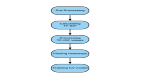
Text2SQL的參考架構(gòu)
原創(chuàng)Text2SQL 使分析人員可以通過用簡單的語言提出問題來輕松地研究數(shù)據(jù)。他們不需要了解復(fù)雜的 SQL,只需輸入一個問題,就可以立即得到所需的數(shù)據(jù)。這對于好奇的分析師尤其有用,他們希望更深入地挖掘數(shù)據(jù),跟隨自己的直覺,發(fā)現(xiàn)有價值的見解,而不會因?yàn)榧夹g(shù)障礙而放慢腳步。在一個快速、直觀地訪問信息可以驅(qū)動更好的決策的世界里,Text2SQL 幫助分析人員釋放他們數(shù)據(jù)的全部潛力。
1. Text2SQL 的重要性
在當(dāng)今數(shù)據(jù)驅(qū)動的業(yè)務(wù)環(huán)境中,如何讓非技術(shù)人員也能輕松訪問和使用數(shù)據(jù),是企業(yè)提升效率與決策能力的關(guān)鍵挑戰(zhàn)之一。Text2SQL(自然語言轉(zhuǎn)SQL)作為自然語言處理(NLP)領(lǐng)域的一項(xiàng)重要技術(shù),在這一背景下發(fā)揮著越來越重要的作用。
Text2SQL極大地增強(qiáng)了非技術(shù)用戶的數(shù)據(jù)交互能力。傳統(tǒng)上,訪問數(shù)據(jù)庫需要掌握復(fù)雜的 SQL 語法,這對沒有技術(shù)背景的用戶來說是一道很高的門檻。而 Text2SQL 技術(shù)使得用戶只需用自然語言提出問題,例如“上個月銷售額最高的產(chǎn)品是什么?”,系統(tǒng)即可自動生成對應(yīng)的 SQL 查詢語句并返回結(jié)果,從而讓所有人都能輕松獲取所需信息。
該技術(shù)顯著提升了工作效率和生產(chǎn)力。通過將自然語言自動轉(zhuǎn)化為結(jié)構(gòu)化查詢,不僅減少了手動編寫 SQL 的時間,也降低了出錯的可能性。這對于需要頻繁進(jìn)行數(shù)據(jù)分析的業(yè)務(wù)人員而言,意味著更快地獲得洞察、更敏捷地響應(yīng)市場變化。
Text2SQL 還具備良好的通用性和可擴(kuò)展性,能夠適配多種類型的數(shù)據(jù)庫架構(gòu)和多樣化的查詢需求。無論是關(guān)系型數(shù)據(jù)庫還是現(xiàn)代數(shù)據(jù)倉庫,無論查詢涉及聚合分析、多表連接還是嵌套子查詢,Text2SQL 都可以靈活應(yīng)對,因此廣泛適用于金融、醫(yī)療、零售、制造等多個行業(yè)領(lǐng)域。
這項(xiàng)技術(shù)也展現(xiàn)出強(qiáng)大的集成能力。它可以被嵌入到現(xiàn)有的 BI 工具、企業(yè)級應(yīng)用平臺或聊天機(jī)器人中,為用戶提供更加直觀、便捷的數(shù)據(jù)訪問方式。這種無縫整合不僅增強(qiáng)了現(xiàn)有系統(tǒng)的智能化水平,也為構(gòu)建以用戶為中心的數(shù)據(jù)分析體驗(yàn)提供了技術(shù)支持。
Text2SQL 不僅是一項(xiàng)技術(shù)突破,更是推動數(shù)據(jù)民主化的重要力量。它打破了技術(shù)壁壘,讓數(shù)據(jù)真正服務(wù)于每一個人,同時也為企業(yè)構(gòu)建智能、高效的數(shù)據(jù)生態(tài)系統(tǒng)提供了堅實(shí)的基礎(chǔ)。
2. Text2SQL 開發(fā)中的主要挑戰(zhàn)
盡管 Text2SQL 技術(shù)在推動數(shù)據(jù)訪問普遍化方面展現(xiàn)出巨大潛力,但其開發(fā)和落地過程中仍面臨諸多技術(shù)與工程上的挑戰(zhàn)。
