阿里面試:Flink 中 TaskManager 架構、內存管理與任務執行機制是怎么樣的?
askManager 作為 Flink 集群中的工作節點,是實際執行數據處理任務的核心組件。
在 Flink 的主從架構中,JobManager 負責任務調度和資源管理,而 TaskManager 則承擔著實際的計算工作。每個 TaskManager 是一個獨立的 JVM 進程,可以運行多個并行任務。

一、TaskManager 整體架構
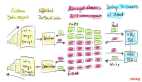
TaskManager 的架構設計體現了高并發、高吞吐的設計理念。下圖展示了 TaskManager 的核心組件及其交互關系:

1. 核心組件解析
(1) Task Slot(任務槽)
Task Slot 是 TaskManager 中資源隔離的基本單位。每個 TaskManager 可以配置多個 Task Slot,每個 Slot 代表固定比例的內存資源。Slot 的數量決定了 TaskManager 能夠并行執行的任務數量。
# flink-conf.yaml 配置示例
taskmanager.numberOfTaskSlots: 4 這個配置表示每個 TaskManager 有 4 個 Slot,意味著可以同時運行 4 個并行任務。值得注意的是,來自同一個作業的不同算子可以共享同一個 Slot,這種機制稱為 Slot Sharing,能夠有效提高資源利用率。
(2) 網絡管理器(Network Manager)
網絡管理器負責 TaskManager 之間的數據傳輸。它管理著網絡緩沖區池,處理數據的序列化和反序列化,并通過 Netty 實現高效的網絡通信。網絡管理器采用零拷貝技術和批量傳輸策略,最大化網絡吞吐量。
(3) 內存管理器(Memory Manager)
內存管理器負責管理 TaskManager 的堆外內存,特別是托管內存(Managed Memory)。它為排序、哈希表、緩存等操作提供內存支持,并通過內存池機制避免頻繁的內存分配和釋放。
(4) RPC 通信層
TaskManager 通過 RPC 與 JobManager 通信,接收任務分配指令、報告任務狀態、處理 Checkpoint 協調等。Flink 使用 Akka 框架實現異步、高性能的 RPC 通信。
(5) 心跳監控(Heartbeat Monitor)
心跳機制確保 TaskManager 與 JobManager 之間的連接狀態。TaskManager 定期向 JobManager 發送心跳信息,JobManager 據此判斷 TaskManager 是否存活。如果心跳超時,JobManager 會將該 TaskManager 標記為失敗并觸發故障恢復流程。
二、TaskManager 內存管理機制
內存管理是 TaskManager 性能優化的關鍵。Flink 采用精細的內存分區策略,將內存劃分為不同用途的區域。

1. 內存結構詳解
(1) JVM 堆內存(Heap Memory)
堆內存主要分為兩部分:
- 框架堆內存(Framework Heap):供 Flink 框架使用,存儲內部數據結構、算子實例等
- 任務堆內存(Task Heap):供用戶代碼和算子使用,存儲用戶定義的對象
配置示例:
taskmanager.memory.framework.heap.size: 128mb
taskmanager.memory.task.heap.size: 512mb (2) JVM 堆外內存(Off-Heap Memory)
堆外內存避免了 GC 的影響,提供更穩定的性能表現:
- 直接內存(Direct Memory):用于框架級別的直接內存操作
- 網絡緩沖區(Network Buffers):專門用于網絡數據交換的緩沖區,是流處理性能的關鍵
- 托管內存(Managed Memory):用于批處理操作(如排序、哈希表)、RocksDB 狀態后端
關鍵配置:
taskmanager.memory.network.fraction: 0.1
taskmanager.memory.network.min: 64mb
taskmanager.memory.network.max: 1gb
taskmanager.memory.managed.fraction: 0.4
taskmanager.memory.managed.size: 2gb 2. 內存配置策略
Flink 1.10 版本引入了新的內存配置模型,支持兩種配置方式:
方式一:配置總內存
taskmanager.memory.process.size: 4gb Flink 會自動計算各個部分的內存大小。
方式二:配置 Flink 內存
taskmanager.memory.flink.size: 3gb 此方式不包括 JVM 元空間和開銷。
3. 內存調優建議
- 網絡緩沖區優化:對于高吞吐場景,適當增加網絡緩沖區大小
- 托管內存調整:使用 RocksDB 狀態后端時,增大托管內存比例
- 避免堆內存過大:過大的堆會導致 GC 暫停時間過長,建議單個 TaskManager 堆內存不超過 32GB
- 監控內存使用:通過 Flink Web UI 監控內存指標,及時調整配置
三、任務執行生命周期
理解任務的執行生命周期有助于診斷任務失敗和性能問題。

