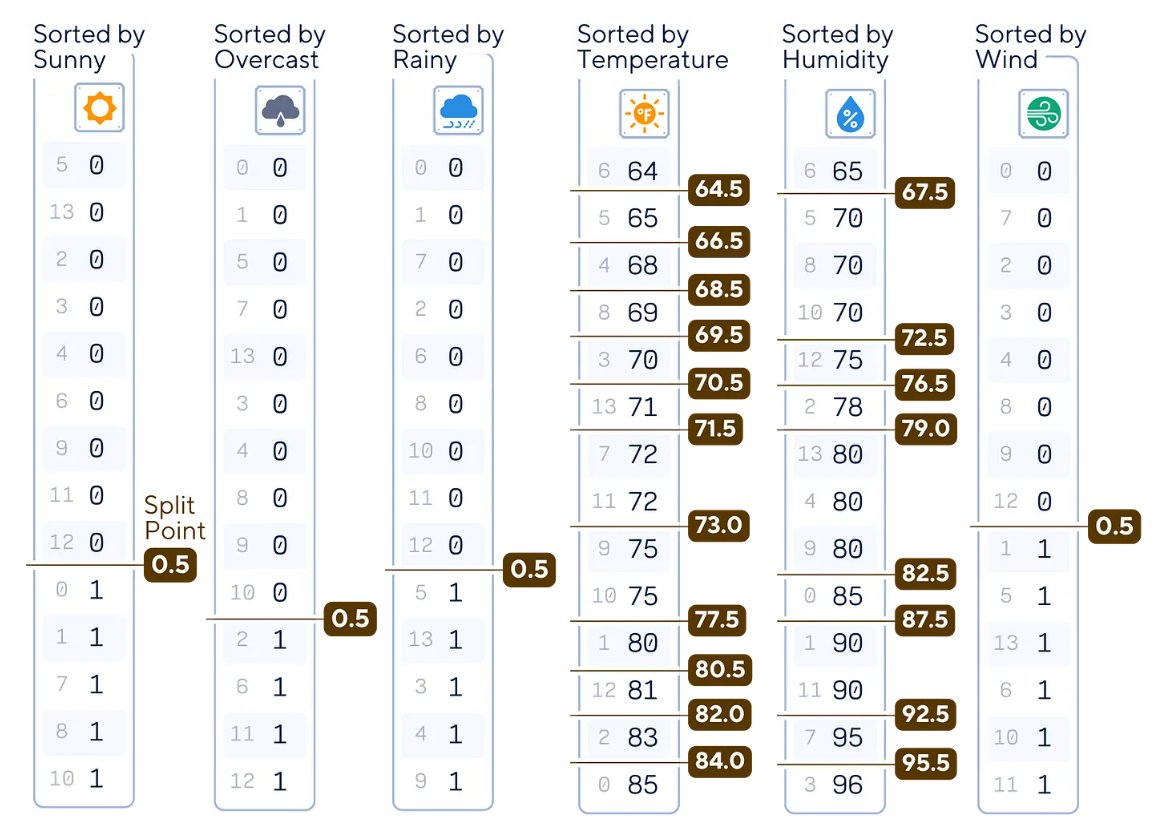
在這個根節(jié)點中,有23個分割點需要檢查。其中,二進制列只有一個分割點。
def potential_split_points(attr_name, attr_values):
sorted_attr = np.sort(attr_values)
unique_values = np.unique(sorted_attr)
split_points = [(unique_values[i] + unique_values[i+1]) / 2 for i in range(len(unique_values) - 1)]
return {attr_name: split_points}
# Calculate and display potential split points for all columns
for column in X_train.columns:
splits = potential_split_points(column, X_train[column])
for attr, points in splits.items():
print(f"{attr:11}: {points}")3.對于每個潛在的分割點,執(zhí)行如下操作:
a.計算當前節(jié)點的基尼不純度。
b.計算不純度的加權平均值。
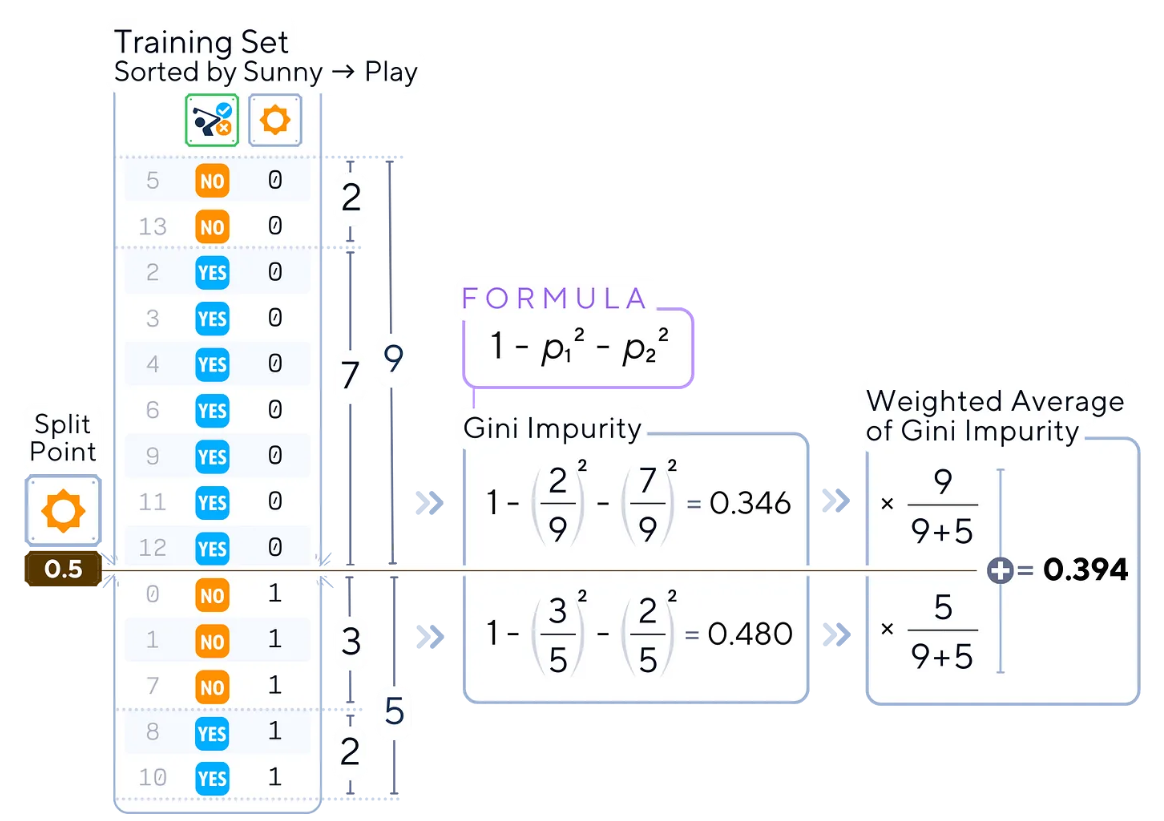
例如,對于分割點為0.5的特征“sunny(晴天)”,計算數(shù)據(jù)集兩部分的不純度(也就是基尼不純度)
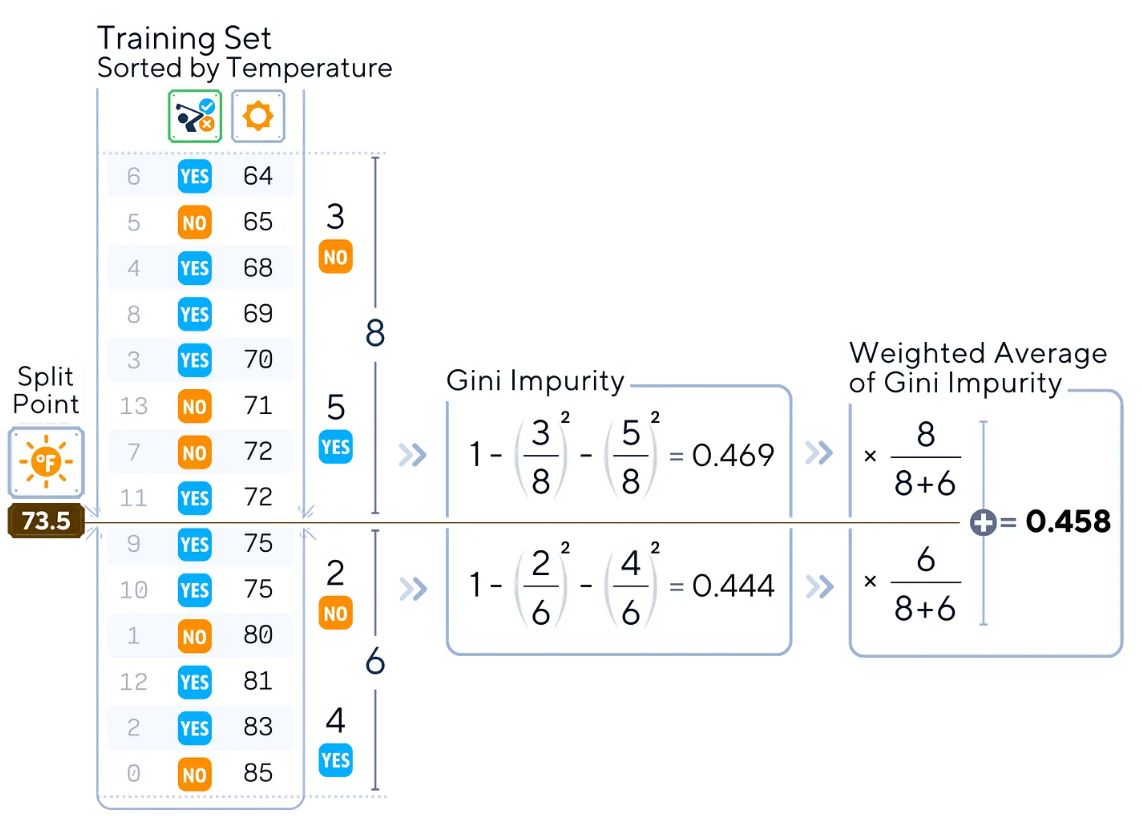
另一個例子是,同樣的過程也可以對“Temperature(溫度)”等連續(xù)特征進行處理。
def gini_impurity(y):