自然語言的模糊性和多樣性是 Text2SQL 系統(tǒng)面臨的首要難題。人類語言本身具有高度的不確定性,同一個問題可以用多種方式表達(dá),而不同用戶對同一語義的理解也可能存在差異。例如,“最近誰買了我們的產(chǎn)品?”這一問題可能指向不同的字段(如客戶姓名、購買時間等),模型需要準(zhǔn)確識別用戶的實(shí)際意圖,這對語義理解和上下文推理能力提出了更高要求。
數(shù)據(jù)庫結(jié)構(gòu)的復(fù)雜性也給模型帶來了不小的挑戰(zhàn)。現(xiàn)實(shí)世界中的數(shù)據(jù)庫往往包含多個表、復(fù)雜的連接關(guān)系以及豐富的約束條件。對于一個不了解底層 schema 的模型來說,要準(zhǔn)確地將自然語言映射到涉及多表連接、嵌套查詢或聚合函數(shù)的 SQL 語句,并非易事。尤其是在面對大型企業(yè)級數(shù)據(jù)庫時,這種難度將進(jìn)一步提升。
上下文理解也是影響生成結(jié)果準(zhǔn)確性的重要因素。用戶在一個對話流程中往往會基于之前的交互提出后續(xù)問題,比如“那他們買了多少?”這時模型必須能夠正確關(guān)聯(lián)上下文中的對象(如“他們”指的是前文中提到的客戶群體),才能生成正確的 SQL 查詢。缺乏上下文建模能力會導(dǎo)致系統(tǒng)誤解甚至完全錯誤地執(zhí)行查詢。
進(jìn)一步,處理復(fù)雜查詢的能力也是一項(xiàng)重大考驗(yàn)。許多實(shí)際業(yè)務(wù)場景中的查詢涉及多張表、深層嵌套結(jié)構(gòu)或高級 SQL 函數(shù)(如窗口函數(shù)、CASE WHEN 等)。要讓模型準(zhǔn)確識別并生成這些復(fù)雜結(jié)構(gòu),不僅需要設(shè)計更為精細(xì)的模型架構(gòu),還需要大量高質(zhì)量的標(biāo)注數(shù)據(jù)進(jìn)行訓(xùn)練,而這正是當(dāng)前許多 Text2SQL 數(shù)據(jù)集所缺乏的。
特定領(lǐng)域的知識理解也不容忽視。不同行業(yè)使用的術(shù)語、業(yè)務(wù)邏輯和數(shù)據(jù)庫模式差異巨大。例如,在醫(yī)療領(lǐng)域,“診斷代碼”可能對應(yīng)特定的表結(jié)構(gòu)和字段含義,而在金融行業(yè)中,“交易流水”又有著完全不同的定義和用途。因此,構(gòu)建一個能夠在垂直領(lǐng)域中表現(xiàn)良好的 Text2SQL 系統(tǒng),往往需要引入領(lǐng)域?qū)<业闹R,并結(jié)合領(lǐng)域特定的數(shù)據(jù)進(jìn)行微調(diào)。
最后,評估與基準(zhǔn)測試的難度也是限制 Text2SQL 發(fā)展的一大瓶頸。傳統(tǒng)的 NLP 評價指標(biāo)(如 BLEU、ROUGE)難以準(zhǔn)確衡量生成 SQL 的語法正確性和執(zhí)行效果。為此,研究者們提出了諸如執(zhí)行準(zhǔn)確率(Execution Accuracy)和結(jié)構(gòu)匹配度(Structural Similarity)等新指標(biāo),但仍需更多標(biāo)準(zhǔn)化、多樣化的測試集來全面評估系統(tǒng)的性能。
因此,Text2SQL 技術(shù)雖然前景廣闊,但在實(shí)現(xiàn)真正可用、可靠和通用的系統(tǒng)之前,仍然需要克服自然語言理解、數(shù)據(jù)庫建模、上下文推理、復(fù)雜查詢處理、領(lǐng)域適配以及科學(xué)評估等多個維度的技術(shù)挑戰(zhàn)。這既是對算法能力的考驗(yàn),也是對數(shù)據(jù)質(zhì)量和工程實(shí)踐的綜合檢驗(yàn)。
3. Text2SQL 系統(tǒng)的核心組件
