多代理強化學習綜述:原理、算法與挑戰
1. 引言
多代理強化學習(Multi-Agent Reinforcement Learning, MARL)是強化學習的一個重要分支,它將傳統的單代理強化學習概念擴展到多代理環境中。在MARL中,多個代理通過與環境和其他代理的交互來學習最優策略,以在協作或競爭場景中最大化累積獎勵。
") MAgent中代理之間的對抗(混合MARL示例)
MAgent中代理之間的對抗(混合MARL示例)
MARL的正式定義如下:多代理強化學習是強化學習的一個子領域,專注于研究在共享環境中共存的多個學習代理的行為。每個代理都受其個體獎勵驅動,采取行動以推進自身利益;在某些環境中,這些利益可能與其他代理的利益相沖突,從而產生復雜的群體動態。
2. 單代理強化學習回顧
在深入MARL之前,有必要回顧單代理強化學習的基本概念。
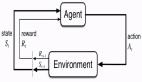
 經典馬爾可夫決策過程圖示
經典馬爾可夫決策過程圖示
2.1 核心概念
- 代理:代理是與環境交互的實體,基于觀察或狀態采取行動,目標是最大化累積獎勵。
- 狀態和環境:環境是代理操作的外部系統。它向代理提供狀態信息,接收代理的行動,并返回新的狀態和獎勵。狀態是代理可觀察到的環境當前情況的表示。
- 馬爾可夫決策過程(MDPs):強化學習問題通常被formulated formulated表述為馬爾可夫決策過程,用元組<S, A, P, R, γ>表示。其中S和A分別是狀態空間和行動空間,P(s' | s, a)是給定行動a時從狀態s轉移到s'的概率,R是獎勵函數,γ是折扣因子。
2.2 策略
代理的行為由其策略π指導:給定一個狀態,策略輸出一個行動或行動的概率分布。強化學習的目標是找到最優策略π*,以最大化長期累積獎勵。
3. 單代理MDP求解方法
解決MDP的核心目標是隨時間最大化累積獎勵。主要的強化學習方法可分為兩類:
3.1 基于價值的方法
 價值函數和學習方法概覽
價值函數和學習方法概覽
在基于價值的方法中,代理學習價值函數,以評估狀態或狀態-行動對的價值,并基于這些價值選擇行動。典型的基于價值的算法包括Q學習、SARSA和時序差分(TD)學習。
3.2 基于策略的方法
 策略梯度方法和更新規則概覽
策略梯度方法和更新規則概覽
基于策略的方法直接學習最優策略,將狀態映射到行動以最大化長期獎勵。常見的基于策略的算法包括策略梯度和演員-評論家方法。
4. 多代理強化學習的特點與挑戰
將單代理強化學習擴展到多代理環境中,需要重新考慮系統建模方法。多代理環境通常被建模為馬爾可夫博弈,其中多個代理同時交互,每個代理都影響狀態轉移和獎勵分配。
4.1 馬爾可夫博弈
馬爾可夫博弈由元組(N, S, A, P, R, γ)定義:
- N:代理數量
- S:狀態空間
- A = A? × A? × … × A?:聯合行動空間
- P:狀態轉移概率函數
- R = (R?, R?, …, R?):每個代理的獎勵函數集
- γ:折扣因子
4.2 MARL的類別
多代理強化學習可以根據代理之間的交互方式分為以下幾類:
- 合作型MARL:代理學習共同完成任務,最大化共享獎勵。適用于多機器人系統等場景。
- 競爭型MARL:代理在對抗性或零和博弈中最大化自身獎勵。例如棋類游戲或對抗性場景。
- 混合利益型MARL:代理既有合作也有競爭關系,目標部分一致,部分沖突。常見于貿易、交通和多人視頻游戲等復雜場景。
4.3 MARL面臨的主要挑戰
 MARL中的主要挑戰
MARL中的主要挑戰
4.3.1 非平穩性
在多代理環境中,每個代理面臨的環境是動態變化的,因為其他代理也在不斷學習和調整策略。這違反了馬爾可夫性質,使得傳統的強化學習方法難以直接應用。
- 影響:狀態轉移概率和獎勵函數不再是靜態的。
- 后果:代理的最優策略可能隨著其他代理行為的變化而改變,導致學習過程的不穩定性。