p = np.bincount(y) / len(y)
return 1 - np.sum(p**2)
def weighted_average_impurity(y, split_index):
n = len(y)
left_impurity = gini_impurity(y[:split_index])
right_impurity = gini_impurity(y[split_index:])
return (split_index * left_impurity + (n - split_index) * right_impurity) / n
# 排序“sunny”特征和相應的標簽
sunny = X_train['sunny']
sorted_indices = np.argsort(sunny)
sorted_sunny = sunny.iloc[sorted_indices]
sorted_labels = y_train.iloc[sorted_indices]
#查找0.5的分割索引
split_index = np.searchsorted(sorted_sunny, 0.5, side='right')
#計算不純度
impurity = weighted_average_impurity(sorted_labels, split_index)
print(f"Weighted average impurity for 'sunny' at split point 0.5: {impurity:.3f}")4.計算完所有特征和分割點的所有不純度后,選擇最低的那一個。
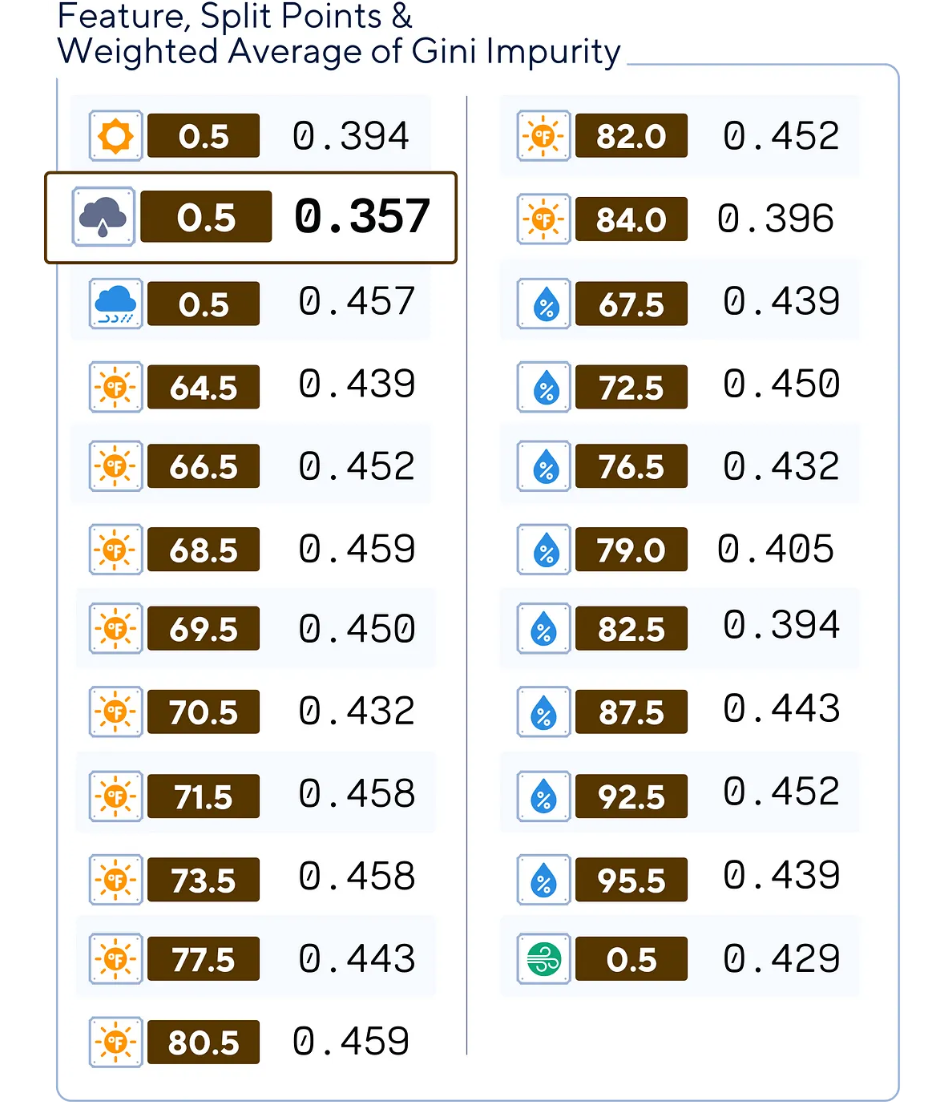
分割點為0.5的“overcast(陰天)”特征給出了最低的不純度。這意味著,該分割將是所有其他分割點中最純粹的一個!