構(gòu)建一個高效、準(zhǔn)確的 Text2SQL 系統(tǒng),離不開一套結(jié)構(gòu)清晰、功能明確的技術(shù)組件。當(dāng)前主流解決方案中,越來越多地采用基于知識圖譜(Knowledge Graph)的架構(gòu),以增強(qiáng)系統(tǒng)對自然語言查詢的理解能力和對數(shù)據(jù)庫結(jié)構(gòu)的映射準(zhǔn)確性。
知識圖譜在這一架構(gòu)中扮演著“語義中樞”的角色。它不僅用于存儲與業(yè)務(wù)場景相關(guān)的術(shù)語、同義詞和業(yè)務(wù)規(guī)則,還負(fù)責(zé)建模特定領(lǐng)域內(nèi)的核心概念及其相互關(guān)系。例如,在零售行業(yè),“銷售額”可能對應(yīng)“訂單表中的 quantity × price 字段”,而在金融領(lǐng)域則可能涉及更復(fù)雜的計算邏輯。通過將這些語義信息結(jié)構(gòu)化地組織在知識圖譜中,系統(tǒng)能夠更準(zhǔn)確地理解用戶的自然語言意圖,并將其轉(zhuǎn)化為精確的 SQL 查詢。
此外,知識圖譜還承擔(dān)了對數(shù)據(jù)平臺元數(shù)據(jù)的集中管理職責(zé)。這包括數(shù)據(jù)庫中的表結(jié)構(gòu)、字段定義、主外鍵關(guān)系等關(guān)鍵信息。通過統(tǒng)一維護(hù)這些元數(shù)據(jù),系統(tǒng)可以在面對復(fù)雜數(shù)據(jù)庫結(jié)構(gòu)時快速定位相關(guān)對象,提升查詢生成的效率和準(zhǔn)確性。
對于需要高度定制化或響應(yīng)敏感的應(yīng)用場景,現(xiàn)代 Text2SQL 系統(tǒng)還可以引入高效的模型微調(diào)技術(shù),如 LoRA(Low-Rank Adaptation,低秩適配)或 MoME(Mixture of Memory Experts Adapters,記憶專家混合適配器)。這些輕量級微調(diào)方法允許開發(fā)者在不改變基礎(chǔ)模型權(quán)重的前提下,將特定業(yè)務(wù)概念和數(shù)據(jù)庫結(jié)構(gòu)注入模型之中。
具體而言,LoRA 和 MoME 可用于注入兩類關(guān)鍵信息:
- 商業(yè)概念例如行業(yè)術(shù)語、企業(yè)內(nèi)部命名規(guī)范、關(guān)鍵指標(biāo)定義等,使模型更貼近企業(yè)的實(shí)際表達(dá)方式;
- 數(shù)據(jù)平臺元數(shù)據(jù)包括具體的表名、字段名及其之間的關(guān)聯(lián)關(guān)系,幫助模型精準(zhǔn)匹配底層數(shù)據(jù)庫結(jié)構(gòu),提高生成 SQL 的準(zhǔn)確性。
這種結(jié)合知識圖譜與輕量級微調(diào)技術(shù)的架構(gòu),不僅提升了 Text2SQL 系統(tǒng)的靈活性和可擴(kuò)展性,也增強(qiáng)了其在不同業(yè)務(wù)環(huán)境和數(shù)據(jù)庫結(jié)構(gòu)下的適應(yīng)能力。最終目標(biāo)是打造一個既能理解自然語言又能準(zhǔn)確操作數(shù)據(jù)庫的智能接口,為非技術(shù)人員提供直觀、可靠的數(shù)據(jù)訪問方式。
4. Text2SQL 參考架構(gòu):以財富管理場景為例
在構(gòu)建一個完整的 Text2SQL 系統(tǒng)時,參考架構(gòu)的設(shè)計至關(guān)重要。它不僅決定了系統(tǒng)如何理解自然語言查詢,還影響著最終生成 SQL 的準(zhǔn)確性與效率。以下將以一個典型的財富管理業(yè)務(wù)場景為例,展示整個 Text2SQL 架構(gòu)的運(yùn)作流程。
4.1 場景描述
假設(shè)用戶提出這樣一個問題:
“截至 2024 年 8 月 31 日,按資產(chǎn)類別分列,我的投資組合的總價值是多少?”
