用雪花 id 和 uuid 做 MySQL 主鍵,被領導懟了
兄弟們,上周三下午,我正對著電腦美滋滋地敲代碼,突然背后傳來一聲 “你這主鍵用的啥?”—— 回頭一看,領導正皺著眉盯著我屏幕上的 MySQL 表結構。我挺得意地說 “用的雪花 ID 啊,分布式環境下唯一,多高級”,結果領導當場就懟了我一句:“高級?你知道這玩意兒給 MySQL 挖坑有多深嗎?”
當時我臉一下子就紅了,心里還嘀咕 “不就是個主鍵嗎,能有啥大問題”,但后來跟著領導扒了半天原理,又自己做了測試,才發現原來選主鍵這事兒,真不是 “能生成唯一 ID 就行” 這么簡單。今天就把我踩過的坑、搞懂的門道都跟大家掰扯掰扯,省得你們跟我一樣,被領導懟了還不知道為啥。
先搞明白:MySQL 主鍵到底要的是啥?
在說雪花 ID 和 UUID 之前,咱得先統一個認知 ——MySQL(尤其是咱們常用的 InnoDB 引擎)對主鍵的要求,跟找對象似的,得 “門當戶對” 才行。你不能光看 “唯一” 這一個優點,就不管其他條件了,不然早晚得出問題。
InnoDB 這引擎有個很關鍵的特性叫 “聚簇索引”,簡單說就是 “主鍵索引和數據行綁在一塊兒”。你可以把它理解成一本書,主鍵索引就是目錄,數據行就是正文內容,目錄的順序和正文的順序是完全對應的。要是目錄亂序,你找內容的時候就得翻來翻去;要是目錄順序整齊,一下就能定位到地方。
所以 MySQL 主鍵的核心要求就三個,少一個都不行:
1. 唯一性:這是底線,沒商量
不管是自增 ID、雪花 ID 還是 UUID,首先得保證 “不重復”。你總不能讓兩個數據共用一個主鍵吧?就像每個人的身份證號不能一樣,不然銀行取錢都能取錯,這是最基本的要求,沒啥好說的。
2. 有序性:這是性能的關鍵,很多人都忽略
剛才說的聚簇索引,要是主鍵是有序的,比如自增 ID 1、2、3、4……InnoDB 插入數據的時候,就知道直接往最后面加就行,跟排隊似的,順著來,效率特別高。
但要是主鍵是無序的,比如 UUID 那種長得亂七八糟的字符串,插入的時候就麻煩了 ——InnoDB 得先找這個 ID 該插在哪個位置,可能插在中間某個地方,這時候就需要 “頁分裂”。啥是頁分裂?你可以想象成書架上的書排滿了,你要把一本新書插進中間,就得先把后面的書都往后挪一挪,騰出地方。數據量小的時候還好,數據量大了,這挪來挪去的功夫可就多了,插入速度會越來越慢,索引還會變得特別臃腫。
3. 占用空間小:越小越好,別給數據庫添負擔
主鍵是要存在索引里的,而且二級索引(比如你建的 name 索引、age 索引)里存的也是主鍵的值。要是主鍵占用空間大,比如 UUID 是 36 個字符,那索引文件就會變得特別大,不僅占磁盤空間,還會影響查詢速度 —— 因為內存里能裝下的索引數據少了,得頻繁去磁盤讀數據,速度能不慢嗎?