def calculate_split_impurities(X, y):
split_data = []
for feature in X.columns:
sorted_indices = np.argsort(X[feature])
sorted_feature = X[feature].iloc[sorted_indices]
sorted_y = y.iloc[sorted_indices]
unique_values = sorted_feature.unique()
split_points = (unique_values[1:] + unique_values[:-1]) / 2
for split in split_points:
split_index = np.searchsorted(sorted_feature, split, side='right')
impurity = weighted_average_impurity(sorted_y, split_index)
split_data.append({
'feature': feature,
'split_point': split,
'weighted_avg_impurity': impurity
})
return pd.DataFrame(split_data)
# 計算所有特征的分割不純度
calculate_split_impurities(X_train, y_train).round(3)5.根據(jù)所選特征和分割點創(chuàng)建兩個子節(jié)點:
- 左子對象:特征值<=分割點的樣本
- 右側子對象:具有特征值>分割點的樣本
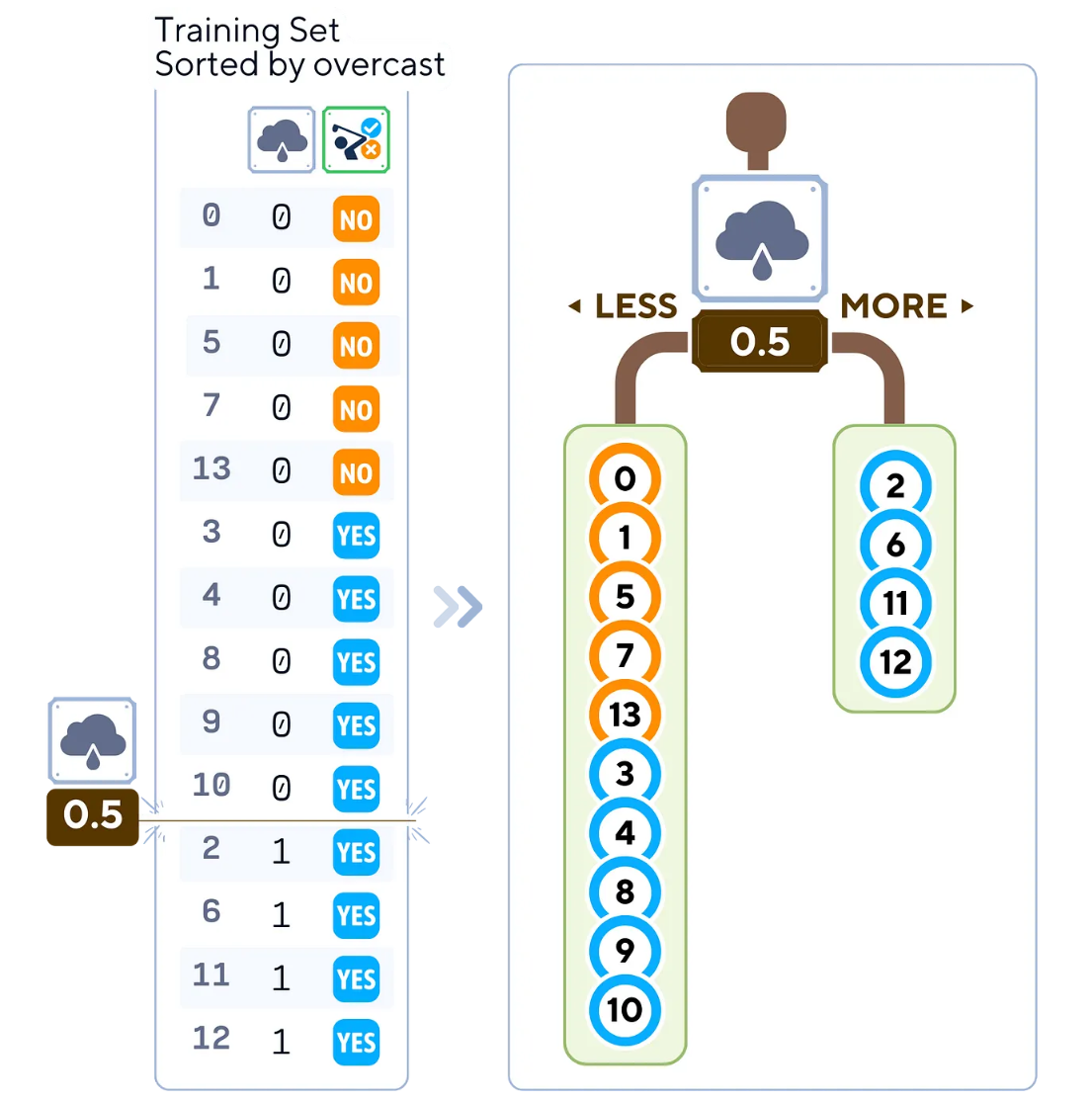
選定的分割點將數(shù)據(jù)分割成兩部分。由于一部分已經(jīng)是純的(右側!這就是為什么它的不純度很低!),我們只需要在左側節(jié)點上繼續(xù)迭代樹。
6.對每個子節(jié)點遞歸重復上述步驟2-5。您還可以停止,直到滿足停止條件(例如,達到最大深度、每個葉節(jié)點的最小樣本數(shù)或最小不純度減少)。
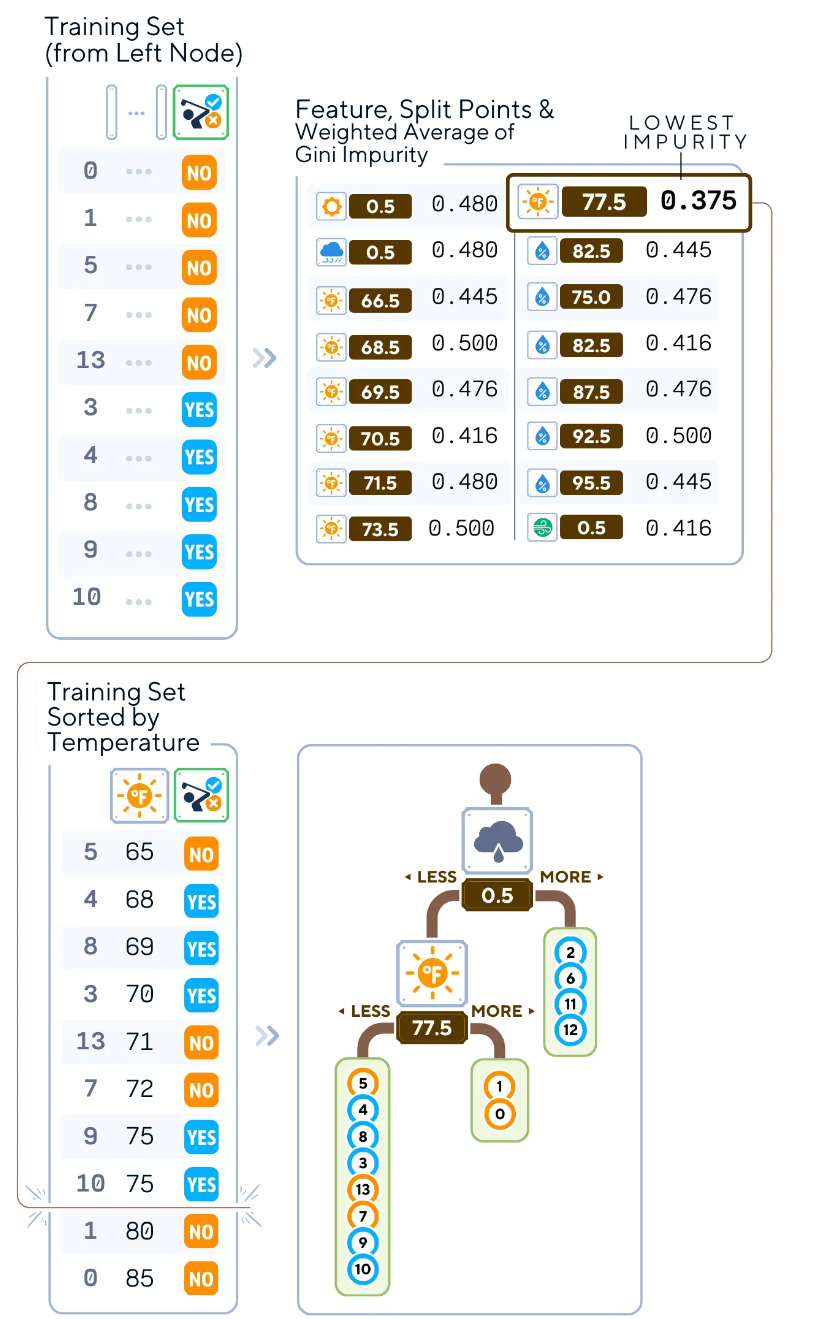
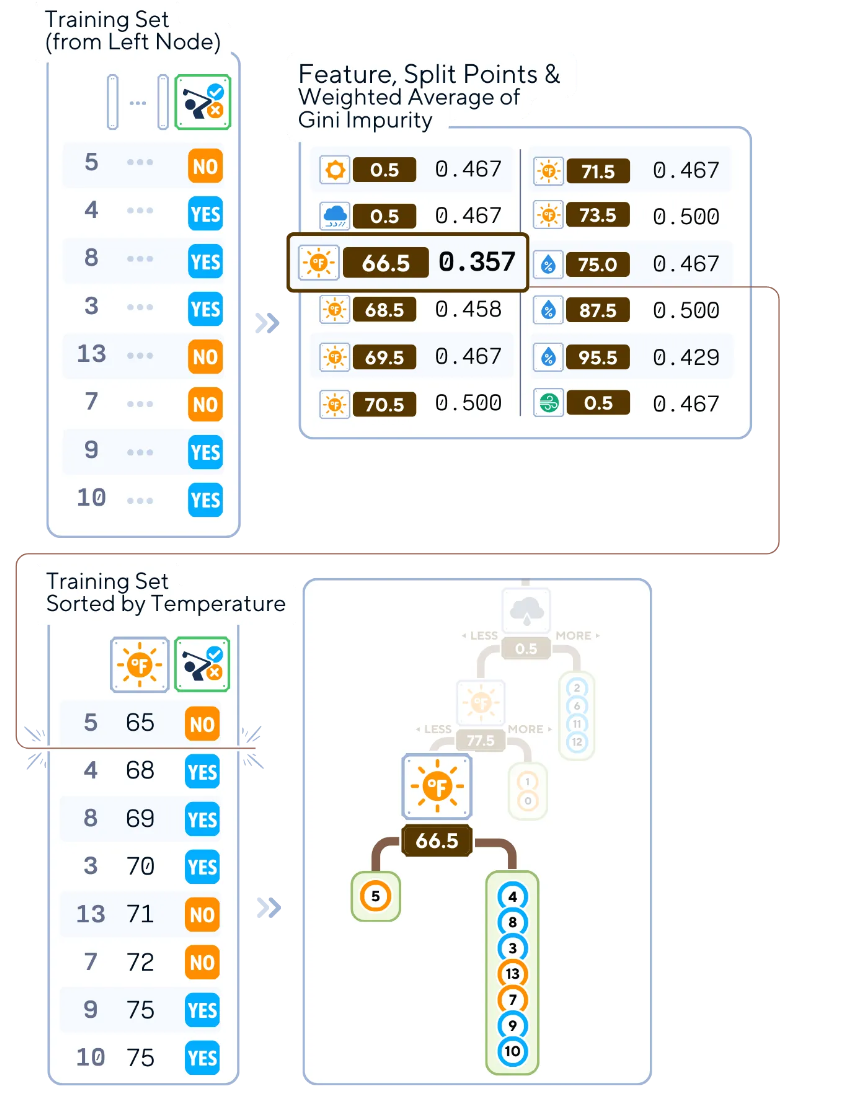
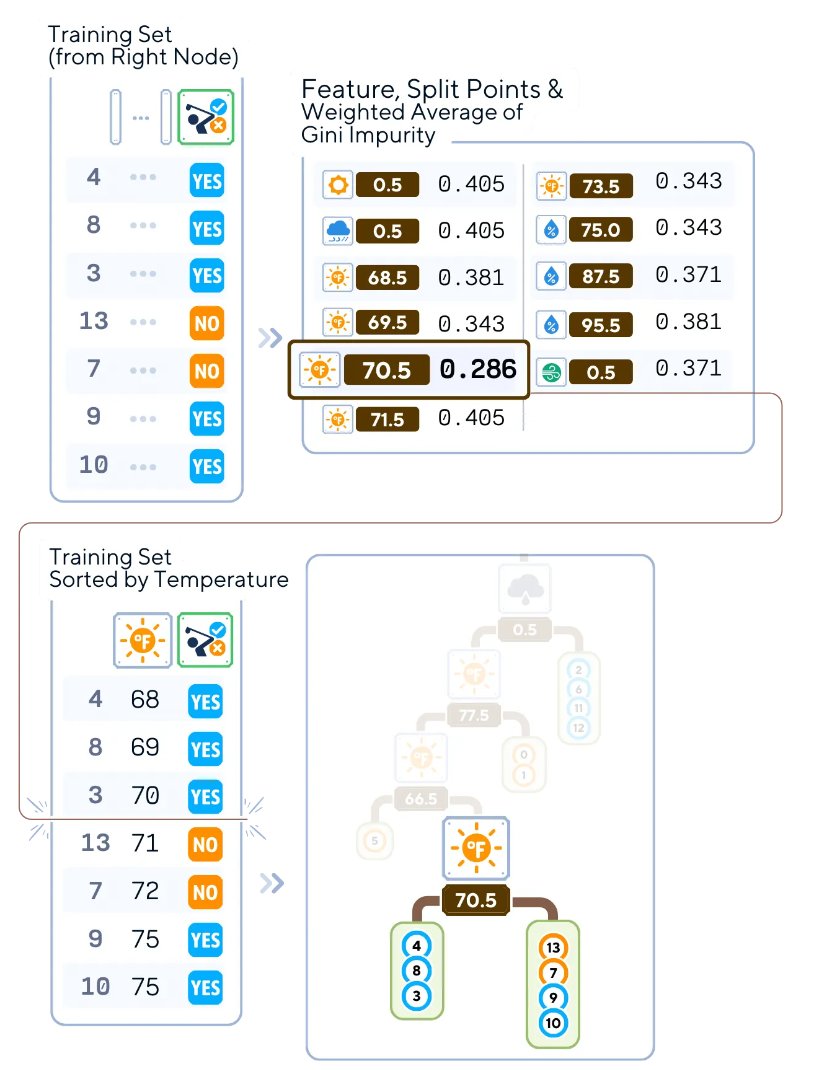

#計算選定指標中的分割不純度