1. 任務注冊階段
當 JobManager 完成作業的調度后,會將任務分配到具體的 TaskManager。TaskManager 接收到任務部署描述符(TaskDeploymentDescriptor),包含任務的執行計劃、依賴關系、狀態后端配置等信息。
2. 資源分配階段
TaskManager 為任務分配 Task Slot,并準備必要的執行資源:
- 分配內存資源(堆內存、托管內存)
- 初始化網絡連接(建立與上下游 Task 的數據通道)
- 準備狀態后端(如果任務需要維護狀態)
3. 算子初始化
任務中的各個算子依次執行 open() 方法:
public class MyMapFunction extends RichMapFunction<string, string=""> {
@Override
public void open(Configuration parameters) throws Exception {
// 初始化連接、加載配置等
// 恢復狀態(如果是從 Checkpoint 恢復)
}
}
</string,> 如果是從 Checkpoint 恢復,此階段會從狀態后端加載算子狀態。
4. 數據處理階段
任務進入主循環,不斷從輸入隊列讀取數據,經過算子處理后輸出到下游:
@Override
public String map(String value) throws Exception {
// 處理邏輯
return value.toUpperCase();
} 在流處理模式下,這個循環會持續運行直到任務被取消或發生異常。
5. Checkpoint 執行
Flink 的 Checkpoint 機制保證了精確一次(Exactly-Once)語義。Checkpoint 執行流程:
- Barrier 傳播:JobManager 觸發 Checkpoint,向 Source 算子注入 Checkpoint Barrier
- 狀態快照:Barrier 流經各個算子時,算子會暫存當前狀態
- 異步持久化:狀態后臺異步地將狀態快照寫入持久化存儲
- 確認完成:所有算子完成快照后,向 JobManager 確認
配置示例:
execution.checkpointing.interval: 60000 # 60秒
execution.checkpointing.mode: EXACTLY_ONCE
state.backend: rocksdb
state.checkpoints.dir: hdfs:///flink/checkpoints 6. 任務完成與資源釋放
任務正常完成或被取消時:
- 執行算子的 close() 方法,釋放外部資源
- 關閉網絡連接
- 釋放內存資源
- 向 JobManager 報告任務完成狀態
四、數據交換機制
TaskManager 之間的數據交換是流處理性能的瓶頸之一。Flink 設計了高效的網絡傳輸機制。