搞懂這三個要求,咱們再回頭看雪花 ID 和 UUID,為啥用它們做 MySQL 主鍵會被領導懟,就一目了然了。
先扒 UUID:看著萬能,實則是 MySQL 的 “空間刺客”
咱們先說說 UUID,這玩意兒全稱是 “通用唯一識別碼”,格式大概是這樣的:550e8400-e29b-41d4-a716-446655440000,一共 36 個字符,看著挺唬人,而且確實能保證全球唯一,不管你多少臺機器生成,都不會重復。
很多剛接觸分布式的同學,一聽說要保證 ID 唯一,第一個想到的就是 UUID,覺得 “這玩意兒不用配置,拿來就用,多方便”。但你要是把它當 MySQL 主鍵,麻煩就來了。
問題 1:無序性直接觸發 “頁分裂地獄”
UUID 最大的問題就是 “無序”—— 你生成的兩個 UUID,誰大誰小完全沒規律。比如你剛插入一個550e8400開頭的,下一個可能是a7164466開頭的,再下一個又可能是12345678開頭的。
這對 InnoDB 的聚簇索引來說,簡直是災難。我之前做過一個測試:用 UUID 當主鍵,往 MySQL 里插入 100 萬條數據,前 10 萬條的時候還挺順暢,插入速度大概每秒 1 萬條;但到了 50 萬條之后,速度就掉到每秒 3000 條了;到 100 萬條的時候,每秒只能插 1000 多條,而且磁盤 IO 占用率直接飆到 90% 以上。
后來我用工具查了一下索引情況,發現索引的 “碎片率” 高達 60%—— 這就是頁分裂搞的鬼。因為每次插入都要挪數據,索引里全是碎片,就像你衣柜里的衣服亂堆一樣,找的時候特別費勁。
反觀用自增 ID 做主鍵,插入 100 萬條數據,速度一直穩定在每秒 1.5 萬條左右,索引碎片率只有 5% 不到。這差距,可不是一星半點。
問題 2:36 個字符的 “空間黑洞”,太費資源
UUID 是 36 個字符,要是用 VARCHAR (36) 存儲,每個 UUID 要占用 36 個字節(要是用 UTF-8 編碼,還可能更多)。咱們來算筆賬:
假設你有一張用戶表,有 1000 萬條數據,主鍵是 UUID,那光主鍵索引就要占用 1000 萬 × 36 字節 = 360MB。要是你再建幾個二級索引,比如 name、phone、email,每個二級索引里都要存主鍵的值,那每個二級索引又要多占 360MB,幾個索引加起來,光索引文件就好幾 GB 了。
要是換成自增 ID,用 BIGINT 類型(8 個字節),同樣 1000 萬條數據,主鍵索引只需要 1000 萬 × 8 字節 = 80MB,二級索引也跟著變小。同樣的磁盤空間,能裝下更多的數據和索引,查詢的時候內存也能緩存更多索引,速度自然就快了。
有些同學可能會說 “我可以把 UUID 轉成二進制存儲啊,這樣占用空間就小了”。沒錯,UUID 轉成二進制是能從 36 字節降到 16 字節,但還是比自增 ID 的 8 字節大一倍,而且還有個更麻煩的問題:查詢的時候你得把 UUID 轉成二進制才能查,寫 SQL 的時候特別麻煩,比如where id = UNHEX('550e8400-e29b-41d4-a716-446655440000'),不僅容易寫錯,而且可讀性極差,后續維護的時候,同事看到這種 SQL 得罵娘。
問題 3:查詢性能差,尤其是范圍查詢
咱們平時查數據,經常會用范圍查詢,比如 “查昨天注冊的用戶”,要是主鍵是自增 ID,因為 ID 是有序的,InnoDB 直接就能定位到昨天的 ID 范圍,快速查出數據。
但要是主鍵是 UUID,ID 是無序的,就算你按主鍵范圍查,InnoDB 也得全表掃描(或者掃描大部分索引),因為它不知道這些 UUID 的范圍對應的數據在哪里。我之前做過測試,查 “最近 1 萬條數據”,自增 ID 主鍵只需要 0.02 秒,而 UUID 主鍵需要 0.8 秒,慢了 40 倍!
那 UUID 就一點用都沒有了嗎?也不是。比如你在分布式系統里給文件命名、給緩存鍵命名,這些場景不需要存在 MySQL 里,也不需要排序,用 UUID 就很合適。但要是當 MySQL 主鍵,那還是算了吧,純屬給自己找罪受。
再聊雪花 ID:比 UUID 靠譜,但坑也不少
說完 UUID,咱們再說說雪花 ID。雪花 ID 是 Twitter 搞出來的一種分布式 ID 生成算法,結構是 64 位的長整型(BIGINT),格式大概是這樣的:
- 1 位符號位:固定 0,因為 ID 是正數
- 41 位時間戳:能表示大概 69 年的時間(從某個起始時間開始算)
- 10 位機器 ID:能表示 1024 臺機器
- 12 位序列號:每臺機器每秒能生成 4096 個 ID(12 位最多 4095)
雪花 ID 的優點很明顯:是有序的(因為有時間戳)、占用空間小(8 字節,和自增 ID 一樣)、能保證分布式環境下唯一,看起來好像完美符合 MySQL 主鍵的要求,那為啥我用雪花 ID 還會被領導懟呢?