selected_index = [4,8,3,13,7,9,10] # 根據(jù)您要檢查的索引來更改它
calculate_split_impurities(X_train.iloc[selected_index], y_train.iloc[selected_index]).round(3)
from sklearn.tree import DecisionTreeClassifier
#上面的整個訓練階段都是像這樣在sklearn中完成的
dt_clf = DecisionTreeClassifier()
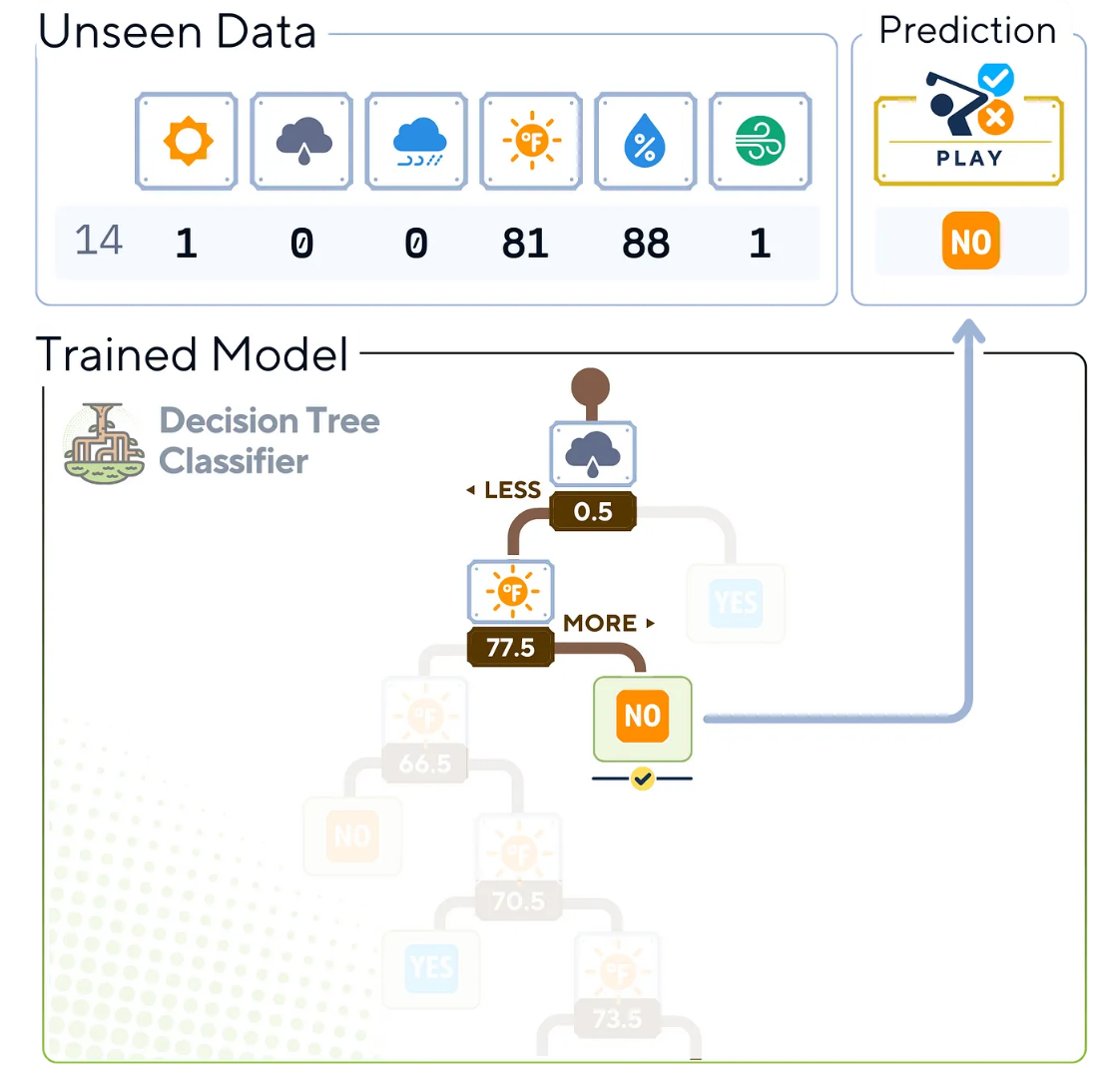
dt_clf.fit(X_train, y_train)算法結束時的輸出樹形式
葉子節(jié)點的類型標簽對應于到達該節(jié)點的訓練樣本的多數(shù)類型。
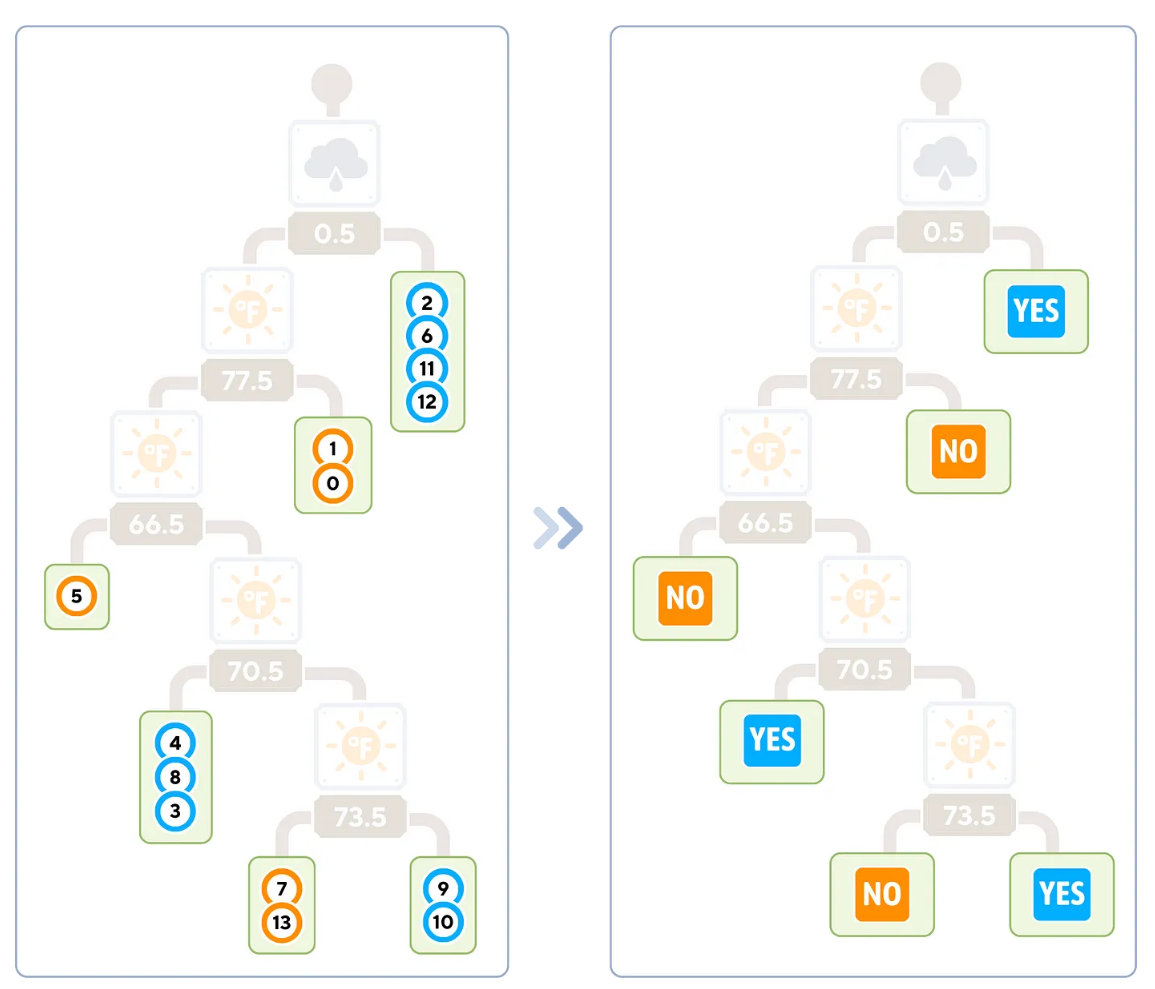
上圖中右側的樹表示用于分類的最后那棵樹。此時,我們不再需要訓練樣本了。
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
#打印決策樹
plt.figure(figsize=(20, 10))
plot_tree(dt_clf, filled=True, feature_names=X.columns, class_names=['Not Play', 'Play'])
plt.show()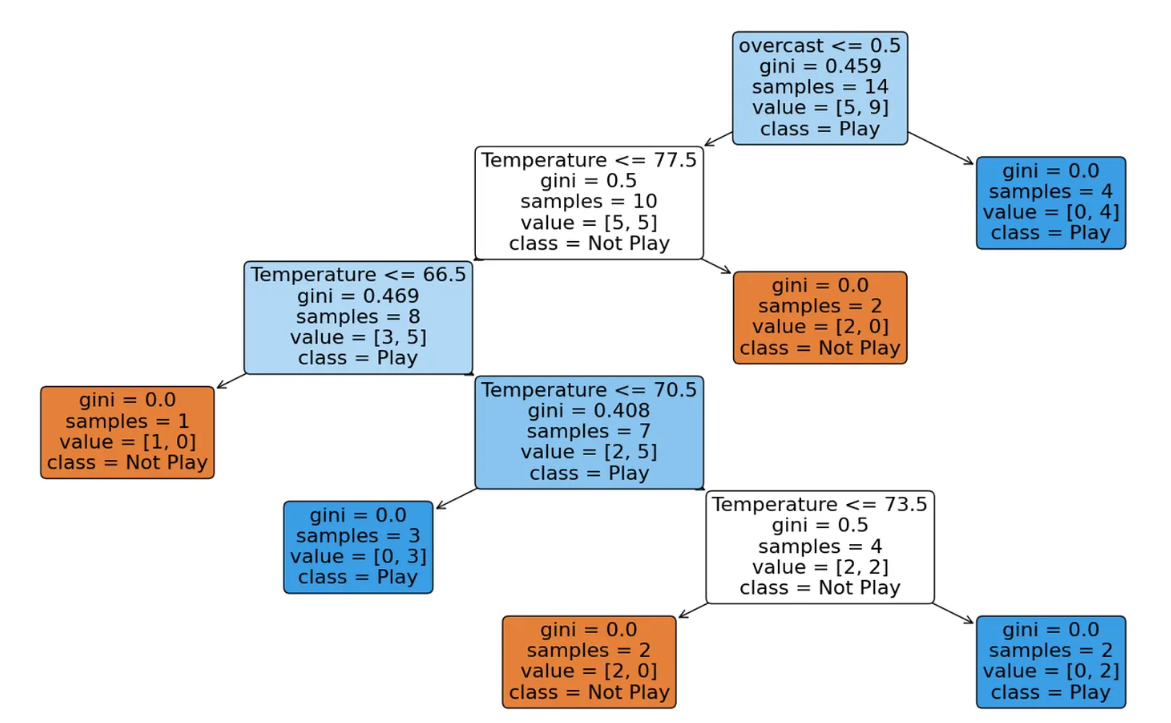
在這個scikit-learn輸出中,還存儲了非葉子節(jié)點的信息,如樣本數(shù)量和節(jié)點中每個類型的數(shù)量(值)
分類步驟
接下來,我們來了解訓練決策樹生成后,預測過程的工作原理,共分4步:
- 從訓練好的決策樹的根節(jié)點開始。
- 評估當前節(jié)點的特征和分割條件。
- 在每個后續(xù)節(jié)點上重復步驟2,直到到達葉子節(jié)點。
- 葉子節(jié)點的類型標簽成為新實例的預測結果。
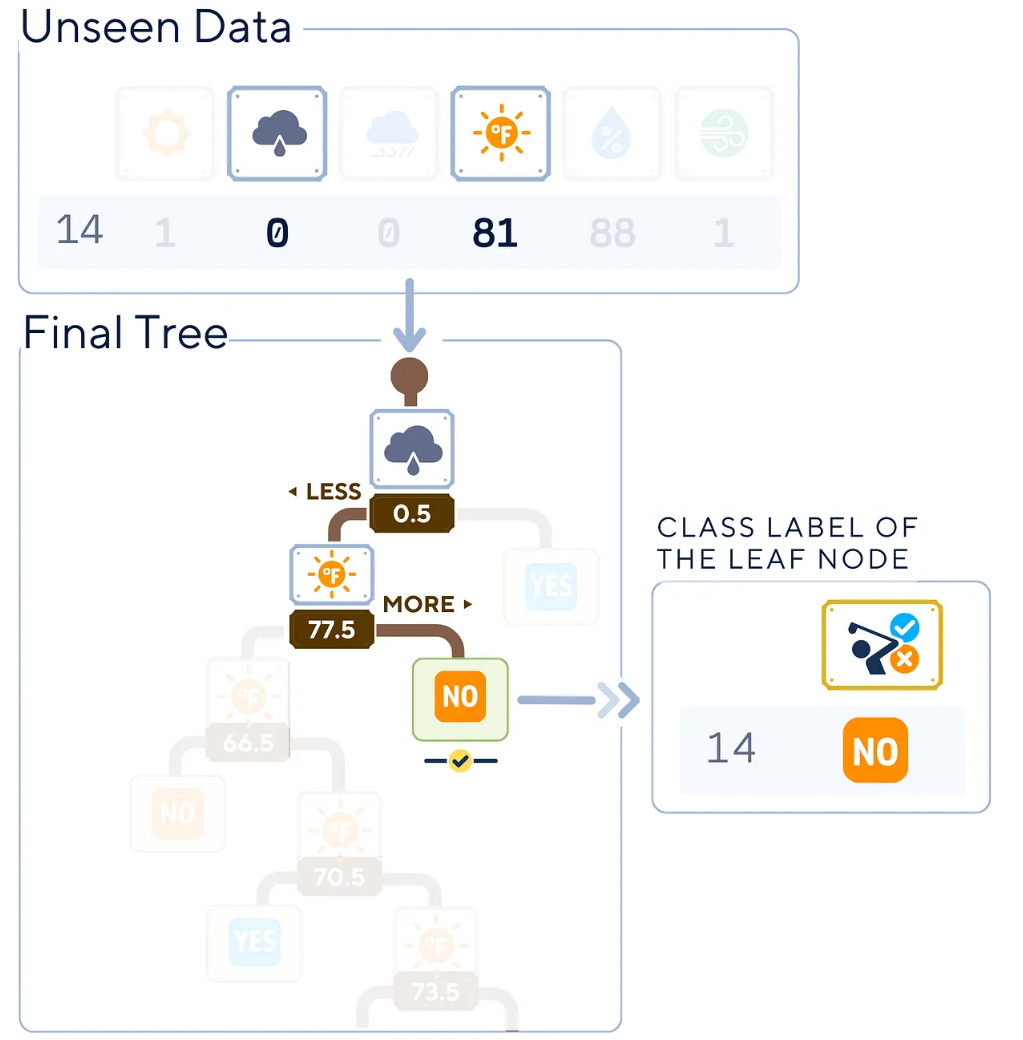
算法中,我們只需要樹運算中所使用的列指標。除了“overcast(陰天)”和“Temperature(溫度)”這兩個之外,其他值在預測中并不重要
# 開始預測
y_pred = dt_clf.predict(X_test)
print(y_pred)評估步驟

決策樹描述了足夠的準確性信息。由于我們的樹只檢查兩個特征,因此這棵樹可能無法很好地捕獲測試集特征。