這一問題雖然表述簡潔,但背后涉及多個關(guān)鍵要素,包括時間限定、聚合計算、多表關(guān)聯(lián)等。接下來我們將逐步解析該查詢是如何被理解和轉(zhuǎn)化為實(shí)際可執(zhí)行的 SQL 語句的。
4.2 查詢合成階段
首先,系統(tǒng)會對用戶的提問進(jìn)行初步分析和結(jié)構(gòu)化處理:
- 業(yè)務(wù)場景識別確定這是一個“投資組合分析”類的問題;
- 核心指標(biāo)提取關(guān)注“總價值”和“按資產(chǎn)類別分解”兩個關(guān)鍵輸出維度;
- 時間條件提取指定日期為“2024年8月31日”;
- 過濾條件判斷當(dāng)前未提供具體的投資組合或客戶信息,因此不設(shè)置額外篩選條件。
這一階段的目標(biāo)是將自然語言轉(zhuǎn)換為結(jié)構(gòu)化的查詢意圖,為后續(xù)模塊提供清晰的輸入。
4.3 查詢轉(zhuǎn)換階段
在這一階段,系統(tǒng)嘗試尋找與當(dāng)前問題相似的歷史查詢或模板,并據(jù)此生成初步的 SQL 結(jié)構(gòu):
- 語義相似性匹配通過向量數(shù)據(jù)庫或知識圖譜,查找是否存在類似的用戶提問及對應(yīng)的 SQL 模板;
- SQL 提取與復(fù)用如果找到匹配項(xiàng),則提取其 SQL 查詢作為基礎(chǔ);
- 校驗(yàn)與增強(qiáng)根據(jù)當(dāng)前問題中的新條件(如特定日期)對提取出的 SQL 進(jìn)行調(diào)整和優(yōu)化,確保邏輯準(zhǔn)確。
此步驟有助于減少模型對全新生成的依賴,提高響應(yīng)速度和結(jié)果穩(wěn)定性。
4.4 上下文生成 Agent
為了生成更精確的 SQL,系統(tǒng)還需要從知識庫中獲取足夠的上下文信息:
- 業(yè)務(wù)上下文檢索包括投資組合的結(jié)構(gòu)定義、資產(chǎn)分類方式以及估值方法等;
- 表元數(shù)據(jù)識別確定涉及的數(shù)據(jù)表,例如
portfolio(投資組合)、asset(資產(chǎn))、valuation(估值)等; - 列與關(guān)系收集獲取字段名稱、數(shù)據(jù)類型,以及各表之間的主外鍵關(guān)系,為后續(xù) JOIN 操作提供依據(jù)。
這些信息構(gòu)成了生成 SQL 所需的“語義橋梁”,幫助模型更好地理解底層數(shù)據(jù)結(jié)構(gòu)。
4.5 SQL 生成 Agent
在所有上下文準(zhǔn)備就緒后,進(jìn)入真正的自然語言到 SQL 的轉(zhuǎn)換階段:
- 輸入內(nèi)容整合:
用戶合成后的查詢意圖;
相關(guān)的 SQL 上下文;
表結(jié)構(gòu)、字段定義及關(guān)系信息。
- 模型處理過程:使用經(jīng)過訓(xùn)練的 Text2SQL 模型,結(jié)合知識圖譜與元數(shù)據(jù)信息,理解用戶意圖并生成如下 SQL 查詢:
SELECT asset_class,SUM(value)AS total_value
FROM portfolio
JOIN asset ON portfolio.asset_id = asset.id