別著急,雪花 ID 的坑,比你想象的要多。
問題 1:時鐘回撥是 “致命傷”
雪花 ID 的有序性,全靠前面的 41 位時間戳。但要是生成 ID 的機器出現 “時鐘回撥”,麻煩就大了。
啥是時鐘回撥?就是機器的系統時間突然往后跳了,比如本來是 2025 年 8 月 25 日,突然變成 2025 年 8 月 24 日了。這可能是因為機器同步了 NTP 服務器時間,也可能是系統出了故障。
一旦發生時鐘回撥,雪花 ID 生成的時間戳就會比之前的小,生成的 ID 就會比之前的小,變成 “無序” 的。要是把這種無序的 ID 插進 MySQL,就會出現和 UUID 類似的問題:頁分裂、插入速度變慢。
更嚴重的是,要是時鐘回撥的時間比較長,還可能生成重復的 ID。比如機器 A 在 8 月 25 日 10 點生成了一個 ID,然后時鐘回撥到 8 月 25 日 9 點,又生成了一個 ID,這兩個 ID 的時間戳、機器 ID、序列號都可能一樣,導致主鍵重復,插入數據直接報錯。
我之前就遇到過這種情況:有個項目用了雪花 ID 當主鍵,有一次服務器重啟后,NTP 同步時間,時鐘回撥了 10 分鐘,結果當天下午插入數據的時候,報了好幾百次主鍵沖突錯誤,查了半天才發現是時鐘回撥搞的鬼。
那怎么解決時鐘回撥問題呢?有幾種方案,但都不完美:
- 方案 1:檢測到時鐘回撥就暫停生成 ID,等時間追上了再繼續。但這樣會導致服務暫時不可用,要是在高并發場景下,比如秒殺活動,這絕對是災難。
- 方案 2:用物理時鐘 + 邏輯時鐘結合的方式,比如記錄上次生成 ID 的時間戳,要是當前時間戳比上次小,就用上次的時間戳 + 1。但這樣會導致 ID 的時間戳和實際時間不一致,后續要是想通過 ID 判斷數據生成時間,就不準了。
- 方案 3:多機房部署的時候,給每個機房分配不同的機器 ID 段,就算某個機房時鐘回撥,也不會和其他機房的 ID 重復。但這需要復雜的配置和管理,小團隊玩不轉。
不管哪種方案,都需要額外的開發和維護成本,不像自增 ID 那樣 “拿來就用,啥都不用管”。
問題 2:機器 ID 配置不當,分分鐘重復
雪花 ID 的 10 位機器 ID,能表示 1024 臺機器。但要是你配置機器 ID 的時候不小心,把兩臺機器配置成了同一個 ID,那這兩臺機器生成的雪花 ID 就會重復,插入 MySQL 的時候就會報主鍵沖突。
我之前見過一個團隊,為了圖省事,直接用機器的 IP 地址最后幾位當機器 ID。結果有一次擴容,新增的機器 IP 最后幾位和之前的機器重復了,導致生成的雪花 ID 重復,線上數據插入失敗,排查了 3 個小時才找到原因,最后還得回滾數據,別提多狼狽了。
那機器 ID 該怎么配置呢?正確的做法是:
- 用 ZooKeeper、Etcd 這類分布式協調工具,給每臺機器分配唯一的機器 ID,機器啟動的時候去申請,關閉的時候釋放。
- 要是沒有分布式協調工具,也可以手動分配機器 ID 段,比如給 A 機房分配 0-100,B 機房分配 101-200,每臺機器在自己的段里選一個唯一的 ID。
但不管哪種方式,都需要額外的配置和維護,不像自增 ID 那樣 “零配置”。
問題 3:在某些場景下,有序性也會出問題
雪花 ID 的有序性,是 “相對有序”,不是 “絕對有序”。因為它的排序優先級是:時間戳 > 機器 ID > 序列號。
也就是說,在同一毫秒內,不同機器生成的 ID,會按機器 ID 排序;同一機器同一毫秒內生成的 ID,會按序列號排序。
這在大部分場景下沒問題,但要是你有 “嚴格按生成時間排序” 的需求,就可能出問題。比如你有一個訂單表,要求訂單 ID 嚴格按下單時間排序,要是兩臺機器在同一毫秒內生成訂單 ID,機器 ID 大的那個,就算下單時間稍晚,ID 也會更大,導致訂單 ID 的順序和實際下單時間的順序不一致。
雖然這種情況出現的概率不高,但要是你的業務對 ID 的時間順序要求特別嚴格(比如金融場景),那雪花 ID 就不太合適了。