1. 結果分區(Result Partition)
上游任務的輸出數據首先寫入結果分區。根據下游任務的并行度和分區策略,數據被分配到不同的子分區(Subpartition)。
分區策略包括:
- Forward:一對一轉發,要求上下游并行度相同
- Rebalance:輪詢分配,實現負載均衡
- Rescale:本地輪詢,減少網絡傳輸
- KeyBy:按鍵分區,保證相同鍵的數據到達同一下游任務
- Broadcast:廣播到所有下游任務
2. 網絡緩沖池
網絡緩沖池是數據傳輸的核心:
- 每個網絡連接分配固定數量的緩沖區
- 緩沖區大小默認為 32KB
- 使用 Netty 的零拷貝技術提升傳輸效率
關鍵配置:
taskmanager.network.memory.buffers-per-channel: 2
taskmanager.network.memory.floating-buffers-per-gate: 8
taskmanager.network.memory.buffer-size: 32kb 3. 反壓機制
當下游任務處理速度跟不上上游時,Flink 會自動觸發反壓:
- 下游任務的輸入緩沖區填滿
- 網絡傳輸暫停,上游輸出緩沖區填滿
- 上游任務處理速度自動降低
反壓是 Flink 自適應流控的重要機制,無需手動配置。可以通過 Web UI 的 Backpressure 標簽頁監控反壓狀態。
4. 序列化優化
數據在網絡傳輸前需要序列化。Flink 提供了高效的序列化框架:
- 對于 POJO 類型,自動生成專用序列化器
- 對于簡單類型(String、Integer 等),使用優化的序列化實現
- 支持注冊自定義類型和序列化器
env.registerType(MyCustomType.class);
env.getConfig().registerTypeWithKryoSerializer(
MyType.class, MyTypeSerializer.class); 五、關鍵配置參數
1. 并行度配置
taskmanager.numberOfTaskSlots: 4
parallelism.default: 4 建議 Slot 數量等于 CPU 核心數,默認并行度根據數據量和計算復雜度調整。
2. 超時配置
akka.ask.timeout: 60s
heartbeat.timeout: 180000 # 心跳超時 180 秒 3. 網絡配置
taskmanager.network.request-backoff.initial: 100
taskmanager.network.request-backoff.max: 10000
taskmanager.network.netty.num.arenas: 4 4. 本地恢復
taskmanager.state.local.root-dirs: /data/flink/local-recovery
state.backend.local-recovery: true 啟用本地恢復可以加速故障恢復,減少從遠程存儲讀取狀態的時間。
六、優秀實踐與常見問題
1. 資源配置最佳實踐
- 合理設置 Slot 數量:一般等于 CPU 核心數,避免過度配置導致上下文切換
- 預留系統內存:為操作系統和其他進程預留至少 1-2GB 內存
- 監控 GC 行為:調整堆內存大小,確保 Full GC 時間在可接受范圍內
- 使用堆外狀態后端:對于有狀態應用,推薦使用 RocksDB 降低 GC 壓力
2. 常見問題排查
(1) 問題 1:任務頻繁失敗重啟
可能原因:
- 心跳超時導致 TaskManager 被判定為失敗
- 內存不足導致 OOM
解決方案:
- 增加心跳超時時間
- 調整內存配置,增加 JVM 內存
- 檢查是否存在內存泄漏
(2) 問題 2:吞吐量低,延遲高
可能原因:
- 網絡緩沖區不足導致反壓
- 并行度設置不合理
- 數據傾斜
解決方案:
- 增加網絡緩沖區大小
- 調整并行度和分區策略
- 使用自定義分區器解決數據傾斜
(3) 問題 3:Checkpoint 超時
可能原因:
- Checkpoint 間隔設置過短
- 狀態過大,寫入速度慢
- 外部存儲性能瓶頸
解決方案:
- 增大 Checkpoint 間隔
- 使用增量 Checkpoint(RocksDB)
- 優化存儲配置,使用高性能存儲
execution.checkpointing.interval: 300000 # 5分鐘
execution.checkpointing.timeout: 600000 # 10分鐘超時
state.backend.incremental: true 3. 監控與調優
使用 Flink 提供的監控指標進行性能分析:
- 任務級別指標:處理速率、延遲、積壓數據量
- TaskManager 指標:CPU 使用率、內存使用、網絡 I/O
- GC 指標:GC 次數、GC 時間、堆內存使用
- Checkpoint 指標:Checkpoint 大小、持續時間、失敗次數
推薦使用 Prometheus + Grafana 構建監控系統:
metrics.reporter.prom.class: org.apache.flink.metrics.prometheus.PrometheusReporter
metrics.reporter.prom.port: 9249 七、總結
TaskManager 作為 Flink 的工作引擎,其設計體現了分布式計算的核心理念:資源隔離、并行執行、高效通信。通過深入理解 TaskManager 的架構、內存管理、任務執行和數據交換機制,我們能夠:
- 優化資源配置:根據作業特點合理分配內存、網絡資源
- 提升系統性能:通過調優并行度、緩沖區等參數提高吞吐量
- 增強系統穩定性:理解故障恢復機制,配置合理的超時和重試策略
- 快速排查問題:根據監控指標和日志定位性能瓶頸