JOIN valuation ON asset.id = valuation.asset_id
WHERE valuation_date ='2024-08-31'
GROUPBY asset_class;這一查詢語句能夠準(zhǔn)確反映用戶的需求:按資產(chǎn)類別匯總投資組合在指定日期的價值。
4.6 審查與優(yōu)化 Agent
生成的 SQL 并非直接交付使用,還需經(jīng)過驗(yàn)證與優(yōu)化:
- 邏輯正確性檢查確認(rèn)查詢是否完整表達(dá)了用戶的意圖,是否遺漏了關(guān)鍵條件或錯誤地連接了表;
- 性能優(yōu)化建議如有需要,對查詢進(jìn)行重寫,例如添加索引、優(yōu)化 JOIN 順序或引入物化視圖,以提升執(zhí)行效率。
這一步驟確保生成的 SQL 不僅語義正確,還能在生產(chǎn)環(huán)境中高效運(yùn)行。
4.7 答案生成 Agent
最后,系統(tǒng)執(zhí)行 SQL 查詢并生成用戶可讀的結(jié)果:
- 數(shù)據(jù)執(zhí)行與獲取調(diào)用數(shù)據(jù)庫接口,執(zhí)行 SQL 并獲取返回結(jié)果;
- 結(jié)果格式化將原始數(shù)據(jù)整理成易于理解的形式,例如:
“截至 2024 年 8 月 31 日,您的投資組合總價值為 [總價值]。以下是按資產(chǎn)類別分列的細(xì)目:
- 股票:[價值]
- 債券:[價值]
- 現(xiàn)金:[價值]
- 房地產(chǎn):[價值]
- 其他:[價值]
這種結(jié)構(gòu)化的回答不僅滿足了用戶的查詢需求,也提升了交互體驗(yàn)。
這個示例清晰地展示了 Text2SQL 系統(tǒng)在實(shí)際業(yè)務(wù)中的應(yīng)用流程。從自然語言理解、上下文建模,到 SQL 生成、優(yōu)化與結(jié)果呈現(xiàn),每一個環(huán)節(jié)都體現(xiàn)了技術(shù)與業(yè)務(wù)邏輯的深度融合。通過這樣的架構(gòu)設(shè)計,企業(yè)可以實(shí)現(xiàn)真正意義上的“數(shù)據(jù)民主化”——讓每一位業(yè)務(wù)人員都能輕松訪問數(shù)據(jù),獲得所需的洞察力,而無需掌握復(fù)雜的 SQL 技能。
5. 面向 Text2SQL 的增強(qiáng)型知識庫生成 —— 知識圖譜
為了構(gòu)建一個基于知識圖譜的高效 Text2SQL 解決方案,我們需要從多種文檔格式(如 PPT、PDF、Word 和 Excel)以及數(shù)據(jù)庫中提取并整合信息。這一過程不僅涉及技術(shù)上的挑戰(zhàn),還需要細(xì)致的數(shù)據(jù)處理和管理策略。
首先,在業(yè)務(wù)數(shù)據(jù)提取與轉(zhuǎn)換階段,我們利用先進(jìn)的多模態(tài)生成式人工智能(GenAI)及文檔智能技術(shù)來解析不同格式的文檔。通過這種方法,可以從 PPT、PDF、Word 和 Excel 文件中提取出有價值的文本內(nèi)容。接下來,應(yīng)用命名實(shí)體識別(NER)和關(guān)系抽取(RE)模型,識別出文檔中的關(guān)鍵實(shí)體(例如公司名稱、產(chǎn)品名稱、個人姓名等)及其相互間的關(guān)系(如“公司A生產(chǎn)產(chǎn)品B”)。這些實(shí)體和關(guān)系將作為節(jié)點(diǎn)和邊被納入到知識圖譜中,形成一個結(jié)構(gòu)化的信息網(wǎng)絡(luò)。