問題 4:遷移數據的時候,能讓你哭
要是你用雪花 ID 當主鍵,后續遷移數據的時候,比如把數據從舊庫遷到新庫,或者分庫分表,就會遇到一個麻煩:雪花 ID 是在應用層生成的,不是數據庫生成的,所以遷移的時候,你得保證新庫的 ID 和舊庫一致,不能重復,也不能漏。
而要是用自增 ID,數據庫會自動生成唯一的 ID,遷移的時候只需要把數據導過去就行,不用管 ID 的問題。
我之前參與過一個項目的數據庫遷移,用的就是雪花 ID 當主鍵,結果遷移過程中,因為有部分數據的 ID 重復,導致遷移失敗,最后不得不寫了個腳本,先把舊庫的 ID 全部導出來,再和新庫的 ID 對比,花了整整兩天才搞定,要是用自增 ID,半天就能搞定。
那 MySQL 主鍵到底該用啥?這 3 個方案才是王道
既然 UUID 和雪花 ID 當 MySQL 主鍵都有這么多坑,那到底該用啥呢?別著急,領導后來給我推薦了 3 個方案,親測好用,咱們一個個說。
方案 1:小項目 / 單機項目,自增 IDyyds
要是你的項目是小項目,或者不需要分布式部署,就一臺 MySQL 服務器,那自增 ID(AUTO_INCREMENT)絕對是最佳選擇,沒有之一。
自增 ID 的優點太多了:
- 完全符合 MySQL 主鍵的三個要求:唯一(數據庫保證)、有序(每次 + 1)、占用空間小(8 字節)。
- 零配置:不用自己寫代碼生成 ID,數據庫自動搞定,省事兒。
- 性能好:插入速度快,查詢速度快,索引碎片少。
- 方便遷移:遷移數據的時候不用管 ID,數據庫自動生成。
那自增 ID 就沒缺點嗎?也有,比如:
- 分布式環境下不唯一:要是你有多個 MySQL 實例,每個實例都自增,就會出現重復的 ID。
- 容易被猜到:比如你的用戶 ID 是自增的,別人很容易猜到你有多少用戶,也容易通過 ID 遍歷數據(比如從 1 開始,依次訪問 /user/1、/user/2)。
但對于小項目 / 單機項目來說,這些缺點根本不是問題。比如你做一個企業內部的管理系統,就一臺 MySQL 服務器,用戶量也就幾千人,用自增 ID 完全沒問題,簡單又高效。
方案 2:分布式項目,數據庫分段自增 ID 更靠譜
要是你的項目是分布式的,需要多臺 MySQL 服務器(比如分庫分表),自增 ID 就不夠用了,這時候可以用 “數據庫分段自增 ID”。
啥是數據庫分段自增 ID?簡單說就是:專門建一個 “ID 生成器” 數據庫,里面有一張表,記錄每個業務表的 ID 當前最大值和步長,每次應用需要生成 ID 的時候,就去這個表拿一段 ID(比如拿 1000 個),然后在應用里自己慢慢用,用完了再去拿下一段。
舉個例子,比如用戶表的 ID:
- 先建一個 ID 生成器表:
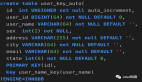
CREATE TABLE id_generator (
table_name VARCHAR(50) NOT NULL COMMENT '業務表名',
current_max_id BIGINT NOT NULL COMMENT '當前最大ID',
step INT NOT NULL COMMENT '步長',
PRIMARY KEY (table_name)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT 'ID生成器表';- 初始化用戶表的 ID 配置:
INSERT INTO id_generator (table_name, current_max_id, step) VALUES ('user', 0, 1000);- 應用需要生成用戶 ID 的時候,先執行以下 SQL,拿一段 ID(0-999):
UPDATE id_generator
SET current_max_id = current_max_id + step
WHERE table_name = 'user'