4.3.2 部分可觀察性
在大多數多代理場景中,單個代理無法獲得完整的環境狀態信息或其他代理的行動。
- 建模:問題轉化為部分可觀察馬爾可夫決策過程(POMDP)。
- 挑戰:代理需要在不完整信息的基礎上推斷隱藏狀態,增加了策略學習的復雜性。
4.3.3 可擴展性和聯合行動空間
隨著代理數量的增加,系統的復雜度呈指數級增長。
- 聯合行動空間:對于n個代理,聯合行動空間為A? × A? × … × A?。
- 計算挑戰:狀態-行動空間的急劇擴大導致計算復雜性顯著增加,傳統RL方法效率降低。
- 可擴展性需求:需要開發能夠處理大規模多代理系統的算法。
4.3.4 信用分配問題
在合作場景中,準確評估每個代理對團隊目標的貢獻變得尤為復雜。
- 挑戰:難以確定哪些代理的行動對實現共同目標起到了關鍵作用。
- 局限性:傳統方法往往無法提供清晰的個體貢獻洞察,影響獎勵分配的公平性和有效性。
這些挑戰共同構成了MARL研究的核心問題,推動了該領域算法和理論的不斷發展。在接下來的章節中,我們將探討應對這些挑戰的一些主要方法和算法。
5. MARL中的決策制定與學習范式
多代理強化學習(MARL)在現實世界的多個領域都有重要應用,尤其是在機器人領域。MARL算法旨在使每個代理學習如何在最大化自身獎勵的同時,維持其對全局獎勵最大化的貢獻。
5.1 MARL的主要學習范式
5.1.1 集中訓練與分散執行(CTDE)
CTDE是MARL中一種廣泛使用的范式,它在訓練和執行階段采用不同的信息訪問策略:
- 訓練階段:代理可以訪問全局信息。
- 執行階段:代理僅基于局部觀察進行決策。
這種方法平衡了學習效率和實際部署的需求。
5.1.2 完全分散學習
在這種范式下,代理在訓練和執行過程中都無法獲取其他代理的信息:
- 每個代理獨立更新自己的策略。
- 目標是最大化所有代理的獎勵總和。
這種方法面臨的主要挑戰是環境的非平穩性,因為從每個代理的角度來看,其他代理的行為變化會導致環境動態的變化。
5.2 核心算法
5.2.1 值分解網絡(VDN)
VDN是一種在CTDE框架下使用的方法,其核心思想是將全局Q值分解為各個代理的Q值之和。
 Q-tot作為各個代理Q值的總和
Q-tot作為各個代理Q值的總和
VDN的基本假設是聯合Q函數可以加性分解為個體代理Q函數:
Q_tot = ∑ Q_i
優點:
- 允許分散執行
- 每個代理可以獨立優化自身策略
局限性:
- 簡單的加和可能導致策略多樣性降低
- 容易陷入局部最優,特別是當Q網絡在代理間共享時
5.2.2 QMIX
QMIX是對VDN的改進,引入了一個混合網絡來組合個體代理值到聯合Q值。
 QMIX架構
QMIX架構
核心特點:
- 使用混合網絡表示個體代理值和聯合Q值之間的非線性關系
- 保持單調性約束,確保行動選擇的一致性
 Q-tot作為混合網絡輸出
Q-tot作為混合網絡輸出
QMIX遵循標準的Q學習范式,使用時序差分(TD)誤差更新全局Q值:
TD_error = r + γ * max_a' Q(s', a') - Q(s, a)5.2.3 獨立近端策略優化(IPPO)
IPPO是一種簡單而有效的MARL算法,其中每個代理在訓練和執行過程中都獨立運作。
關鍵特點:
- 每個代理擁有獨立的策略和評論家網絡
- 使用PPO算法進行策略更新
IPPO使用PPO的裁剪目標函數來防止過大的策略更新:
 IPPO中使用的PPO裁剪目標
IPPO中使用的PPO裁剪目標
優勢:
- 簡單,易于實現
- 良好的可擴展性
局限性:
- 可能難以實現全局最優,特別是在需要高度協調的任務中
5.2.4 多代理近端策略優化(MAPPO)
MAPPO是PPO算法在多代理場景中的擴展,采用CTDE方法。
核心思想:
- 使用中心化評論家來解決非平穩性問題
- 評論家可以訪問聯合狀態,學習更穩定的值函數
MAPPO的策略更新通過最大化以下PPO目標來執行:
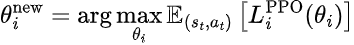
其中L_i_PPO是代理i的PPO目標。
中心化評論家通過最小化以下誤差來更新:
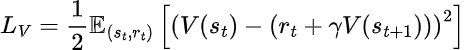
MAPPO通過結合中心化訓練和分散執行,在處理非平穩環境方面表現出色。
在下一部分中,我們將繼續探討更多高級MARL算法,以及多代理系統中的通信策略。
6. 高級MARL算法與通信策略
6.1 多代理深度確定性策略梯度(MADDPG)
MADDPG是深度確定性策略梯度(DDPG)算法在多代理環境中的擴展。它采用集中訓練分散執行(CTDE)的策略,引入了中心化的Q函數來處理所有代理的聯合行動。
 MADDPG算法流程
MADDPG算法流程
核心特點如下:
- 每個代理擁有自己的演員網絡(策略)和評論家網絡
- 評論家網絡在訓練時可訪問所有代理的觀察和行動
- 使用目標網絡來穩定學習過程
MADDPG的評論家網絡更新遵循標準的Q學習范式:
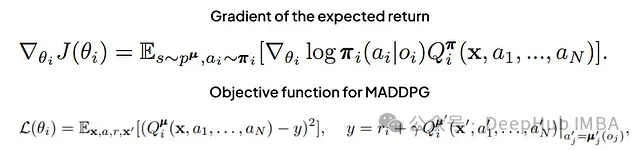
其中Q函數是中心化的動作-值函數,接受所有代理的行動作為輸入。
策略更新通過最大化預期Q值來實現:

MADDPG通過允許代理學習其他代理的策略,有效地處理了非平穩環境的挑戰。
6.2 MARL中的通信策略
在多代理系統中,有效的通信對于協調和決策至關重要。然而,通信也面臨諸如帶寬限制、不可靠信道等挑戰。
 代理間的三種不同通信策略
代理間的三種不同通信策略
6.2.1 可微分和強化的代理間學習(RIAL/DIAL)
RIAL和DIAL是探索代理間高效通信的重要方法:
- RIAL:結合DRQN和獨立Q學習,分別用于行動選擇和通信
- DIAL:引入可微分通信通道,支持端到端學習
6.2.2 SchedNet
SchedNet引入了學習型調度機制,代理學習決定哪些代理應該被允許廣播消息。
 SchedNet架構
SchedNet架構
主要組件:
- 調度機制
- 消息編碼
- 基于有限通信和局部觀察的行動選擇
6.2.3 TarMAC:目標多代理通信
TarMAC專注于提高代理間通信的效率和有效性。
 TarMAC架構
TarMAC架構
核心思想:
- 使用目標通信策略,允許代理選擇性地與特定同伴通信
- 采用基于簽名的軟注意力機制來實現消息定向
 使用簽名和值構建的消息
使用簽名和值構建的消息
 跨代理計算的注意力
跨代理計算的注意力
6.2.4 基于自編碼器的通信方法
這種方法旨在開發多代理系統中的通信語言,重點關注如何使用自編碼器在環境中建立語言基礎。
 基于自編碼器的通信架構
基于自編碼器的通信架構
主要組件:
- 圖像編碼器:將原始像素觀察嵌入到低維特征空間
- 通信自編碼器:學習從特征空間到通信符號的映射
- 接收器模塊:使用GRU策略處理編碼的圖像特征和消息特征
7. 結論和未來方向
多代理強化學習(MARL)通過引入多個代理在共享環境中交互的復雜性,極大地擴展了傳統強化學習的邊界。MARL在處理非平穩性、部分可觀察性、可擴展性和信用分配等方面的挑戰推動了該領域的快速發展。
未來研究方向
- 可擴展性:開發能夠有效處理大規模多代理系統的算法仍然是一個關鍵挑戰。
- 分散訓練分散執行(DTDE):探索完全分散的訓練和執行方法,以應對更復雜的實際場景。
- 通信策略:進一步研究高效、魯棒的代理間通信機制,特別是在有限帶寬和不可靠通道的情況下。
- 遷移學習:研究如何將學到的策略從一個多代理環境遷移到另一個環境。
- 模型化MARL:結合模型學習與MARL,提高樣本效率和泛化能力。
- 公平性和倫理:探討MARL系統中的公平性問題,以及如何在多代理決策中納入道德和倫理考慮。
隨著研究的深入和技術的進步,MARL有望在更多復雜的實際問題中發揮關鍵作用,推動人工智能在多代理系統中的應用不斷向前發展。