在業(yè)務(wù)規(guī)則提取與合并環(huán)節(jié),我們采用基于規(guī)則的系統(tǒng)或機(jī)器學(xué)習(xí)技術(shù),從文檔和元數(shù)據(jù)中提煉出隱含或明確的業(yè)務(wù)規(guī)則。這些規(guī)則隨后被轉(zhuǎn)化為邏輯語句或約束條件,并嵌入到知識圖譜中,以便于將特定條件與實(shí)體及關(guān)系相聯(lián)系,從而增強(qiáng)系統(tǒng)的決策支持能力。
對于元數(shù)據(jù)提取與集成,持續(xù)地從數(shù)據(jù)庫中抓取最新的元數(shù)據(jù)至關(guān)重要。這包括但不限于表名、列名、數(shù)據(jù)類型以及表之間的關(guān)系。獲取這些信息后,將其整合進(jìn)現(xiàn)有的知識圖譜內(nèi),增加新的節(jié)點(diǎn)和邊,以反映數(shù)據(jù)庫內(nèi)部的結(jié)構(gòu)化信息。這種做法不僅豐富了知識圖譜的內(nèi)容,也提升了其對底層數(shù)據(jù)的理解深度。
此外,進(jìn)行語義標(biāo)注是提高知識圖譜理解和推理能力的關(guān)鍵步驟。通過對圖譜中的實(shí)體賦予特定的語義類型(如“PERSON”、“ORGANIZATION”、“LOCATION”),可以更準(zhǔn)確地捕捉到每個實(shí)體的本質(zhì)屬性。同時,使用語義關(guān)系(如“ISA”、“HASPART”、“WORKS_FOR”)來描述連接實(shí)體之間的關(guān)系,有助于澄清這些連接的具體含義,進(jìn)一步增強(qiáng)了知識圖譜的表現(xiàn)力。
最后,在確保知識圖譜的質(zhì)量方面,實(shí)施一套全面的質(zhì)量保證機(jī)制不可或缺。該機(jī)制涵蓋錯誤檢測、糾正措施以及驗(yàn)證流程,旨在維護(hù)知識圖譜的一致性和準(zhǔn)確性。與此同時,考慮到信息的時效性,還需建立持續(xù)更新機(jī)制,定期引入來自文檔、數(shù)據(jù)庫及外部資源的新信息,保持知識圖譜的最新狀態(tài)和相關(guān)性,確保它能夠適應(yīng)不斷變化的業(yè)務(wù)需求和技術(shù)環(huán)境。
通過上述步驟,我們可以創(chuàng)建一個強(qiáng)大而靈活的知識圖譜基礎(chǔ)架構(gòu),為 Text2SQL 系統(tǒng)提供堅實(shí)的支持,使其不僅能理解自然語言查詢,還能精準(zhǔn)地映射到復(fù)雜的數(shù)據(jù)庫結(jié)構(gòu),實(shí)現(xiàn)高效的跨領(lǐng)域數(shù)據(jù)訪問與分析。
6. Text2SQL 評估框架與模型優(yōu)化策略
在構(gòu)建和部署 Text2SQL 系統(tǒng)的過程中,建立一個全面的評估框架至關(guān)重要。其核心目標(biāo)是確保模型能夠準(zhǔn)確理解用戶的自然語言查詢,并將其轉(zhuǎn)化為結(jié)構(gòu)正確、語義一致的 SQL 語句,從而在實(shí)際數(shù)據(jù)庫環(huán)境中返回正確的結(jié)果。