# 評估分類器
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")關鍵參數(shù)分析
上面決策樹算法中,使用了好幾個控制其增長和復雜性的重要參數(shù):
- 最大深度(Max Depth):這個參數(shù)用于設置樹的最大深度,這個參數(shù)可以成為防止訓練過擬合的一個很有價值的工具。
友好提示:讀者不妨考慮從一棵淺樹(可能3-5層深)開始,然后逐漸增加深度。
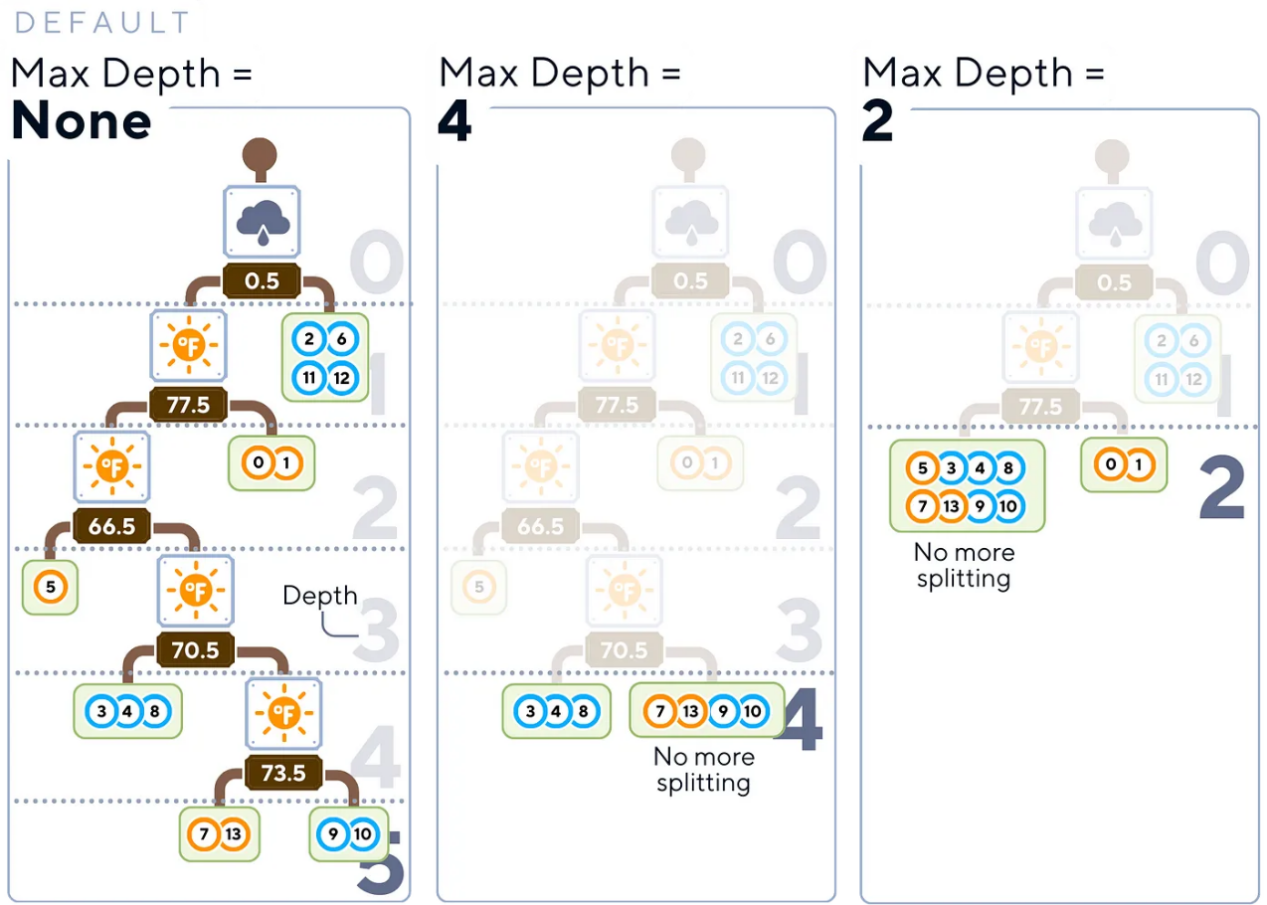
從一棵淺樹開始(例如,深度為3-5),逐漸增加,直到找到模型復雜性和驗證數(shù)據(jù)性能之間的最佳平衡。
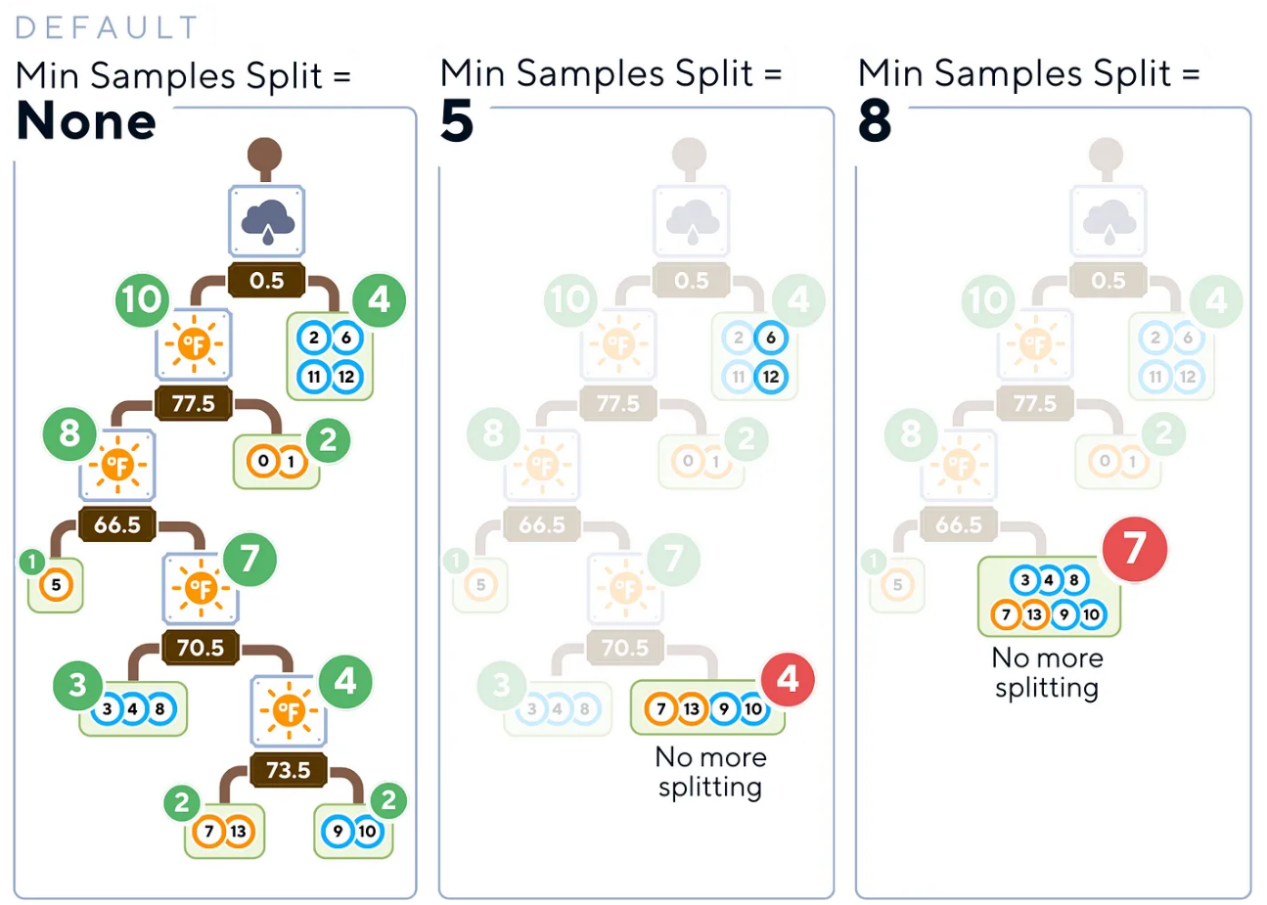
- 最小樣本分割(Min Samples Split):此參數(shù)確定分割內(nèi)部節(jié)點所需的最小樣本數(shù)。
友好提示:讀者不妨將其設置為更高一些的值(約占訓練數(shù)據(jù)的5-10%),這可以幫助防止樹創(chuàng)建太多小而特定的分割,從而可能導致無法很好地推廣到新數(shù)據(jù)。
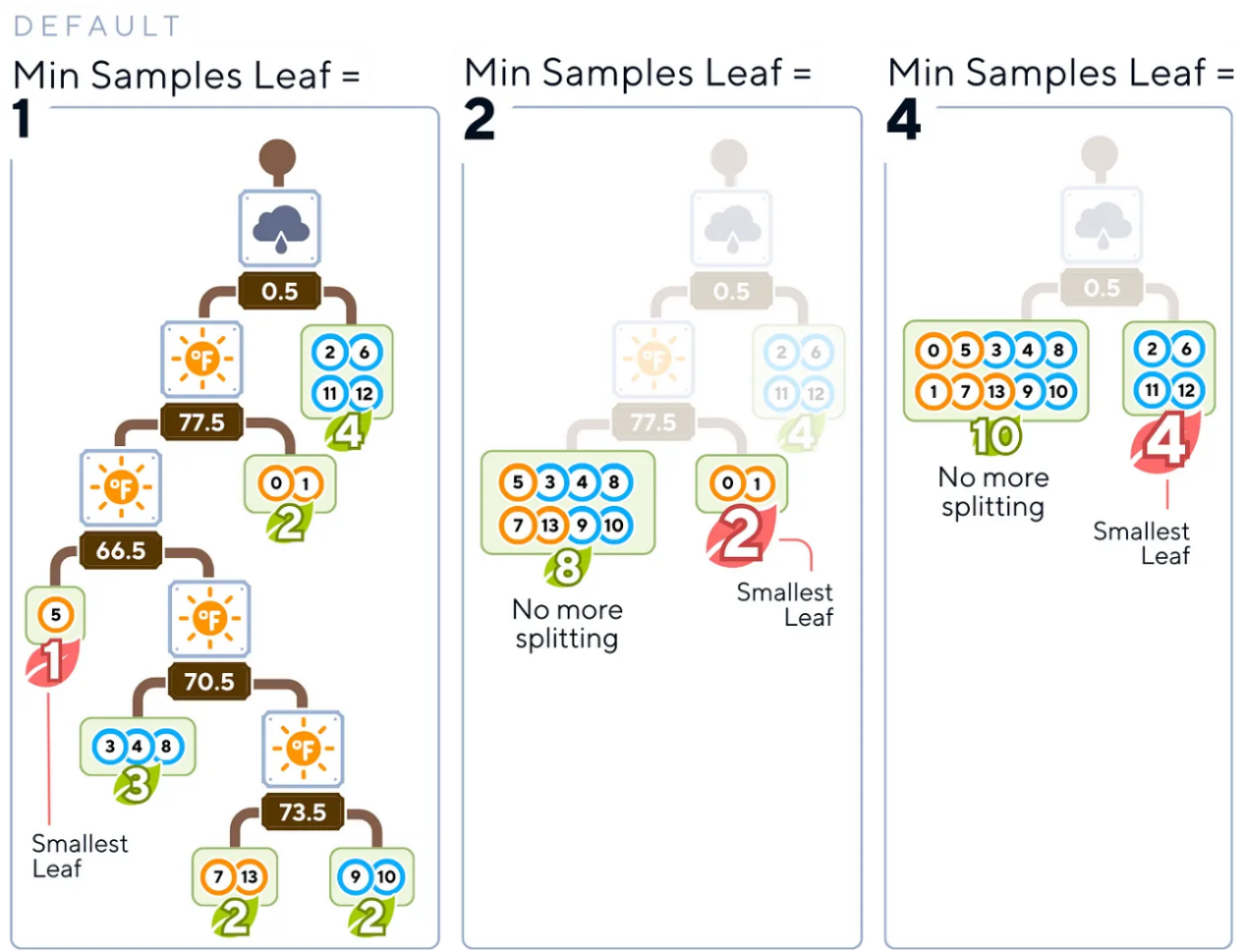
- 最小樣本葉節(jié)點(Min Samples Leaf):這個參數(shù)指定葉子節(jié)點所需的最小樣本數(shù)。
友好提示:選擇一個值,確保每個葉子代表數(shù)據(jù)的一個有意義的子集(大約占訓練數(shù)據(jù)的1-5%)。這種方法有助于避免過于具體的預測。
- 標準(Criterion):這是一個函數(shù)參數(shù)指標,用于衡量一次分割的質(zhì)量(通常為代表基尼不純度的“gini(基尼)”或信息增益的“entropy(熵)”)。
友好提示:雖然基尼不純度的計算通常更簡單、更快,但熵在多類型算法問題方面往往表現(xiàn)得更好。也就是說,這兩種技術經(jīng)常給出類似的運算結果。
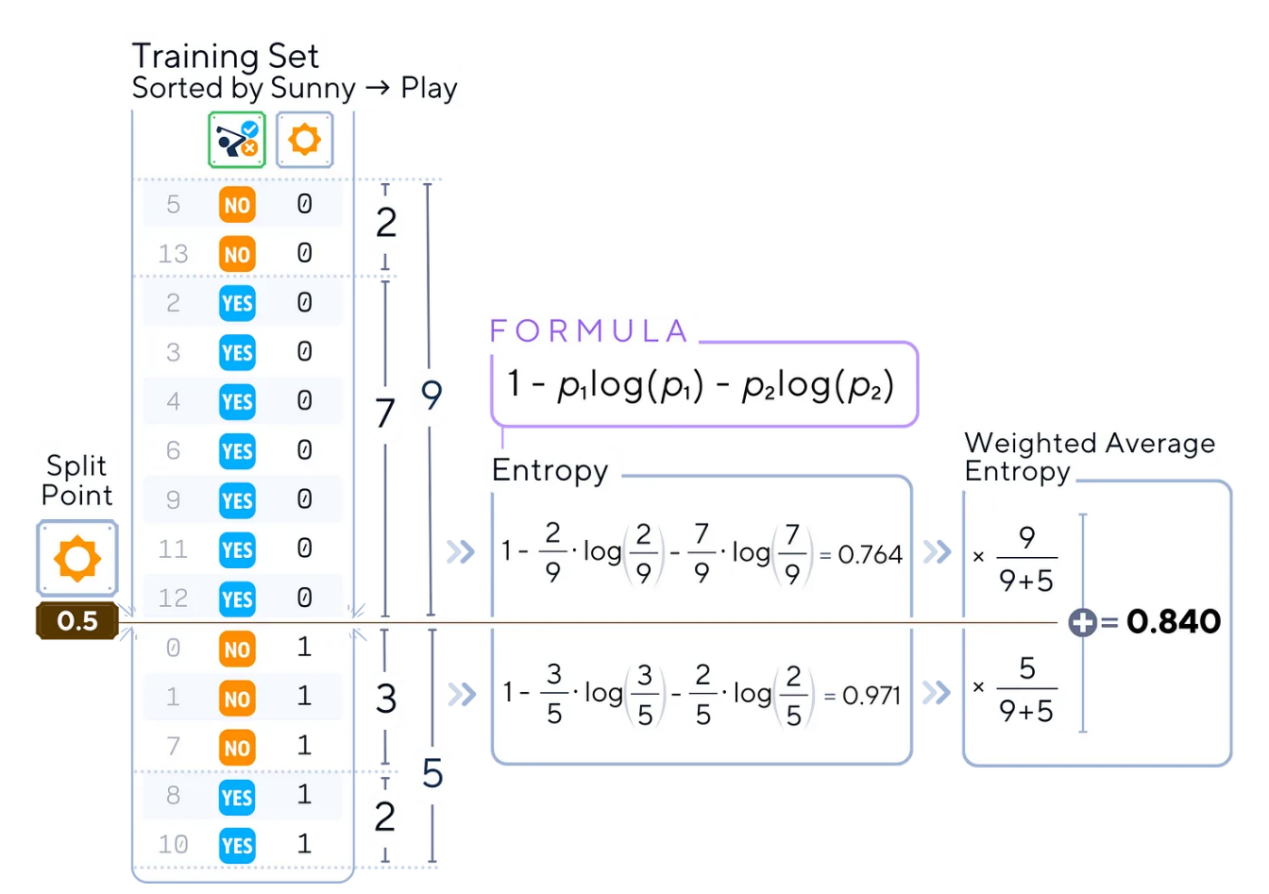
分割點為0.5的“sunny(晴天)”的熵計算示例
算法優(yōu)、缺點分析
與機器學習中的任何算法一樣,決策樹也有其優(yōu)勢和局限性。
優(yōu)點:
- 可解釋性:易于理解,決策過程能夠可視化。
- 無特征縮放:可以在不進行規(guī)范化的情況下處理數(shù)值和分類數(shù)據(jù)。