AND current_max_id = 0;- 應用拿到這段 ID 后,就可以從 0 開始,依次生成 0、1、2……999,用完了再去拿下一段(1000-1999)。
這種方案的優點:
- 有序性:ID 是連續的,符合 MySQL 主鍵的要求,不會出現頁分裂。
- 分布式唯一:因為所有應用都從同一個 ID 生成器拿 ID,所以不會重復。
- 性能好:每次拿一段 ID,不用每次生成 ID 都訪問數據庫,減少數據庫壓力。
- 配置簡單:不用依賴 ZooKeeper、Etcd 這些分布式協調工具,只需要一個數據庫就行。
缺點也有,就是 ID 生成器數據庫是單點,要是這個數據庫掛了,所有需要生成 ID 的業務都得停。不過可以搞主從復制,主庫掛了就切從庫,解決單點問題。
我之前參與的一個電商項目,用的就是這種方案,分了 10 個庫,每個庫有 10 個表,每天新增訂單 100 多萬,用數據庫分段自增 ID,從來沒出現過 ID 重復或者性能問題,特別穩定。
方案 3:高并發場景,Redis 生成 ID 也不錯
要是你的項目并發特別高,比如秒殺活動,每秒要生成幾萬甚至幾十萬的 ID,數據庫分段自增 ID 可能會有點吃力(因為每次拿段 ID 都要訪問數據庫),這時候可以用 Redis 生成 ID。
Redis 生成 ID 的原理很簡單:利用 Redis 的 INCR 命令(原子性遞增),每次生成 ID 的時候,就調用 INCR 命令,讓某個鍵的值加 1,這個值就是新的 ID。
比如生成用戶 ID:
- 先在 Redis 里設置一個鍵,初始值為 0:
SET user_id 0- 每次需要生成用戶 ID 的時候,調用 INCR 命令:
INCR user_id這樣每次調用 INCR,都會返回一個唯一的、有序的 ID。為了提高性能,也可以像數據庫分段自增那樣,一次性從 Redis 拿一段 ID,比如拿 1000 個:
INCRBY user_id 1000這樣就能拿到一段 ID(比如從 1001 到 2000),然后在應用里自己慢慢用。Redis 生成 ID 的優點:
- 性能極高:Redis 是內存數據庫,INCR 命令的性能特別好,每秒能處理幾十萬次請求,完全能滿足高并發場景。
- 有序性:ID 是連續遞增的,符合 MySQL 主鍵要求。
- 分布式唯一:所有應用都訪問同一個 Redis,不會出現 ID 重復。
缺點:
- 需要依賴 Redis:要是 Redis 掛了,ID 生成就會出問題,所以得搞 Redis 集群,保證高可用。
- 數據持久化問題:要是 Redis 沒有持久化,或者持久化失敗,Redis 重啟后,ID 會從之前的值開始,可能會重復。所以需要開啟 Redis 的 AOF 持久化,并且配置合適的持久化策略。
這種方案適合高并發場景,比如秒殺、直播帶貨這些需要快速生成大量 ID 的業務。我之前做過一個秒殺項目,每秒并發 10 萬 +,用 Redis 生成訂單 ID,特別穩定,從來沒掉過鏈子。
總結:別再盲目跟風,選對主鍵才是王道
看到這里,你應該明白為啥我用雪花 ID 當 MySQL 主鍵會被領導懟了吧?不是雪花 ID 不好,也不是 UUID 不好,而是它們不適合當 MySQL 主鍵。
選 MySQL 主鍵,就像選鞋子,不是越貴越好,也不是越高級越好,而是要合腳。總結一下:
- 小項目 / 單機項目:直接用自增 ID,簡單高效,不用瞎折騰。
- 分布式項目(中低并發):用數據庫分段自增 ID,穩定可靠,配置簡單。
- 分布式項目(高并發):用 Redis 生成 ID,性能極高,能扛住大流量。
- 要是你實在想用雪花 ID:那一定要做好時鐘回撥處理和機器 ID 配置,并且接受它可能帶來的遷移麻煩和排序問題。
- 至于 UUID:除非你腦子進水了,否則別把它當 MySQL 主鍵。
技術沒有好壞之分,只有合適不合適。別看到別人用雪花 ID、用 UUID,你就跟著用,得先搞明白背后的原理,結合自己的業務場景,才能做出正確的選擇。不然哪天被領導懟了,還不知道為啥,多冤啊!