一個有效的評估體系應(yīng)從多個維度對模型性能進(jìn)行衡量。首先是語法正確性(Syntax Accuracy),即生成的 SQL 是否符合數(shù)據(jù)庫語法規(guī)范,能否被成功執(zhí)行。其次,更重要的是執(zhí)行準(zhǔn)確性(Execution Accuracy),即生成的 SQL 查詢是否能夠在真實(shí)或模擬數(shù)據(jù)庫中返回用戶期望的結(jié)果。此外,還應(yīng)考慮語義一致性(Semantic Equivalence),即模型輸出的 SQL 是否真正反映了用戶的意圖,即使語法不同,只要執(zhí)行結(jié)果一致也可視為有效。
除了這些定量指標(biāo)外,還需引入上下文理解和泛化能力評估,例如測試模型在面對多輪對話、復(fù)雜嵌套查詢或跨表連接等場景時的表現(xiàn)。同時,針對特定行業(yè)或業(yè)務(wù)場景的數(shù)據(jù)集進(jìn)行驗(yàn)證,也有助于評估模型在實(shí)際應(yīng)用中的適應(yīng)性和穩(wěn)定性。
7. 針對 Text2SQL 的大型語言模型微調(diào)策略
為了進(jìn)一步提升 Text2SQL 模型的性能,尤其是在特定業(yè)務(wù)領(lǐng)域或數(shù)據(jù)庫結(jié)構(gòu)下的表現(xiàn),對基礎(chǔ)語言模型進(jìn)行針對性微調(diào)成為一種高效手段。其中,QLoRA(Quantized Low-Rank Adaptation,量化低秩適配) 是當(dāng)前較為流行的一種輕量級微調(diào)方法。
QLoRA 的優(yōu)勢在于它結(jié)合了模型量化與低秩矩陣調(diào)整技術(shù),在顯著降低訓(xùn)練所需計算資源和內(nèi)存消耗的同時,仍能保持較高的模型性能。通過這種方式,開發(fā)者可以基于通用的大語言模型(LLM),快速適配到具體的 Text2SQL 任務(wù)中,使其更準(zhǔn)確地理解自然語言問題,并生成符合特定數(shù)據(jù)庫結(jié)構(gòu)的 SQL 查詢。
具體而言,QLoRA 可用于注入兩類關(guān)鍵信息:
- 業(yè)務(wù)術(shù)語與表達(dá)方式使模型更貼近企業(yè)內(nèi)部的語言習(xí)慣,提高對行業(yè)專有詞匯的理解能力;
- 數(shù)據(jù)庫元數(shù)據(jù)知識包括表結(jié)構(gòu)、字段含義、關(guān)系約束等,幫助模型更精準(zhǔn)地映射自然語言到數(shù)據(jù)庫對象。
這種微調(diào)方法不僅提升了模型的實(shí)用性,也為構(gòu)建可擴(kuò)展、可維護(hù)的企業(yè)級 Text2SQL 解決方案提供了技術(shù)支持。
綜上所述,一個完善的評估框架與高效的模型優(yōu)化策略相結(jié)合,是推動 Text2SQL 技術(shù)走向成熟、落地的關(guān)鍵路徑。它們共同確保系統(tǒng)在面對多樣化查詢時具備高度的準(zhǔn)確性、穩(wěn)定性和適應(yīng)性,為實(shí)現(xiàn)真正的“自然語言驅(qū)動數(shù)據(jù)分析”奠定堅實(shí)基礎(chǔ)。