- 處理非線性關系:可以捕獲數(shù)據(jù)中的復雜模式。
- 特征重要性:能夠明確指出哪些特征對預測最重要。
缺點:
- 過擬合:容易創(chuàng)建過于復雜的樹,這些樹往往不能很好地泛化,尤其是在小數(shù)據(jù)集的情況下。
- 不穩(wěn)定性:數(shù)據(jù)中的微小變化可能會導致生成完全不同的樹。
- 帶有不平衡數(shù)據(jù)集的偏見:可能偏向于主導類型。
- 無法推斷:無法在訓練數(shù)據(jù)范圍之外進行預測。
在我們本文提供的高爾夫示例中,決策樹可能會根據(jù)天氣條件創(chuàng)建非常準確和可解釋的規(guī)則,以決定是否打高爾夫。然而,如果沒有正確修剪或數(shù)據(jù)集很小的話,它可能會過度擬合特定的條件組合。
結論
無論如何,決策樹分類器還是解決機器學習中許多類型問題的好工具。它們易于理解,可以處理復雜的數(shù)據(jù),并向我們展示它們是如何做出決策的。這使得它們廣泛應用于從商業(yè)到醫(yī)學的許多領域。雖然決策樹功能強大且可解釋,但它們通常被用作更高級集成方法的構建塊,如隨機森林或梯度增強機等算法中。
簡化型決策樹分類器算法
下面給出本文示例工程對應的一棵簡化型決策樹的分類器算法的完整代碼。
#導入庫
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from sklearn.tree import plot_tree, DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加載數(shù)據(jù)
dataset_dict = {
'Outlook': ['sunny', 'sunny', 'overcast', 'rainy', 'rainy', 'rainy', 'overcast', 'sunny', 'sunny', 'rainy', 'sunny', 'overcast', 'overcast', 'rainy', 'sunny', 'overcast', 'rainy', 'sunny', 'sunny', 'rainy', 'overcast', 'rainy', 'sunny', 'overcast', 'sunny', 'overcast', 'rainy', 'overcast'],
'Temperature': [85.0, 80.0, 83.0, 70.0, 68.0, 65.0, 64.0, 72.0, 69.0, 75.0, 75.0, 72.0, 81.0, 71.0, 81.0, 74.0, 76.0, 78.0, 82.0, 67.0, 85.0, 73.0, 88.0, 77.0, 79.0, 80.0, 66.0, 84.0],
'Humidity': [85.0, 90.0, 78.0, 96.0, 80.0, 70.0, 65.0, 95.0, 70.0, 80.0, 70.0, 90.0, 75.0, 80.0, 88.0, 92.0, 85.0, 75.0, 92.0, 90.0, 85.0, 88.0, 65.0, 70.0, 60.0, 95.0, 70.0, 78.0],
'Wind': [False, True, False, False, False, True, True, False, False, False, True, True, False, True, True, False, False, True, False, True, True, False, True, False, False, True, False, False],
'Play': ['No', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No', 'No', 'Yes', 'Yes', 'No', 'No', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No', 'Yes']
}
df = pd.DataFrame(dataset_dict)
#準備數(shù)據(jù)
df = pd.get_dummies(df, columns=['Outlook'], prefix='', prefix_sep='', dtype=int)
df['Wind'] = df['Wind'].astype(int)
df['Play'] = (df['Play'] == 'Yes').astype(int)
# 分割數(shù)據(jù)
X, y = df.drop(columns='Play'), df['Play']
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.5, shuffle=False)
# 訓練模型
dt_clf = DecisionTreeClassifier(
max_depth=None, # 樹的最大深度
min_samples_split=2, # 分割內(nèi)部節(jié)點所需的最小樣本數(shù)
min_samples_leaf=1, # 在一個葉節(jié)點上所需的最小樣本數(shù)
criterion='gini' # 測試分割質(zhì)量的函數(shù)
)
dt_clf.fit(X_train, y_train)
# 開始預測
y_pred = dt_clf.predict(X_test)
#評估模型
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
#繪制樹
plt.figure(figsize=(20, 10))
plot_tree(dt_clf, filled=True, feature_names=X.columns,
class_names=['Not Play', 'Play'], impurity=False)
plt.show()相關閱讀
有關決策樹分類器及其在scikit-learn中的實現(xiàn)的詳細說明,讀者可以參考官方文檔(參考2),其中提供了有關其使用和參數(shù)的更為全面的信息。
技術環(huán)境
本文示例項目使用了Python 3.7和scikit-learn 1.5開源庫。雖然所討論的概念普遍適用,但具體的代碼實現(xiàn)可能因版本不同而略有不同。
關于插圖
除非另有說明;否則,文中所有圖片均由作者創(chuàng)建,并包含經(jīng)Canva Pro許可的設計元素。
參考資料
- T. M. Mitchell,Machine Learning(機器學習) (1997),McGraw-Hill Science/Engineering/Math,第59頁。
- F. Pedregosa等人,《Scikit-learn: Machine Learning in Python》,Journal of Machine Learning Research(機器學習研究雜志) 2011年,第12卷,第2825-2830頁。在線可訪問地址:https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html。
譯者介紹
朱先忠,51CTO社區(qū)編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:Decision Tree Classifier, Explained: A Visual Guide with Code Examples for Beginners,作者:Samy Baladram